常用现代汉语副词用法自动识别研究
2012-10-15张坤丽昝红英柴玉梅
张坤丽,赵 丹,昝红英,柴玉梅
(郑州大学 信息工程学院,河南 郑州450001)
1 引言
现代汉语副词的研究,自《马氏文通》问世以来,始终是广大语法学者关注的一个重要的课题。尽管汉语副词绝对数量并不是很多,但其功能和用法纷繁多样,不但使用范围广、频率高,且其内部成员虚实不一,有些副词承载着语义的变化,而有些副词承载着语法功能,包括搭配关系、语用倾向以及篇章功能,大都各具特点,每一个都具有很强的个性,所以缺乏系统性和规律性[1]。因此针对具体的副词,对其用法进行自动识别,具有重要的意义。
本文中副词用法自动识别在俞士汶等[2]提出的构建三位一体汉语广义虚词知识库思路的基础上,对昝红英等[3-4]已建立的副词用法词典和副词用法规则库进行了完善和补充,对《人民日报》2000年1~6月分词与词性标注的语料进行了人工校对,并以此作为实验语料,先采用规则进行用法自动识别,实验结果显示,规则总体有较好的识别准确率,但对较为常用且用法较多的副词,效果不佳,因此,本文又采用统计的方法对这些词进行用法自动识别。
本文具体章节安排如下:第2节介绍副词用法识别的相关研究;第3节介绍副词用法词典、副词用法规则库及副词用法语料库;第4节介绍分别采用规则和统计的副词用法自动识别实验;第5节给出了实验结果,并对结果进行分析;最后给出本文的总结,并对今后的工作进行展望。
2 相关研究
针对副词的研究,综合多年来汉语语法学界的研究成果,副词的主要研究包括:对副词性质、归属、范围和分类的研究;对副词个例的研究;对副词小类的研究等。其中较为著名的有陆俭明等的《现代汉语虚词散论》[5],张谊生的《现代汉语副词研究》[1]及《现代汉语虚词》[6],张亚军的《副词与限定功能描述》[7]等。副词的研究虽然硕果累累,但这些研究大都是面向人用的。
近年来,面向机器的研究也逐步开始。俞士汶等[2]最早提出了虚词机器词典、虚词规则库、虚词语料库“三位一体”构建现代汉语广义虚词知识库的思想,并将广义虚词界定为副词、介词、连词、助词、语气词和方位词;刘云[8]构建了汉语虚词词典的基本框架,为副词、介词、连词、助词和语气词等设计了相应的描述属性,对常用虚词进行了归类总结;昝红英等[3-4]构建了现代汉语广义虚词知识库,包括虚词用法词典、虚词用法规则库和虚词用法标注语料库;刘锐等[9]、袁应成等[10]采用基于规则的方法对虚词用法的自动识别进行了研究,昝红英等[11]还针对副词中的个例“就”采用统计模型进行了用法自动识别,而以上研究无论是基于规则还是基于统计的方法并没有建立在大规模语料库的基础上,或仅是对一些个例进行了研究,这对于将副词用法自动识别结果应用到自然语言处理领域还是远远不够的。
3 “三位一体”的副词知识库
3.1 副词用法词典
本文根据北京大学计算语言所《人民日报》1998年1月及2000年1~6月分词及词性标注语料,以及副词的实际应用,在文献[3-4]已有副词用法词典的基础上,进行了词条的调整及用法的总结和修改,与之前的版本相比,副词用法词典的规模有所扩大。原有副词用法词典[4]共收副词1 181个,用法共计2 040条,目前副词用法词典共收录1 587个副词,用法共计2 396条,其词条与用法分布如表1所示。

表1 副词词语与用法的分布情况
以副词“将”为例,抽取词典中ID、释义、用法和例句属性在表2列出。其中“ID”含义及“<>”中内容含义详见文献[3]。
3.2 副词用法规则库
在副词用法词典中对用法描述的基础上,结合词典中不同用法的例句以及真实语料《人民日报》中不同副词用法的特征,抽取其中具有可操作性的判断条件特征,以有序的BNF范式进行副词用法的规则描述,构建副词用法规则库。规则中大写字母为指定用法的上下文特征,F表示句首,M表示左搭配,L表示左紧邻,R表示右紧邻,N表示右搭配,E表示句尾;小写字母表示词性,汉字表示词形。用法规则的描述定义详见文献[3]。在建立副词用法语料库的过程中间,对发现的规则描述不准确或规则排序对用法自动识别的影响进行了讨论,反复修改了规则库中的规则及规则排序,通过实验测试确定最终的规则描述及排序。

