公司运营危机预警模型的比较研究
——以中国上市公司为例
2012-10-25李同正孙林岩冯泰文
李同正,孙林岩,冯泰文
(西安交通大学 管理学院,陕西 西安 710004)
公司运营危机预警模型的比较研究
——以中国上市公司为例
李同正1,孙林岩2,冯泰文3
(西安交通大学 管理学院,陕西 西安 710004)
研究当前国内外公司运营危机预警问题的现状,首先要寻找一套适合于我国上市公司的财务状况识别指标体系,然后依据该指标体系采用不同方法建立运营危机预警模型,最后利用样本公司实际指标数据对各个模型的短期及中期预警效果进行比较分析与实证研究。结果表明,分类树模型的三年期预警准确率都在80%以上。
运营危机预警;判别分析;logistic回归;BP神经网络;分类树
公司经营状况的好坏往往是企业经营者、投资者、债权人和审计师关注的焦点。致使公司陷入经营困境的原因是多方面的,既可能是企业经营者决策失误,也可能是管理失控,还可能是外部环境变化等。由于影响企业出现运营危机的因素很多,大多企业管理当局局限于各种主客观因素,对出现危机的潜在信息不能及时发觉。对于预警模型的构建,目前采用较多的方法是判别分析、logistic回归和神经网络。本文将在比较运营危机预警模型构建方法的基础上,对各个模型的短期及中期预警效果进行比较分析与实证研究。
一、分类树与回归树介绍
分类树是一种基于统计理论的非参数识别技术,其特点在于既保持了多元参数、非参数统计的一些优点,又克服了其不足。其表现为:自动进行变量的选取,降低维数;充分利用先验信息处理数据间非同质的关系;分类结果表达形式简单易于解释,并可有效地用于对数据的分类[1,2]。分类树分析的一般性思路:在整体样本数据的基础上,生成一个层次多、叶结点多的大树,以充分反映数据之间的联系,然后对其进行删减,产生一系列子树,参照一定规则从中选择适当大小的树,用于对新数据进行分类[3,4]。
(一)分类树的建立
分类树的目标是产生一系列规则,对那些只知道属性变量值的样本进行正确分类。分类树的算法:按照特定规则逐个检验每个属性变量,看它们对不同类别样本的判别情况,之后选择对正确分类提供信息量最大的变量将样本集合分为2个子集。这个过程递归地应用于每个子集,直到达到止停点(如每个样本都被正确分类)。在对样本进行分类时,分类规则采用二叉树形式,对于连续变量Xi:表示为{Xi|Xj>C吗?C为样本空间中变量Xii的取值范围内的一个常数,i= 1,…,m,m为连续变量个数};而对于离散变量Xij:表示为{Xij|Xij∈V?V为样本空间中变量Xii所有可能取值集合U的某个子集,,j=1,…,n,n为离散变量个数}。据此样本对分类规则“是”或“否”的回答将这个节点分为左右2个子节点。
图1中X为样本集合,大写字母A、B、C表示不同的样本类别,( )为非叶节点,[ ]为叶节点,Si表示分类规则,最终结果:XA=X7∪X9∪X5,XB=X4∪X11,XC=X10∪X12。树上表现出的变量通常只是变量指标集中的一部分。分类树的一个优点是它能提供易于理解的分类规则。每个叶子相当于一个分类规则。

