基于用法的现代汉语连词结构短语识别研究
2012-10-15昝红英周丽娟张坤丽
昝红英,周丽娟,张坤丽
(郑州大学 信息工程学院,河南 郑州450001)
1 引言
连词是一种具有连接作用的虚词,能够连接词语、短语、小句、句子乃至句群,可以表示并列、选择、转折、递进、目的、因果等多种关系。能够连接词语、短语的连词,例如,“和、与、并、及、或、而、甚至、以、以至”等;连接小句、句子的连词,例如,“不但、虽然、如果、与其、然而”等;连接句群的连词,例如,“再次、总之、由此可见”等。连词结构短语指的是连接词语、短语的连词所连接的包含连词在内的短语,即含有连词的有标记联合短语。根据表示关系的不同可以细分成不同的连词结构短语,例如,由“和、与、并、及”构成并列的连词结构短语,由“或”构成选择的连词结构短语,由“而”构成转折或补充的连词结构短语等。本文用一对“<CP_xx>”和“</CP_xx>”来标记连词结构短语,其中“xx”表示连词结构的关系类别,如下面例句所示,其中“bl、xz、bc”分别是并列、选择、补充等关系的汉语拼音缩写。
(1)<CP_bl>改革、发展和稳定</CP_bl>的任务十分繁重。
(2)消费者愿意为<CP_xz>新型产品或现有产品的改进型</CP_xz>支付更高的价钱。
(3)大家的心情<CP_bc>激动而又新奇</CP_bc>。
连词结构短语的识别有助于提高机器翻译的质量。如下面是美国斯坦福国际咨询研究所(SRI)中提供的句子汉英翻译结果。
(4)当天,<CP_bl>长崎市民团体和原子弹爆炸受害者</CP_bl>等约70人在长崎和平公园静坐。
译文:On the same day,victims of the atomic bombings of nagasaki civic groups and about 70 people,including the peace park in nagasaki meditation.
(5)如果<CP_xz>狗换了主人或主人地址变更</CP_xz>,要及时更新登记信息 。
译文:If a dog in the address of the owner or master of change,and to update information in a timely manner.
如果能正确识别汉语句子中的连词结构短语,那么在翻译时首先可以确保这个短语不会翻译错,也不会把短语的成分和句子的其他成分混淆。因此,连词结构短语的识别具有重要意义。
2 相关研究
周强[1]通过计算词语的相似度来寻找联合结构形成的最优路径,主要是利用从树库中得到的数据,构造统计模型,进行短语自动界定处理,并根据错误事例和语言学知识形成调整规则来降低自动界定的错误率。孙宏林[2]根据联合成分之间的对称性对连词左右两边的词串进行概率评分,选择一个概率最大的组合从而进行识别。吴云芳[3]从语言学角度研究并列结构的特点,根据中心语相似和结构平行识别有标记并列结构,通过辨别同类词连用形成的歧义格式识别无标记并列结构。王东波等[4-5]采用条件随机场模型,并结合语言学特征识别有标记的联合结构。
本文在王东波的基础上,结合虚词用法知识库中连词的用法来识别连词结构短语。首先根据连词的用法对每个可以连接词语、短语的连词编写若干条规则,实现基于规则的连词结构短语识别。然后将连词用法作为特征,采用条件随机场模型实现基于统计的连词结构短语识别,进而分析了不同长度的连词结构短语识别情况,并与未加入连词用法特征的方法进行了比较。
3 基于规则的连词结构短语识别
3.1 构建连词结构短语识别规则库
在连词用法词典和连词用法规则的基础上,对各个连词的用法进行了考察,找到每个用法所对应的连词结构短语的形式化表示或边界,然后抽取其中具有可操作性的判断条件特征,以有序的BNF范式描述连词结构短语的识别规则。因为连词结构短语涉及到左右两个边界,所以目前抽取的主要识别特征有:左搭配M、左紧邻L、右紧邻R、右搭配N。另外在规则库中引入了其他一些符号,如A表示同词性同词,B表示同词性不同词。识别规则的一般描述形式为:
<ID>→[M][L][R][N]
M→<词语1>|<词语2>|…|n|v|a|…
L →<词语1>|<词语2>|…|n|v|a|…
R →<词语1>|<词语2>|…|n|v|a|…
N →<词语1>|<词语2>|…|n|v|a|…
其中,规则元语言中的符号“→”表示定义为,符号“|”表示多选一,规则右部顺序出现的字符表示其所代表的特征属性为有序合取关系。规则中的符号<ID>为连词用法编码,“<词语>”表示该属性位置上出现的词语,“n、v、a”等表示该属性位置上出现的词性。连词结构短语识别规则的描述形式类似于连词用法规则的描述形式,不同的是连词结构短语识别规则中没有用到句首F和句末E这两个特征,并且<ID>后的定义不是这个用法的定义,而是这个用法所对应的连词结构短语的定义。连词用法词典和连词用法规则的详细说明可以参考文献[6]。下面是连词“和”的结构短语识别规则:
$和
@<c_he2_1>→B~B^B→n|a|v
@<c_he2_1a>→B、{B、}~B^B→a|v|n
@<c_he2_1a>→MN^M→X、^N→</CP>(等|的)
@<c_he2_1c>→B~B^B→a|v
@<c_he2_1c>→MN^M→v^N→n
@<c_he2_2>→MN^M→(无论|不论|不管)<CP> ^N→</CP>(,|。)
@<c_he2_1b>→MN^M→X(、|与|同|及|以及)^N→(、|与|同|及|以及)X
用法“c_he2_1a”表示连接三项以上成分,它对应的连词结构短语的左边界是第一个成分,右边界是最后一个成分,因此这个连词结构短语就用“B、{B、}~B”表示。“c_he2_2”用法用于“无论、不论、不管”后,它对应的连词结构短语的左边界是“无论、不论、不管”后的第一个词语,右边界没有明显的特点,就规定到小句末尾。规则中的“<CP>”和“</CP>”是连词结构短语的开始和结束标记。默认情况下,M、L对应左边界,R、N对应右边界,这时不用加标记。然而“c_he2_2”对应的短语左边界在M所定义的那些词之后,所以在“无论、不论、不管”后加上“<CP>”,表示左边界在这些词之后。同理,加上“</CP>”表示右边界在对应这些词语的前面。
3.2 基于规则的连词结构短语识别
基于规则的连词结构短语识别程序是以行为单位进行文本处理的,处理一行文本的具体流程如下。
(1)读取一行文本,按逗号、分号、冒号、句号、问号、叹号分割成小句。
(2)判断小句是否为空及是否含有连词。若不为空且含有连词,记录连词所在的位置pos及用法编码ID;否则,将该小句写入结果文件,处理下一个小句直到全部处理完。
(3)根据ID从规则文件中解析规则,得到ID对应的连词结构短语的规则表示,记为S。若找不到ID,将这个小句中的ID左边的字符串(包括ID)写入结果文件,ID右边的字符串设为新的小句,转至(2)。
(4)从S中获得连词结构短语左右边界的特征及定义,并根据是否含有“<CP>”和“</CP>”确定边界的位置。
(5)根据连词结构短语左右边界的特征在pos前后匹配。若匹配成功,根据连词用法词典,得到ID对应的关系标记xx,左边界前插入“<CP_xx>”,右边界后插入“</CP_xx>”,并将这个小句中的ID左边的字符串(包括ID)写入结果文件,右边的字符串设为新的小句,转至(2);否则,解析ID对应的下一个连词结构短语的规则表示,转至(3)。
本文的实验语料是“北京大学计算语言学研究所”提供的2000年1月《人民日报》分词与词性标注语料,并由“郑州大学自然语言处理实验室”预先完成其中连词用法的标注[6],实验的输入和输出语料如下所示。
