网络维吾尔文判别及其文本长度下界的探讨
2012-10-15倪耀群许洪波唐慧丰程学旗
倪耀群,曹 鹏,许洪波,唐慧丰,程学旗
(1.中国科学院 计算技术研究所,北京100190;2.中国科学院 研究生院,北京100049;3.解放军外国语学院,河南 洛阳471003)
1 引言
1.1 维吾尔文和阿拉伯文、哈萨克文等文字共用很多字母
阿拉伯文是由28个辅音字母和12个发音符号(不包括叠音符)组成的拼音文字,世界上大约有60多个民族的文字是以阿拉伯字母为基础来书写的。为正确书写和显示这60多种文字中的专有字符,Unicode标准在阿拉伯基本字母集合(U+600~U+6FF)之外提供了阿拉伯语变形显现形式-A(U+FB50~U+FDFB)和阿拉伯语变形显现形式-B(U+FE70~U+FEFC)字符集。
中国新疆地区使用的维吾尔文、哈萨克文和柯尔克孜文都属于这类文字,以阿拉伯字母为基础书写的维文称为老维文,简写为ASU(Arabic-Script Uyghur),老维文有32个字母。而以阿拉伯字母为基础的哈萨克文有33个字母,柯尔克孜文有30个字母和一个合体字母,这些文字共用了很多字母,编码重叠较多,字符集差异很不明显。例如,哈萨克文33个字母中有21个字母的字型形状及编码与维吾尔文完全相同[1];波斯文有32个字母,其中28个是阿拉伯字母。下面列举了几种文字:

其中维文被谷歌浏览器chrome的“网页检测”识别为阿拉伯文;而谷歌翻译的“检测语言”功能,把维文识别当作“普什图语”(阿富汗的主要语言),如图1所示。

图1 谷歌翻译误将维文(《人民日报》记者深入灾区第一线采访)检测为“普什图语”
如何将维吾尔文从阿拉伯文、哈萨克文、柯尔克孜文等以阿拉伯字母为基础书写的类似文字中识别出来,是维文信息处理的一个重要研究问题。
1.2 维吾尔文的书写体系复杂
维吾尔文的书写系统受其他语言的影响比较大,字符编码存在一些混乱的情况。
维文32个字母因位置不同有126个书写形体[2](glyph),加上元音分节符hamza的各种变形等其他编码后共使用了162个书写形体[3]。然而ISO没有为维文开辟专门的代码区,而是把维文字符分配到阿拉伯基本字母集合、变形显现形式-A和变形显现形式-B这三块不连续的区间。
对变形字母的编码如何处理造成了编码的混乱。(1)字母在单词中不同位置发生了变形,应该存储为名义字母(Representative,32个),但有些网站上直接使用阿拉伯变形显现形式的编码来存储该字母。如: 的编码为“06CB”,其末尾形式为,也应该存储为“06CB”,但是有些网站存储为变形显现形式-A的编码“FBDF”;(2)有些情况下元音字母之前应该添加hamza,有人加了,有人不加;添加hamza之后可以变成一个复合字母(conjunct vowel form)[4],也可以保持原来的两个字母;(3)连写字母和是否拆分为 和 也不尽相同。
另外由于维文网站的多元化导致维文网页字体的编码不一,同一个字母在不同网站中有多个编码,如”的编码有U+649、U+635和U+6CC等。据统计,目前有264个网页字体文件,如“Alp Basma Aq”、“UKIJ Tuz Tor”等。需要消除这些网页文件造成的编码差异,使用统一的编码表示所有维文字符。
总结以上两点,维吾尔文的识别有其困难性和特殊性,为解决维文的识别,作者使用基于字符层的语言模型来确定文本的语种。
本文的组织结构如下:第2节介绍了语种识别的相关工作;第3节介绍了维吾尔文的识别模型,分为模型参数确定、模型训练和维文识别算法流程;第4节测试了模型在网页、论坛和微博客等不同类型数据上的性能;第5节就微博客数据的测试结果进一步分析,讨论了4种文字中识别语种所需要的字符串长度,在理论分析基础上对实际数据计算后得出了语种识别的文本长度最低界限,以及不满足下限的超短文本能达到的最高语种识别准确率。
2 语种识别的相关工作
语种识别实质是分类问题,一般有规则方法和统计方法,规则方法需要人工总结出语言知识并将其转换为系统规则,依赖于设计人员对语言本身的充分了解和分析,而且结果的正确性很难把握。
文献[5]利用一元语法模型(unigram)进行汉字内码识别的方法,可以高速、准确地识别简体汉字和繁体汉字,满足实时处理等各种应用。但单一的以字为基本单位的unigram方法过于简单,没有考虑阿拉伯字母等其他语言的情况。
文献[6]采用编码模式、字符分布和双字符序列分布的复合方法来检测语言/编码,效果很好,在UTF16和UTF8的情况下,尽管编码方式正确识别了,语言信息仍是未知的。检测语言时需要每一种语言的,大量的文本采样数据,同时需要对语言的认知/分析有一定的深度,对许多单字节编码还没有测试。文献[7]在8种编码(utf-8、us-ascii、iso-8859-1、shift-jis、euc-jp、iso-2022-jp、euc-kr、iso-2022-kr)上测试了 Naive Bayes(NB)和Support Vector Machine(SVM)模型,认为SVM需要较少的内存就可以达到98.22%识别准确率,但是检测的编码之间重叠程度不大,仅是英日韩文字的不同编码。
规则方法有薛亚平[1]和张健[8],他们根据GB2l6690-2008信息技术—维吾尔文、哈萨克文、柯尔克孜文编码字符集国家标准,按照不同文种的字符编码构造正则表达式进行匹配,从而识别文种。由于维文、哈文、柯文和阿文的非重叠区很小,这几种文本的正确识别具有一定的难度,识别率还不是很高,需要结合人工辅助来正确识别。
3 维吾尔文的识别模型
考虑到维吾尔文和其他采用阿拉伯字母书写的文字尽管在编码上有很多重叠,但是字母排列顺序不同,这是文字自身表现出的区别于其他文字的明显特征。因此,作者提出了一种基于n-gram模型的维文语种识别方法。
3.1 n-gram模型中阶数n的确定
在n-gram建模方法使用这样的假设:语言是一个马尔可夫过程,某个字母的出现仅仅与前面的n-1个字母相关,因此m个Unicode字符构成的字符串s的概率可以表示为式(1):

