基于用户特性的搜索引擎查询结果缓存与预取
2012-10-15马宏远
马宏远,王 斌
(1.中国科学院 计算技术研究所,北京100190;2.中国科学院 研究生院,北京100049)
1 引言
据中国互联网信息中心(CNNIC)研究报告显示[1],截止到2009年12月31日,中国网民达到3.83亿,其中搜索引擎使用率为73.3%,搜索引擎已经是人们获取信息的主要工具。一方面,互联网网民增多,搜索引擎工作负载变大;另一方面,互联网网页也逐年增多,其规模已经达到336亿,且仍以年增长率超过100%的速度快速膨胀,搜索引擎需要尽可能多地索引这些网页以提供准确和丰富的查询结果。在如此海量信息中,高效获取所需查询对学术界和工业界提出挑战。自本世纪初以来,随着互联网步入高速发展时期,一些搜索引擎检索系统性能优化方法先后被提出,主要有并行处理(massively parallel processing)、索引压缩(index com-pression)、索引裁剪(index prune)、倒排表跳转(list skipping)、提早结束(early termination)等技术。除此之外,缓存技术(caching)与预取技术(prefetching)作为重要的系统性能优化手段而被搜索引擎检索系统广泛采用和研究。
缓存作为有效减少响应时间和系统负载的关键技术,被广泛应用于系统性能优化。查询结果缓存通过缓存已被用户检索过的查询结果以避免再次对该结果进行排名计算带来的CPU和磁盘读开销。Markatos[2]比较动态LRU缓存替换策略以及LRU策略的若干变种和静态缓存策略的命中率,得出静态缓存策略对小容量缓存有效,随着容量增大,有效性降低。Xie[3]讨论缓存位置的影响,分别讨论客户端缓存、代理服务器缓存和搜索引擎服务器缓存技术。Fagni[4]提出静态、动态混合的缓存策略。Gan和Suel[5]提出基于查询开销的查询结果缓存方法,考虑查询频率和开销来对查询结果给予不同权重。Ozcan[6]提出基于查询稳定度的查询结果缓存方法,考虑查询在一定时期内的稳定程度来选择查询结果。Skobeltsyn[7]提出一种结合索引裁剪技术的查询结果缓存方法。查询结果预取是通过预测follow-up查询[7],提前取得查询结果。Lempel[8]根据查询自身特性,建立follow-up查询页码分布,提出了一种基于该分布的查询结果预取方法。Fagni[4]通过分析查询请求页码对follow-up查询的影响,提出一种基于当前请求查询页码的自适应查询结果预取方法。对于Web缓存预取[9],主要是通过分析用户访问URL顺序来预测访问路径,以预取用户数据。
与以往研究不同,我们根据用户特性来设计查询结果缓存与预取方法,在国内某著名商业搜索引擎日志上验证了我们提出方法的有效性。本文第2节分析搜索引擎用户特性;第3节阐述基于用户特性的查询结果预测方法,给出全局和局部预测模型;第4节描述基于用户特性的查询与预取算法框架,给出算法时间复杂度和空间复杂度分析;第5节是实验结果及分析;第6节是本文结论以及未来工作。