表2 副词“将”的义项及用法

续表
针对表2中“将”的用法^描述,“将”的规则如下:
$将
@<d_jiang1_4>→R^R→够|能
@<d_jiang1_3b>→R^R→[不再|仍然|可能|始终|更可能]是
@<d_jiang1_2>→R^R→t
@<d_jiang1_3a>→M^M→(预计|估计|展望|表示|舆论|相信|评论|议题|认为|说|一经|一旦|如果|由于|随着|假如|假若|为了|根据|宣布|预测)*[,]
@<d_jiang1_1>→M|N^M→t*[,]^N→t
@<d_jiang1_3a>→N^N→a|v
d_jiang1_2、d_jiang1_3b、d_jiang1_4的用法描述容易形式化,但d_jiang1_1和 d_jiang1_3a用法相同且很难形式化。通过观察语料,当“将”与“预计……预测”等词(第4条规则所示)左搭配,或右搭配形容词(a)或动词(v)时(第六条规则所示)多为d_jiang1_3a用法,因此把d_jiang1_3a用两条规则进行描述,当“将”左或右搭配时间词(t)时,多为d_jiang1_1用法,而d_jiang1_1规则描述相对于第6条规则描述更为准确,因此把d_jiang1_1作为第5条规则。
由“将”的规则可知,一个用法可以由一条或多条规则进行描述,针对词典中2 396个用法,与之对应的虚词用法规则库共计2 497条规则。
3.3 副词用法语料库
在副词用法词典和规则库都已完善的基础上,参考词义语料库的建设经验和分析[12],先利用副词规则库中的规则对《人民日报》1998年1月以及2000年1~6月的语料进行了初步自动标注,然后再用人工校对的方法对语料中出现的副词用法标注进行确认和修改。
由于副词用法语料库是建立在北京大学计算语言所对《人民日报》进行分词及词性标注的基础上,所以在进行副词用法标注的过程当中,也发现了原语料中的词性标注错误或分词错误,对这一类问题用“@”在语料中标出。如果仅是词性不正确的用“<@POS>”表示,修改词性标注的样例如下:
我们/rr两/m国/n尽管/d<@c> 没有/df建交/vi,/wd但/c人员/n往来/vi频繁/a,/wd经贸/jb合作/vn 发展/vn 很/dc快/a ,/wd 展现/v出/vq双边/n关系/n的/ud美好/a前景/n和/c经贸/jb合作/vn的/ud巨大/a潜力/n。/wj
如果是分词及词性标注都不正确,则将正确的分词及词性标注在“@”后,修改分词及词性标注的样例如下:
这/rz道/qe菜/n的/ud原料/n不/d特殊/a,/wd但/c做工/n很/d巧妙/a,/wd也许/d只有/d<@只/d有/v> 老/a淳安/ns人/n会/vu做/v。/wj
为避免人工校对中个人因素所带来的用法标注的差异,每一份语料中的用法标注都是在机标的基础上经过多人校对并讨论确定的。校对后的《人民日报》语料副词词语与用法分布如表3所示,其中Cw表示出现副词用法词典中的词条数,Cf表示出现频次,Ce表示分词或词性错误,C表示正常标注用法频次。

