不平衡情感分类中的特征选择方法研究
2013-04-23王志昊王中卿李寿山李培峰
王志昊,王中卿,李寿山,李培峰
(苏州大学 计算机科学与技术学院 ,江苏 苏州 215006)
1 引言
随着互联网的迅猛发展,人们越来越习惯于在网络上表达自己的观点和情感,网络上随之出现大量带有情感信息的文本。这些文本大多以评论、博客的形式存在,传统的基于主题的文本分类系统已经无法满足对这些主观文本分析的需求。在此背景下,情感分类作为一种面向主观文本分析的特定任务越来越受到广泛关注[1]。情感分类任务是指对文本自身情感倾向性进行分类。例如,判断某一评论是“赞扬” 或“批评”[2-4]。近年来,情感分类在自然语言处理研究领域已经成为一个热点研究问题[1]。
目前大部分情感分类研究建立在正类样本和负类样本平衡的基础上[5]。然而,实际情况中,在收集的产品评论语料中,会时常发现正负类别里面的样本数目差距非常大。换言之,正负类数据的分布往往并不平衡。这种数据不平衡性会导致传统机器学习分类算法在分类过程中严重偏向多类样本,分类器性能受到很大损失。为了本文的表述清楚,我们称这种情况下的情感分类任务为不平衡情感分类,并将样本集合中样本数较多的类别称为多类(Majority Class),样本数较少的类别称为少类(Minority Class)。
此外,作为一种特定的文本分类任务,情感分类任务同其他文本分类一样,面临着高维度特征空间的问题。该问题可能造成冗余的同时也使得一些学习算法难以施展。为了解决高维特征的问题,特征选择方法在文本分类研究中占有非常重要的地位[5]。然而,对于情感分类,特别是不平衡情感分类,特征选择方法的研究还非常缺乏。如果在不平衡分类任务中进行特征选择还是一个迫切需要解决的问题相关研究表明,在不平衡情感分类中,欠采样(Under-sampling)方法是一种表现较好的方法[6]。为了能够降低不平衡分类中高维度特征空间问题,本文以欠采样方法为基础,结合四种经典的特征选择方法,提出三种特征选择模式。
本文结构安排如下: 第2节介绍了不平衡情感分类和特征选择的相关工作;第3节提出基于欠采样的特征选择方法;第4节给出实验结果及分析;第5节给出相关结论。
2 相关工作
2.1 不平衡情感分类
