基于Heritrix的web信息抽取优化与实现
2012-10-13陈建峡
吴 伟,陈建峡
(湖北工业大学计算机学院,湖北 武汉430068)
WEB结构化信息抽取将网页中的非结构化数据按照一定的需求抽取成结构化数据,是垂直搜索引擎的核心技术.由于Heritrix源码是开放的、可扩展的,而且Heritrix适合所有网络规模,能够进行高质量的web文档信息抽取项目,因此成为目前用来实现web信息抽取的主要技术之一.
1 Web信息抽取技术简介
垂直搜索引擎是为某些特定的领域、某些特定的用户、某些特定的要求抓取有价值的信息以及相关的服务.具体表现为:按需要的主题抓取web当中海量的非结构化的URL,再将URL中的重要元素做出抽取并存入到数据库.同一般的web搜索引擎相比,垂直搜索引擎检索对象一对一、检索结果更为准确和深入.所以,用WEB结构化信息抽取操作,可以将URL中的非结构化的数据按用户的需求变为结构化数据,这是垂直搜索引擎与普通搜索引擎之间最大的区别,更是其核心技术.
Web信息抽取,是将web作为信息源的信息抽取,就是从半结构化web信息中抽取需要的数据资源[1].核心是把分散在互联网当中的半结构化页面当中隐含的信息给抽取出来,变成更具有结构化和语义更加清晰的形式,便于在web中对数据的查询及程序直接利用 Web中的数据.通常可以将 Web信息源分为三类[2]:自由文本、结构化文本、半结构化文本.以半结构化文本为主.目前用来实现web信息抽取的技术有 Heritrix、Nutch、JSpider、Crawler4j、Ex-Crawler等[3].由于 Heritrix源码的特性,笔者选择用其来完成本文所要提出的问题.
2 Heritrix技术简介
Heritrix是一个爬虫框架(图1)[4],从总体看,是一个平台结构,内部的全体部件都包含松耦合这一特点.每个组件都能够拆卸及替换,为基于Heritrix的自定义开发提供了条件.
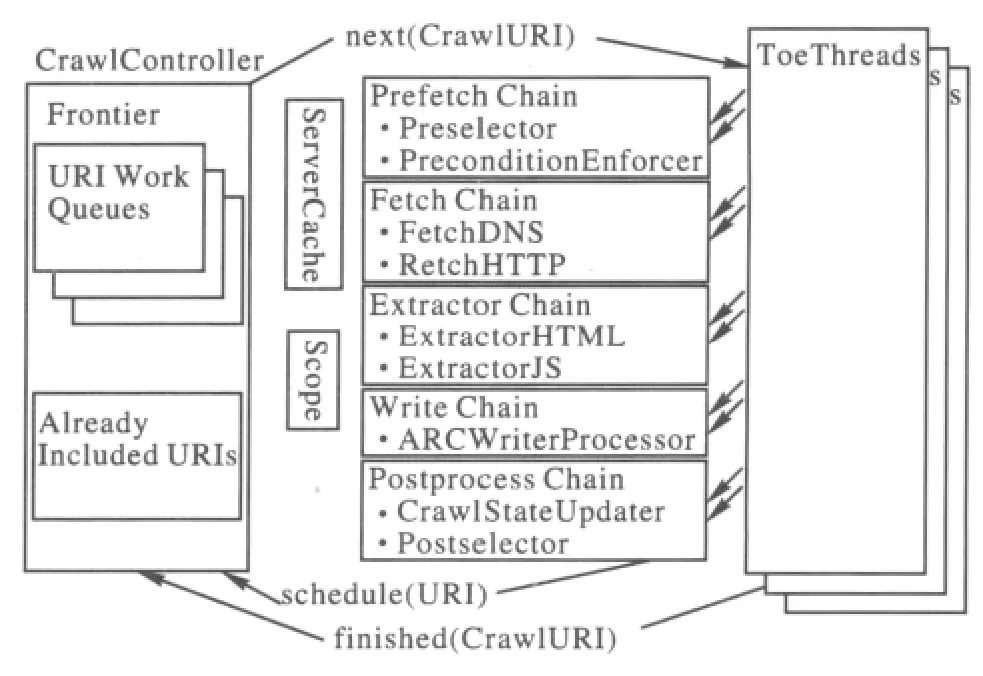
图1 Heritrix架构图
Heritrix中组件的用途:1)Crawl Controller,Web信息抽取中的核心,这一组件用于控制 Web信息抽取的整个过程;2)Crawl Or der,是工作的开始,记录了整个任务的全部属性;3)Frontier,将爬过的URI标记,同时将未处理过的链接放入等待处理队列中;4)Toe Thread,处理 URL的线程;5)processor,表示单独处理器,剩余的处理器全部为它的子类.
在Heritrix架构中,Crawl Contr oller,决定了整个Web信息抽取任务的始末.用户在Heritrix的控制台设置抓Job后,Heritrix要先构造出XMLSettings Handler,再来调用中央控制器的构造函数,构造一个中央控制器实例并初始化,这样中央控制器就可以开始运行Job[5].向线程池里工作状态中的线程提供需要抓取的链接,则需要启动线程池以开始Web信息抽取,
如若用户不发出暂停或终止的指令,web信息抽取工作就会一直继续,直到无链接可抓,控制器才会认为这次的任务执行完毕,线程被关闭.图2为Heritrix抓取流程:
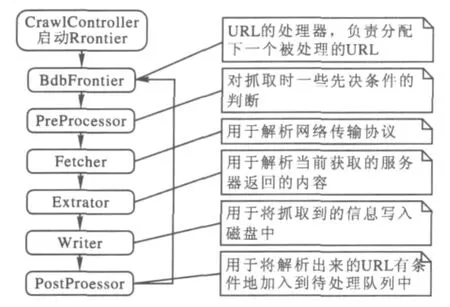
图2 Heritrix工作流程图
Heritrix在Web信息抽取时,当线程从队列中取得一个URL之后,被抓取成功的URL队列便产生了阻塞状态,直到被取出的URL执行完所有的处理,方可恢复这个阻塞状态.Heritrix实际上是单线程的工作状态.这是导致工作进度慢的主要原因,例如抓取湖北工业大学校园网就需要花费大约160 h以上,因此采取了ELFHash算法对其抓取工作进行优化.
3 Heritrix的优化
3.1 HLFHash算法
笔者对Heritrix进行了采用多线程的改进,以便更有效更快速地抓取网页内容.当链接送到url处理器时就为其赋予一个Key值,之后再将前面赋予的Key值与相对应的链接放在一起,便可以组成一个队列.Heritrix中所有的链接用Queueassignmentpolicy计算Key值.链接的Key值,Heritrix默认用Hostname Queue Assign ment Policy计算.这种方法的缺点是:当对同一个网站当中的信息进行抓取时会产生很大的问题.
现将queueassign mentpolicy类进行相应的改变,以提高web信息抽取的效率.通过研究、分析ELFHash算法就能实现此功能.ELFHash算法的基本思想如下:

3.2 多线程抓取的实现
根据ELFHash基本算法,利用ELFHash算法策略,多线程抓取首先要为org.archive.crawler.fr ontier添加一个继承于Queue Assign ment Policy的ELFHash Queue Assign ment Policy类.这样,当使用Heritrix抓取网页的时候,Heritrix就变成默认使用ELFHash Queue Assign ment Policy来分配连接队列了.经过验证,抓取效率能得到很大的提高.本文实现的主要代码如下:

本文以网易手机的网址建立job,运行优化后的Heritrix,再看Heritrix抓取web信息的过程和抓取URL的结果.从图3可知,优化后的50个工作线程全是工作状态,无闲置线程.

图3 ELFHash算法优化结果图
3.3 URL优化
Heritrix在抓取信息的过程中将网站内部所有URL及其包括的所有文件都抓取出来,这些不必要的文件占用了很多的硬盘空间,所以需要对URL进行适当优化,让其更准确地抓取用户所需要的URL和文件信息.
本文的研究过程中,选择了网易的手机网站来作垂直搜索的信息来源.web信息抽取包括两种:一个是手机的参数,另一个则是手机照片.产品在网站中的图片格式则为“gif”、“j peg”、“j pg”等,通过对URL源码的分析可知:网易手机以“pr oduct.tech.163.co m/mobile”起始.由 web信息抽取工作流程不难看出,扩展方法是扩展 Heritrix的Fr ontier-Scheduler中的Post Processor部件.
1)抓 取 所 有 以 “htt p://pr oduct.tech.163.com/mobile/”为前缀的 URL.在eclipse中实现的代码见图4.