2 搜索引擎用户特性分析
用户行为分析是系统优化的重要基石,文献[3,10-12]对搜索引擎的用户行为进行分析来开展相关工作。与以往分析工作不同,本文着重分析搜索引擎用户特性。本文数据来自于国内某著名商业搜索引擎从2006年9月1日到2006年10月31日的用户查询日志,包括近三千多万条用户查询和一亿多条用户点击记录。我们从该日志中提取了所有用户对该搜索引擎发起的查询请求,作为分析搜索引擎查询结果页浏览特性的基础。
搜索引擎系统的任务来源于数以百万甚至千万计的用户,用户根据自身的需求构造一个查询表达式提交给搜索引擎,往往不同的用户具有不同的查询浏览习惯。2006年9~10月间,该搜索引擎的用户总数约为580万。本节将从用户角度分析查询结果页浏览特性。图1(a)是在该搜索引擎用户查询日志上,统计用户浏览查询结果页数,其具有明显的长尾分布特征,44%的用户在此期间只出现1次查询,往往这些用户是系统的临时用户,而10%的用户在此期间出现查询的次数大于10。搜索引擎在做系统性能优化时,考虑小部分用户的行为特性可能对系统性能有更多帮助,譬如搜索引擎的登录用户或者查询频率贡献比较大的用户。图1(b)是在该搜索引擎用户查询日志上,统计用户浏览查询结果页码相对分布(访问查询结果第一页约占用户总查询请求的70%),可以看出页码范围越靠前的访问量递减趋势相比于相对靠后的页码范围内的访问量递减趋势要明显。
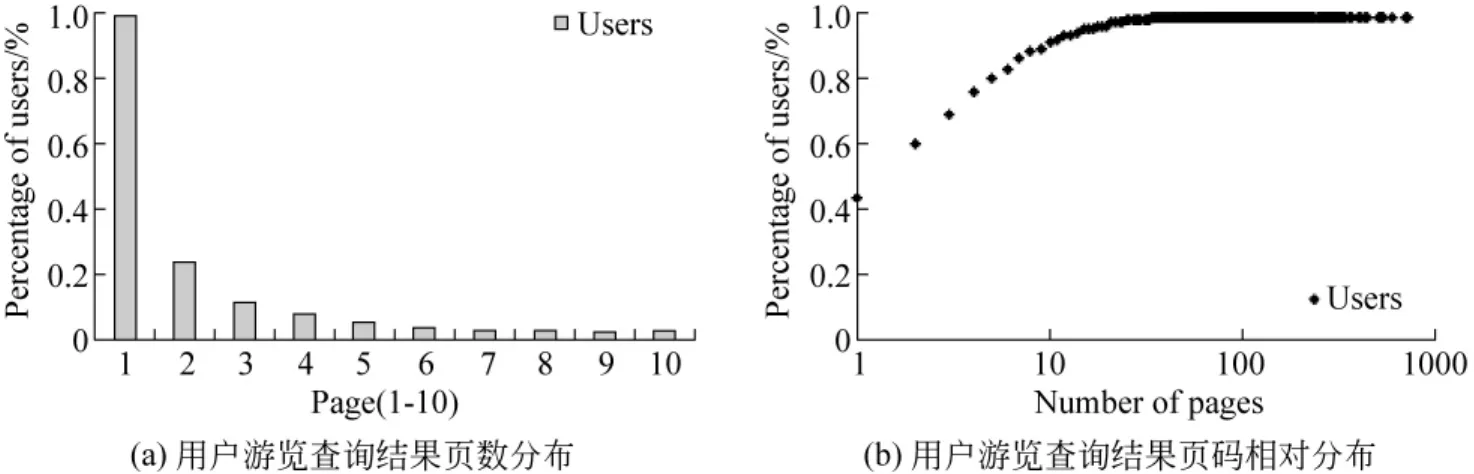
图1 搜索引擎的用户特性与查询结果浏览
当用户从搜索引擎获得部分查询结果时,会根据自身需求是否满足等情况决定是否继续浏览后续结果。当用户觉得当前查询结果页中的结果并不满意,其可能继续访问顺序靠后的查询结果页,甚至跳跃多个页前向访问;在经过一番比较后,用户可能觉得以前的某个页中的结果相对于当前页中的结果更好,这时,用户会回顾那些已经访问过的查询页中的结果或者跳过的页中的结果。根据用户的浏览行为,将用户查询请求浏览行为分为:(1)前向浏览(Vf);(2)后向浏览(Vb);(3)重复浏览(Vr)。我们将用户查询按照浏览行为分为以下5个集合:
A:只浏览第一页;
B:浏览除第一页外的页,且其浏览过程行为集合为{Vf}
C:浏览除第一页外的页,且其浏览过程行为集合为{Vf,Vr}
D:浏览除第一页外的页,且其浏览过程行为集合为{Vf,Vb}
E:浏览除第一页外的页,且其浏览过程行为集合为{Vf,Vb,Vr}
我们对该搜索引擎用户查询日志上用户发起的每个查询进行汇总。统计信息如图2所示,约70%的用户查询只访问第一页结果;对于浏览除第一页外的页的用户浏览行为分析,其中25%的用户查询存在前向浏览行为,只有约4%的用户查询具有后向浏览行为。

