基于SimRank的跨领域情感倾向性分析算法研究
2012-10-15吕韶华林鸿飞
吕韶华,杨 亮,林鸿飞
(大连理工大学 计算机科学与技术学院,辽宁 大连116024)
1 引言
随着Web2.0的快速发展,主观文本数量呈指数增长,对主观文本进行倾向性判断是情感计算领域的热点问题。传统的倾向性分析[1-2]均是判断特定领域的情感倾向性,投入大量时间和资金对文本进行标注,然后利用监督分类方法对标注后的文本进行训练,得到倾向性分析的模型,然后用此模型来对新的文本进行倾向性判断。但是面对不同领域的文本,如果直接利用由监督分类方法实验所得出的模型进行倾向性分析,准确率偏低。面临这个难题,各种跨领域情感倾向性分析方法应运而生。
跨领域情感倾向性分析是指利用源领域中已标注情感倾向性的文本,得到新目标领域中未标注情感倾向性的文本的倾向性。文献[3]利用图排序算法处理跨领域情感倾向性分析问题,文中同时考虑了新旧两个领域之间文档的相似度从而对其进行赋值:首先,在旧领域和新领域文本之间建立内容相似矩阵;再对该矩阵进行标准化后得到与新领域每个文档的相似度最大的前K个旧领域中的文档;然后,使用同样的方法找到新领域中文档内容之间相似的文档;最后,依据标注文本的倾向性和得到的K个相似文档,计算各个文档的情感倾向性分数,对上述两个分数进行线性加和后得到文档的最后情感分,进而依据最后的得分确定新领域中各个文本的情感倾向性。但该方法在多个实验中所得到的结果相比于本文提出的方法所得到的实验结果好。文献[4]借助与领域相独立的词语作为连接源领域和目标领域的桥梁,运用文中所提出的SFA算法,把不同领域的词语映射到统一的潜在空间,从而对目标领域的文本进行情感倾向性判断。可是,其处理的文本仅包括英语语料,未考虑中文文本的情感倾向性分析问题。文献[5]利用基于图的算法判断不同语言中词语的倾向性,实验表明文中的方法比传统的SO-PMI方法效果好,但是该方法只考虑了形容词的倾向性,处理的是跨语言的情感倾向性分析问题,与本文中处理的跨领域情感倾向性不同。
本文在前人工作的基础上,提出基于SimRank的跨领域情感倾向性分析算法,具体步骤如下:首先,参照文献[4],将源领域和目标领域中的词语分为领域相关词和领域无关词,并把领域无关词作为两个领域情感倾向判定的种子词;然后,利用Sim-Rank算法和情感词典,计算领域相关词与种子词的相似度并扩展种子词的规模,从而找出潜在情感空间;最后得到的潜在情感空间中的词作为特征词,借助SVM对已经标注情感倾向性的源领域文本进行训练,利用得到的模型对未知情感倾向性的目标领域文本进行情感倾向性判定。
本文的组织结构如下:第2节是相关工作介绍;第3节介绍基于SimRank的跨领域情感倾向性分析算法;第4节是本文的实验结果计算及分析;最后一节对本研究进行了总结和展望。
2 相关工作
2.1 情感倾向性分析
有关情感倾向性分析的研究成果众多[1-2,6],但是,当面对不同的领域文本,如果直接利用有监督模型进行倾向性分析,准确率不高,因为不同领域的文本在词的分布上难以一致,这就造成在训练阶段得到的模型难以用于预测新的领域的文本的情感倾向性。例如,文献[1]利用句子之间的连词等信息作为突破口来判定词语的情感倾向性;文献[2]把传统的有监督分类方法用在情感倾向性分析方面,利用多种分类器对文本的倾向性进行判断,并在电影语料上做实验,结果表明有监督的方法得到的准确率最高达到82.9%;文献[6]则利用 WordNet中形容词的同义词集和反义词集判断情感词的倾向性,进而在句子级别上判定情感倾向性。
虽然实验结果表明有监督的方法对情感倾向性判定比较有效,但是该方法需要大量的标注语料,耗时费事,代价颇大,且其准确性难以保证。同时,当面对不同的领域文本,如果直接利用有监督模型进行倾向性分析,准确率不高,因为不同领域的文本在词的分布上难以一致,这就造成在训练阶段得到的模型难以用于预测新的领域的文本的情感倾向性。