不平衡分类问题在机器学习[7]、模式识别[8]、数据挖掘[9]等领域均受到了广泛关注,是众多实际应用任务中的共同具有的具挑战性问题。
在主流的不平衡分类方法中,过采样技术和欠采样技术应用最为广泛。其中,过采样技术通过重复少类样本达到样本数平衡的目的[10];欠采样技术则通过减少多类样本使得两类样本数平衡[8,11]。目前,针对情感分类中的不平衡问题研究还不是很多,其中,Li等人将监督学习、主动学习和半监督学习方法引入不平衡情感分类问题,取得了很好的分类效果,很大程度上减少了样本的标注量[6,12-13]。
2.2 情感分类中的特征选择
一直以来,高维度特征空间是文本分类研究的一个重点问题。特征选择可以让文本分类变得更快速,分类更精确[14]。相关研究表明,将特征选择方法CHI应用于大规模在线产品评论,可以在不损失性能的前提下减少特征向量维度[4]。此外,Li等[15]将DF、MI、IG等特征选择方法用于平衡数据的主题文本分类和情感分类问题中,有效降低了维度。然而,据我们所知,在不平衡情感分类问题上还没有关于特征选择方法的研究。
3 不平衡情感分类中的特征选择方法
3.1 不平衡情感分类方法: 随机欠采样(Random Under-Sampling)
随机欠采样是指从初始的多类标注样本中随机取出和少类标注样本一样规模的样本,与少类样本一同构建分类器。根据王等人在不平衡分类方法的实验结果得知,基于随机欠采样的分类效果优于完全训练(Full Training, FullT),主要原因是分类算法严重趋向多类,使得少类的召回率很低[16]。此外,随机欠采样相比其他重采样技术也具有明显优势,分类性能最佳[17]。因此,本文所提出的特征选择方法及模式只考虑分类效果较好的随机欠采样方法。
3.2 特征选择方法
在特征选择过程中,需要对每一个特征使用一个权重函数进行计算,计算出标识该特征重要性的权重值。通过对权重大小的比较,对所有特征进行排序,提取排序在前面的特征作为最终的分类特征。对于某个特征t的权重函数,计算出的值越大,该特征就被认为是越重要。为了便于估算上述权重值,需要获取训练集中的某些统计信息,它们分别是:
p(t): 文档x包含特征t的概率;
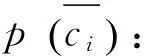