图2 用户浏览行为分布图
3 搜索引擎用户特性分析
3.1 相关定义
我们将搜索引擎用户集合定义为U,用户提交查询集合定义为Q,用户提交搜索查询主题集合定义为T,用户提交搜索查询页码集合定义为P,用户查询日志总查询条数定义为N。那么,用户查询日志可以表示为:


即用户查询日志中的第i条查询记录为:在时刻τi,用户ui向搜索引擎提交的查询主题为ti,查询页码为pi。用户每次提交查询页码集合可以表示为:

会话(session)是分析用户查询特征的重要因素,其划分是信息检索领域的一个主题,采用如下定义:同一用户在一定时间内带着某些固定意图而进行的查询搜索活动。假设划分后的会话总数为M,每个会话内用户u最先提交查询的时刻定义为τj,那么,特定用户u查询日志划分会话可以表示为:
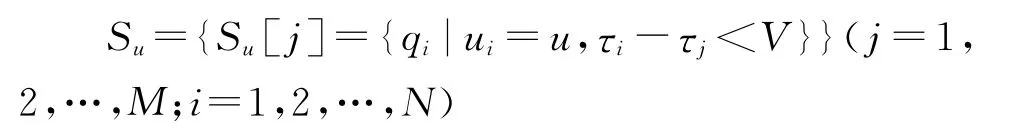
即用户u的所有会话集合Su为:给初始时刻τj,该用户后续查询时刻距离初始时刻τj间隔小于时间长度V的所有查询。给定用户u,在一个会话中提交搜索查询页码集合记作PSu[j],那么,用户u的查询页码集合表示为:

3.2 基于马尔可夫链模型
从我们对该搜索引擎用户查询日志统计表明,约96%的查询请求访问查询结果页码顺序是非逆序的(由于篇幅限制,未贴此结果)。基于此事实,引入如下假设:用户以页码的自然顺序访问查询结果页。我们使用基于马尔可夫链的方法设计预取模型,状态转移概率如图3所示,状态“i”(1≤i≤n)表示用户发起一个查询主题t,请求页码为“i”;状态“0”表示用户发起一个查询主题t后,不再对该主题产生页码请求。在任意时刻τj,当前访问页号Xj和所有以前访问页号X1,X2,…,Xj-1的信息是已知的,所有将来的访问页号Xj+1仅依赖于现在的信息Xj,而不依赖以往的信息X1,X2,…,Xj-1,有:
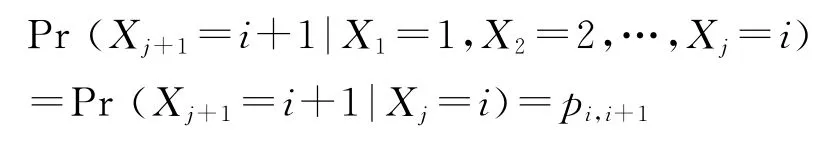
那么,我们在模型设计过程中,需要获得Pr(Xj+1=i+1|Xj=i)即状态转移图中由状态“i”转移到状态“i+1”的概率pi,i+1。
3.3 基于用户特性的查询结果预测模型