2.2 SCL算法
SCL[7]算法是一种有效的跨领域情感倾向性分析算法。它的主要思想是:利用源领域和目标领域中多次出现的带有明确情感倾向性的种子词作为枢纽特征,然后通过训练得出非枢纽特征与枢纽特征的权值模型,最后利用所得到的模型对目标领域的文本进行情感倾向性预测分析。


2.3 迁移学习
迁移学习是指把源领域的知识迁移到相关的目标领域。许多文献对此问题进行了研究[8-10],文献[8]采用重新对源领域的实例进行赋予权值的方法,达到对目的领域迁移的目的;文献[9]用新的特征表示来处理迁移学习问题;文献[10]提出一种“两段法”来解决迁移学习问题。广义上,本文的跨领域情感倾向性分析研究也属于迁移学习,所以近年来出现一些用迁移学习的方法来解决跨领域情感倾向性分析研究成果[7,11]。
2.4 SimRank算法
SimRank[12]是利用图模型计算图上各点之间的相似度,其主要思想是:一个点与其本身的相似度最高,相同或相似的节点的邻节点也相似。具体定义如下:
对图G上的任意两点a和b,假定相似度为s(a,b),那么

其中C(0<C<1)为衰减系数,表示相似度在传递过程中的衰减速度。I(V)表示节点V的入度集,Ii(V)表示第i个入边相邻节点。
SimRank算法及其改进算法已广泛应用于计算对象之间的相似性[13]。本文把源领域和目标领域文本中包含的所有词视为图上的节点,并分别构建由源领域和目标领域的词组成的图,若两个词语在一个句子中共现,那么两者之间就存在一条边,利用SimRank算法计算该图上任意两个点之间的相似度。
SimRank算法及其改进算法已广泛应用于计算对象之间的相似性[13]。文献[12]的实验显示SimRank算法在挖掘节点相似性的结果相对于对比实验能够提高36%到45%。本文把源领域和目标领域文本中包含的所有词作为图的节点,借助潜在情感空间,利用SimRank算法计算该图上任意两个点之间的相似度,从而实现源领域到目标领域的情感倾向性分析。
3 基于SimRank的跨领域情感倾向性分析算法
为了后文叙述方便,把基本术语在此做集中介绍。
源领域(Ds):已经标注情感倾向性的文本,可以利用这些标注信息作为跨领域情感倾向性分析进行训练;
目标领域(Dt):未标注情感倾向性文本,即待判定情感倾向性文本,且该领域的文本与源领域(Ds)不属于同一领域;
种子词(Seeds):在源领域和目标领域出现次数最多的情感词,这些种子词有明确的倾向性,它们需要借助情感词典进行判断,这些种子词对计算SimRank有重要影响;
潜在情感空间(Latent Emotional Space):在源领域和目标领域中,获取与同一个种子词的Sim-Rank最大的词,将这些词构成词空间,该空间中的这些“词”即可作为连接源领域和目标领域的桥梁,这就解决了2.1节提到的跨领域情感倾向性分析中源领域和目标领域不同而引起的问题。例如,若源领域和目标领域中与种子词w的SimRank值最大的词分别是ws和wt,那么ws_wt即为潜在空间里的一个词,可用作分类特征;
情感词典(Dic):用于判定词的倾向性,从而形成种子词,判定的方法为:正向为1,负向为-1,无情感为0。
具体而言,跨领域情感倾向性分析问题可用上述术语表达如下:对给定的源领域Ds和目标领域Dt,有

其中Ds由ns对标注情感倾向性的评论组成,xsi是第i个文本内容,ysi是xsi对应的情感倾向性,其取值范围为{1,0,-1},分别表示评论的情感倾向性为正向、无情感和负向,Dt仅由nt个文本组成。
跨领域情感倾向性分析的任务是利用Ds中的文本和情感倾向性标注信息,预测Dt中每个文本的倾向性。相对于特定领域的情感倾向性分析研究,跨领域情感倾向性分析涉及的难点有以下两点。
