基于误用检测与异常行为检测的整合模型
2012-06-06刘人杰陈纯锴
谢 红,刘人杰,陈纯锴
(哈尔滨工程大学信息与通信工程学院,黑龙江哈尔滨 150001)
0 引言
入侵检测系统(intrusion detection system,IDS)作为重要的网络安全系统,是信息安全与计算机领域的研究热点。入侵检测分成误用检测(misuse detection)和异常检测(anomaly detection)两种。误用检测也叫基于知识的检测,学习阶段是以攻击数据包来产生样本,再将这些攻击样本转换成适当的规则;检测阶段则利用收集到的网络数据包对比其特征是否符合规则,若符合规则判断为有攻击行为。主要的特征是:人工产生攻击规则、无法检测未知攻击、较高漏报率(false-negative rate)与较低误报率(false-positive rate)、检测时间较短。常用的有:基于状态转换分析的 IDS,如 STAT 和 USTAT[1-2],基于特征匹配的IDS。这种方法依据具体攻击特征库进行判断,所以检测准确度很高,但漏报率随之增加,因为攻击特征的细微变化,就会使得误用检测无能为力,尤其难以检测到内部人员的入侵行为。异常检测是一种基于行为的检测方法,它在学习阶段是在无入侵行为的网络环境下产生正常数据包的样本,再将样本转换成规则;在检测阶段对比收集到的数据包是否符合正常规则,若不符合,即判断有异常行为。其特征是:自动产生正常数据包规则、可检测未知攻击、较高误报率与较低漏报率、耗费时间大。它可能检测未曾出现过的攻击方法,因此是目前研究的热点,如Fumio Mizoguchi提出基于机器学习的可视化异常型 IDS[3],基于网络状态的 IDS[4]。但异常检测不可能对整个系统内所有用户行为进行全面地描述,所以异常检测的误报率较高。其次,由于统计简表需要不断更新,入侵者如果知道某系统在IDS的监视之下,它们就能慢慢地训练检测系统使其认为某一种行为方式是正常的。误用检测及异常检测两大入侵检测技术的整合,是不容易有效地实现的;例如,在文献[5]中提到了利用模板对应的方式来检测异常行为,并且以改善贝叶斯TCP网络(bayesian TCP network)的方式作为误用检测技术的基础,并提出了结合两大入侵检测技术混合式系统的观念,该文中的异常检测只针对合法数据,但如果在训练时系统遭遇攻击,系统将把这些攻击行为定义为正常行为,到了正式检测的阶段时,只要碰到同样的攻击,系统就会遗漏掉。本文的整合式入侵检测系统的基本思想就是把误用检测作为辅助手段,异常检测作为主要检测手段,综合两者优点,首先使用误用检测过滤出合法数据,检测确认攻击的行为与类型,再使用异常检测对用户行为或网络连接进行全面的检测,并能够预防新型的攻击行为。
1 系统模型
系统模型如图1所示,系统由4个模块所组成。①数据采集模块:收集用户历史行为数据进行特征提取,用于构造入侵行为模式规则库和知识库;收集系统中各种审计数据或网络数据,用于被检测。②误用检测模块:采用Apriori算法来进行检测。③异常检测模块:采用隐马尔可夫模型的检测方法。④决策模块:用来整合异常检测模块与误用检测模块的检测结果,利用规则来判定是否为入侵行为与类型。
从系统的整体来看,首先使用误用检测确认攻击的行为与类型,降低误报率。再借助于异常检测直接确保所有网络数据的合法性,预防新型的攻击行为,降低漏报率。通过整合式的检测方式,除了可以有效地降低系统被攻击的威胁,还可以协助管理者随时掌握系统的状况与进一步修正。
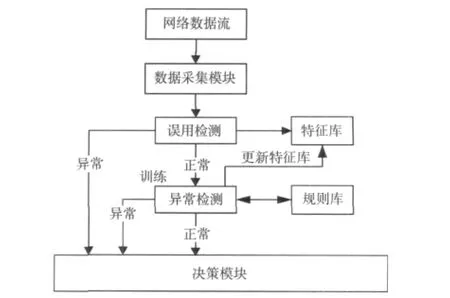
图1 系统模型功能框图Fig.1 Schematic diagram of system model
运用贝叶斯分类器,能有效地处理各种多维训练序列集。但要求各事例属性间具有独立性,虽然实际中不一定能满足数据属性相互独立的条件,但并不影响该算法的分类预测效果。在文献[6]中的实验,简单贝叶斯分类器对于KDD Cup99序列集来说具有优良性能。于是我们参考文献[7]的方法,结合隐马尔可夫与简单贝叶斯分类器优点,提出多维-隐马尔可夫异常行为检测模型用于异常检测,模型如图2所示。简单贝叶斯分类器在处理多维序列时,有着简单、快速的优点,很多文献对简单贝叶斯分类器均有介绍,在此不再赘述。
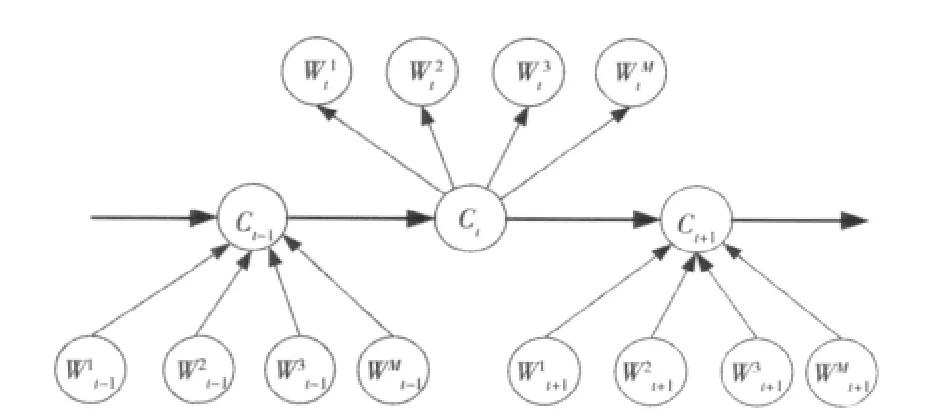