图3 查询请求页码状态转移图
在2.1节中,我们定义了基于用户信息来划分用户查询日志,其中,Pu集合是考虑用户信息因素下历史请求页码的分布,其会考虑用户偏好。对于一个搜索引擎而言,通常用户规模是数以百万甚至千万、亿级别的,统计每个用户的历史请求页码分布需要很大的开销。然而,用户偏好的确可能给搜索引擎查询结果缓存的预取带来有用信息,以及针对有些搜索引擎支持个性化搜索,譬如用户登录搜索引擎,这些信息又是搜索引擎已经记录的。因此,我们对基于Pu的预测模型分为全局预测模型和部分预测模型。
(1)全局预测模型
全局预测模型考虑全部用户信息,通过记录用户的浏览页码统计信息进行预测。根据Pu集合的历史信息,将用户u对页号为i访问的次数记作Countu[i],那么,采用如下定义:

即考虑用户的所有会话内某个页的分布。我们采用如下方法计算用户查询请求页码概率:

根据上面的定义,给定用户当前访问页号i,预测下一次用户查询页码集合Ωu,页面访问预测模型如下,其中,阈值φglobal用来调节预取效果:

全局预测模型认为所有用户都是平等的,每个用户都使用该模型进行浏览页预测,搜索引擎需要存储所有用户访问信息,这对超大规模搜索引擎是个挑战。
(2)部分预测模型
部分预测模型考虑部分用户信息,通过记录部分用户的浏览页码统计信息进行预测。可以选取登录或则查询频率最高的一些用户作为统计主体,这样有益于提高个性化搜索性能。根据Pu集合的历史信息,将用户u对页码为i访问的次数记作Countu[i],定义部分用户集合为USpec,那么,采用如下定义:即只考虑部分用户USpec的所有会话内某个页的分布。我们采用如下方法计算用户查询请求页码概率:


根据上面的定义,给定用户当前访问页号i,预测下一次用户查询页号集合Ωu,页面访问预测模型如下,其中阈值φuser用来调节预取效果:

与全局预测模型不同的是,部分预测模型只考虑部分用户USpec的浏览页分布,搜索引擎只需要存储部分用户访问信息,这样可能降低搜索引擎为存储这些统计信息所需要的开销。
3.4 模型阈值选取方法
我们采用如下两种方法来确定阈值:(1)设置固定阈值,采用固定值,需要预先设定,阈值与当前浏览页码无关;(2)根据总体浏览页码分布动态调整阈值,阈值与当前浏览页码有关。
4 算法框架
在第3节,我们给出结合用户特性的预测方法。本节将在此基础上,给出结合用户特性的缓存与预取算法框架,如算法1所示。在搜索引擎环境下,有必要对查询结果预取做一些必要规则。
规则1:在一个会话内,搜索引擎收到用户的一个查询主题的首次请求不为第一页时,不对该用户的查询结果做预取。
用户向搜索引擎发起一个查询请求,通常会返回查询结果的第一页。然而,一些网络查询代理程序可能会首次请求第二页,并不需要对这些查询请求做预取优化,原因在于,其并不是搜索引擎的真正用户。提高网络代理程序的性能是以占取搜索引擎为真正用户服务的资源为代价。
规则2:以查询结果页码的自然顺序做预取。
用户在查询时,通常按照自然顺序访问查询结果页,总体上,约96%的查询请求访问查询结果页的行为是非逆序的。该规则也是预取模型的基本假设。
规则3:只有当浏览查询结果页码的概率大于阈值才做预取。
搜索引擎缓存系统的存储容量是有限的,一次错误的预取行为会造成缓存存储容量的浪费,即可能使有用的条目被替换出缓存。因此,并不是简单以某一浏览页码被访问概率大于不被访问概率为条件,而是,使用阈值来调节预取行为。
规则4:对于部分预测模型,搜索引擎缓存系统首先查询该部分所对应的缓存,如果不命中,再去查询其他部分缓存。
对于搜索引擎的部分预测模型,缓存系统根据某些属性分为多块缓存,如根据用户信息分类。当收到用户的某一查询主题时,根据查询结果访问的空间局部性,即通过局部预测模型预取用户可能访问的查询结果页码,缓存系统应该首先在该用户所对应的查询结果缓存中查询,以提高缓存检索相关条目操作的效率。
算法1 基于用户特性的查询结果缓存与预取算法框架