其中P(wi|wi-n+1wi-n+2…wi-1)用大数定律估计,即 wchar类型的字符串 wi-n+1wi-n+2…wi-1wi在所有以 wi-n+1wi-n+2…wi-1开头的字符串中所占的比率。
在n-gram模型中阶数n的选择存在着一个平衡,冯冲、黄河燕[9]认为理想的识别模型应当既能够描述训练样本所独有的语种和编码特点,又不过分反映样本中特定的文本内容和语言现象。为了确定n-gram的阶数,作者在4种语言的网页正文中统计了 所 有 uni-gram,bigram,tri-gram,4-gram 和 5-gram,以及这些gram出现的次数。
以维文为例,bigram有1 132个,其中最频繁的bigram出现了5 822 195次,有60个bigram出现次数超过一百万次,大部分(751个)bigram出现次数在1 000次以上;对比tri-gram有17 854个,只有5个tri-gram出现次数超过一百万次,10 025个trigram出现次数小于100次,数据稀疏现象比较明显。对阿拉伯文的统计也验证了这一点。
综合考虑,因为tri-gram的统计意义不明显,按照大数定律估计的概率由于数据稀疏不很准确,而且会造成更大的系统开销(约16 777 216个存储单元),所以最终确定以bigram模型计算字符串概率:其中的P(w1)是字符串的开始字符,如果在每个字符串前面加上一个虚拟开始符号(概率为1),可以去掉该项,简化计算。
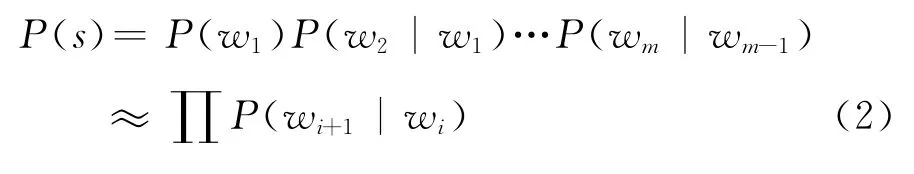
3.2 Bigram模型的训练
P(bigram|L)是语言L中bigram出现的概率,为表现统计意义,忽略那些频率较低的bigram,如维文有7个bigram只出现一次,这些bigram代表了样本中特殊的偶发的语言现象,对区分语种的作用微乎其微。维吾尔文和阿拉伯文的bigram频次分布如图2(见下页)。
为充分表现语言在bigram上的共性并去除偶发现象的干扰,作者选用高频bigram组成该语言的特征表,同时为防止图2所示长尾效应的影响,特征表中的bigram概率之和应该大于一个阈值(作者选取0.9)。按照这个原则,作者在阿拉伯文中选取了400个bigram,在维文中选取了1 000个bigram。
作者根据阿拉伯文和维文字母编码的特点,对维文变形显现字符映射到基本阿拉伯字符,经过映射后字符的UTF8编码在D880~DBBF(U+600~U+6FF)范围内,进一步对其压缩,将这个256个编码的区间映射到unsigned char(0~255),使得语言模型的存储结构(语言特征表)大大减小。