图2 多维隐马尔可夫异常检测模块模型Fig.2 Multi-dimensional hidden markovmodel
以下是多维-隐马尔可夫分类器训练与测试步骤。
1)训练阶段:①利用一组已分类好的训练数据,使用计数法则,得到属于每一个类别的特征值估计值;②将一组已分类好的训练数据状态序列,使用计数法则得出隐马尔可夫的状态转移矩阵。
2)检测阶段:①每组数据经过训练出来的贝叶斯分类器,计算出每个类别所生成的概率;②将每个类别所生成的概率及状态转换矩阵,经过viterbi algorithm求出最佳状态序列。
异常检测模块分为训练和检测2个阶段。在训练过程中,要达到网络数据完全无攻击事实上是很难达成的,如果在训练系统时遭遇攻击行为,系统将把这些攻击行为定义为正常行为,到了正式检测的阶段时,只要碰到同样的攻击,系统就会遗漏掉。针对这样的问题,如M.V.Mahoney曾尝试过将训练切割成很多部分来进行[8],以期各个训练分段能够互相补正彼此训练时发生错误的地方(即训练时遭遇攻击行为)。然而经实验证实,在各分段所能够检测到的攻击,在混合之后检测率却大幅下降。因此,可以结合误用检测技术来辅助异常检测系统使得用来训练的网络数据更趋近于无攻击状态,让检测工作能够得到更加良好的结果。对经过误用检测出的正常网络连接进行训练,构建正常网络连接的规则库,并且可以更新特征库,形成良性循环,在以后的检测中就可以检测出此种攻击。
决策模块用来整合异常检测与误用检测模块的检测结果,利用决策规则判定是否为入侵行为与入侵的类型,并负责将检测的结果回报给管理者,模块所使用的规则为:若误用检测模块判定为正常但异常检测模块判定为异常,则是入侵行为;若误用检测模块判定为异常则直接判定为入侵,并判断入侵的类型;只有误用和异常检测模块都判断正常才是正常数据,并非入侵行为。
2 算法描述
2.1 误用检测Apriori算法
Apriori算法是一种最有影响的挖掘布尔关联规则频繁项集的算法。它是R.Agrawal和R.Srikant于1994年提出的,算法使用频繁项集性质的先验知识,其思想是:使用逐层搜索的方法,用k项集搜索k+1项集。首先扫描数据库,累积每一个项的计数,并过滤出满足频繁集的最小支持度阈值min_sup,得出频繁一项集,记为L1。然后L1与其自身连接产生频繁候选集,再依据最小支持度阈值min_sup条件,过滤掉非频繁项产生频繁二项集L2。L2用于产生L3,依此循环下去,直至不能再找到频繁k项集[9-11]。
Apriori特征产生算法。
输入:连接事件数据库D,每个连接事件的权值为wt,最小支持度阀值为min_sup。

2.2 多维隐马尔可夫模型的异常检测算法
经典隐马尔可夫模型理论具有状态集固定的缺陷,这种缺陷影响了隐马尔可夫模型对随机信号建模的能力,并限制了基于隐马尔可夫模型的分类器的性能。在应用时,我们对隐马尔可夫模型进行改造,由于贝叶斯分类器对于KDD Cup99序列集有优良性能,于是我们结合隐马尔可夫与简单贝叶斯分类器优点,构造了多维-隐马尔可夫异常检测模型及其检测算法,使它的状态数量能自动匹配真正的隐含状态数量,这样它不但能提取更多的结构信息,对随机信号的建模也将更加准确。
对于有时间关系的序列集的处理,我们自然想到使用支持向量机搭配滑动窗口(sliding window)的方法,已知一数据集X={X1,X2,…,XT},每次取长度为w的数据作为新的数据,如图3所示。
黑色矩形代表一段数据,长度为w,每取完一个数据块后向右移动1个单位继续抓取。测试序列长为T,则短序列集包含T-w+1个长为w的滑动窗口短序列,数据集将会转变为


图3 滑动窗数据示意图Fig.3 Schematic diagram of sliding window data
长度为N的观测序列中,所有长度为w的观测序列出现概率的平均值为
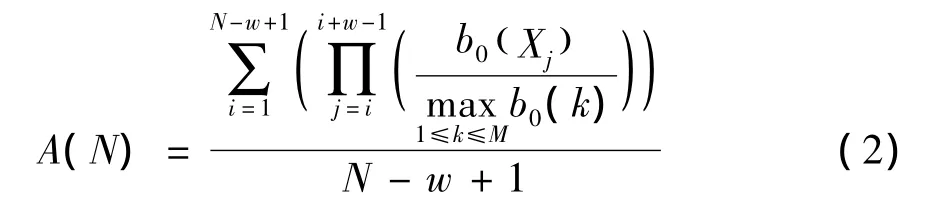
为了方便于在线检测,我们推导出如下递推算法[12-13]

3 性能分析
实验数据采用国际数据挖掘工具竞赛(KDD CUP)1999年的竞赛数据作为训练和检测数据,为了处理方便,采用整个KDD CUP99的10%数据集(共494 019条连接记录),它是一个独立的数据集(包括训练数据集和测试数据集)。每条数据由41个特征属性和一个决策属性构成。同时为了保证执行的效率,试验中分别随机选取10万条记录作为训练数据集和测试集,并随机分为10组。每个TCP/IP连接有41个属性,并标有其所属的类型(如:正常或具体的攻击类型),其中34个属性为数值型变量,7个为符号型变量。该数据集含有网络环境中的多种模拟攻击。模拟攻击(包括正常请求)主要分为 5 大类[14-15],具体如表 1 所示。