表3 校对语料中副词词语与用法的分布情况
4 副词用法自动识别
4.1 基于规则的副词用法自动识别
基于规则的副词用法自动识别,就是对建立的副词规则库中的规则进行解析,根据特征去匹配语料库中的语句,具体为以下三个步骤。
(1)初始化标注语料、用法规则库,为方便大规模的语料自动标注,读取语料时将语料文本内容按照段落截句,将标注语料切分成一个个段落,以动态数组的形式读入内存,用法规则以哈希表的形式写入内存。
(2)读取待标注的整句,找出整句中所有需要标注的副词及对应规则,对整句进行预处理,得到对应的词表和原始语句,以及所有待标副词在词表和原始语句中的位置。
(3)查找待标副词的规则,并依序读取其用法规则信息,根据规则描述由匹配器调度程序确定触发的匹配器类型,再由相应匹配器解析用法规则,并进行对应匹配,根据匹配情况确定标注结果,待整句中所有副词都标注完后,输出整句,并转到上一步继续读取下一个整句,直至没有待标整句,标注程序结束。
自动标注系统用到六个类型(规则中的F、M、L、R、N、F)的匹配器的设计要求,及基于规则的副词用法自动标注系统的具体实现详见袁应成等[10]。
以副词“将”为例说明基于规则的用法标注过程,已经通过标注系统抽取含有“将”的句子如下:
明年/t春天/t,/wd将/d召开/v九/m 届/qe[全国/n人大/jn]nt一/m 次/qv会议/n和/c[全国/n政协/jn]nt九/m 届/qe一/m 次/qv会议/n。/wj
当检测到副词“将”之后,查找到“将”的规则,并按照规则排列顺序逐条进行匹配,以最终匹配上的规则@<d_jiang1_1>→M|N^M→t*[,]^N→t进行说明。
首先调用M匹配器,由M匹配器解析用法规则,根据词语的相对位置,先对规则描述中的时间词“t”进行实例化,在“将”之前的词语中找到“春天”与之匹配,“t”间隔0个字符(*)有“,”与规则匹配,因此规则中M匹配成功。M和N之间是或的关系,M匹配成功之后,整条规则匹配成功,最终将标注结果“<d_jiang1_1>”。
4.2 基于统计的副词用法自动识别
基于统计的经验主义方法是从训练数据中自动地或半自动地获取语言知识,建立有效的统计语言模型,并根据训练数据的实际情况不断地优化,而基于规则的理性主义方法很难根据实际的数据进行调整,因此规则方法在某些方面不如基于统计的经验主义方法好。
本文考虑到副词的用法与副词所在的上下文语境及语境序列有着紧密的依赖和限制关系。因此,本文选择了3个在机器学习领域应用比较广泛且效果较好的统计模型:条件随机场(Conditional Random Fields,CRF)模型、最大熵(Maximum Entropy,ME)模型和支持向量机(Support Vector Machine,SVM)模型。
CRF是一个在给定输入节点条件下计算输出节点条件概率的无向图模型,它考察给定输入序列对应的标注序列的条件概率,训练目标是使得条件概率最大化[13]。ME是一个广泛应用于分类问题的统计模型,基本思想是,将已知的知识建模,对未知的知识不做任何假定,即给定已知事件集合,在已知事件集上挖掘出潜在的约束条件,然后选择一种模型,这个模型必须满足已知的约束条件,同时对未知可能发生的事件尽可能使其均匀分布[14]。SVM是基于统计学习理论的学习方法,该方法通过使用一些策略来最大化具有不同特征的数据的中间界限,并针对数据的特征来判断该数据属于哪个类别[15]。
本文利用CRF++工具包[16]、Zhang Le的最大熵工具包 maxent[17]和 LibSVM 工具包[18]作为自动标注工具。
5 实验结果及分析
5.1 基于规则的副词用法自动识别结果及分析
本文利用《人民日报》2000年1~6月分词和词性标注的语料作为实验语料。首先用自动标注系统标注实验语料出现的所有副词得到机器标注结果,通过与人工校对后的标准语料比对,标注一致的就认为是识别正确的。实验对《人民日报》2000年1~6月中出现的所有副词的标注结果进行了统计。
本文采用准确率来衡量副词用法的自动识别结果,具体见式(1):

其中C1为标注正确的副词总数,C2为副词出现词频减去分词或词性错误的个数,即校对语料中正常标注的次数。实验结果如表4所示,另外对2000年1月到6月副词用法识别准确率的分布情况作以统计,其中“CP>0.8”表示准确率高于0.8的用法个数,“C0.5≤P≤0.8”表示准确率在0.5与0.8之间的用法的个数,“CP<0.5”表示准确率低于0.5的用法个数。
从表4的汇总的结果看,总体准确率为84.86%,从准确率分布来看,高于80%的用法个数为1 411个,占已出现用法1 656个的85.2%,说明基于规则进行副词用法自动标注有一定的效果。进一步对语料中出现频次较高(频次>2 000次)并且用法较多(用法>4个)的副词准确率进行统计,按准确率降序排列,如表5所示。从表中数据可看出,共有17个词语符合要求,而其中有8个词语的准确率高于80%,并且在规则描述时也发现,用法的个数及用法描述是否容易形式化,都是影响规则识别准确率的因素。用法越多,规则之间的冲突也就越明显,规则识别的准确率越低,所以在这些高频词中,用法多的副词采用规则自动识别的效果较差。