图2 维吾尔文和阿拉伯文bigram特征频次分布图
3.3 对未知文本的语种识别
按照Bayes公式,字符串s属于某种语言L的概率

其中P(s)为定值,而先验概率P(L)可以根据训练文本中维文、阿拉伯文、哈萨克文等文章所占的比例计算出来。但是在测试新的未知文本时,难以预知该文本的来源,因此简单认为所有待检测文本所属的文种是等概率的,即P(L)为一个常数。
而后验概率P(s|L)的对数
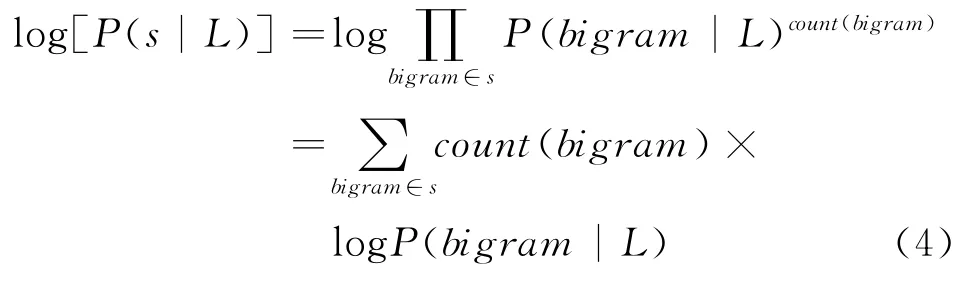
count(bigram)为字符串s中某个bigram 出现的次数,但是P(bigram|L)有可能为零,原因有二,一是训练文本中根本没有出现该bigram,二是某些低频的bigram没有被该语言的bigram特征表收录(如维文去除了132个bigram,保留了1 000个bigram)。这就需要进行零概率的拉普拉斯校准。
在概率空间(0,1)上对数函数是严格单调递增的,即P(bigram|L)与其对数值正相关,因此count(bigram)×P(bigram|L)与count(bigram)×logP(bigram|L)正相关。
最终使得字符串s出现概率最大的语言,就是s所属的语言,定义为L*:
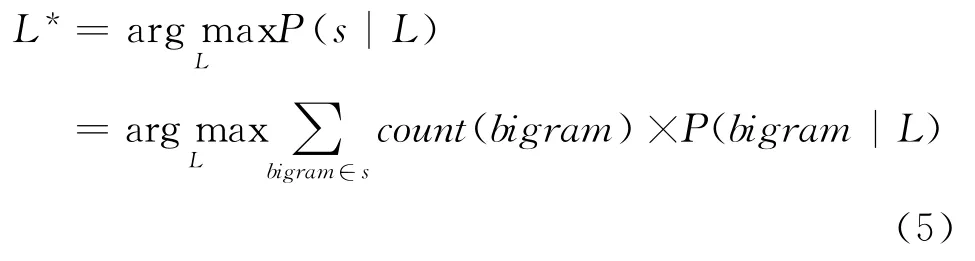
只需要将待识别的网页文本扫描一遍,统计count(bigram),然后按照式(5)计算该网页文本属于某种语言的概率。理论上,有多少个语种,就需要多少次相似度计算。作者的目的仅仅是识别维吾尔文,所以可以简化计算,将识别文本看成二分类问题,即比较该文本属于维文(正例)和非维文(负例)概率。非维文的计算本来需要将维文以外的其他所有语言的文本一起作为负例样本,鉴于哈萨克文和柯尔克孜文的样本非常少,作者简单的把阿拉伯文当作负例样本。
维文训练网页有6万页面(2008年采集的维文网页和论坛,3GB)和6 560个阿拉伯文页面(2008年采集的中国网阿拉伯文版,200MB)。
模型训练和网页维文识别的流程如图3所示(见下页)。
4 维吾尔文识别结果及分析
现有的维吾尔文识别方法是基于表达式规则和人工辅助的[1,8],且并没有给出识别准确率,与作者采用的统计方法缺乏可比性。因此,作者通过使用不同时间、不同来源的网页数据(新闻和论坛),以及不同类型的网页数据(微博客)来进行实验测试,验证了该方法在不同数据上的良好性能和稳定性。
4.1 对网页和论坛的测试
测试环境:硬件环境:AMD 3600+ CPU,2.5G内存,80G硬盘
程序识别网页的处理速度大约为100MB/s。对单个网页(中文、阿拉伯文、哈萨克文、柯尔克孜文、维吾尔文)的判别结果如表1所示。
对不同时间、不同来源的多个网站的网页分组测试结果如表2所示。
分析:

图3 模型训练和维文识别流程图

表1 五种语言的网页文种判别结果

表2 四种语言网页开放测试的正确率
2)对正文较长的新闻、论坛等网页,维吾尔文的识别准确率较高。
3)训练中使用的阿拉伯文和维吾尔文,在识别时也得到了非常高的准确率。
4.2 对微博客的测试
微博客的特点是文本长度短,转发造成的重复内容多,而且转发还造成同一文本内包含了多种文字。因此对微博客需要去重后才能正确评价文本分类识别的准确率。文献[10]提到了一种通过文本压缩将文本转换为一个大整数从而去重的方法。
在2010年推特识别结果中随机采样了31条数据进行人工判断,发现有30条判断正确(准确率96.6%),1条来自伊朗的波斯文消息被判别为维吾尔文,该消息呈现如下形式:
Deutsche Welle RT@User2Iran awaiting 40%inflation
http://bit.ly/6e1wPH #iranelection
容易看出,这条消息中包含德、英、波斯三种文字,其中波斯文的25个阿拉伯字符占消息字符总数的18.461 538%,其维文得分0.001 361比阿拉伯文得分0.001 283只高出了0.000 078。而且“伊朗”这个词的波斯文拼写“”与维文拼写“”最后三个连续的字符都相同(),类似这样的单词片段导致程序的误判。
5 语言识别问题中的文本长度下界分析
语言分类的文本长度下界其实就是求解若干字符串集合的公共字符串,作者将研究范围限定在维吾尔文、阿拉伯文、哈萨克文和柯尔克孜文四种文字的字符串集合中。
对同种语言的每个网页抽取正文后,用空格、标点符号、数字、字母等作为分割标记切分正文得到若干字符串,将它们放到一个集合中,形成一个语言词串(token)集合。维吾尔文、阿拉伯文、哈萨克文和柯尔克孜文四种文字的字符串集合中分别含有251 928,82 559,21 972和14 521个字符串。这些字符串在长度上的分布如图4所示。
最终目的是找出这四个集合的最大公共子串。

图4 四种语言单词/token按照字符串长度上的分布
5.1 两个字符串集合的公共字符串
字符串集合 A={A1,A2,A3…Am}和B={B1,B2,B3,…,Bn},假设 A1,A2,A3,…,Am的平均长度为L1,B1,B2,B3,…,Bn的平均长度为L2,则:
A的子串个数上限为mC2L1,同理B的子串个数上限为nC2L2,通过字符串比较得到公共子串(common sub)的比较次数上限为mC2L1nC2L2,设 m=n=10 000,L1=L2=10,比较次数大约为2 025亿次。实际上m,n比10 000大很多(对维文来说20万单词是很保守的估计),使得两个大集合之间的公共子串求解变得不可行。更遑论四个集合的公共子串的计算了。
我国传统的抗旱工作模式是危机管理,即在旱情出现后才对干旱作出反应,临时组织动员广大干部群众,并拿出大量资金和物资投入抗旱减灾工作中。但随着社会主义市场经济体系的不断完善,传统的危机管理模式在观念、措施、手段和政策上呈现出一些不适应的地方:一是重视“抗”,忽视“防”,难以做到以最小的投入取得最大的抗旱减灾效果;二是重视工程措施,忽视非工程措施,难以发挥工程设施的最大抗旱效益;三是重视行政手段,忽视经济、法律、科技手段,抗旱减灾能力缺陷明显;四是重视经济效益,忽视生态效益,难以满足和谐发展要求。
为此,对公共子串做出限制,要求公共子串必须真实存在于某个语言的字符串集合中。也就是说,公共子串必须是某种语言的合法单词或其变形(token),称这样的单词为合法公共字符串。
5.2 四种语言字符串集合的合法公共字符串
依照上述合法公共字符串的定义,可以在有限时间内求得每个集合相对于其他三个集合的合法公共字符串。流程如下:
1)ABCD为四个字符串集合,S(A)为集合A中所有字符串的子串集合的并集,同理得到S(B)、S(C)和S(D),从上面的分析容易得出
|S(A)|=10 000×10×9/2(大约为百万数量级)
2)对集合A中的每个字符串Ai分别在集合S(B)、S(C)和S(D)中查找,如果在三个集合中全都查到,则Ai是一个合法公共字符串。
3)同样的方法验证集合B、C、D中的每个字符串是否为合法公共字符串。
4)所有合法公共字符串中长度最长的字符串就是四个集合的最长合法公共字符串,也就是语言分类的文本长度下界。
实验环境:建立的四个语言的集合比较消耗内存(大约2GB)和时间,在 windows7(64bit)4G内存环境下经过约20分钟运行得到合法公共字符串(简称公共单词)共1 112个,其长度分布和该长度对应的识别准确率如图5所示(见下页)。

