一种频率增强的语句语义相似度计算*
2013-03-19廖志芳邱丽霞谢岳山樊晓平
廖志芳,邱丽霞,谢岳山,樊晓平
(1.中南大学软件学院,湖南长沙 410002; 2.中南大学信息科学与工程学院,湖南长沙 410075;3.湖南财政经济学院,湖南长沙 410086)
文本相似度[1]是表示两个或多个文本之间匹配程度的一个度量参数,相似度越大,说明对比的内容相似程度越高,反之越低.文本相似度计算广泛应用于文本挖掘、Web信息搜索和机器翻译等,是自然语言处理中的一个重要研究领域[2].在长文本句子相似度计算中,主要分析相同的句子并且将句子分类[1];在图像修复中,根据嵌入图像的描述文字进行修复可以达到更高的精度[3],在web内容进行搜索时,计算web页面中的语句相似度能够更加有效地推荐搜索结果[4].
当前的文本相似度计算包括词语相似度计算,语句相似度计算等,词语相似度计算是指词语之间在语义上的相似度计算,狭义地说,是指从字面上来计算两个词语之间的相似度[5],其研究方法主要包括利用语义词典以及词典中数据的树状层次结构关系,来计算词语之间的语义相似度值;其次是利用统计学中的概率分布思想,结合语料库,通过词语在语料库中出现的频率来反应词语间的相似度.第一类方法的基础是语义词典库,根据义原或者词语本身构成的树状结构,来得到词语的相似度值,这类方法的一个较明显的缺点是词典库中经常存在一些没有登录或记录的词汇.第二类方法的基础是语料库,该方法中假定当词语所在的上下文环境相似时,词语之间才是相似的.但是这个方法中的一个缺陷是有时语料库中的词语频率函数并不满足某种概率分布[6].
但是,单纯的词语之间语义相似度计算还不足以满足日常需要,人们在平常的工作生活中,接触到的通常是以文本形式出现的信息,因此,词语语义相似度计算还需要过渡到语句语义相似度计算层面上.在语义相似度计算方法中,主要包括将词性和词序结合的方法[7]、依存树法、编辑距离方法和基于HowNet的方法[8]等,我们从复杂度、词语权重信息、同义词反义词、数据稀疏、语义信息、语句结构和算法可行度进行分析发现,这些方法并不能完全满足这些因素.
在以往的文本或者长句相似度匹配中,可以通过上下文关系中推断出文本的语义,但是在短句中,由于词汇量的问题,以往的语句相似度计算法在短句中的语义相似度计算中有效性不高[9],因而文本中短句中相似度计算,如5~25个词语组成的不讲究语法的短句,已逐渐成为自然语言处理中的一个重要领域.
本文将HowNet作为语义词典库,HowNet是由董振东先生创立,HowNet的描述对象是汉语词语和英语词语所代表的概念,它揭示了概念之间以及概念属性之间的复杂关系,并以此构成一个组织庞大、内容丰富的知识库.
1 词语相似度计算
在HowNet中,词语由多个概念描述,概念由义原描述,在计算词语相似度之前,需要先计算义原之间的相似度以及概念之间的相似度.本文在计算义原相似度时将同时考虑义原距离和义原深度.
1.1 HowNet结构
HowNet中义原之间按照上下位关系构成树状结构,义原树便是本文进行语句语义相似度计算的数据结构基础,其树结构如图1所示.

图1 义原树状结构Fig.1 Sememe tree structure
1.2 义原相似度计算
按照通常的定义,义原距离定义为两个义原之间最短路径上边的条数之和.通常我们先计算义原的距离,然后再将距离函数转换成义原的相似度[5].义原相似度与义原距离满足:
1)两个义原,若其中某个义原不存在于义原树中,或两个义原在两棵不同的义原树里,此时规定,义原之间的距离为+∞.
2)两个义原同处于一棵义原树中,此时规定,义原距离等于两者之间最短路径上边的条数之和.
3)义原相似度关于义原距离是单调递减函数.
定义1 设p1,p2是两个义原,l是两个义原之间的距离,其相似度值记为f1(l),则有:

其中α>0是一个可调节的参数,指数函数的设计能够很好地满足上述三个条件.
按照通常的定义,义原深度定义为两个义原之间的最近公共父节点到义原树树根节点的层次数.义原相似度与义原深度满足:
1)义原与其本身的深度值等于该义原节点到树根节点的层次数,其相似度为1.
2)两个义原,如果均不在同一棵义原树或者其中一个义原在6棵义原树中无法找到,则规定义原深度为0.
3)义原相似度关于义原深度是单调递增函数.
定义2 设p1,p2是两个义原,T1,T2分别是该义原节点到义原树根节点所经过的义原集合,T1∩T2表示两个集合中的公共节点部分,则p1,p2之间的深度就是集合T1∩T2中元素的个数,相似度的计算公式定义如下:

其中h是义原的深度,β>0是可调节的参数.
由上文的介绍可知,义原相似度与义原距离和义原深度都密切相关,最终的义原相似度用sim(p1,p2)来表示,则有:

其中α>0,β>0分别是义原距离和义原深度的可调节参数.公式(3)表明,在计算义原相似度时同时考虑了义原距离和深度,能够更充分地利用义原树状结构中包含的义原信息.
1.3 概念相似度计算
在HowNet中,概念是由多个义原组成的知识描述语言来描述的,所以,可由义原之间的相似度计算为基础,进而得到概念之间的相似度计算.
HowNet的概念描述式中,包含第一基本义原描述式、其他独立义原描述式、关系义原描述式以及符号义原描述式这4种类型的描述.下面分别介绍如何计算这4类描述式的相似度.
1.3.1 第一基本义原描述式
概念知识描述式中的第一个义原描述式便是第一基本独立义原.这部分相似度用sim1(S1,S2)来表示,并且按照上述公式(3)进行计算,即:

1.3.2 其他独立义原描述式
其他独立义原是概念知识描述式中,在第一义原之后,关系义原或符号义原之前的所有独立的义原或具体词.这部分相似度用sim2(S1,S2)来表示,由于描述式涉及到多个独立义原或具体词,计算比较复杂,在本文中遵循以下的约定:
1)独立义原与具体词之间的相似度一般取一个较小的正数γ.
2)具体词之间的相似度,若词相同,相似度为1,若词不同,相似度为0.
3)独立义原之间的相似度按照公式(1)计算.
假设T1=(p11,p12,…,p1s),T2=(p21,p22,…,p2t)分别是概念S1,S2的其他独立义原集合.首先计算义原p1i与p2j(i=1,2,…,size(T1);j=1,2,…,size(T2))之间相似度的最大值maxk,并记录下取最大值时两个集合中的义原位置索引index1和index2,然后在独立义原集合中将位置索引值为index1和index2的两个义原删除,这时,一趟循环结束.以后的每趟循环都按上述步骤进行,直到其中某个独立义原集合个数为零为止,循环次数等于min(s,t),最终,其他独立义原描述式的相似度计算公式为:

其中s,t分别是概念S1和S2的独立义原个数,δ>0是可调节的参数,计算时一般取δ=0.2.
1.3.3 关系义原描述式
在概念的知识描述式中,含有“=”符号以及“=”符号之后其他描述符号之前的所有描述.在计算这部分相似度时,首先要进行分组,将相同key值的关系义原分为一组.
假设map1和map2分别是概念S1,S2的关系义原集合,对于map1和map2中,每一对key值相同的两个value集合list1和list2,根据“其他独立义原描述式”的sim2(S1,S2)进行计算,得到相似度值simk(k=1,…,cnt),其中cnt表示相同key值对的个数.最终sim3(S1,S2)的计算公式为:

其中size表示map1与map2的键值对个数之和,δ>0是可调节的参数,计算时通常取δ=0.2.
1.3.4 符号义原描述式
符号义原是在概念的知识描述式中,含有#%$*+&@?!这些符号的义原.符号义原之间的相似度计算也需要先将类型相同的义原归为一组.用sim4(S1,S2)表示符号义原的相似度,其计算步骤与关系义原的计算步骤相同,计算公式按照公式(6).
根据上述介绍的计算步骤,最终,HowNet概念之间的相似度计算公式为:
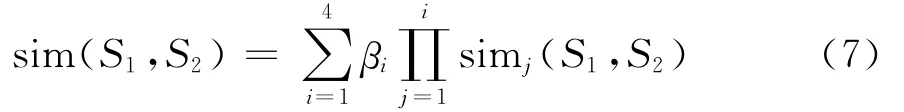
其中βi>0(i=1,2,3,4)是可调节的参数,并且β1+β2+β3+β4=1,β1≥β2≥β3≥β4,由于第一基本义原反应了概念的最主要特征,所以权值β1一般取值大于0.5.βi(i=1,2,3,4)取值逐渐变小说明在计算概念相似度时,前一种描述式对后面的描述式有约束作用,同时也体现了4种描述式对相似度值的贡献程度越来越小.
1.4 词语相似度计算
HowNet中的词语一般由一个或多个概念来进行描述.词语相似度计算可由概念相似度计算得到,以下定义3解释了最终词语相似度计算公式.
定义3 假设W1和W2是HowNet中的两个词语,W1含有m个概念S11,S12,…,S1m,W2含有n个概念S21,S22,…,S2n,则W1和W2的相似度计算公式为:

公式(8)表示,HowNet词语之间的最终相似度等于两个词语所有概念间相似度的最大值,将词语之间相似度计算归结为概念之间的相似度计算.
2 短句中的语义相似度计算
通过文献分析,在以前的词语相似度计算算法中,没有考虑语句中不同词语对相似度值的不同贡献,所有词语在相似度计算中的权重均为1,其计算结果缺乏合理性[10].
本文对语句相似度算法进行适当的改进,将词语在语料库中的频率函数引入到语句相似度计算中,为语句中的不同词语在计算语句相似度时赋予不同的权重.对于一个词语,如果在语料库中出现的次数越多,则其在整个语句中所占有的权重或者说对语句整体起到的作用会越低,比如“这些”、“我们”、“这个”等词语,相反,在语料库中出现次数越少的词语在语句中所应占有的权重越大.
2.1 语料库中词语的频率计算
语料库中含有大量的文本,这些文本通常经过整理,并按照一定的格式进行存储.本文采用1998年1月份的人民日报标注语料库[7](简称PFR语料库),该语料库是由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的,它被作为原始数据应用于大量的研究和论文中.
假设N是PFR语料库中收录的所有词语个数,那么,词语(word)的频率计算式为freq(word)=n/N,其中n表示词语word在语料库中出现的总次数.我们设计指数函数I(word)=e-λlog(n+1)/log(N+1),将该函数作为词语在整个语句中的权重系数引入到最终的语句相似度计算中,该函数满足如下3个条件:
条件1:I(word)关于语料库中词语的频率是单调递减函数,频率越大,I(word)值越小,反之越大.
条件2:指数函数的设计意在将权重值控制在[0,1]之间,并且也能满足条件1.
条件3:语料库中词语频率越大,该词语在语句中的权重越小,即对语句之间的语义相似度值贡献越小.
对于上述频率函数I(word),例如语句“我们这个商城的计算机价格很便宜”,在PFR语料库中,我们/2027,这个/628,商城/23,计算机/75,价格/107,便宜/25.可以看出,词语“我们”和“这个”出现的次数较多,分别为2 027次和628次.根据人们所拥有的知识,这两个词语在整个语句中所占有的语义权重应该较小,而词语“商城”、“计算机”、“价格”、“便宜”这些词语出现的次数较少,同时它们也代表着语句的主干,在整个语句语义中占有较重要的地位,本文中设计的词语频率函数正好符合这一规律.
2.2 短句中语义相似度计算实现
目前的语句相似度计算算法中,由于没有分别考虑语句中不同词语对相似度的不同贡献,导致语句相似度计算结果存在一定的不合理性.例如,对于相似性较高的语句,其计算结果值偏低,而对于相似性较低的语句,其计算结果值却偏高.为了更好地解决这个缺陷,本文将2.1中介绍的词语频率函数引入到语句相似度计算公式中.
定义4 设Sen1,Sen2是两个待计算相似度的中文语句,如果Sen1中有m个词语W11,W12,…,W1m,Sen2中有n个词语W21,W22,…,W2n,那么语句Sen1和Sen2之间的语义相似度计算公式为:

其中I(W)=e-λlog(num+1)/log(N+1),num表示词语W在PFR语料库中的次数,N表示PFR语料库中词语的总数.s等于W1i与W2j(j=1,…,n)取相似度最大值时j的值,t等于W1i(i=1,…,m)与W2j取相似度最大值时i的值,λ>0是可调节的参数.

