汉语-维吾尔语的一对一词对齐研究
2012-11-14张亚军贺琛琛
张亚军 贺琛琛
(1.昌吉学院计算机工程系 新疆 昌吉 831100;2.昌吉学院人事处 新疆 昌吉 831100)
1 引言
词语的对齐(简称词对齐,Word Alignment)研究是自然语言处理的一个重要组成部分,词对齐分为三类:一对一、多对一、多对多。其目的是要找出从源语言的字符串和目标语言的字符串之间的词对齐。词对齐对于平行语料库、语料数据挖掘等方面尤为重要。同时,词对齐还可以为双语词典、语音识别、信息检索提供源材料。英语和汉语词对齐研究相对成熟,基本精度在90%以上,取得的召回率约88%。然而汉语-维吾尔语(简称汉维)词对齐的研究,处于前期研究阶段。
研究词对齐方法主要有两类:
(1)基于语言学的方法:充分使用各种语言学的资源进行词对齐研究。例如利用统计和词典相结合的方法进行的词对齐[1];或者利用语言学比较的方法进行词对齐等[2]。
(2)基于统计的研究方法:其思路是通过对平行语料库的统计性训练,取得双语对应词的同现概率作为词对齐的基础,主要方法有Brown提出的基于信源信道模型方法实现的词对齐[3];Dagan等人对Brown的模型进行改进的词对齐[4];Gale、Piao、Okita都使用互信息和X2检验方法进行词对齐[5][6][7]等。
基于统计方法实现汉维一对一的词对齐是本文研究的重点内容。
2 词对齐模型描述
2.1 基于信源信道模型的统计方法
信源信道思想应用于统计机器翻译,实际上可以理解为一个解码的过程,此时把翻译系统视为信源信道,即对于一个目标语言字串S,将寻找一个最大可能的源语言句子T,搜索概率P(T|S)最大值的过程。 由贝叶斯公式:
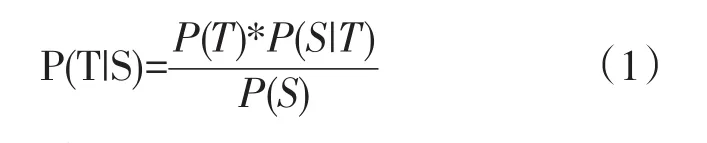
其中P(T)为语言模型,P(S|T)为翻译模型。
由于式(1)右边P(S)与T无关,因此,求上式的最大值等同于求等式右边分子的最大值即:
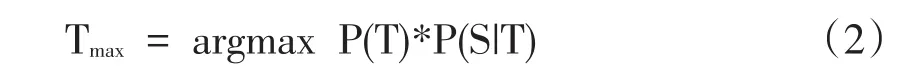
2.2 IBM模型1和模型2
大量的参数训练是词对齐的基础工作,由此可以计算出源语言词语和目标语言词对齐的概率,从而搜索出概率最大值。本文采用EM(期望最大化)算法实现的IBM模型1和模型2。
IBM模型1-2的单词翻译概率公式相同,计算公式如(3)所示:
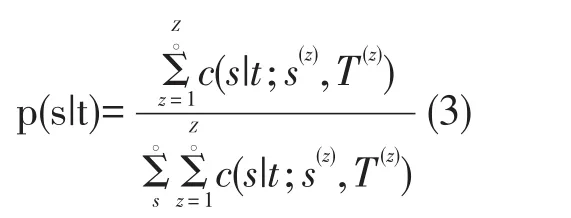
其中c(s|t;S(z),T(z))表示目标语言的单词t在翻译句对(S|T)中与源语言的单词s对齐的期望次数,s表示源语句中的词语,t表示目标语句中的词语。Z表示语料库中句对个数。
IBM模型1-2不同的是目标语言的单词t在翻译句对(S|T)中与源语言的单词s对齐的期望次数。模型一对齐期望次数如(4)式所示:

其中m表示源语言长度即源语言中词语的个数;len表示目标语言长度即目标语言中词语的个数;p(s|t)是目标语言单词与源语言单词翻译概率;δ是Kronecker函数,当它的两个参数相同时,δ=1,否则δ=0。
由于模型1忽略了单词出现在句子中的位置,模型2在模型1基础上不再假设每一个源语言词语与目标语言词语之间有相同的对齐概率,而是考虑了目标语言句子的不同位置和不同句对长度的影响,可能导致任意两个对位存在不同的概率,由此引入对位概率p(aj|j,m,l)。模型二对齐次数如(5)式所示:
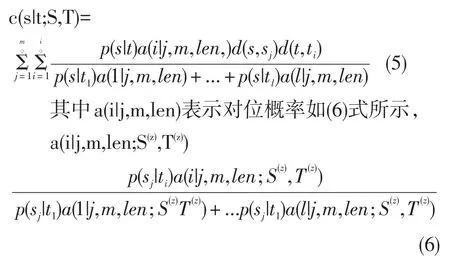
3 汉维一对一词对齐
3.1 系统处理流程
系统流程如图1所示,模型1和模型2是研究的重点。
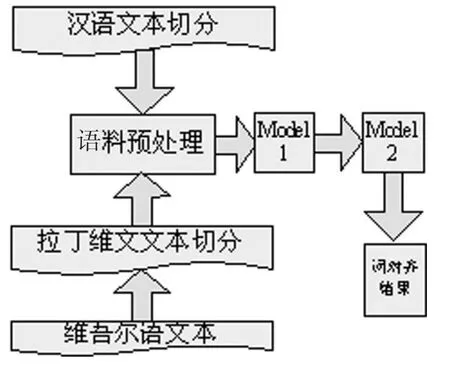
图1 汉维一对一词对齐流程
3.2 语料预处理
实验要求选取平行语料库中的语料,本文选取汉语语料和维吾尔语语料。具体要求有:将汉语语料和维吾尔语语料分别存放于格式为txt的两个文本,文本中的每一行都是一个独立的句子,且汉语文本及维吾尔语文本的相同行为互相对应的一个句对。
例如:
中文文件

维文文件

汉语词语切分利用中国科学院计算技术研究所提供的中文分词工具ICTCLAS处理。维吾尔语切分工具由新疆大学多语种信息重点实验室提供。在词语对齐训练过程当中发现对齐结果受到个别拉丁维文字符的影响,采取的方案是将其转化为无歧义可以识别的字符来处理。例如é转化为E、ü转化为U、ö转化为O等。例如:
拉丁维文:

转换个别字符后的拉丁维文:

3.3 一对一对齐步骤与算法
3.3.1 一对一对齐步骤
(1)语料预处理:将汉文词语分词,维文转化为拉丁维文并将个别字符转化为无歧义可以识别的字符;
(2)IBM模型1实现汉维词对齐:以源语言文本和目标语言文本作为输入文件,初始化单词概率分布P(S|T),计算目标语言的单词t在翻译句对(S|T)中与源语言的单词s对齐的期望次数,迭代修正单词翻译概率。
(3)IBM模型2实现汉维词对齐:在考虑了目标语言句子的不同位置和不同句对长度因素下,以模型1最终修正的单词翻译概率为初始值,计算对位概率a(i|j),不断迭代修正单词翻译概率。
3.3.2 对齐算法
算法主要步骤如下
St1:设输入预处理后的维吾尔语文本S=S1S2S3…Si… SZ,Si为源文件,汉文文本 T1T2T3…Ti…TZ,Ti为目标文件;
St2:初始化单词概率分布p(s|t);
St3:对于每一个句对(S(Z),T(Z)),计算期望次数c(s|t;S(Z),T(Z));
St4:对于每一个至少出现在一个目标语言句子中的单词t计算同时对每一个至少在一个源语言句子出现的单词s,计算得出新的单词对位概率值p(s|t);
St5:重复St3和St4,直到迭代完毕,结束模型1算法;
St6:将模型1修正后的单词对位概率值作为模型2的初始值,并引入对位概率a(i|j,m,l)赋予初始值;
St7:对于每一个句对(S(Z),T(Z)),计算期望次数c(s|t;S(Z),T(Z))和 c(i|j,m,l;S,T);
St8:对于每一个至少出现在一个目标语言句子中的单词t计算同时对每一个至少在一个源语言句子出现的单词s,计算得出新的单词对位概率值p(s|t)和新的对位概率值a(i|j,m,l);
St9:重复St7和St8,直到迭代完毕,结束模型2算法。
4 对齐结果与分析
本文平行语料库由新疆大学信息学院多语种信息技术重点实验室提供。语料库中整理了汉维相对应的10000句对。从中抽出本实验所需的汉维相对应331个句对,其中这331个句对中的词都是一对一的对齐方式。
4.1 模型实现
(1)通过上述一对一汉维词对齐步骤,本文实现了一个可以在windows下运行的汉维词语对齐模型系统。本系统的核心代码是采用visual studio 2010平台下的C#编写,主要采用数据库访问的方式存取数据,运行界面如图所示。
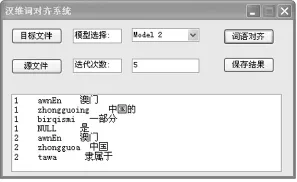
图2 运行界面
(2)为对比该系统的评测指标,在相同语料下,利用Giza++[7]进行了的汉维词语对齐,其中从模型1到模型2。如图3所示:

图3 Giza++词对齐结果
4.2 系统评价指标
将汉维331句对进行词对齐的人工校对,同时从Giza++结果中找出一对一的汉维词对齐作为标准测试语料。按照规定,引入了三种评测指标:
正确率=正确的对齐总数/对齐总数*100%
召回率=正确的对齐总数/实有对齐总数*100%

可以得到以下几个结论:
(1)两个模型运行测试结果

表1:Model 1和Model 2的对齐结果
(2)本系统同Giza++的词对齐相比,各项评测指标如表2所示。
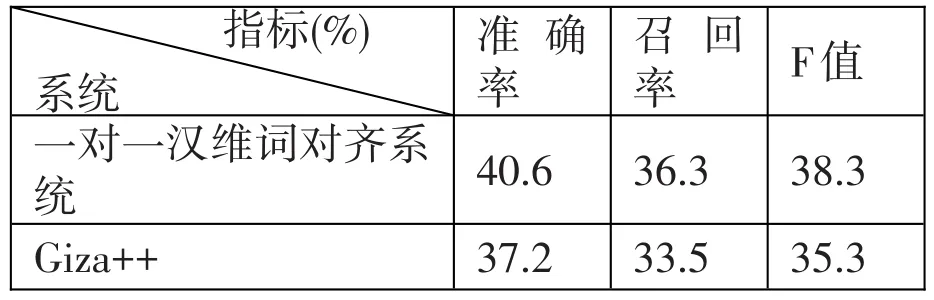
表2:与Giza++对齐结果比较
4.3 实验结果分析
从上述两个表中可以发现,正确率和召回率不高,经过总结分析,影响因素如下:
1.汉语和维吾尔语在切分过程中容易出现切分错误,在词对齐时会导致错误放大。
2.汉语和维吾尔语的句法结构不同。汉语属于SVO语言,而维吾尔语是SOV语言。
3.汉语无形态语言,而维吾尔语为形态丰富的语言。维吾尔语中有明显形态标志的格,大部分出现在句子的末尾,最多可能出现四种形态标记。
4.本实验中选取的语料规模较小,部分词语可能未能够覆盖。
5.模型2的效果比模型1好。但是同Giza++相比较,若使用基于信源信道模型的统计方法来解决一对一词对齐,后者的效果较好。
5 总结
论文的主要研究工作是基于统计机器翻译的一对一汉维词对齐方面。通过测试,本方法基本达到实验效果,同时也为后续其他词语级对齐打下基础。
目前,本系统设计主要考虑了IBM模型1-2实现了一对一词对齐。但是当我们观察一些实际翻译例子时发现,很多情况下句对中的词语为一对多、多对一、多对多。因此,在今后的工作中,首要研究如何实现汉语和维吾尔语一对多、多对一和多对多的对位关系;其次要考虑两种句法结构相差大的语言上的句子结构。
[1]邓丹,刘群,俞鸿魁.基于双语词典的汉英词对齐算法研究[J].计算机工程,2005,(8):31-16.
[2][Huang,2000]Jin-Xia Huang,and Key-Sun Choi.C-hinese-Korean word alignment based on linguistic c-omparison[C].In:Annual Meeting of the Association for Computational Linguistics,2000.392-399.
[3]Brown P F,Della Pietra S A,Della Pietra V J,et al.The Mathematics of Statistical Machine Translation:Parameter Estimation[J].Computational Linguistics,1993,19(2):263
[4][Dagan,1993]Dagan L,Chunch K,et al.Robust bilingual word alignment for machine aided translation[A].Proceedings of the W orkshop on Very Large corpora:Academic and Industrial Perspectives[C],C olumbus,1993.1-8.
[5][Gale,1991]Gale,W.and Church,K.Identifying W ord Correspondences in Parallel Texts[A].Proceedings of the 4th DARPA Speech and Natural LanguageWorkshop[C],Pacific Grove,CA,1991.152-157.
[6]Piao,Scott.Word alignment in English-Chinese parallel corpora.Literary and Linguistic Computing,2002,17(2).pp.207-230.
[7]Okita,Tsuyoshi.Word alignment and smoothing methods in statistical machine translation:Noise,prior knowledge and overfitting.Dublin City University School of Computing,2012.