算法1给出了基于用户特性的查询结果缓存与预取算法框架,我们在此给出算法时间复杂度和空间复杂度分析。第6行,在缓存中检索该查询请求的查询结果,该操作依赖于缓存中信息条目的具体组织方式,通常,采用基于哈希的组织方式使该操作开销为Ο(1)。第11行,缓存条目更新,该操作依赖于所采用的缓存替换策略,如LRU策略的缓存替换时间复杂度为Ο(1),记作 Complexity(Replacement-policy)。第22行,预测浏览页码集合,由于此过程需要获得查询相关信息,其依赖于信息的具体组织,可以采用二维表的方式,用户id作为表的行项,因此,该过程时间复杂度为Ο(1)。综上分析,该算法的时间复杂度依赖于所使用缓存替换策略的时间复杂度,即Complexity(Replacement-policy)。算法的空间开销来自于预测模型计算所需要的参考信息,通常,全局预测模型需要存储所有用户查询浏览页码分布,而部分预测模型只需要存储部分用户浏览页码分布。
5 实验与分析
5.1 数据集
本文实验数据集来自于国内某著名商业搜索引擎从2006年9月1日到2006年10月31日的用户查询日志。选取前500万条用户查询记录预热查询结果缓存,剩下约2 500万条用户查询记录作为查询结果缓存的工作负载。
5.2 评价方法
搜索引擎缓存系统是提升系统整体性能的重要手段,缓存系统性能的优劣对整体有着重要影响。通常,缓存是以命中率作为其衡量指标,由于缓存系统实际受到存储容量的限制,需要考虑存储容量因素,即当缓存条目达到一定空间后需要以某种策略替换某些条目。为了分析存储容量对缓存命中率的影响,我们采用工作集模型[13]离线计算该用户查询日志的理论缓存命中率。在该用户查询日志的查询请求负载下,缓存容量和命中率的关系曲线如图4所示。当缓存容量大于0.025(实际缓存查询结果条目占总查询条目的百分比)时,命中率变化趋势趋于平缓。在实验中,我们近似选取5K、10K、20K、50K、75K、100K、150K、200K、250K 条查询结果作为缓存容量来分析缓存性能。从图4中可以看出,查询结果缓存命中率理论上界为58.44%(Normalized size=1时)。需要指出的是,该理论上界是查询结果缓存不采用预取技术所能达到的最优值。

图4 工作集模型下的理论缓存命中率
离线策略通常是用作缓存替换算法的理论分析,需要预先知道当前访问时间以后的全部或者部分工作负载。预先知道工作负载是不现实的,因此,离线策略是不可能在实际系统中实现的。在理论分析时,根据预先知道工作负载的多少可以将离线替换策略分为全局最佳替换策略(Global-OPT)[14]和局部最佳替换策略(Local-OPT)[15]。由于数据集规模大,我们采用Local-OPT(窗口为缓存容量大小)作为本文实验比较目标。
本文提出了基于用户特性的预测模型。在以往的研究工作中,搜索引擎查询结果缓存系统通常采用Pre-K和Pre-SDC[4]两种预取方法。在我们实验中,将其作为baseline。
5.3 结果与分析
本文实验对Pre-SDC、Pre-K和提出的基于用户特性的方法,在缓存容量5K~250K的9个容量配置下,综合多种因素进行实验。Pre-SDC的参数K在取值为1或者2处,能获取最佳命中率(由于篇幅限制,未贴此结果)。因此,实验取K=0、K=1和K=2作为Pre-K和Pre-SDC的参数。
图5是全局预测模型与 Pre-SDC、Pre-K、不预取、局部最佳替换策略和理论上限的对比曲线,注意,该实验结果默认使用LRU替换策略。可以看出图中最下面的 W/o prefetching和Local-OPT曲线都是缓存没有采取预取技术所获得的缓存命中率,其结果均偏低,这说明搜索引擎查询结果缓存系统采用预取技术对于系统性能提升是非常必要的。图中最顶部的虚线为不采用预取技术的缓存命中率上界,即认为缓存容量无限大时所获取的命中率。可以看出,在采用预取技术后,缓存容量为250K时,采用预取技术的曲线已经接近该上界。实际上,随着缓存容量的增大(大于250K),采用预取技术的缓存命中率是会超过该理论上界。基于用户特性(Pre-GlUser+phi_0.1)(此时,φ=0.1,关于φ选取方法对预测模型的影响在后面实验分析)预取的缓存命中率均好于未采用预取技术的缓存命中率。然而,基于全局预测模型的效果比基于Pre-SDC和Pre-K效果要差。由此可见,基于用户特性的方法需要考虑用户群体内部的差异,如我们在第1节分析搜索引擎用户特性所显示,往往某些用户占据了大部分查询请求现象。