p(t,ci): 文档x包含特征t并且属于类别ci的联合概率;
p(ci|t): 文档x包含特征t时属于类别ci的概率;
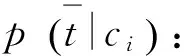
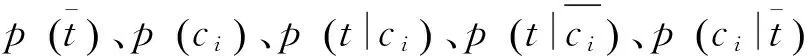
本文采用文本分类中传统的四种特征选择方法,分别是文档频率(DF)、互信息(MI)、信息增益(IG)和χ2统计(CHI)。下面将分别介绍这四种特征选择方法。
1) 文档频率(DF)
文档频率指的是训练集中出现某特征词的文档数量,定义为:
该方法认为某特征在文档中出现次数越多就显得越重要。这种方法存在一个明显缺点: 某些高频的停用词计算出的DF值很高但并不具有区别类别的能力,选取这些特征对分类并没有太大作用。然而,DF方法计算复杂度小,实现简单,并且在基于主题的文本分类任务中表现出较好的性能[14]。
2) 互信息(MI)
互信息用于衡量某个词和类别之间的统计独立关系。如果特征词t与类别ci的互信息越大,说明特征t 中包含的与类别有关的鉴别信息就越多。某个特征词t和某个类别ci的互信息定义如下:
在多个类别的集合中,通常使用最大MI和平均MI两种方式确定某一特征词t与类别ci之间的互信息,具体如下:
由于最大互信息的分类效果比平均互信息更好[14],我们选择最大互信息作为特征词t的特征值。
3) 信息增益(IG)
信息增益计算文档中包含特征词t与不包含特征词t时的信息差[14]。若特征t带来的信息越多,该特征就越重要。计算信息增益的方法定义如下:
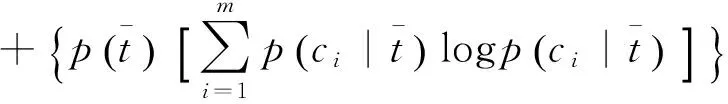
(5)
信息增益方法考虑了特征出现和不出现两种情况,比较全面,分类效果较好, 在之后的实验中也得到验证。
4) 统计(CHI)
CHI方法[14]定义如下:
其中,
χ2(t,ci)

(7)
3.3 基于不平衡数据的特征选择模式
在不平衡情感分类问题中,同时需要处理数据分布不平衡和特征选择两个问题。因此,按照处理这两个问题的次序,本文提出三种特征选择模式。在处理数据不平衡问题时,我们仅仅以随机欠采样为研究对象。
1) 先随机欠采样,后特征选择(UnderS+FS)
