基于大规模语料库的汉语词义相似度计算方法
2013-04-23吴云芳邱立坤吕学强
石 静, 吴云芳, 邱立坤, 吕学强
(1. 北京大学 计算语言学研究所,北京 100871; 2. 鲁东大学 文学院,山东 烟台 264025;3. 北京信息科技大学 网络文化与数字传播 北京市重点实验室,北京 100101)
1 引言
词汇语义信息是自然语言处理中很重要的资源,是进一步进行句法和语义分析的基础。在信息检索中的查询扩展、机器翻译中的模块识别等方面,相似词都是不可或缺的知识资源;在句法分析、词义消歧等信息处理任务中,词语相似度也发挥着重要的作用。而相似度词典的手工构建是一项费时费力的浩大工程,存在着不易更新、覆盖度不全等诸多缺陷。自动地获取相似词并得到相似度,使自动构建词典成为可能,不仅减少了工作量,还使词典资源能够定时更新和扩展。
词义相似度的计算可分为两大类方法: 基于大规模语料库和基于词典。基于词典的研究多是利用词典中现有的层次关系计算两个词的相似度,例如,基于WordNet来计算英语词语的语义相似度,基于HowNet来计算汉语词语的语义相似度。基于语料库的研究多是选取上下文特征,用向量来表征词语,再利用这些特征向量进行词语之间相似度的计算。研究者用这两种方法对英语词义相似度进行了大量的研究,但汉语研究主要集中在基于词典的方法上,基于大规模语料库计算汉语词义相似度的研究还不多见。刘群和李素建[1]基于HowNet计算汉语词义相似度,后人在此基础上进行了很多拓展研究,例如,文献[2-3]。但基于词典的方法需要有完备的知识库的支撑,依赖词典编撰者个人的经验知识,无法反映大规模语料库中词语真实的意义和用法。Agirre等[4]的研究表明,基于语料库的方法可以取得和词典方法相媲美的结果而无需人工知识的支撑。本文采用基于语料库的方法来计算汉语词语的语义相似度。
基于语料的相似词获取方法是基于分布性假设[5]: 语义相似的词语通常有着相似的上下文。Lin[6]基于一个6.4亿词的英文语料,加以依存句法分析,将上下文语境表示成有依存关系的三元组,而后基于互信息提出一种算法来计算词语之间的相似度,实验结果优于其他计算方法。Curran[7]提出将不同上下文表征方式相结合,包括用3种句法分析方法CASS, MINIPAR, SEXTANT 抽取出的上下文特征,3种窗口特征W(L1,2), W(L1,R1), W(R1,2)。实验结果表明,集成方法显著优于单个方法。Weeds 等[8]基于BNC语料,应用9种不同的相似度算法,所得相似度结果差别很大,因而指出面对不同任务时应选择合适的计算方法,但是作者并没有明确指出如何来选择算法。Hagiwara 等[9]系统研究了分布相似方法中的上下文特征选择,选取的3类特征包括依存关系、窗口词语、句子共现。句子共现特征效果很不理想,依存关系和窗口词语可以达到较好的结果,三者的结合超越任何单一的特征。Geffet和Dagan提出了一种自举方法来计算特征的权值,其基本思想是,相似词共有的特征是那个意义最好的表征,因此其权值应该被加大[10]。Kazama 等[11]进行了日语语义相似度计算研究,提出了一种贝叶斯算法来解决基于分布方法中的数据稀疏问题。