公式(9)表示,语句之间的相似度值最终由词语之间相似度加权构成.频率函数I(w)的值决定着词语w对语句相似度值的贡献度大小,I(w)越大,表明词语w在语句相似度值中所占的比重越大,反之越小.
在利用公式(9)进行语句语义相似度计算之前,需要对语句进行分词操作.本文采用开源的paoding中文分词组件对语句进行词语切分,paoding分词具有速度快、分词准确率高等优点,能够较好地满足本文中对分词的要求.
本文在综合考虑义原距离和深度的条件下计算义原相似度,进而计算概念相似度,然后计算词语相似度.在语句相似度计算改进部分,本文引入了语料库,为每个词语在语句相似度计算时赋予了不同的权重,充分体现了不同词语对相似度值的不同贡献程度,最终语句相似度的计算结果更为合理,同时也与人们的主观判断更为接近.至此,本文研究了以HowNet为语义词典库,来进行语句语义相似度计算的所有细节以及最终的计算公式.
3 实验及分析
本文使用3种方法来对算法进行比较分析.
方法1:在计算词语的相似度时,仅使用How-Net概念表达式中的第一独立义原.即sim(S1,S2)=sim1(p1,p2)=α/d+α,其中d是两个义原之间的距离,α>0是可调节的参数.
方法2:刘群、李素建等[8]提出的一种词语相似度计算方法,在计算时只考虑义原距离,未考虑义原深度.
方法3:本文中介绍的改进的计算方法.
1)实验素材
①HowNet提供的词库文件glosarry.dat,义原树状结构文件WHOLE.DAT.
②HowNet提供的一部分计算接口.
③反义词、近义词文件作为数据集.
④paoding中文分词组件.
⑤1998年1月份的人民日报语料库文件.
2)参数设置
方法1:α=1.6.
方法2:α=1.6,β1=0.5,β2=0.19,β3=0.16,β4=0.15.
方法3:α=0.125,β=0.956,λ=0.1,βi(i=1,2,3,4)取值同方法2.
3.1 词语相似度实验与分析
利用上述3种方法,采用下载的常用中文反义词120对,近义词133对,对词语进行相似度计算.
3.1.1 反义词的相似度计算
从表1中可得到,方法3中反义词的相似度(Antonyms Similarity,简称AS)是最小的,同时通过对120对反义词实验数据统计,将相似度区间分为4个,图2显示了在每个相似度区间取值时,反义词对的数量.图中方法1,2,3中的4个立柱分别区间为1,[0.8,1),[0.5,0.8)和[0,0.5),从图中可知,方法1和方法2在相似度大于0.5时分别有93对和91对反义词,约占77.5%.方法3在同样的区间段只有23对反义词,约占19%,而且81%的词语相似度小于0.5.图中可直观地看出方法3的计算结果是最合理的.

表1 反义词对相似度实验结果(节选)Tab.1 Antonyms similarity comparison
3.1.2 近义词的相似度计算

图2 反义词对的实验数据柱状图比较Fig.2 The comparison of antonym

图3 近义词对的实验数据柱状图比较Fig.3 The comparison of synonyms
图3更为直观地显示了在每个相似度区间中(区间表示如图2)近义词对的个数.方法1和方法2中,相似度取值为1.0的近义词分别有114对(占85.7%)和83对(占61.6%),而在[0.8,1.0]之间取值的词对数量很少,只分别占0.15%和0.68%.对于方法3的计算结果,其计算结果为0.999的近义词数为61对(占45.8%),而在[0.8,0.98]之间取值的词对数为40(占30.1%),相对来说,方法1和方法2的结果中,大部分的近义词对相似度(Synonyms Similarity,简称SYS)计算结果等于1.0,而方法3的值却更为合理,虽然近义词是意思相似或相近的词语,但毕竟不是相同的词语,计算结果等于1.0可以说明前两种方法较粗糙.
表2对近义词对进行了相似度比较,可以看出,方法3的相似度比较更符合人们的主观判断.
从上述对反义词和近义词的词语相似度对比可看出,3种方法中,本文中采用的方法计算结果比较合理,并且与人们的主观判断也较为契合.

表2 近义词对相似度实验结果(节选)Tab.2 Synonyms similarity comparison
3.2 语句相似度实验与分析
利用上述3种方法,测试了50对语句之间的语义相似度(Sematic Similarity,简称SES)值,部分结果如表3所示.