首先,在训练样本中先使用随机欠采样技术,使得正类样本和负类样本数量相等;其次,再分别采用DF、MI、IG、CHI四种特征选择方法,从平衡的数据中获得不同维度的特征向量。在特征选择的过程中,截取特征值较大且分别排在各方法前n位的特征。图1为该特征选择模式图。
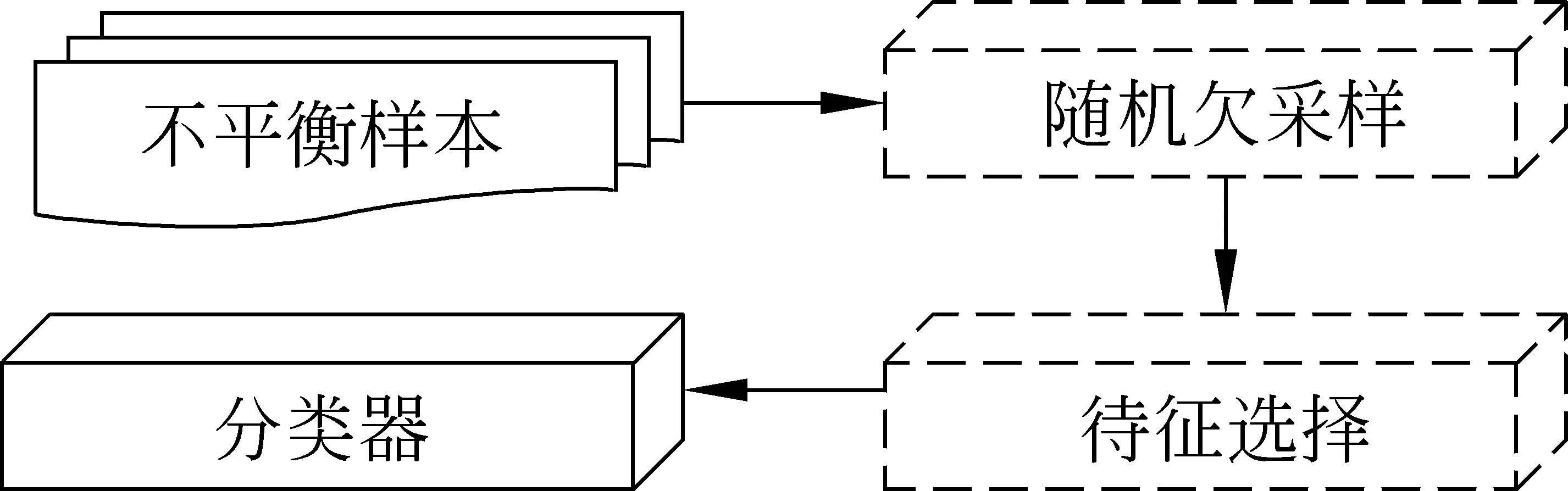
图1 先随机欠采样,后特征选择模式
2) 先特征选择,后随机欠采样(FS+UnderS)
首先,在不平衡的训练样本中采用特征选择方法,得到分类器所需的特征向量;其次,使用随机欠采样获取平衡的训练样本。在特征选择的过程中,截取特征值较大且分别排在各方法前n位的特征。
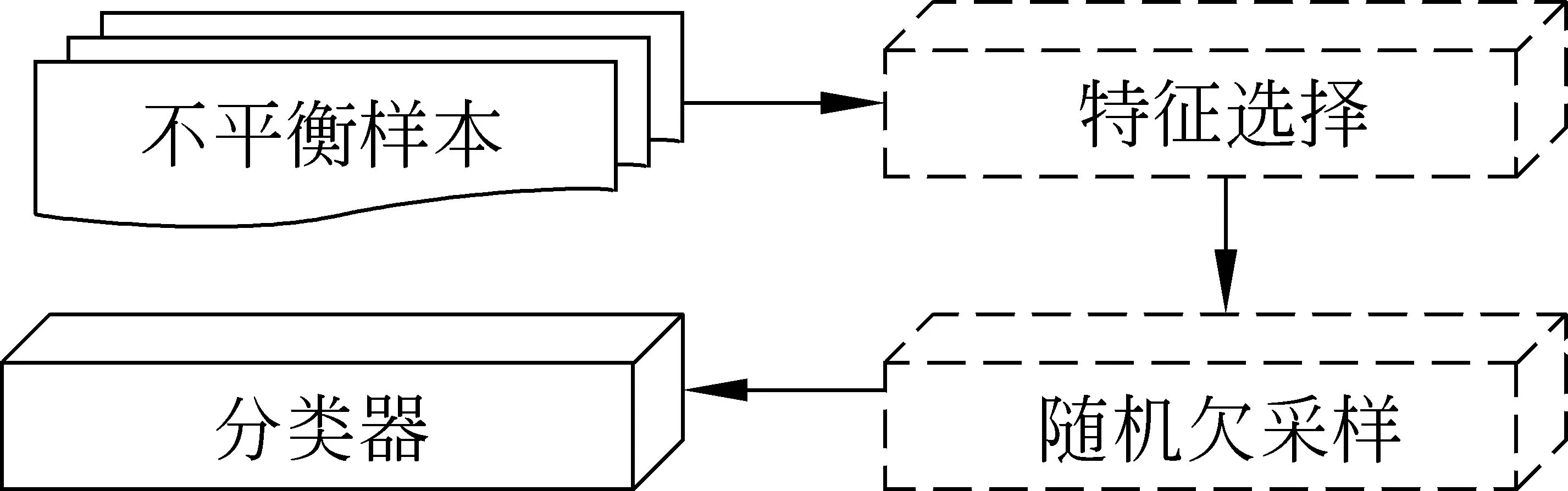
图2 先特征选择,后随机欠采样模式
3) 先单边特征选择,后随机欠采样(One-side FS+UnderS)
这种模式同上面第二种模式在处理不平衡数据和特征选择两方面有着同样的次序。但是,在特征选择过程中有所不同。具体来讲,在特征选择的过程中不但考虑截取的特征数目,同时保证所提取出特征的正负平衡性[7]。在选出的特征中,正类特征的数量和负类特征的数量相等。然后,使用随机欠采样得到平衡的训练样本。
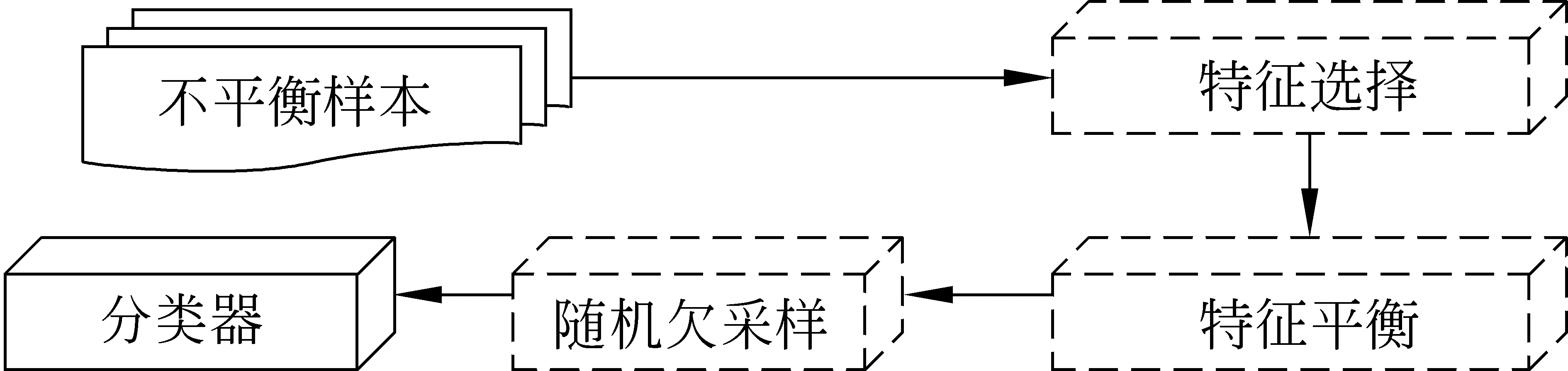
图3 先单边提取,后随机欠采样模式
4 实验
4.1 实验设置
实验数据采用卓越网收集的来自四个不同领域的中文评论语料。这四个领域分别是箱包、化妆品、相机和软件。表1给出每个领域训练样本的不平衡情况分析,其中N+代表正样本数,N-代表负样本数,N+/N+为两者的数量比:
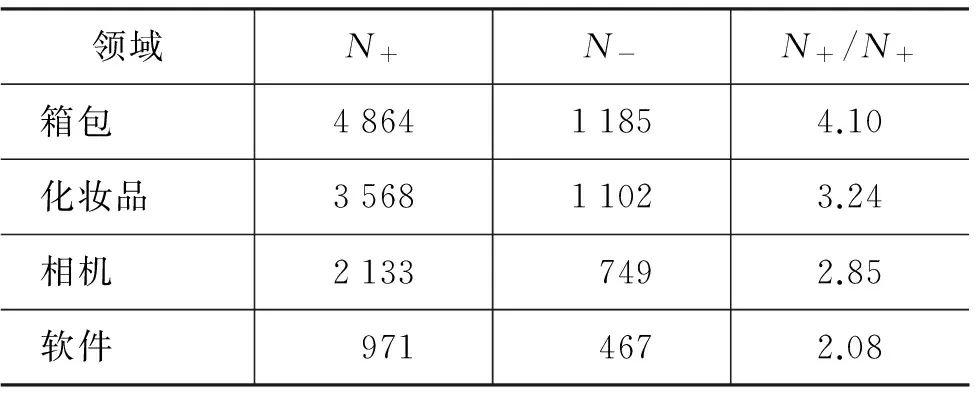
表1 各领域正负类样本分布情况
从表1可以看出每个领域里面的正样本数远远多于负样本数。此外,我们对每个领域特征的不平衡情况也做了分析。若该特征在正类样本中出现的次数多,则认为该特征是正类特征,记作T+,反之,如果该特征在负类样本中出现的次数多,那我们认为该特征是负类特征,记为T-,Tall为所有训练样本中特征总数,具体见表2。表2可以看出,不平衡情感分类问题中的特征同样存在不平衡分布情况。这也是我们提出第三种模式的研究动机所在。