本文研究了基于大规模语料库的汉语词义相似度计算方法,系统地比较分析了相似度计算中的上下文选择方法: 上下文特征的权值计算、基于窗口和基于依存关系的表示方法、不同语体的差异。
2 基于分布的相似度计算方法
基于分布的相似度计算方法的核心思想是,基于大规模语料,将词语分布的上下文语境表示成向量,通过计算向量之间的相似性来获得目标词之间的相似度。具体实现方法为: 1)取目标词所在的上下文,或词语、词性、相对位置,或包含目标词的句内依存关系,作为特征;2)利用上下文与目标词的关系,或共现次数,或相关程度等,作为特征权值,构成向量;3)使用相似度计算方法,或余弦夹角,或向量重叠的信息量,计算两个向量的相似程度,作为两个词语的相似度。该方法不需要语言学知识或人工标注语料的指导,可以自动地从大规模语料库中挖掘出词语潜在的语义,是一种应用很广泛的无指导自动语义获取方法。
2.1 上下文特征的权值选择
在语料中按一定方法选取上下文特征后(见下文第3节详述),使用向量空间模型来表征词语,即对每个目标词都构造特征向量,特征向量的每个维度对应一个特征。如何来衡量每个维度的权值是一个很值得研究的问题,权值选取方法不同,相似度计算的结果差异很大。本文实验了5种不同的权值计算方法。
1)tf: 上下文词与目标词共现的频次;
2)bool值: 上下文词与目标词曾经共现则取值为1,从未共现则取值为0;
3)idf值: 上下文词的idf取值
其中,N为目标词的总数,df(cj)为词cj在上下文出现的目标词的个数,+1是为了平滑,避免出现0值;
4)tfidf: 指1)的tf乘以3)的idf,
tfidf(wi,cj)=tf(wi,cj)×idf(cj)
(2)
其中,wi为目标词,cj为上下文词;
5) PMI: 指目标词wi和上下文词cj的互信息,


(3)
其中,T为语料中所有出现词的总个数,count(x)为语料中x出现的频次。
2.2 向量的相似度计算
当特征向量构建完成后,词语之间语义的相似度就转换为计算向量之间的相似度。常用的相似度计算方法有匹配系数、Dice系数、Jaccard系数、Lin方法等。本文实验了前2种相似度计算方法。
1) cos: cos度量被广泛应用于计算语义相似度。

2) LIN方法: 是指Dekang Lin在1998年提出的求词语相似度的公式[6],它被研究者广泛应用于计算英语的词义相似度,被证明有较好的效果。
其中,T(w)是出现在w上下文的词,且与w的互信息为正值。可以观察到,LIN方法与cos_PMI公式有相似之处,只是将分母的求乘积改成求和,分子的求模改成求和。
3 上下文特征的表征形式
3.1 基于窗口对比基于依存关系
语义相似度研究中,上下文特征常用两种表征形式: 基于窗口和基于依存关系。Pado和Lapata (2007)[12]研究表明,基于依存关系可以区别不同的语义关系类别。本文比较分析了这两种不同的上下文表征形式。
1) 基于窗口