表1 网络攻击主要类型Tab.1 Main types of network attacks
研究中将实验的结果分别针对检测率(detection rate)、误报率(false positive rate)以及正确率(accuracy)来做一个验证,依据公式(4)-(6)来评估入侵检测系统的性能。
IDS的检测率、误报率和漏报率。分别定义为

由表 2可知,检测率为 93.12%,误报率为0.46%,整体的正确率为99.37%,说明整合模型在检测上的性能是稳定的,并能够有效检测网络数据中的入侵行为。

表2 系统整体检测性能Tab.2 Detection performance of the whole system
表3再针对每种类别分别进行分析,该方法在只使用10%训练数据和部分记录属性的情况下,仍然对Dos攻击具有很高的检测率和非常低的误报率,并且对Probe和R2L攻击也有较好的检测率,影响整体性能的类别主要是U2R,主要是U2R样本数较少的原因,以至于系统在无法识别的情形下造成错误的判断,导致检测性能不尽理想。
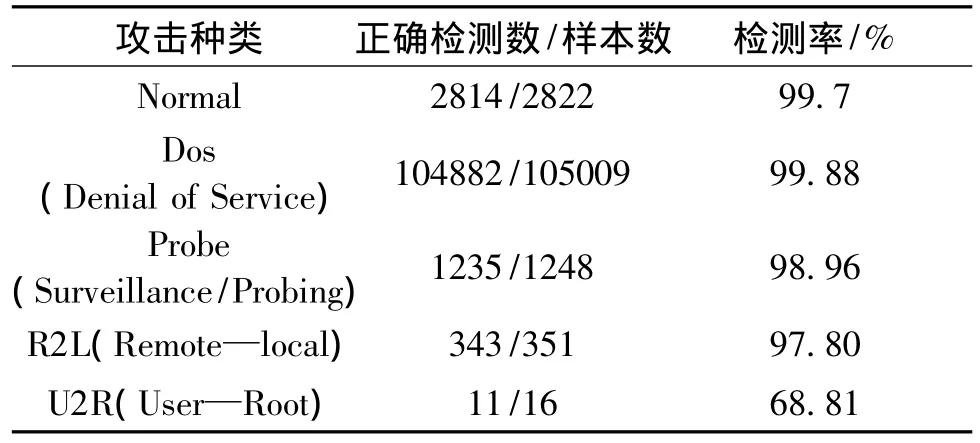
表3 整合式入侵检测性能详细分类表Tab.3 Details of the integrated classification of intrusion detection performance
4 结论
误用检测方法依据具体特征库进行判断,所以检测准确度很高,但无法检测到未知攻击;异常检测方法可以检测到已知攻击的变种及未知攻击,但误报率和漏报率较高。本系统使用了异常检测与误用检测相结合的方法,不仅可以有效地检测已知的攻击,而且具有检测未知攻击的能力。实验表明,这种方法具有较高检测率、正确率,较低的误报率,对于Probe和DOS类攻击也有较好的检测效果,可以弥补单独使用一种检测方法对此类攻击检测效果的不足。
[1] KORAL I,RICHARD K,PHILLIP P.A rule-based intrusion detection approach[J].IEEE Trans on Software Engineering,1995-3,21(3):181-199.
[2] NUANSRIN,SINGH S,DILLON T S.A process statetransition analysis and its application to intrusion detection[C]//15th Annual Computer Security Applications Conference.Phoenix,Arizona,[s.n.]1999:378-387.
[3]MIZOGUCHI F.Anomaly detection using visualization and machine learning[C]//IEEE 9th International Workshops on Enabling Technologies:Infrastructure for Collaborative Enterprises.Gaithersburg,Maryland:IEEE Press,2000:165-170.
[4] SHAN Zheng,CHEN Peng,XU Ke,et al.A network state based intrusion detection model[C]//2001 International Conference on Computer Networks and Mobile Computing,Beijing,CHINA:[s.n.],2001:481-486.
[5]VALDESA.detecting novel scans through pattern anomaly detection[C]//Proceedings of the DARPA Information Survivability Conference and Exposition.Princeton,USA:IEEE,2003:140-151.