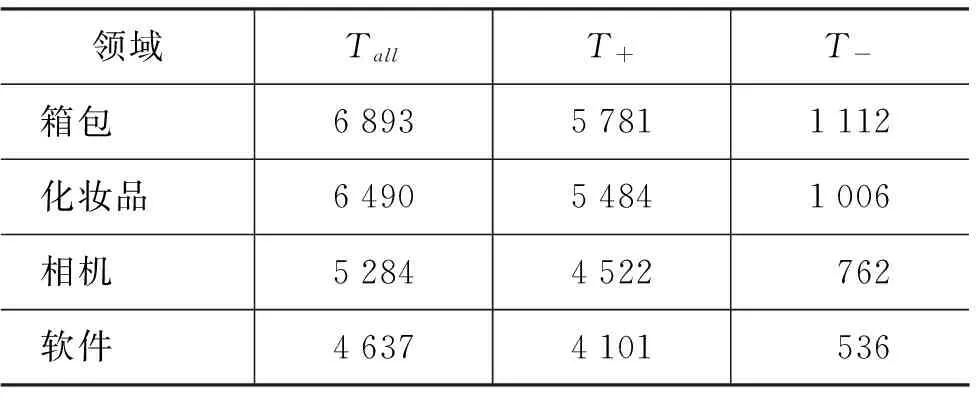
表2 各领域正负类特征分布情况
我们选择80%的样本作为训练样本,剩余的20%样本作为测试样本。分类算法为最大熵方法,具体实现是借助MALLET机器学习工具包。实验过程中,所有参数都设置为它们的默认值。
在进行分类之前首先采用中国科学院计算技术研究所的分词软件ICTCLAS对中文文本进行分词操作。给定分好词的文本后,我们选取词的Unigram作为特征,用以获得文本向量的表示。
在平衡数据的情感分类中,通常使用准确率(Acc.)作为分类效果的衡量标准。而在不平衡分类中,由于分类结果很容易偏向多类,所以使用准确率作为分类效果的衡量标准对于少类变得非常不公平。因此,一般使用几何平均数(G-mean)作为衡量分类效果的标准。几何平均数的计算方法为:
其中:TPrate和TNrate分别代表了正类样本的召回率和负类样本的召回率。
4.2 不同特征选择模式的比较
首先,我们以IG方法为基础,比较三种模式的性能表现。图4为IG在不同特征选择模式下的分类结果。其中每张曲线图中横纵坐标表示的含义相同,横坐标为特征数目,纵坐标为G-mean值。图中,除了3.3节提到的三种特征选择模式外,还加入了只基于欠采样的实验数据用于对比研究,结果表示为(UnderS)。
从实验结果可以看到: (1)图上标识的几种模式中,先随机欠采样后特征选择(UnderS+FS)模式的性能普遍表现较好,当特征数大于500时,该模式的分类效果始终处于其他几种模式之上。当特征数过低时,由于分类信息的缺乏,分类器性能偏低,低于只使用随机欠采样(使用全部特征)模式。(2)实验结果表明,当各个领域的特征数在500~1 000的范围内时,G-mean达到峰值,即特征数在这个范围内,分类器具有最佳分类效果,我们称之为理想特征数。(3)在理想的特征数范围内,IG和CHI方法拥有不俗的表现,相比只使用欠采样技术的模式,分类效果能够有3%~6%的提高。
此外,在使用其他三种特征选择方法时,存在类似的结论。因此,在后续实验中,我们选取UnderS+FS进行比较不同特征选择方法的研究。
4.3 不同特征选择方法的比较
从上一节的结果可以看出,先随机欠采样,后特征选择这种特征选择模式具有最好的分类效果,图5显示了在这种模式下DF、MI、IG、CHI等特征选择方法的结果。