表4 基于规则的副词用法识别结果

表5 高频副词规则识别准确率统计

续表
5.2 基于统计的副词用法自动识别结果及分析
实验语料与5.1节中相同,选取表5中规则识别准确率低于80%的9个副词,采用统计方法进行自动用法识别。基于统计方法进行自动识别的结果,与特征模板、上下文窗口大小、统计模型的选取是有关的,因此从这三个方面进行实验。在实验过程中采用十折交叉验证进行测试。
首先,在副词用法描述中,通常情况下是以副词前后搭配的词或词性不同作为用法的区分,但是不同的副词,特征也不同,因此采用不同的特征,即词(W)、词性(POS)和词+词性进行实验,采用窗口为左2右2,仅列出其中3个词的实验结果,如图1所示。从实验结果可以看出,不同词的最高的准确率特征也不相同,说明在实验过程中对于不同的词要通过对比实验确定选取哪种特征。
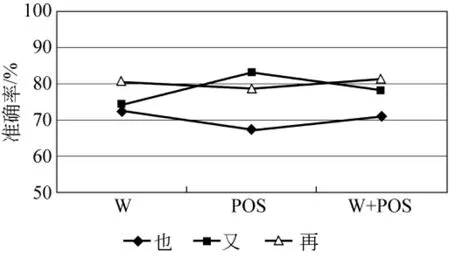
图1 不同特征对副词用法识别的影响
其次,根据副词用法的语境特点,分别选取不同的上下文窗口,采用CRF的统计方法,针对图1中已经确定的最好特征,即“也”采用词为特征,“又”以词性为特征,“再”用“词+词性”为特征,考察在不同窗口下副词用法识别的准确率,采用对称窗口进行实验,“L”表示左窗口大小,“R”表示右窗口大小,实验结果如图2所示。从实验结果可以看出,不同的词,上下文窗口的大小对识别准确率影响也不同。

图2 不同窗口对副词用法识别的影响
第三,根据不同窗口和不同特征模板对实验结果的影响,采用多次实验,将CRF、SVM和ME的最好实验结果及相关参数在表6中列出。CRF实验结果受特征和窗口大小的影响,而对ME和SVM仅考虑窗口大小的影响。通过对比实验,发现就选取的这9个词而言,除“正”之外,CRF效果相对较好,规则方法的宏平均准确率为59.68%,而CRF的宏平均准确率为86.71%,提高了27.03%,实验选取的词都是高频词,所以将会对全部副词用法识别准确率有较大的提升。

表6 不同的模型对副词用法识别的影响
6 总结及展望
采用“三位一体”的构建现代汉语广义虚词知识库的思想,本文根据已建立的副词用法词典和副词用法规则库以及副词用法语料库,针对副词的个性差异,实现了基于规则的副词用法的自动识别,并采用CRF、ME、SVM模型对常用副词实现了基于统计的用法自动识别。实验结果显示,规则识别的总体准确率能够达到84.86%,而对其中的规则识别效果不好的高频常用词,采用统计的方法可进一步将这部分高频词的识别准确率提高27.03%。
下一步我们将继续完善副词用法词典和规则库,构建完备精确的面向自然语言处理的现代汉语广义虚词知识库。另外尝试根据语料中副词用法分布的相对频率,对规则进行加权处理,采用规则和统计相结合的方法,或者采用多分类器集成的方法,提高副词用法自动识别的准确率。同时,也尝试将副词用法的自动识别结果应用在机器翻译或褒贬评价等自然语言处理领域,以期取得较好的效果。
[1]张谊生.现代汉语副词研究[M].上海:学林出版社,2001.
[2]俞士汶,朱学锋,刘云.现代汉语广义虚词知识库的建设[J].汉语语言与计算学报,2003,13(1):89-98.
[3]昝红英,张坤丽,柴玉梅,等.现代汉语虚词知识库的研究[J].中文信息学报,2007,21(5):107-111.
[4]昝红英,朱学锋.面向自然语言处理的汉语虚词研究与广义虚词知识库构建[J].当代语言学,2009,2:124-135.
[5]陆俭明,马真.现代汉语虚词散论[M].北京:语文出版社,1999.
[6]张谊生.现代汉语虚词[M].上海:华东师范大学出版社,2000.
[7]张亚军.副词与限定功能描述[M].合肥:安徽教育出版社,2002.
[8]刘云.汉语虚词知识库的建设[D].[博士后出站报告].北京:北京大学,2004.
[9]刘锐,昝红英,张坤丽.现代汉语副词用法的自动识别研究[J].计算机科学,2008,8(A):172-174.
[10]袁应成,昝红英,张坤丽,等.基于规则的虚词用法自动标注算法设计与系统实现[C]//第十一届汉语词汇语义学研讨会论文集,苏州:苏州大学,2010:163-169.
[11]昝红英,张军珲,朱学锋,等.副词“就”的用法及其自动识别研究[J].中文信息学报,2010.24(5):10-16.
[12]金澎,吴云芳,俞士汶.词义标注语料库建设综述[J].中文信息学报,2008,22(3):16-23.
[13]Lafferty J,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18th ICML-01,2001:282-289.
[14]Berger A.L,Della Pietra V.J,Della Pietra S.A.A maximum entropy approach to natural language processing[J].Computational Linguistics,1996,22(1):39-71.
[15]http://www.support-vector.net[CP/OL].
[16]CRF++:Yet Another Toolkit[CP/OL].http://www.chasen.org/~taku/software/CRF++.
[17]http://homepages.inf.ed.ac.uk/s0450736/maxent_toolkit.html[CP/OL].
[18]http://www.csie.ntu.edu.tw/~cjlin/libsvm[CP/OL].