表3 3种方法语句语义相似度实验结果对比(节选)Tab.3 Semantic similarity results of three methods
由表3中测试句对的实验结果可以看出,方法1和方法2的计算结果都较为粗糙,对语义相差较大的语句计算得到的相似度的结果值偏高.而本文中改进之后的方法,在计算语句相似度时,其结果与人们的主观判断更为接近.这种比较合理化结果的重要原因在于计算语句相似度时引入了词语的频率函数作为权重,充分利用了语句中不同词语的语义信息以及对语句相似度值的不同贡献程度.
同时,本文利用上述3种方法中的50对语句,每对语句重复执行100次相似度计算的过程,并记录了每种方法所需要的时间,最后分别计算50对语句平均执行100次的时间,图4为时间柱状图,纵轴以s为单位,方法3每对语句执行100次平均只需3.252s,很好地降低了算法前后所需的时间,提高了时间效率.
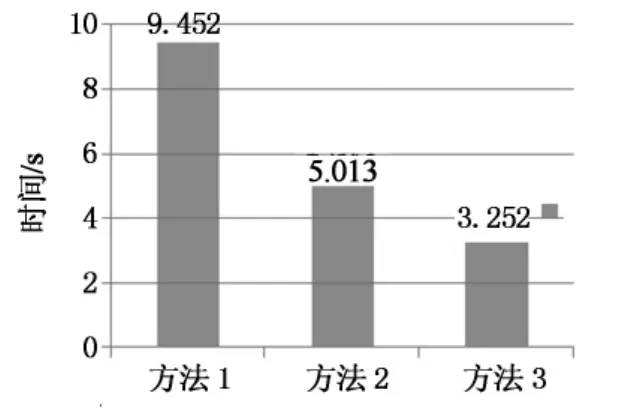
图4 3种算法时间复杂度对比Fig.4 Comparison of time complexity
4 结 论
本文以HowNet为语义词典库,介绍了How-Net中义原相似度计算、概念相似度计算以及词语相似度计算的细节和公式.最终,以此为基础,研究了改进的语句语义相似度计算.在对语句相似度算法改进时,将词语在语料库中的频率函数作为权重系数加入到计算公式中.语料库中词语出现的频率越大,对语句整体所起的作用越小,反之则越大,这个规律与人们日常的观念也相符合.本文改进的算法在一定程度上解决了目前基于HowNet的语句相似度算法中存在的计算结果不合理现象.最后,通过三种方法的对比实验证明,改进后的语句相似度计算方法更合理.
[1] ALIGULIYEV R M.A new sentence similarity measure and sentence based extractive technique for automatic text summarization[J].Expert Systems with Application,2009,36(4):7764-7772.
[2] 涂承胜,鲁明羽,陆玉昌.Web内容挖掘技术研究[J].计算机应用研究,2003,20(11):5-9.TU Cheng-sheng,LU Ming-yu,LU Yu-cang.Web content mining technology[J].Computer Application Research,2003,20(11):5-9.(In Chinese)
[3] CHIANG J H,YU H C.Literature extraction of protein functions using sentence pattern mining[J].IEEE Transactions on Knowledge and Data Engineering,2005,17(8):1088-1098.
[4] KO Y,PARK J,SEO J.Improving text categorization using the importance of sentences[J].Information Processing and Management,2004,40:65-79.
[5] LIN De-kang.An information-theoretic definition of similarity semantic distance in wordnet[C]//Proceedings of the Fifteenth International Conference on Machine Learning.1998:296-304.
[6] 田久乐,赵蔚.基于同义词词林的词语相似度计算方法[J].吉林大学学报,2010,28(6):602-608.TIAN Jiu-le,ZHAO Wei.Words similarity algorithm based on tongyici cilin in semantic web adaptive learning system[J].Journal of Jilin University,2010,28(6):602-608.(In Chinese)
[7] 车万翔,刘挺,秦兵,等.基于改进编辑距离的中文相似句子检索[J].高技术通讯,2004(7):15-19.CHE Wang-xiang,LIU Ting,QIN Bing.Similar chinese sentence retrieval based on improved edit-distance[J].High Technology Letters,2004(7):15-19.(In Chinese)
[8] 刘群,李素建.基于《知网》的词汇语义相似度计算[C]//第三语义学研讨会论文集.台北:台北中央研究院,2002:149-163.LIU Qun,LI Su-jian.How net-based lexical semantic similarity calculation[C]//Third Semantics Workshop Proceedings.Taipei:Academia Sinica,2002:149-163.(In Chinese)
[9] AMINUL Islam,DIANA Inkpen.Semantic text similarity using corpus-based word similarity and string similarity[R].Ottawa,Canada:University of Ottawa,2008.
[10]LIAO Zhi-ning,ZUHAIR A.Bandar,James D.O’Shea,Keeley Crockett.Term-based approach for semantic similarity of short texts[R].Manchester,England:Manchester Metropolitan University,2012.