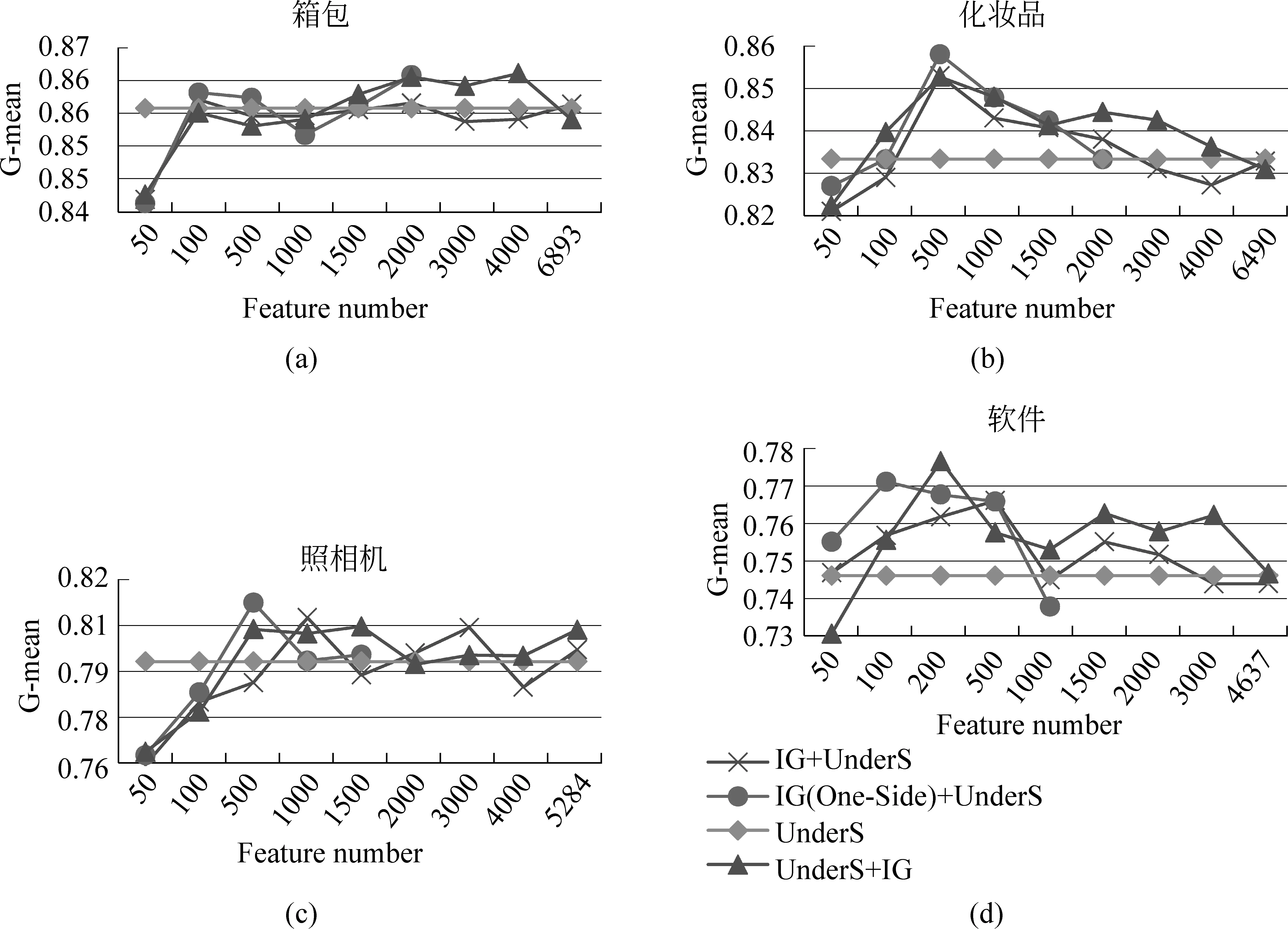
图4 IG方法下不同特征选择模式分类结果
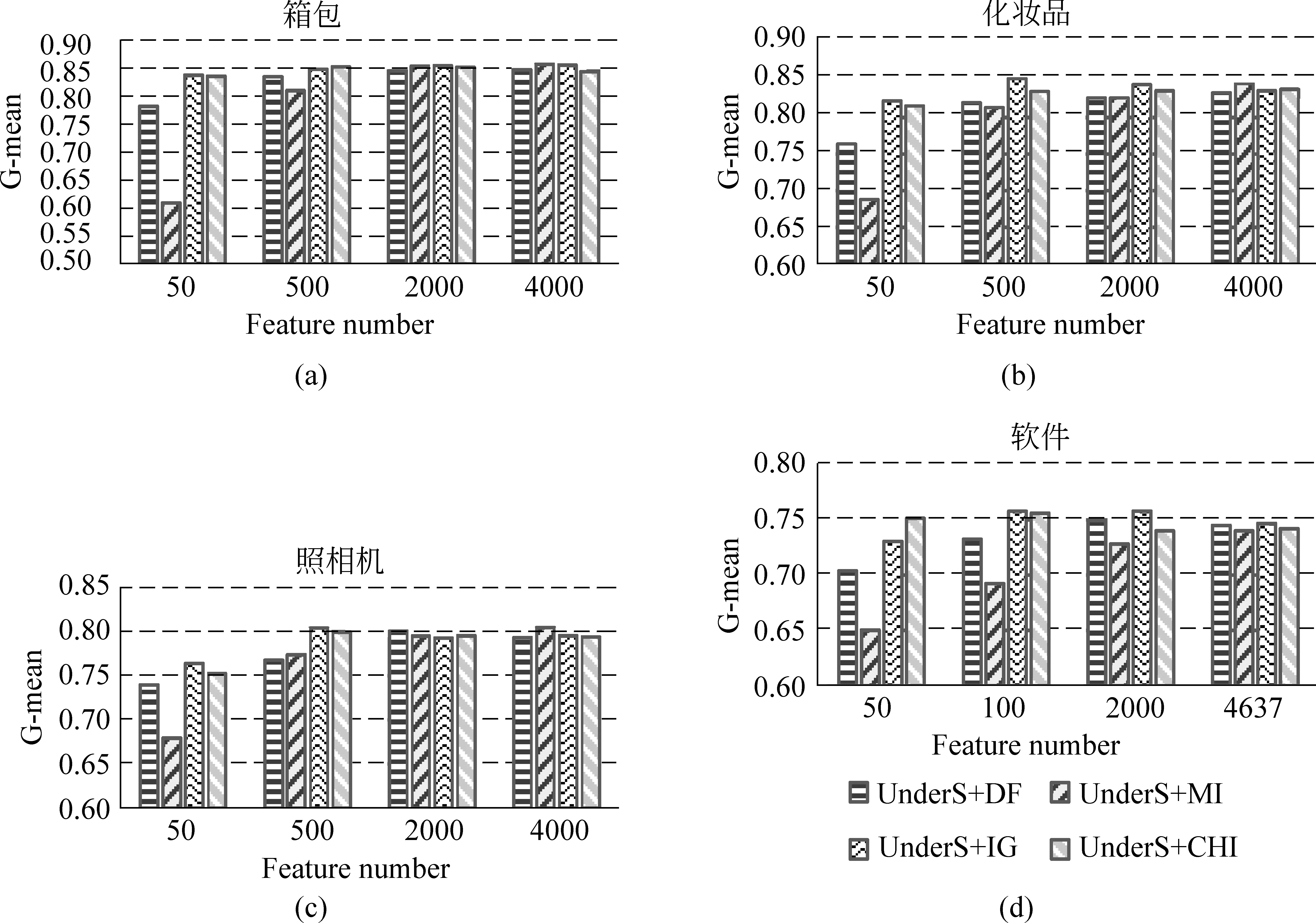
图5 特定模式下不同特征选择方法的分类效果
实验结果表明: 四种特征选择方法的分类效果基本随着特征数的增加而提高。当特征数目较少时,各个特征选择方法的分类效果差异明显,其中IG方法具有明显优势,CHI次之,MI方法则相对较差。当特征数量大于等于1 000时,几种特征选择方法性能基本不变。从此结果我们可以看出特征选择方法可以在不损失情感分类效率的前提下显著降低特征向量的维度。综合几组实验结果,IG方法相对于其他特征选择方法分类效果较好,即使在特征数小于500的情况下依然保持较高的性能。
5 结语
本文研究了不平衡情感分类问题中的特征选择方法,提出了三种特征选择模式。实验结果表明,使用先随机欠采样,后特征选择的模式的分类效果优于只采用随机欠采样方法,能很好地解决中文情感分类任务中的不平衡问题。通过比较发现,特征选择方法可以在不损失情感分类准确性的前提下显著降低特征向量的维度,提高学习效率。IG方法在几种特征选择方法中表现最好,在特征数很少的情况下也能保持较高的准确度。
关于不平衡情感分类的研究才刚刚起步,很多地方还需要我们进一步探讨。在实验中我们只应用了四种领域的语料,在下一步工作中,我们将尝试其他领域的语料,测试特征选择方法的有效性。此外,我们还将考查,在众多特征选择方法中,是否还有其他适合解决不平衡数据情感分类问题的方案,是否还有更好的特征选择模式都值得我们关注。
[1] Pang B, L Lee, S Vaithyanathan. Thumbs up? Sentiment classification using machine learning techniques[C]//Proceedings of EMNLP-02, 2002.
[2] Liu B, M Hu, J Cheng. Opinion Observer:Analyzing and Comparing Opinions on the Web[C]//Proceedings of WWW-05, 2005.