输入:改革/vn、/w发展/vn和/c<c_he2_1a>稳定/vn的/ud任务/n十分/d繁重/a。/wj
输出:<CP_bl> 改革/vn、/w 发展/vn和/c<c_he2_1a> 稳定/vn</CP_bl> 的/ud任务/n十分/d繁重/a。/wj
通过规则识别与多人交叉人工标注校对的连词结构短语的正确答案进行比较,正确答案中所有连词结构短语总共有14 169个,准确率为48.67%,召回率为30.98%,F值为39.19%。规则识别结果比较低,主要原因是,规则是根据有限的语料人工总结的,具有局限性和片面性。如下面句子是“和”的部分规则识别结果。第一个句子(6)用法为“c_he2_1”,但它的结构并不是左右两边都是名词、形容词或动词,这样规则就无法表示。第二个例句(7)跟“c_he2_1a”的第二个规则很接近,右边界标注正确,因左边界未找到正确的位置“节水/vi”,仍然无法完全标注正确。第三个例句(8)是动词短语的并列,符合“c_he2_1c”的第二个规则,在确定右边界时采用最小匹配,找到第一个名词就结束,导致标注错误。因此,本文下面尝试基于统计的连词结构短语识别。
(6)20000101-01-001-002/m — —/wp 在/p首都/n各界/rz迎接/v新/a世纪/n和/c<c_he2_1> 新/a千年/t庆祝/vn 活动/vn 上{shang5}/f的/ud讲话/n
(7)各地/rz开展/v的/ud节水/vi<CP_bl>灌溉/v、/wu 打井/vi、/wu 集/Vg 雨/n 节灌/vn和/c<c_he2_1a> 灌区/n节水/vn</CP_bl>等/u工作/vn,/wd
(8)<CP_bl> 发展/v地方{di4fang1}/n经济/n和/c<c_he2_1c> 保持/v社会/n</CP_bl>稳定/vn ,/wd 两者/rz是/vl相辅相成/iv 的/ud。/wj
4 基于统计的连词结构短语识别
4.1 条件随机场统计模型
基于统计的经验主义方法是从训练数据中自动地或半自动地获取语言知识,建立有效的统计语言模型,并根据训练数据的实际情况不断地优化,而基于规则的理性主义方法正如前面一部分所述,事先总结好的,很难根据实际的数据进行调整,因此规则方法在某些方面不如基于统计的经验主义方法好。本文采用条件随机场(Conditional Random Field,CRF)模型进行连词结构短语识别。
CRF模型[7]是由Lafferty在2001年提出的一种典型的判别式模型,给定输入节点值,通过训练学习,计算给定输出节点的条件概率,并使得条件概率获得最大值。近年来,该模型在中文分词[8]、中文命名实体识别[9]、歧义消解[10]等汉语自然语言处理任务中有广泛的应用。连词结构短语识别可以看成是文本中词语与词性序列选择标记、确定边界的过程。因此本文选择CRF模型来确定边界,识别连词结构短语。
4.2 特征及特征模板的选取
CRF模型是序列标注问题,能充分考虑上下文中的特征,综合利用词和词性等特征。优点是可以任意加入与处理对象有关的语言学特征,作为一个独立的语言学结构。在连词结构短语的识别中,很显然,有连接功能的连词以及顿号对短语的识别有一定的帮助作用。因此,本文选择词语、词性以及连接功能标记作为特征。为了判别连词用法对连词结构短语的识别是否有影响,本文采用两组特征集,这两组特征集的区别在于连接功能标记。特征集Ⅰ
特征模板采用25个特征,其中词语为7个窗口,范围是{-3,-2,-1,0,1,2,3},词性为5个窗口,范围是{-2,-1,0,1,2},连接结构标记为5个中,连接功能标记为Y和N,即如果是连词或顿号,标记为Y,其他情况标记为N。特征集Ⅱ中,如果是连词,标记用连词用法的ID表示;如果是顿号,标记为Y;其他的情况标记为N。