窗口上下文是指取一定窗口内的词作为目标词的上下文特征,即区分位置的词袋词语(bag of words)。在本文实验中,原始语料经过切词、词性标注之后,利用标点符号“。,: );”进行了断句处理。在句子范围内,选取目标词前后窗口为3的上下文词、这些词的词性、与目标词的相对位置作为上下文特征。选取时,删除了和目标词共现频次很低的特征(≤10)。例如下面的这个句子:
(1) 黑龙江/ns 将/d 严格/ad 控制/v 森林/n 资源/n 消耗量/n
设目标词为“控制”,窗口为3的上下文特征w-3,w-2,w-1,w+1,w+2,w+3分别为“黑龙江/ns”,“将/d”,“严格/ad”,“森林/n”,“资源/n”,“消耗量/n”。
2) 基于依存关系
依存关系上下文是指,以与目标词相关的所有句内依存关系作为上下文特征。其语言学假设是: 能在相同依存关系中担任相同成分的词是相似词。这需要首先对语料中的每个句子进行依存分析,本文使用了斯坦福的汉语分析器*http://nlp.stanford.edu/software/lex-parser.shtml。对语料进行依存分析,该依存分析器一共包含45种汉语依存关系,详见Chang 等[13]的描述。例如,下面的句子及提取出的依存关系如下:
(2) 新加坡 印尼 签订 航空 协定
nsubj(签订-3, 新加坡-1);nsubj(签订-3, 印尼-2);nn(协定-5, 航空-4);dobj(签订-3, 协定-5)
每一条依存关系提供的信息有: 关系名称(如nsubj,主谓;nn,名词修饰名词;dobj,动宾),两个参与关系的词语及它们分别在句中的位置。45种依存关系中有一种标注为dep,表示无法清晰定义的其他关系。本文实验时去掉了该关系,选取其余44种关系作为有用特征。
对每一个目标词w,其一个依存特征定义为一个三元组
3.2 新闻语料语体对比网络语言语体
词义相似度计算中关于语料语体的影响,即有关领域迁移和对比(domain adaptation)的研究还不多见。本文在新闻语体和网络语体这两种语体上进行了实验。
1) 新闻语体
使用了国际语言资源联盟LDC的Chinese Gigaword,选取其中的新华社语料加以研究,该语料库收录了1991~2004年14年的新华社全部文本,共约471 110K字。对语料进行了前期处理工作: 1)从Unicode到GB编码的转换;2)利用中国科学院计算技术研究所的分词软件ICTCLAS对全部文本进行了自动词语切分和词性标注;3)利用斯坦福的汉语分析器对全部文本进行了依存分析。经过统计计算,得到语料中出现的所有名词、动词、形容词及其频次,去掉出现10次以下的词,并经过初步筛选: 动词和形容词去掉不能单独构成词的语素(词性标注为”vg””ag”)、名词取词性标注为”n”,构成相似度计算的目标词,名词有31 125个,动词有15 250个,形容词有 3 060个。在新闻语体上,我们只计算同词类词语的语义相似度,即计算了31 125×31 125个名词的相似度,15 250×15 250个动词的相似度,3 060×3 060个形容词的相似度。
2) 网络语体
使用了搜狗实验室提供的网络语料,从中提取了130 000个常用词所出现的句子,每个词语抽取了最多1万个句子,利用中国科学院计算技术研究所的分词软件ICTCLAS对全部文本进行了自动词语切分和词性标注,计算了130 000×130 000个词语之间的相似度。