图5 全局预测模型与缓存命中率

图6 部分预测模型与缓存命中率
基于全局信息的预测模型需要额外信息存储开销,然而,用户往往是不对称的。基于部分用户信息的预测模型就是利用这一特性来降低信息存储开销,采用区分服务的思想来提高部分和整体命中率。在训练集中选取该搜索引擎查询频率最高的14 748个用户(约占总用户数的0.25%,总共用户为5 809 111)作为部分用户集合,分配10%的缓存容量给这部分用户作为部分用户缓存。图6是基于部分用户信息的预测模型与其他方法的对比。实验结果表明,该方法可以获得3.03%~4.17%的命中率提升,对我们选定的用户集合获得20.52%~28.2%的命中率提升(如图7(a)所示)。
图7是采用部分信息的预测模型前后,该用户集合缓存命中率和缓存系统总体命中率的对比(由于篇幅限制,只贴出Pre-SDC1比较图,其他方法与此结论类似)。从用户集合命中率对比图7(a)来看,这14 748个用户的命中率得到大幅提升。一方面,通过给予这部分用户更多的缓存空间,使他们所需要的查询能够尽量缓存住;另一方面,这部分用户相比其他用户,对搜索引擎查询请求贡献更大。从总体缓存角度来看,其命中率也得到提升。由此可见,本文提出的基于部分用户缓存与预取的方法,一方面,可以降低全局预测模型存储用户信息开销;另一方面,通过对不同部分用户划分不同容量可以提高部分用户的查询命中率,即提高这部分用户的查询检索性能,与此同时,可以提高缓存总体命中率。