连词结构短语的识别标记参考王东波[4-5]使用的方法,根据公式得出语料中连词结构短语的平均长度,从而确定使用7词位标注集。其中,Ni表示长度为i的连词结构短语的个数,K表示连词结构短语的最大长度,N表示连词结构短语的总个数。连词结构短语的长度指的是连词结构短语中词语的总个数,并且包括连词在内,所以长度的最小值为3。具体的标注集为T= {B,S,T,F,M,E,O},其中B是连词结构短语的开始词,S是短语中第二个词,T是短语中第三个词,F是短语中第四个词,M是短语中第五个以上(包括第五个)的词,E是短语结尾的词,O是连词结构短语外部的词。两组特征集如表1所示,其中表1a是特征集Ⅰ,表1b是特征集Ⅱ。窗口,范围是{-2,-1,0,1,2}。其中0代表当前位置,-1代表左边第一个位置,1代表右边第一个位置。

表1b 特征Ⅱ表示
4.3 基于统计的连词结构短语识别结果及分析
基于统计方法的实验语料和规则的实验语料一样,采用10折交叉进行验证实验。具体流程如图1所示。

图1 基于统计的连词结构短语识别过程
对语料中的所有连词结构短语进行实验,结果如表2所示。结果显示,基于统计的方法比规则方法提高很多,并且使用连词用词特征的识别结果比没有使用连词用法特征的识别结果好,这初步说明了连词的用法对连词结构短语的识别有一定的帮助。因为从某些连词的用法上能够确定某些连词结构短语的边界,所以可以将连词用法应用在连词结构短语的识别中。

表2 基于统计的连词结构短语识别结果
连词结构短语的长度不同,表现的特点也不一样。这里,连词结构短语的长度指的是连词结构短语中词语的总个数。为了训练得到更好的模型,本文对不同长度的连词结构短语分别进行训练和测试,这里只考虑简单结构(不含嵌套结构),结果如表3所示。明显地,不同的长度识别结果不同,长度越短识别效果越好。另外,连词用法特征对各种长度的识别效果不同。其中,长度为3、5、8、10及10以上时,准确率、召回率和F值都有所提高,最高提高了4.29%;长度为4、6、9时,准确率提高,而召回率和F值降低;只有长度为7时,准确率、召回率和F值都降低,下降0.5%左右。原因可能是,连词用法词典及规则还不完善,连词用法标注可能存在错误的现象,这时就会引入噪声数据,从而影响连词结构短语的识别结果。不过,从总体上来看,用法特征对识别结果起到促进作用。
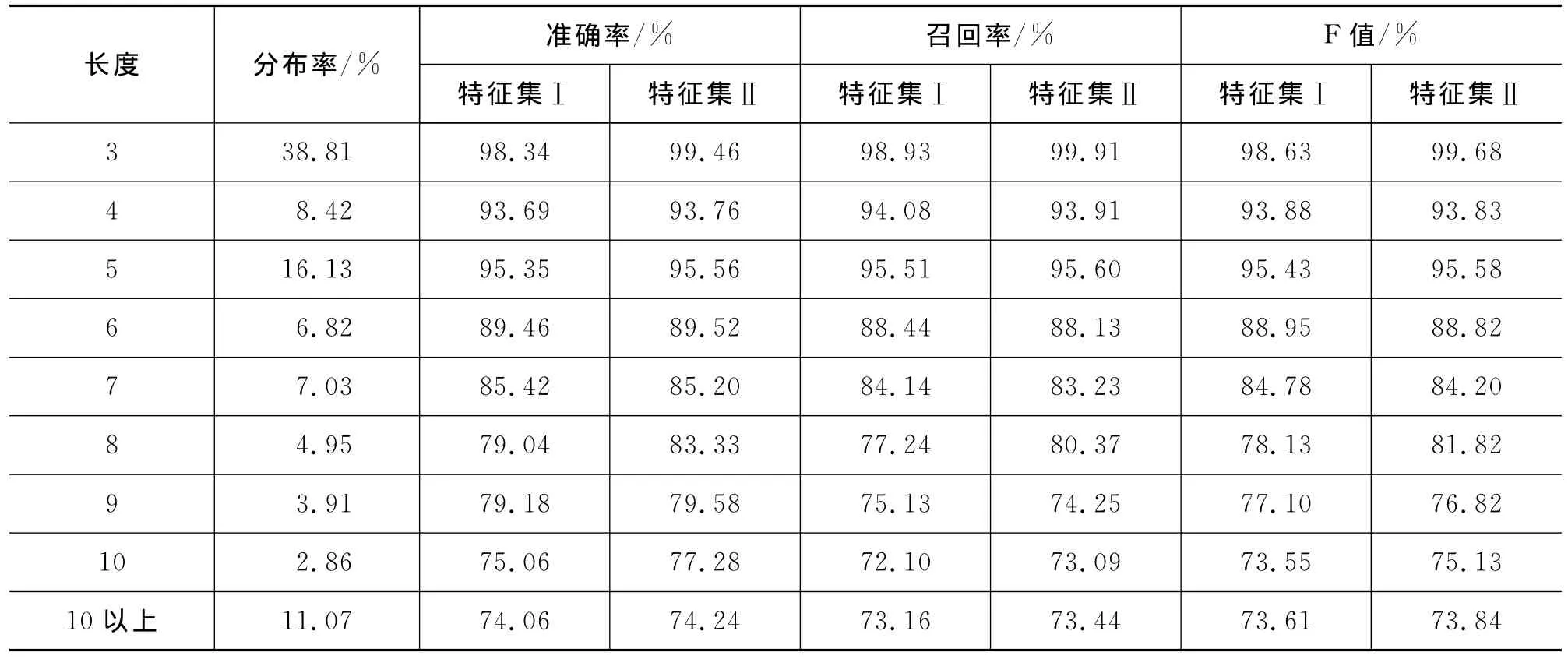
表3 不同长度的连词结构短语识别结果
不同连词所连接的连词结构短语识别情况也有所差异,本文对连词所连接的连词结构短语总数中位于前6位的连词分别进行了考察,涉及到4种关系的连词结构短语,包括并列关系(由“和、与、及、并”连接)、转折关系(由“而”连接)、补充关系(由“而”连接)、选择关系(由“或”连接)。其中连词“和”出现的次数将近一半,它所连接的短语占76,14%,说明所有短语中并列结构短语居多。表4、5、6分别显示的是不同连词所连接的长度为3、5、8的短语识别结果。分布率Ⅰ表示某个连词连接的某个长度的短语个数与这个长度的短语总个数的比例,分布率Ⅱ表示某个连词连接的某个长度的短语个数与这个连词所连接的短语总个数的比例。虽然从每个长度的总体识别结果来看,连词的用法促进了连词结构短语的识别,但是也存在一些词,连词的用法起到相反作用,如长度为5时的“和、与、及、而”。

表4 长度为3的常用连词的短语识别结果

表5 长度为5的常用连词的短语识别结果

表6 长度为8的常用连词的短语识别结果
5 结论
本文利用连词的用法分别实现了基于规则和统计的连词结构短语识别,基于条件随机场统计模型的识别结果明显高于规则的识别结果,虽然连词用法没有提高很多的识别效果,但是实验结果表明连词用法对连词结构短语的识别是有帮助的。下一步,将根据连词用法知识库尝试把更多的语言学特征加入到连词结构短语识别中,并将不同长度短语的识别也扩展到复杂结构中,期望能为机器翻译提供更好的预处理知识。
附录A 连词“和”的部分属性说明