4 实验结果与分析
4.1 评测方法
选择了哈尔滨工业大学的《同义词词林》(扩展版)作为评测标准。《词林》(扩展版)共收录了91 114个词,以5层的树状结构来组织这些词。我们基于类别大小的考虑,主要使用了2、3、4层进行评价,第2层有95个类,第3层有1 425个类,第4层有4 229个类。限于篇幅,本文只汇报了第4层的评价结果,不同方法在不同层级上的相对实验结果是一致的。
采用了两种评价指标。相似词排名的前N个词具有更大的实际意义,因此用P@K来评价,K分别取1、5、10、50,即排名前K个词对应到《词林》里的准确率。
(6)
使用了MAP指标来评测,MAP为所有选出的目标词的平均AP值:
(7)
其中,N为计算结果中目标词所包含的同义词数目(在本实验中,名词N=31 125,动词N=15 250,形容词N=3 060),R为《词林》中目标词所含有的同义词的数目,ans为《词林》中目标词所在的同义词类别,M为加以评价的目标词总数目。本文对多义词还未做处理,如果一个词出现在多个类别中,那ans为这些类别的合集。
在评测时,根据词语在语料中出现的频次、单字词还是双字词、义项的多寡等多种因素,分别人工选取了150个名词、150个动词、150个形容词,共450个词语作为样本进行评测。
4.2 实验结果
1) 不同权值的比较分析
在新闻语体的Chinese Gigaword语料上,基于窗口选取上下文特征,利用cos方法来计算向量相似度,比较实验了不同权值的性能,实验结果如表1所示。
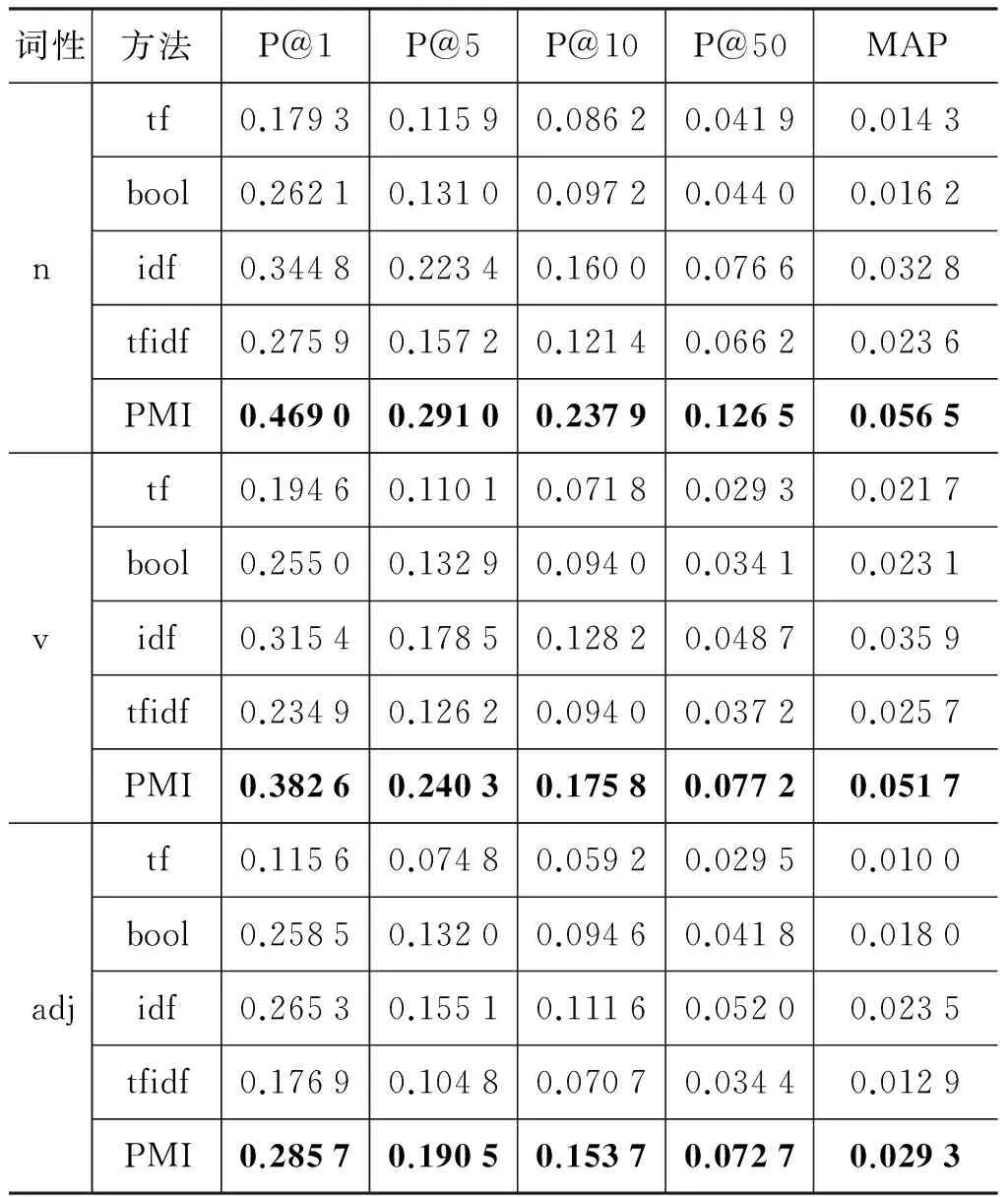
表1 不同权值的比较结果
可以观察到,权值的计算方法对实验结果的影响非常大,无论是对于动词、名词还是形容词,权值PMI方法都取得了最好的实验结果,然后依次是idf、tfidf和bool,最差的是tf。PMI权值的结果最好,是因为其运用了更多的信息。idf可以削弱高频词的作用,例如,“的”、“是”等这些其实对词义区分并无提示作用的词,所以也取得了比较好的效果。相对而言,tf过多地强调了频次,这样使得无作用的超高频词起了主导作用,所以结果比较差。
2) 不同相似度计算方法的比较分析
在新闻语体的Chinese Gigaword语料上,用基于窗口和基于依存关系两种方法选取上下文特征,比较了cos_PMI 和LIN方法两种不同相似度计算方法的性能,如表2所示。

表2 不同相似度计算方法的比较结果
可以观察到,无论是基于窗口还是基于依存关系,无论是对于动词、名词还是形容词,cos_PMI方法都要优于LIN方法。Lin(1998)[7]提出该方法时,是基于全部的依存关系。但是在汉语中即便是基于依存关系,LIN方法比cos_PMI仍是略逊一筹。
通过分析LIN和cos的公式可以得知(式(4)和式(5)),LIN其实类似于cos的一个变体,将内积转化为求和,将求模也转化为求和的结果。乘的方式更能扩大两个元素的作用,而相加则可能将其中一个的信息湮没,所以在相同PMI权值下,乘的方法即cos,获得了比加的方法即LIN,更好的效果。
3) 窗口和依存关系的比较分析