1)同一个词语在一个领域中的情感倾向性相对固定,但是它在不同领域中表达的情感倾向性不一定相同。这类问题与词所在的领域相关,所以不能直接使用传统的情感倾向性分析方法。比如表1所示的关于酒店评论和电子产品评论。

表1 评论举例
在这两个出自不同领域的句子中“小”在各自领域中的倾向性比较固定,但是当它出现在不同的领域中的时候,则表达了两种相反的倾向性,前者表示否定,而后者表示肯定。如何在跨领域情感倾向性分析中准确判断领域内的词语的情感倾向,并把它迁移到不同领域是跨领域情感倾向分析的一个难点。
2)一些词语只在特定领域中有情感倾向,在不同领域中可能不包含情感,甚至不出现,这样也导致了传统的情感倾向性分析方法无法判断倾向性,因为这两个领域的词空间分布不同。例如,针对电子产品的评论——“这个相机很好,耐用”,“耐用”在电子产品评论中经常出现,表示评论者认为该产品结实,表达肯定情感,但是在酒店领域的评论中出现的几率很小,如果直接使用特定领域中情感倾向性分析的方法,那么会丢失很多特征,准确率也随之降低。
类似SCL,本文的算法也同样利用多次出现的带有明确情感倾向性的种子词作为连接源领域和目标领域的枢纽特征,进而构建由这两个领域中枢纽特征和非枢纽特征形成的图,计算图中所有点之间的SimRank值,从而找到潜在情感空间,最后,把潜在情感空间中的词语作为特征,对源领域中已经标注情感倾向性的全部文本和目标领域中未标注情感倾向性的部分文本进行训练,得到倾向性分类模型,再利用此模型对目标领域中未标注情感倾向性的文本进行倾向性分析判断。下面通过例句具体说明一下:
Elec领域:“Nokia 8800外观漂亮,十分大气”
Stock领域:“综合看今天强势的反弹,笔者认为节前的调整已经全部结束,多头将在最后一个交易日展开全面反击,以一个漂亮的红色周K线迎接国庆的可能很大。”
来自不同领域的倾向性词汇“大气”和“强势”在“漂亮”作为枢纽特征即种子词的“链接”下,通过SimRank方法计算相似度,用于分析未标注文本的情感倾向性。
具体算法如下:
(1)构造枢纽特征集合P以及Ds和Dt的词语组成的图G。
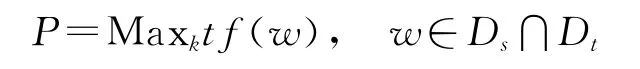
tf(w)为词语在某个领域中出现次数,Maxk表示出现次数最多的前k个词。源领域和目的领域的图G中节点代表词语,同时出现在一个句子中的各个词语之间存在一条边。
(2)选择种子词Seeds。利用Dic标注出P中有明显情感倾向性的词作为Seeds。本文所用的Dic是由文献[14]的情感词汇本体和 HowNet[15]中情感词构成。
(3)计算图G中的各个词语之间的SimRank值,构建潜在情感空间。

LES表示潜在情感空间,其是由满足上式的ws和wt词语对ws_wt组成,MaxSim(i,j)表示与词语i的SimRank值最大的词。
(4)把LES和Seeds中的词语作为特征词,对Ds的文本和部分Dt文本进行SVM训练,Seeds中的权值为1,LES的权重为其所属领域的SimRank值,利用得到的模型对Dt中的文本进行倾向性预测。
(5)该算法能够解决前文提到的两个问题。对于第一个问题,在酒店领域的评论“我很讨厌这个酒店,房间太小”中,“小”与具有否定倾向的“讨厌”共现,根据算法判断其倾向性为否定,同理,在电子领域的评论“我就喜欢这么小的电池”中,“小”的倾向性为肯定。同样,由于上述算法计算了所有共现词之间的SimRank值,在选择特征时能够考虑到特定领域的词,从而解决(1)提到的第二个问题。例如,在如图1所示中,Ds表示对酒店的评论文本,Dt表示电子产品的评论文本,由算法所得到的源领域和目标领域中与种子词“完美”的SimRank最大的词分别是“不错”和“耐用”,故“不错_耐用”成为潜在情感空间中的一个词,可以用在后续的分类特征。