图4 URL设置代码
2)遇到以“.zip”、“.rar”、“.exe”、“.pdf”、“.doc”、“.xls”等结束的 URL跳过不予以抓取,在eclipse中实现的代码如图5所示:

图5 跳过的URL代码图
图6 为不抓取以 “.zip”、“.rar”、“.exe”、“.pdf”、“.doc”、“.xls”等结束的 URL.

图6 URL优化结果图
4 实验分析
实验平台在window7操作系统下,Eclipse-sdk-3.4.2-win32,在基于Java JDK(Java Develop ment Kit)1.6.0_10的可扩展开发平台中对 Heritrix1.14.3进行优化工作.
笔者利用ELFHash算法优化后分别对当当网、湖北工业大学校园网、网易手机网进行抓取工作,可以通过图7(横轴的当当网、湖工、网易手机表示为抓取的网站,纵轴的数字表示为线程数、抓取信息量大小及用时多少)看出线程数为1所需的时间远远大于线程为50所需的时间.
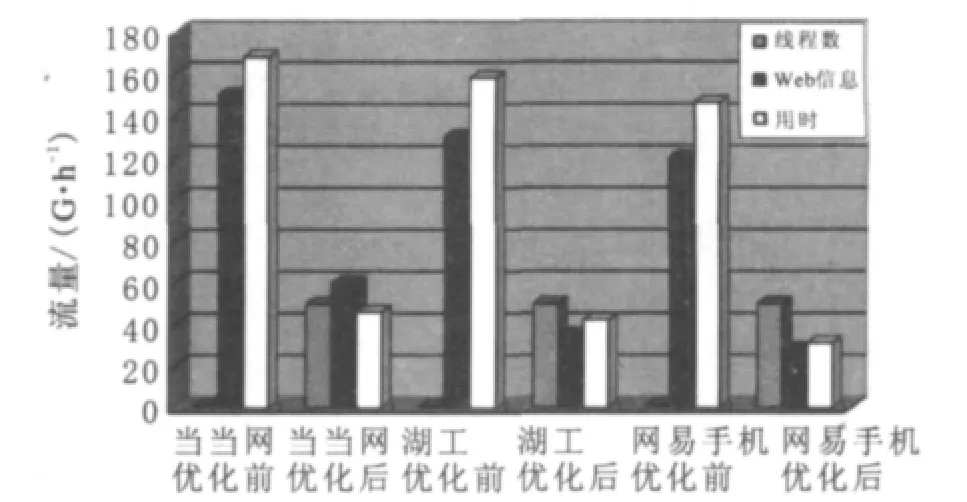
图7 线程优化对比图
5 结束语
本文在Eclipse中运用ELFHash算法通过对Heritrix的queueassign ment policy进行改变,使得Heritrix在Web信息抽取过程由原来的单线程变成了多线程,提高了Web信息抽取的工作的效率,为Heritrix添加的当当网、湖工校园网站、网易手机网站等的工程节约了资源,节省了时间.但是在Web信息抽过程中依然还存在有少量的jpg、t xt等信息不能够完整的抓取下来,有待进一步完善.
[1]火善栋.基于网页结构特征的网页主要文本信息抽取策略[J].现代计算机(专业版),2008(4):2.
[2]蒲筱哥.基于Web的信息抽取技术研究综述[J].现代情报,2007(10):215-219.
[3]邱 哲,符滔滔,王雪松.开发自己的搜索引擎lucene+Heritrix[M].北京:人民邮电出版社,2010.
[4]佚 名.Heritrix架构简述[EB/OL].(2011-08-21)http://blog.csdn.net/histor yasamirror/article/details/6705923.
[5] Heritrix-home page[EB/OL].(2011-06-09)http://www.webcrawler.co m.