在新闻语体的Chinese Gigaword语料上,用性能最好的cos_PMI方法,比较了窗口和依存关系两种不同方法的性能,如表3所示。
可以观察到,在中文句法分析的结果下,基于窗口方法优于基于依存关系的方法。这个原因是多方面的, 其中一个主要的原因是因为中文的句法分析准确率不高,引入了大量的噪声。据本文的分析,存在以下几类主要错误。
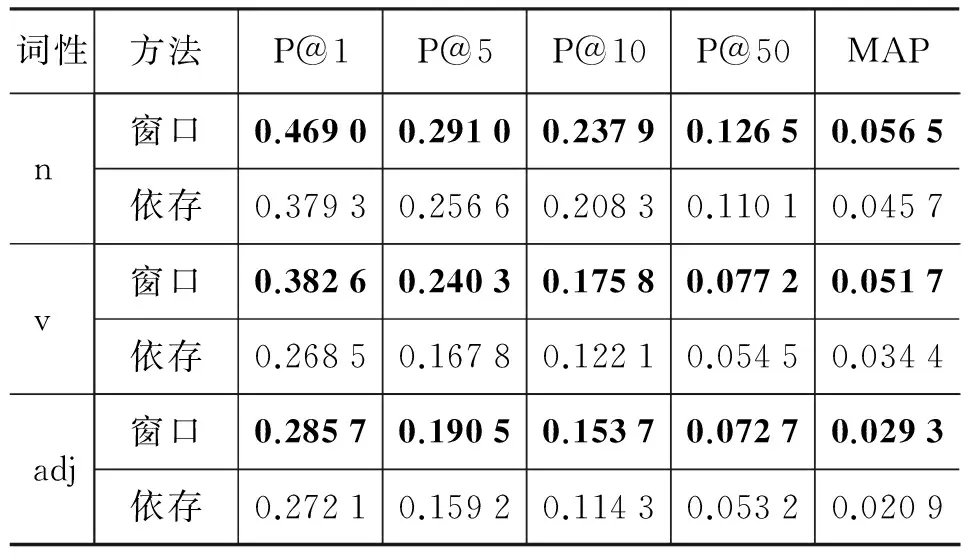
表3 窗口和依存关系的比较结果
[1] 词语切分错误
该报 道 是 毫无 根据 的 ——“报道”切分错误
[2] 词性标注错误
( /NN 约/AD 423万/ CD 美元/ M )/ JJ —— 括号标注错误,应标注为标点符号PU
[3] 人名地名分析错误
记者/NN 肖/ NR 辉/ CD 家/ M——名字都被拆分开,标注成了不同的词性
[4] 中心语提取错误
阿 否认 开放 边界 的 消息 dobj(开放-3, 消息-6) ——“开放”的宾语应该是“边界”
[5] 标点符号的错误。包括标点符号词性标注错误和标点相关的关系punct的错误,例子见[2]、[6]
[6] 句法树分析失败造成依存关系分析的错误
#Failure# punct(作出-3, 裁定-14)——句法树分析失败,导致错误的punct关系,punct应存在于一个词与一个标点之间
4) 新闻语料和网络语言的比较分析
基于窗口方法选取特征,利用PMI方法衡量权值,用cos方法计算相似度,比较分析了两种不同语体: 新闻语料和网络语言对语义相似度计算的影响,实验结果如表4所示。

表4 新闻语料和网络语言的比较结果
可以观察到, 网络语体较新闻语体有着较大的优势。新闻语体是针对特定领域的,质量较高但覆盖率不足,词语的用法受限,经常会运用一些特定的句式;网络语体是不限领域的,覆盖率较高,词语用法丰富灵活。表4的结果告诉我们,在计算词义相似度时,语料语体的选择是一个很重要的因素。
5 结语
本文研究了基于大规模语料库的汉语分布性相似度计算方法。分布性相似度计算方法包含两个步骤: 用上下文特征向量来表征目标词语;计算向量的相似度来逼近词义的相似度。本文系统实验了汉语词义相似度计算中的各种因素: 比较分析了tf、bool、idf、tfidf、PMI 5种不同的上下文特征权值算法;比较分析了cos 和LIN 两种不同的相似度计算方法;比较分析了窗口上下文和依存关系上下文两种不同的表征形式;比较分析了新闻语体和网络语体的领域差别。实验结果表明: PMI 权值明显优于其他权值衡量方法;以PMI为权值的cos方法优于LIN方法;在汉语分析器的现状基础上,基于窗口的相似词获取方法优于基于依存关系的相似词获取方法;网络语体因其丰富灵活性而优于新闻语体。
接下来,我们将进一步实验,在窗口和依存关系的基础上深入挖掘,去寻找更多的或更有用的上下文特征。在依存关系方面,思考如何去除噪音挑选出准确且重要性高的关系。并进一步对相似度计算的公式加以分析,以求提出更好的计算方法。
[1] 刘群,李素建. 基于《知网》的词汇语义相似度的计算[C]//第三届汉语词汇语义学研讨会,台北,2002.