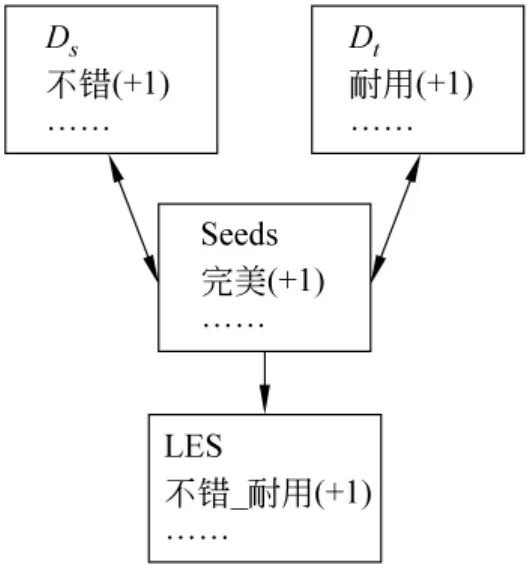
图1 LES示意图
4 实验结果与分析
4.1 语料来源
实验语料来自文献[3],该语料的规模如表2所示(“词典长度”表示数据集中不同词的数量),语料中包括三个领域的评论,分别是:电子评论Elec(来源于:http://detail.zol.com.cn/),财经评论Stock(来源于:http://blog.sohu.com/stock/)及酒店评论 Hotel(来源于:http://www.ctrip.com/)。所有评论均已由专家进行了倾向性标注。
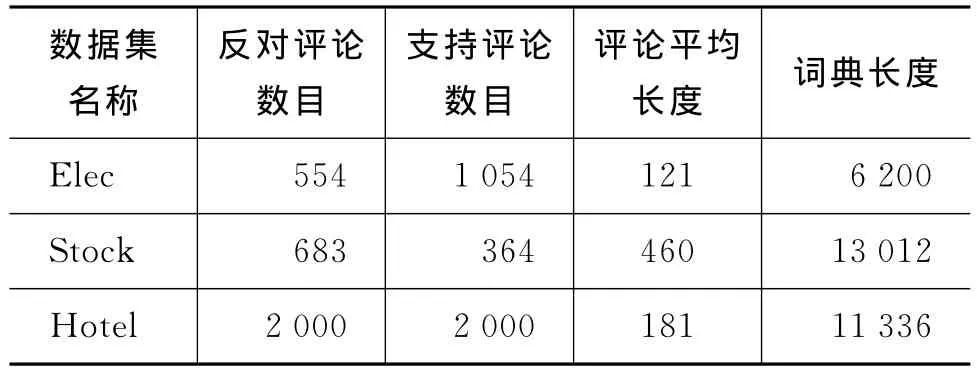
表2 实验语料规模
4.2 对比实验的描述
本文对实验语料所包括的三个领域,两两之间分别作跨领域倾向性分析实验,共计6组实验。本文的实验进行了如下的预处理:首先,使用中国科学院ICTCLAS分词系统[16]对所有语料文本进行分词,然后去停用词,并针对各领域进行词频统计,去除出现次数小于3次的低频词。最后利用词频统计结果和Dic得到Seeds。
本文所用的Dic的规模如表3所示。
分别计算Ds和Dt中经处理后得到的词之间的SimRank值,按照本文上述算法,得到LES。对Ds和部分Dt文本使用SVM-light工具包[17]进行训练,使用其中的线性核,所有参数都使用默认值。针对Dt文本,利用训练后得到的模型进行倾向性预测。
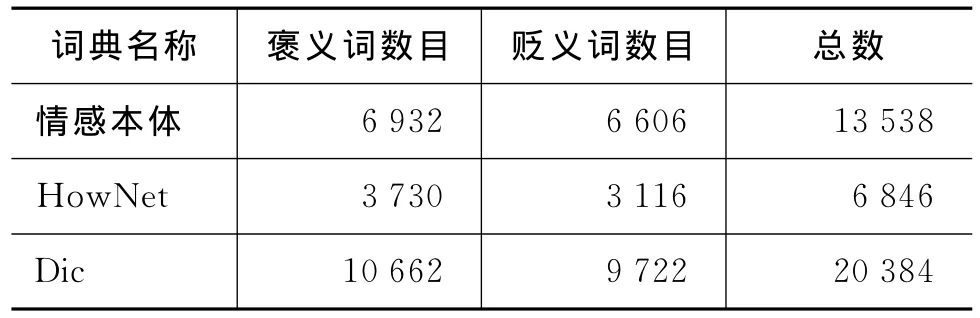
表3 Dic的规模
4.3 实验结果
本文使用准确率(Accuracy)作为评价指标,准确率是指预测的文本倾向性和经专家标注的文本的倾向性一致的文本数目占所预测文本总数的比例。

文献[3]中把用SVM训练分类作为Baseline,同时使用SCL和文中算法进行了实验,本文以文献[3]的实验结果作为对比实验。本文实验结果如表4所示。
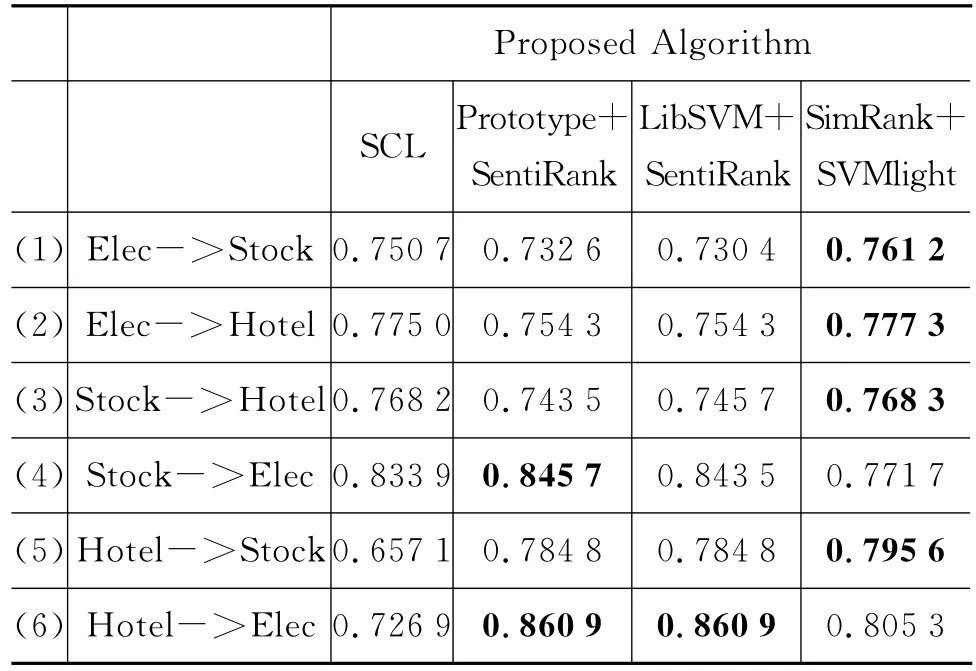
表4 实验结果对比
4.4 实验结果分析
本文提出的基于SimRank的方法(以下简称SR算法)在实验(1)(2)(3)(5)中取得了最佳的结果,体现了本文方法的有效性及鲁棒性,但在实验(4)(6)中没有文献[3]中的SentiRank方法突出,以下部分将对实验结果进行深入的分析。
SentiRank方法以SCL算法作为对比算法,结果显示:在(1)(2)(3)上使用SCL算法得到的结果都优于SentiRank方法,可见种子词即同时出现在源领域和目标领域的高频词汇对跨领域情感分析起着重要作用。
正如第3节所述,本文的算法本质上和SCL算法的思想一致,均是利用两个领域中与领域无关的词语作为桥梁,从而解决跨领域情感倾向性分析问题,但是原始的SCL算法考虑的较为简单,仅仅是对矩阵进行SVD分解,不能够准确、深入地挖掘出两个领域的潜在情感空间,进而影响了实验结果的准确度,SR算法是对其的一个改进,考虑到利用SimRank算法挖掘共现的词语的相似性,将源领域及目标领域中与种子词SimRank值最大的词形成词对,从而更准确地构成潜在情感空间,实现了利用种子词把两个领域更好地联系了起来,所以在实验(1)(2)(3)中都取得了最好的效果,从实验结果我们可以看到,本文使用SimRank算法进行潜在情感空间的选择在一定程度上能够提高SCL算法的性能,因此本文的SR算法在这个三组实验的结果要优于SCL算法。
文献[3]的实验结果表明SentiRank方法在实验(4)(5)(6)中得到的结果好于SCL算法,分析原因可知,由于SCL算法的思想主要考虑词汇的共现信息且分析对象粒度为整个篇章(在本文实验中即为整条评论),很大程度上会受到低频词及数据集大小影响,同时枢纽特征的选择也对SCL算法有至关重要的影响。