[6] AMOR N B,BENFERHATS,ELOUEDIZ.Naive Bayes vs decision trees in intrusion detection systems[C]//Proceedings of the ACM Symposium on Applied Computing,Nicosia,Cyprus:ACM,SIGAPP,2004:420-424.
[7]XIE Yi,YU Shun-zheng.A dynamic anomaly detection model for web user behavior based on HSMM[C]//International Conference of CSCWD'06,Guangzhou,CHINA:IEEE Press,2006:451-460.
[8]SAMABIA T,SHOAB K.A novel packet header visualizationmethodology for network anomaly detection[C]//Proceedings of the 4th IASTED International Conference on Communication,Network,and Information Security.Berkeley,United states:Acta Press,2007:96-100.
[9] RAJASEGARAR S,LECKIE C,PALANISWAMI M.Centered hyper ellipsoidal support vector machine based anomaly detection[C]//IEEE International Conference on Communications.United States:Institute of Electrical and Electronics Engineers Inc,2008:1610–1614.
[10] HATHAWAY R J,BEZDEK JC,HUBAND JM.Scalable visual assessment of cluster tendency for large data sets[J].Pattern Recogn,2006,39:1315 – 1324.
[11] FALLAH S,TRICHLER D,BEYENE J.Estimating number of clusters based on a general similarity matrix with application to microarray data [J].Statist.Appl.Genet.Mol.Biol,2008,7(1):1-23.
[12] FTANZ P.Bayesian network classifiers versus selective formula not Shown-NN classifier [J].Pattern Recognition,2005,38(1):1-10.
[13] CHEBMLU S,ABRAHAM A,THOMAS JP.Feature deduction and ensemble design of intrusion detection systems [J].Computers and Security,Elsevier,Amsterdam,2005,24(4):295-307.
[14] SHIHong-bo,WANG Zhi-hai,HUANG Hou-kuan,et al.A restricted double level Bayesian classification model[J].Journal of Software,2004,15(2):193-199.
[15] PENA J M,LAZANO J A,LARRINAGA P.An improved Bayesian Structural EM algorithm for learning Bayesian networks for clustering[J].Pattern Recognition Letters,2000,21(8):779-786.