[2] 张亮,尹存燕,陈家骏. 基于语义树的中文词语相似度计算与分析[J].中文信息学报,2010,24(6):23-30.
[3] 刘青磊,顾小丰. 基于《知网》的词语相似度算法研究[J]. 中文信息学报,2010,24(6):31-36.
[4] Agirre E, Alfonseca E, Hall K, et al. A study on similarity and relatedness using distributional and WordNet-based approaches[C]//Proceedings of HLT-NAACL, 2009: 19-27.
[5] Harris Z. Mathematical structures of language[D]. Wiley, New Jersey,1968.
[6] Lin D. Automatic Retrieval and Clustering of Similar Words[C]//Proceedings of COLING/ACL 1998: 768-774.
[7] Curran J. Ensemble methods for automatic thesaurus extraction[C]//Proceedings of EMNLP-2002: 222-229.
[8] Weeds J, Weir D, McCarthy D. Characterizing measures of lexical distributional similarity[C]//Proceedings of COLING-2004: 1015-1021.
[9] Hagiwara M, Ogawa Y, Toyama K. Selection of effective contextual information for automatic synonym acquisition[C]//Proceedings of ACL/ COLING-2006, 2006: 353-360.
[10] Geffet M, Dagan I. Bootstrapping distributional feature vector quality[J]. Computational Linguistics, 2009, 35(3):435-461.
[11] Kazama J, Saeger S, Kuroda K, et al. A Bayesian method for robust estimation of distributional similarities[C]//Proceedings of COLING-2010, 2010: 247-256.
[13] Chang.P, Tsengb,H, Jurafskya,D and Manning,C. Discriminative Reordering with Chinese Grammatical Relations Features[C]//Proceedings of the Third Workshop on Syntax and Structure in Statistical Translation at NAACL HLT 2009.51-59.
附录A
词语相似度示例(前10个相似词)
哀思: 情思-0.088 乡愁-0.084 乡思-0.084 忧思-0.075 爱意-0.069 英灵-0.066 情愫-0.065 痛楚-0.064 敬意-0.063 深情厚意-0.063
轮船: 游轮-0.117 货轮-0.114 客轮-0.108 海轮-0.102 渡轮-0.097 海船-0.096 货船-0.096 航船-0.095 船只-0.089 江轮-0.087
泥土: 浮土-0.128 灰土-0.104 沙土-0.096 沙子-0.094 淤泥-0.091 沙砾-0.091 表土-0.090 土块-0.088 泥巴-0.087 尘土-0.086
床单: 被单-0.151 床罩-0.136 被褥-0.135 枕巾-0.134 枕套-0.127 蚊帐-0.121 浴巾-0.119 棉被-0.112 毛巾被-0.107 褥子-0.103
老练: 老到-0.122 老辣-0.122 练达-0.109 干练-0.096 沉稳-0.092 老成-0.083 娴熟-0.083 狡诈-0.0821 镇定-0.080 精明-0.078
犀利: 尖刻-0.122 锐利-0.117 凌厉-0.098 老辣-0.093 精辟-0.087 敏锐-0.087 泼辣-0.082 简练-0.081 机智-0.081 机敏-0.080
优雅: 高雅-0.135 典雅-0.130 幽雅-0.129 柔美-0.121 淡雅-0.118 雅致-0.115 素雅-0.113 婉约-0.109 文雅-0.103 温婉-0.102
解救: 营救-0.076 援救-0.068 挽救-0.067 搭救-0.064 拯救-0.063 抢救-0.063 脱身-0.057 安抚-0.056 救护-0.053 救活-0.053
纠正: 改正-0.103 制止-0.087 订正-0.083 改掉-0.077 克服-0.075 更正-0.069 补救-0.067 矫正-0.066 督促-0.065 批评-0.064
善待: 关爱-0.109 关心-0.102 爱护-0.096 对待-0.092 爱惜-0.092 体谅-0.090 珍惜-0.089 感化-0.085 体恤-0.083 尊重-0.083