图7 部分用户集合与所有用户集合缓存命中率

图8 基于用户特性模型阈值对缓存命中率的影响
接下来,我们分析模型阈值选取方法对模型的影响。实验在缓存容量为50K和200K的情况下,对基于用户特性的预测模型,测试固定阈值(以0.1递增,从0到1变化φ值)和动态调整阈值方法,结果如图8所示,基于用户特性的预测模型在阈值静态设置为0时获得最佳缓存命中率,即图中A、B区域。因此,当使用基于用户预测模型时,建议采用静态阈值方法,将其值设置为0。需要指出的是,我们在前面的实验中,通过设置静态阈值为0.1验证基于用户特性的预测模型(含阈值)和算法框架的有效性。实际上,通过调节该静态阈值,系统性能是能够进一步有所提升的。然而,其代价是增加搜索引擎检索排序系统的负载。关于模型阈值与检索排序系统负载的关系是本文需要的进一步工作。
6 结论及未来工作
查询结果缓存与预取是有效提升搜索引擎系统性能的关键技术。本文面向搜索引擎查询结果缓存与预取问题,提出一种基于用户特性的缓存与预取的方法,该方法包括用来指导预取的查询结果预测模型和基于用户特性的分区缓存。通过在国内某著名搜索引擎大规模用户查询日志上的实验,讨论用户信息选取范围(全局和局部)、阈值选取方法等问题。实验结果表明,该方法可以有效提升搜索引擎缓存命中率,尤其对搜索引擎系统查询量的贡献较大的用户群体更为显著。
未来的工作集中在三个方面,一是探寻更多的用户特性融入到本文提出的基于用户特性的缓存与预取框架之中;二是研究选定用户集合大小与该集合分配缓存容量关系对整体缓存命中率的影响;三是讨论模型阈值选取对搜索引擎检索排序系统的负载影响。
除此之外,当今的搜索引擎系统对实时索引更新有重要需求,由于索引更新,导致缓存的查询结果陈旧。因此,如何保证缓存一致性成为一个重要挑战,文献[16-18]已取得一定成果。在该场景下,考虑用户特性是我们未来可能尝试的工作。
[1]CNNIC(China Internet Network Information Center).The 25th report in development of Internet in China[DB/OL].http://www.cnnic.net.cn/uploadfiles/pdf/2010/1/15/101600.pdf.2010.
[2]E.P.Markatos.On caching search engine results[J].Computer Communications.Elsevier Science B.V..2001,24(2):137-143.
[3]Y.Xie,D.R.O'Hallaron.Locality in search engine queries and its implications for caching[C]//Proceedings of INFOCOM'02,2002:1238-1247.
[4]T.Fagni,R.Perego,F.Sivestri,et al.Boosting the performance of web search engines:caching and prefetching query results by exploiting historical usage data[J].ACM Trans.Information Systems,2006,24(1):51-78.
[5]Q.Gan,T.Suel.Improved techniques for result caching in web search engines [C]//Proceedings of WWW'09,ACM,2009:431-440.
[6]R.Ozcan,I.S.Altingovde,et al.Static query result caching revisited [C]//Proceedings of WWW'08,ACM,2008:1169-1170.
[7]G.Skobeltsyn,F.Junqueira,et al.ResIn:A combination of results caching and index pruning for high performance web search engines[C]//Proceedings of SIGIR'08,ACM,2008:131-138.
[8]R.Lempel,S.Moran.Predictive caching and prefetching of query results in search engines[C]//Proceedings of WWW'03,ACM,2003:19-28.
[9]班志杰,古志民,金瑜.Web预取技术综述[J].计算机研究与发展,2009,46(2):202-210.
[10]Y.Li,S.Zhang,B.Wang,et al.Characteristics of Chinese Web Searching:A Large-Scale Analysis of Chinese Query Logs[J].Journal of Computational Information Systems. Bethel: Binary Information Press,2008,4(3):1127-1136.
[11]岑荣伟,刘奕群,张敏,等.基于日志挖掘的搜索引擎用户行文分析[J].中文信息学报,2010,24(3):49-54.
[12]余慧佳,刘奕群,张敏,等.基于大规模日志分析的网络搜索引擎用户行为研究[J].中文信息学报,2007,21(1):109-114.
[13]D.R.Slutz,I.L.Tratger.A note on the calculation of average working set size[J].ACM Commun.,1974,17(10):563-565.
[14]R.L.Mattson,J.Gecsie,et al.Evaluation Techniques for Storage Hierarchies[J].IBM Systems Journal,1970,9(2):78-117.
[15]B.G.Prieve,R.S.Fabry.VMIN-An Optimal Variable Space Page Replacement Algorithm[J].ACM Comm.,1976,19(5):295-297.
[16]B.B.Cambazoglu,F.P.Junqueira,V.Plachouras,et al.A refreshing perspective of search engine caching[C]//Proceedings of WWW'10,ACM,2010:181-190.
[17]R.Blanco,E.Bortnikov,F.Junqueira,et al.Caching search engine results over incremental indices[C]//Proceedings of SIGIR'10,ACM,2010:82-89.
[18]S.Alici,I.S.Altingovde,R.Ozcan,et al.Timestamp-based Result Cache Invalidation for Web Search Engines[C]//Proceedings of SIGIR'11,ACM,2011:973-982.