图1 分类树模型的一般表示形式
(二)分类树的删减和选择
现实生活中的数据会含有一些噪声,故训练样本所确定的分类树结构不能完全正确判别所有类别的样本。另外,当分类树的层数和叶节点较多时,其可读性比较差,不易理解。因此需要对原始树进行删减,去掉那些仅反映数据间特殊关系的树枝。分类树删减算法包括渐进删减算法、最优删减算法(OPT)及其变形。
其中OPT算法是基于动态规划的一种递归删减算法,其主要用于实现概念简化的功能,同时减少噪声影响;它能够产生一系列比较密集的删减子树从而扩大选择的范围。OPT算法或类似变形的目的是产生Tmax的最优删减树序列S0。此算法首先生成几乎为叶节点的很小的子树序列,之后这些小的子树被一步步结合起来,产生越来越大的子树,由之继续构成T0的子树序列。直到最终形成大树Tmax。因为每一个T的子树又都是由它自己的最优删减序列构成,因此这类算法在寻求全局最优。其缺点在于它的时间复杂度仍然比较高。
二、样本公司和指标变量的选择
(一)样本公司的选择
本文的研究对象是中国上市公司,为研究方便将沪深两地证券市场的ST公司界定为处于运营危机中的公司。
本文选择样本时,从2005年被宣布特别处理的公司中选取了32家ST公司及与之相对应(与ST公司同行业、资产总额大体相等)的32家非ST公司共64家公司作为研究样本。样本被分为训练样本和检验样本两组,训练样本包含16家ST公司和对应的16家非ST公司,检验样本包含16家ST公司和对应的16家非ST公司。研究所选取的财务数据是这些公司被宣布特别处理前三年的财务数据,32家非ST公司的数据按照对应的ST公司财务数据选取的年度选取,因为ST公司是在2005年被宣布特别处理的,其选取数据的年份为2004年、2003年和2002年,其对应的非ST公司选取数据的年份也为2004年、2003年和2002年。数据来源于深圳市国泰安(GTA)信息技术有限公司中国上市公司财务数据库。
(二)指标变量的选取
根据企业破产理论和数据可得性原则,同时借鉴前人相关的研究成果,本文分别从短期偿债能力、营运能力、长期偿债能力、盈利能力、风险水平、股东获利能力、现金流量分析和发展能力等八个方面选择了42个财务指标(见表1)。这些指标的选取原则以能全面、准确地反映公司财务状况为基础,充分借鉴了国内外这一领域的前期研究成果,如A ltman的Z-Score模型采用的预测变量,Robert、Mark、张玲[5]和姚靠华[6]等在其研究中采用的指标。
三、分类树模型的建立与比较
分类树分析在计算过程中自动选取变量,避免了主观因素的影响。在公司运营危机预警过程中存在两类错分成本:第一类错误是将有运营困难的公司预测为正常,第二类是将正常公司预测为处于运营困境中的公司。分类树分析可以将两类成本设置成不同的数值,以满足不同利益相关者的需要。分类树分析的这些优点保证了其在构建运营危机预警模型时的有效性。
在本文的研究中,令ST公司为1,非ST公司为0,得到目标变量(Target Variable);将选定的42个变量作为预测变量(Predicator Variable)全部纳入模型,分类方法采用Gini法,两类错分成本的数值相等。
(一)短期预警
所谓短期预警是指根据2003年或2004年的公司财务数据对公司2005年的经营状况进行预警,预警期限为1年或2年。

表1 预警指标集

表2 2004年判别分析模型结果

表3 2004年logistic回归模型结果

表4 2004年BP神经网络模型结果
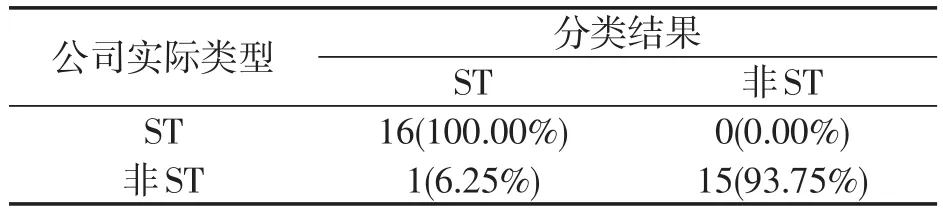
表5 2004年分类树模型结果
四种模型的1年期预警准确率分别为87.50%、65.63%、84.37%和96.88%,判别分析模型、BP神经网络模型和分类树模型的预警准确率都达到了80%以上。
四种模型的2年期预警准确率分别为62.50%、65.63%、68.75%和90.63%,分类树模型的预警准确率远高于其他三个模型。
(二)中期预警
所谓中期预警是指根据2002年的公司财务数据对公司2005年的经营状况进行预警,预警期限为3年。