图5 不同字符串长度对应的公共单词个数及识别准确率
作者给出文本语种判别长度下界为8(大于7个字符)。少于8个字符的字符串无法判断语言类别,图3给出的准确率也是理论上的最高值。
应该指出,这个数据基于作者研究的范围统计得到,而网页实际出现的词串有可能未被统计,或者属于其他未定义语言。实际识别准确率可能更高(从两种文字的正规文本集合中识别维文)或者更低(从更多种类文字的非正式文本中识别维文)。
6 总结与下一步工作
本文介绍了一种利用二元语法模型(bigram)进行从维吾尔文、阿拉伯文、哈萨克文和柯尔克孜文网页中识别维吾尔文的方法,针对维文的编码混乱的各种情况进行细致的预处理,能够从类似阿拉伯文的网页中高速、准确的识别维文(网页论坛的识别达到准确率98.9%,微博客96.6%,速度约100MB/s)。对短文本的测试结果分析引入了文本识别长度下界的概念,作者对四种语言的公共字符串进行了理论分析和统计计算,从而确定了四种文字中正确识别需要的文本长度下界为8个字符。
经过对不同时期采集的开放数据(2008年和2011年的维吾尔文、阿拉伯文网页、2010年的推特数据)的测试,表明该方法可以快速、准确地处理维文网页的识别问题,对于微博客等短文本在预处理(将消息按照字符集分解为几个比较“纯净的”单语言网页)之后再做语种识别,还能进一步提高判断精度。
由于采用阿拉伯字母书写的语言比较多,在字符集上相互之间的交叠大而复杂,因此按照N元语法模型对更多的文字(如波斯文、普什图文、乌尔都文……)训练更多的语言特征,是解决语种分类错误的一条有效途径。
[1]薛亚平,袁保社.全文检索系统中语种识别与索引技术研究[J].网络安全技术与应用,2009,(12):49-51.
[2]哈力克·尼亚孜,吾买尔·阿皮孜.基础维吾尔语[M].新疆大学,1995:1-2.
[3]瓦热斯江·阿布都克力木.维文Unicode在线处理技术与实现[D].新疆大学硕士研究生学位论文,2002:17-18.
[4]Imad Saleh,Waris Abdukerim Janbaz.Web Development Considerations for Unicode-based Text Processing in Uyghur Language[C]//Proceedings of the 30th Internationalization and Unicode Conference,November 2006,Washington,DC USA:15-17.
[5]李继锋,刘群.基于N-Gram模型的高速汉字编码识别系统[J].计算机工程与应用,2004,(3):39-42.
[6]Shanjian Li,Katsuhiko Momoi.A composite approach to language/encoding detection[OL],http://www-archive.mozilla.org/projects/intl/UniversalCharsetDetection.html.
[7]Seungbeom Kim,Jongsoo Park.Automatic Detection of Character Encoding and Language[R],CS 229,Machine Learning,Autumn 2007,Stanford University.
[8]张健,任炜,蒋欣,等.多语种eml文件编码及语种识别算法研究[J].新疆大学学报(自然科学版),2010,27(4):482-485.
[9]冯冲,黄河燕,陈肇雄,等.基于字符层马尔科夫模型的多语种识别[J].计算机科学,2006,33(1):226-235.
[10]曹鹏,李静远,满彤,等.Twitter中近似重复消息的判定方法研究[J].中文信息学报,2011,25(1):20-27.