[3] Wiebe J, T Wilson, C Cardie. Annotating Expressions of Opinions and Emotions in Language. Language Resources and Evaluation, 2005.
[4] Cui H, V Mittal, M Datar. Comparative Experiments on Sentiment Classification for Online Product Reviews[C]//Proceedings of AAAI-06, 2006.
[5] Li S, C Huang, G Zhou, et al. Employing Personal/Impersonal Views in Supervised and Semi-supervised Sentiment Classification[C]//Proceedings of ACL-10, 2010.
[6] Li S, G Zhou, Z Wang, et al. Imbalanced Sentiment Classification[C]//Proceeding of CIKM-11, 2011.
[7] Kubat M. and S. Matwin. Addressing the Curse of Imbalanced Training Sets:One-Sided Selection[C]//Proceedings of ICML-97, 1997.
[8] Barandela R, J Sánchez, V García, et al. Strategies for Learning in Class Imbalance Problems[J]. Pattern Recognition, 2003.
[9] Chawla N, N Japkowicz, A. Kotcz.Editorial. Special Issue on Learning from Imbalanced Data Sets[J]. SIGKDD Exploration Newsletter, 2004.
[10] Chawla N, K Bowyer, L Hall, et al. SMOTE: Synthetic Minority Over-Sampling Technique[J]. Journal of Artificial Intelligence Research, 2002.
[11] Yen S, Y Lee. Cluster-Based UnderSampling Approaches for Imbalanced Data Distributions. Expert Systems with Applications, 2009.
[12] Li S, Z Wang, G Zhou, et al. Semi-Supervised Learning for Imbalanced Sentiment Classification[C]//Proceeding of IJCAI-11, 2011.
[13] Li S, S Ju, G Zhou. Active Learning for Imbalanced Sentiment Classification[C]//Proceedings of EMNLP-12, 2012.
[14] Yang Y. and J. Pedersen. A comparative study on feature selection in text categorization[C]//Proceedings of ICML-97, 1997.
[15] Li S, S Ju, G Zhou. A Framework of Feature Selection Methods for Text Categorization[C]//Proceedings of IJCNLP-09, 2009.
[16] 王中卿, 李寿山, 朱巧明, 等. 基于不平衡数据的中文情感分类. 中文信息学报, 2012,26(3): 33-37.
[17] Japkowicz N, S Stephen. The class imbalance problem: A systematic study[J]. Intelligent Data Analysis, 2001.