ID 释义 用法例句c_he2_1 表示平等的联合关系。<b>连接类别或结构相近的并列成分。<b><CP_bl>老师~同学</CP_bl>都赞成这么做<b>|<CP_bl>稻场上~小溪边</CP_bl>顿时少了那些女人们的踪迹<x>c_he2_1a 表示平等的联合关系。<b>连接三项以上时“和”放在最后两项之间,前面的成分用顿号连接。<b>一切事物都有<CP_bl>发生、发展~消亡</CP_bl>的过程<b>|<CP_bl>北京、上海、天津~重庆</CP_bl>都是直辖市<x>c_he2_1b 表示平等的联合关系。<b>多项并列成分如果有几个层次,可用“和”表示一种层次,用顿号或“与、同、以及、及”表示另一种层次。<b><CP_bl>爸爸、妈妈~哥哥、姐姐</CP_bl>都不在家<b>c_he2_1c 表示平等的联合关系。<b>连接做谓语的动词短语、形容词短语时,动、形限于双音节。谓语前或后必有共同的附加成分或连带成分。<b>事情还要进一步<CP_bl>调查~了解</CP_bl><b><x>|泰山的景色十分<CP_bl>雄伟~壮丽</CP_bl><b>c_he2_2 表示选择,相当于“或”。<x> 常用于“无论、不论、不管”后。<b> 这意味着,只要在沪注册的企业不论<CP_xz>所有制~归属</CP_xz>,都可以享受这一政策。<r>
[1]周强.汉语语料库的短语自动划分和标注研究[D].北京:北京大学,1996.
[2]孙宏林.现代汉语非受限文本的实语块分析[D].北京:北京大学,2001.
[3]吴云芳.面向中文信息处理的现代汉语并列结构研究[D].北京:北京大学,2003.
[4]王东波,陈小荷,年洪东.基于条件随机场的有标记联合结构自动识别[J].中文信息学报,2008,22 (6):3-8.
[5]Dongbo Wang,Danhao Zhu,Xinning Su,et al.Automatic Identification of Parallel Structure Based on Conditional Random Field[C]//Proceedings of the 3rd International Symposium on Computer Science and Computational Technology(ISCSCT'10),Jiaozuo,2010:400-404.
[6]Hongying Zan,Lijuan Zhou,Kunli Zhang.Studies on the Automatic Recognition of Modern Chinese Conjunction Usages[J].Lecture Notes in Computer Science,2011,6838:472-479.
[7]Lafferty J,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proceedings of the 18th ICML-01,Montreal,2001:282-289.
[8]Hai Zhao,Changning Huang,Mu Li.An Improved Chinese Word Segmentation System with Conditional Random Field[C]//Proceedings of the 5th SIGHAN Workshop on Chinese Language Processing(SIGHAN-5).Sydeny,2006:162-165.
[9]周俊生,戴新宇,尹存燕,等.基于层叠条件随机场模型的中文机构名自动识别[J].电子学报,2006,5:804-809.
[10]丁德鑫,曲维光,徐涛,等.基于CRF模型的组合型歧义消解研究[J].南京师范大学学报,2008,8(4):73-76.