而本文的SR算法同时也有一定局限性,在后三个实验中只有一组结果优于对比实验的结果,即在(5)上结果要好于SCL及SentiRank方法,而在实验(4)(6)中的结果没有SentiRank方法表现的好,分析原因可知,从另一个方面是因为SR算法类似于SCL算法,但是要优于SCL算法,其同样会受到低频词、数据集大小及种子词选择的方面的影响,这一点可以从三个数据词典的长度得出(Elec:6 200,Stock:13 012,Hotel:11 336)。在实验(4)(6)中都是由于Stock和Hotel领域的数据词典长度都约为Elec的2倍,其不可避免的引入了一定的噪音,影响了实验的结果,而实验(5)由于Hotel与Stock领域数据大小相似,故SR方法的结果在三种方法中表现最好。
同时较之SentiRank提出的方法,未考虑源领域和目标领域之间文本的相似性,也是SR算法的结果在(4)(6)两组实验上不如SentiRank结果的原因之一,其也是以后的研究中进一步需要考虑的问题,将SR算法结合不同领域间文本相似性这一重要信息深入挖掘跨领域文本的情感倾向性。
5 总结与展望
本文提出一种基于SimRank的跨领域倾向性分析算法用于解决不同领域中情感倾向性分析的问题。该算法使用源领域和目标领域中出现次数最多的情感词作为连接两者的枢纽特征,利用两个领域中词语构成的图上计算这些枢纽特征的SimRank值,进而构建潜在情感空间,把潜在情感空间中的词语作为分类特征,使用SVM分类器对源领域进行训练,用得到的分类模型对目标领域的文本进行情感倾向性判断。6组实验的结果表明本文算法是有效的。下一步的工作可以考虑融入语法分析,对算法加入与领域相关的情感倾向性判定因素,同时,本文仅仅考虑两个领域之间的情感倾向性迁移问题,以后的工作可以在多个领域间进行情感倾向性判定。
[1]V.Hatzivassiloglou,K.R.McKeown.Predicting the semantic orientation of adjectives[C]//Proceedings of ACL97,Madrid,ES,1997:174-181.
[2]Pang B,Lee L,Vaithyanathan S.Thumbs up?Sentiment classification using machine learning techniques[C]//Proceedings of EMNLP2002, Philadelphia,USA,2002:79-86.
[3]Qiong Wu,Songbo Tan,et al.SentiRank:Cross-Domain Graph Ranking for Sentiment Classification[C]//2009IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology,Milano,Italy,2009:309-314.
[4]S.J.Pan,X.C.Ni,J.T.S,et al.Cross-domain sentiment classification via spectral feature alignment[C]//Proceedings of the 19th International Conference on World Wide Web,Raleigh NC,USA,2010:751-760.
[5]Christian Scheible.Sentiment Translation through Lexicon Induction[C]//Proceedings of the ACL 2010 Student Research Workshop,Uppsala,Sweden,2010:25-30.