表6 2002年判别分析模型结果
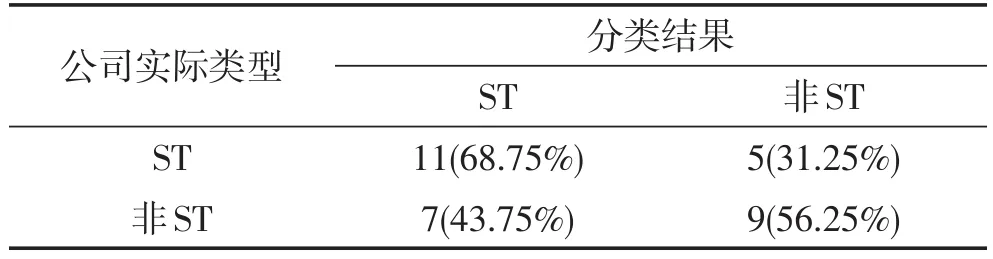
表7 2002年logistic回归模型结果

表8 2002年BP神经网络模型结果
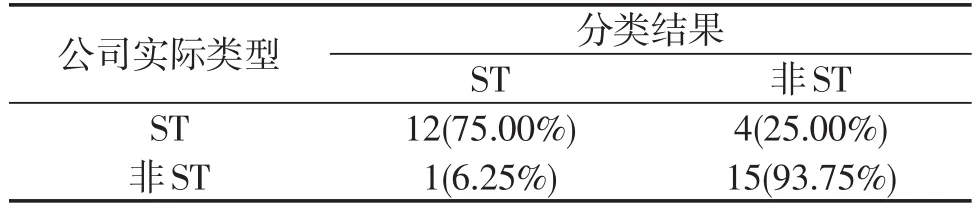
表9 2002年分类树模型结果
四种模型的中期预警准确率分别为62.50%、62.50%、 68.75%和84.38%,分类树模型的预警准确率仍在80%以上,表现出较好的中期预警效果。
四、结论
通过以上42个指标体系建立分类树模型来进行中国上市公司运营危机预警分析是可行的。分类树模型与其他模型相比预警的准确率都比较高,说明分类树模型更有效;预警准确率都随时间长度的增加而降低;在建立分类树模型时,对分类结果起决定作用的指标主要有利息保障倍数、营业收入净利润率、总资产净利润率、财务杠杆系数、经营杠杆系数和每股收益。
对于公司预警模型的研究还可以在以下几方面进行深入探讨:
(1)建立有效的指标体系。国内企业预警研究用到的指标来自定性研究,一般都没有经过主成分分析或时差检验,很难符合最小完备集的要求。
(2)加入非财务变量。Lee等证明,台湾上市公司治理结构与经营困境相关。姜秀华等认为,弱化的公司治理是中国上市公司陷入危机的重要因素。可见,公司治理与经营困境关系的研究备受关注,但有关治理变量的选择及其他因素的影响尚值得研究。
(3)分析企业陷入经营困境的影响因素,为中国公司避免经营困境提供建议。
(4)定性研究与定量研究相结合。目前,大部分研究集中于指标处理方法和预警模型等定量研究,少数关于预警原理的研究缺乏深度。尚玉钒和席酉民研究了企业文化管理与企业预警的关系,为研究财务预警提供了新思路。
(5)开展对预警系统的评价研究。大部分研究忽视对预警模型或预警系统结论的检验,尚缺乏关于预警系统评价的研究。
[1]Altmen E.,Fraydman H.,Kao E.D.Introducing recursive partitioning for financial classification: the case of financial distress[J].Journal of Banking and Finance,1985,(2):269—291.
[2]Breiman L.Technical note:some properties of splitting criteria[J].Machine Learning,1996,(1):41—47.
[3]Bohance M.,Bratko I.Trading accuracy for simplicity in decision tree[J].Machine Learning,1994,(3):233—250.
[4]Mark E. Z. Methodological Issues Related to the Estimation ofFinancialDistressPrediction Models[J]. Journal of Accounting Research,1984,(22):59—82.
[5]张玲.财务危机预警分析判别模型及其应用[J].预测,2000,(6):38—40.
[6]姚靠华,蒋艳辉.基于决策树的财务预警[J].系统工程,2005,(10):102—106.
F83
A
1007-905X(2012)06-0052-03
2012-03-07
1.李同正,男,河南人,西安交通大学管理学院博士研究生;2.孙林岩(1955— ),男,河北景县人,管理学博士,西安交通大学管理学院副院长,教授,博士生导师,研究方向为制造战略、工业工程。
责任编辑 姚佐军