[6]Hu M,Liu B.Mining and summarizing customer reviews[C]//Proceedings of the 2004ACM SIGKDD,Washington,USA,2004:168-177.
[7]J.Blitzer,M.Dredze,F.Pereira.Biographies,bollywood,boom-boxes and blenders:domain adaptation for sentiment classification[C]//Proceedings of the 45th Annual Meeting of the Association for Computa-tional Linguistics,Prague,Czech Republic,2007:440-447.
[8]W.Dai,Q.Yang,G.Xue,et al.Boosting for transfer learning[C]//Proceedings of the 24th International Conference on Machine Learning,Corvallis,OR,2007:193-200.
[9]S.-I.Lee,V.Chatalbashev,D.Vickrey,et al.Learning a meta-level prior for feature relevance from multiple related tasks[C]//Proceedings of the 24th International Conference on Machine Learning,Corvallis,OR,2007:489-496.
[10]J.Jiang,C.X.Zhai.A two-stage approach to domain adaptation for statistical classifiers[C]//Proceedings of the 16th ACM Conference on Information and Knowledge Management ,Lisboa,Portugal,2007:401-410.
[11]Aue,Anthony,Gamon,et al.Customizing Sentiment Classifiers to New Domains:a Case Study[C]//Proceedings of the International Conference on Recent Advances in Natural Language Processing,Borovets,BG,2005.
[12]Glen Jeh,Jennifer Widom.SimRank:A Measure of Structural-Context Similarity[C]//Proceedings of the 8th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,Alberta,Canada,2002:538-543.
[13]许晟,李亚楠,王斌.基于加权SimRank的中文查询推荐研究[C]//第五届全国信息检索学术会议(CCIR2009),上海,中国,2009:242-251.
[14]徐琳宏,林鸿飞,潘宇,等.情感词汇本体的构造[J].情报学报,2008,27(2):180-185.
[15]http://www.keenage.com/
[16]http://ictclas.org/
[17]Vapnik V.The nature of statistical learning theory[M].New York:Springer-Verlag,1995.
