聚类挖掘在高校图书馆管理系统中的应用
2012-06-02韩存鸽
韩存鸽
(武夷学院数学与计算机系,福建武夷山 354300)
目前,基本上所有的高校图书馆都建立了各自的业务处理系统和图书馆办公自动化系统,这些系统对提高高校图书馆的工作效率、减少重复性工作起到了积极作用,推动了高校图书馆事业的发展。
但是大多数图书馆数据库系统只能对现有数据进行查询、录入和存取等比较简单的操作,不能发现数据中隐藏的关系和规则,不能对图书馆所存数据的潜在信息以及读者的个人信息进行高效的分析,并比较准确地预测其发展趋势,从而导致“数据丰富,但信息贫乏”的局面。本文使用聚类挖掘对武夷学院图书馆管理的流通数据进行分析,给广大师生提供个性化的服务。
1 聚类挖掘基本理论
聚类分析是数据挖掘研究领域中一个非常活跃的研究课题。目前聚类分析已被广泛应用于许多研究领域,包括数据挖掘、图像分割、模式识别、市场研究等领域[1-6]。
1.1 概念及主要算法
所谓聚类就是将物理或抽象的集合分成相似的对象类的过程。簇是数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异[7]。在大多数情况下,一个簇中的对象可以被作为一个组来处理。作为数据挖掘的一个功能,聚类分析能作为一个独立的工具来获得数据分布情况,并观察每个簇的特点,集中对特定的某些簇做进一步的分析。
目前文献中存在大量的聚类算法。比较著名的有 K-MEANS、PAM、CLARANS、BIRCH、CURE、SCAN、OPTICS、CLIQUE CABOSFV 等。各类数据挖掘软件中比较经典的为K-means模型。
1.2 聚类分析过程
首先,输入样本集合,然后对样本进行预处理,通过对不同属性的样本进行选择、抽取,根据聚类分析的数据类型要求形成样本表示,再根据样本间的相似性进行分组聚类。一般情况,聚类是一个循环渐近的过程,需要对样本间的相似性进行比较,以改善不同的分组情况,使同组对象彼此更相似,而与其他组的对象更相异[8]。图1为聚类分析的过程。
1.3 K-means算法
K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为2个对象的距离越近,其相似性就越大。
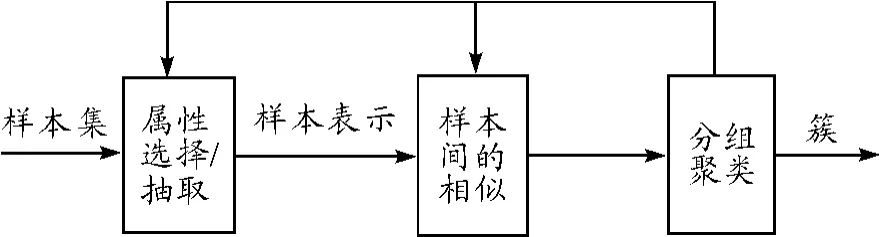
图1 聚类分析的过程
1.3.1 K-means算法的处理流程
首先,随机地选择k个对象,每个对象初始地代表了一个簇的平均值或中心。对剩余的每个对象,根据其与各个簇均值的距离(一般用欧氏距离)将它派给最近的簇。然后计算每个簇的新均值。这个过程不断重复,直到准则函数收敛。通常采用平方误差准则,其定义为[8]其中:E是数据库中所有对象的平方误差总和;p是空间中的点,表示给定的数据对象;mi是簇Ci的平均值(p和mi都是多维的)。这个准则使生成的结果簇尽可能地紧凑和独立。
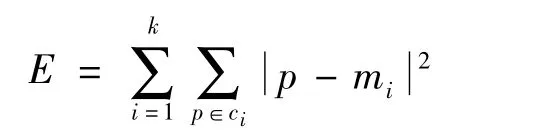
1.3.2 K 均值划分算法
Input:K(簇的数目),D(包含n个对象的数据集)
Output:K个簇的集合
方法:
1)从D中任意选择k个对象作为初始簇中心;
2)repeat;
3)根据簇中对象的均值,将每个对象(再)指派到最相似的簇;
4)更新簇均值,即计算每个簇中对象的均值;
5)until不再发生变化。
2 聚类挖掘数据的采集及处理
2.1 聚类挖掘数据采集
武夷学院图书馆使用的是大连网信软件公司研制妙思文献管理集成系统。该系统全面覆盖了图书馆自动化业务的功能需求,核心功能包括图书和连续出版物的采购、编目、典藏以及流通管理系统,支持校园一卡通。
2.1.1 读者聚类数据采集
从武夷学院图书馆管理系统中聚类挖掘所需的信息,分别形成ltxxb(流通信息表)、dzxxb(读者信息表)、wxxxb(文献信息表)、tmxxb(条码信息表)4个表。本次研究是在Visual FoxPro 6.0环境下进行数据的处理,具体SQL查询语句如下:
select ltxxb.读者证号,ltxxb.读者姓名,dzxxb.读者单位,借出时刻,wxxxb.索取号;
from ltxxb,dzxxb,wxxxb,tmxxb into table alldata;
where ltxxb.条码 =wxxxb.条码 and tmxxb.索取号=wxxxb.索取号 and ltxxb.读者证号=dzxxb.读者证号 and借出时刻 between{^2006.08.01}and{^2007.07.31 23:00:00}
利用Visual FoxPro语言输入SQL命令,统计每一位读者1年内的借阅数量。在VFP6.0中具体SQL查询语句如下:
select读者证号,读者单位,count(读者证号)as借阅册数;
from alldata into table jieyue;
group by读者证号;
order by借阅册数desc
读者借阅数据共有9 826条记录。
2.1.2 图书流通量数据采集
先从 ltxxb中统计出每种书的流通量,在VFP6.0中具体SQL查询语句如下:
select控制号,count(读者证号)as流通量;
from ltxxb into table tushult;
group by控制号;
order by流通量desc
共有22 636条记录。
然后从tushult和wxxxb中显示每种借阅书籍的相关信息,此处使用wxxxb表和tushult表进行左连接,目的是找出一年未曾借出的书籍,SQL命令如下:
select流通量,复本数,索取号,正题名,出版日期,标准编号,文献类型;
from wxxxb into table tushujl;
left join tushult on tushult.控制号 =wxxxb.控制号;
order by流通量desc
图书流通数据共有235 869条记录。
2.2 聚类挖掘数据的处理
2.2.1 空值作删除处理
做聚类分析的2类数据读者借阅量和图书流通量中的所有属性都不能为空,如果出现空值,则删除这条记录。如jieyue表中由于有些临时读者信息被删除,出现读者证号为空的现象,所以必需去掉这部分空值信息;又如在tushujl数据表中,描述图书信息的正题名字段不能出现空值,如发现则应剔除。对于tushujl表中流通量为“.null.”的记录,在删除之前把一年来未流通的书籍信息保存在单独的一个表中(后面要用),最终形成待挖掘的22 635条记录。
2.2.2 噪声处理
分析 wxxxb、tmxxb、ltxxb 、dzxxb四个数据表的记录,发现存在一些影响挖掘结果的数据。如在流通量数据表中,一些复本数超过100的为非正常数据,转换成20~30复本数。一些不流通的图书,如工具书阅览室内的图书等应排除,以免影响聚类结果。在借阅数据表中,有的读者“一卡通”借书证挂失补办了,造成新旧证号都有借阅信息,影响了读者借阅情况的挖掘,对这些记录应合并为1条。
3 在Clementine中实施聚类挖掘及结果分析
使用 Clementine 挖掘工具[9-10]K-means模型进行聚类分析,从读者的借阅册数和图书流通量2个角度进行聚类分析,聚类结果表示为图书馆的图书推荐。
3.1 读者聚类挖掘及结果分析
在Clementine中首先应该导入待分析数据jieyue.xls(在 Visual FoxPro 中将 jieyue.dbf导出成jieyue.xls),使用type节点对数据的属性进行设置。这里针对读者的借阅册数进行分类,所以,只有借阅册数字段方向为输入,读者证号、读者单位、读者姓名3个字段都为无。使用Clementine进行聚类分析,有3种模型可供选择,分别是“神经网络”、“K均值”、“两步”聚类模型,本文选择经典的“K-means”模型进行聚类挖掘。在该模型的属性设置上,聚类数k=3,分别为“活跃读者”“消极读者”“一般读者”,最后将聚类结果以表格形式显示出来。从读者借阅册数角度进行聚类分析的整个流程如图2所示。以表格形式显示聚类结果,部分数据如图3所示。
图2 读者聚类挖掘流程
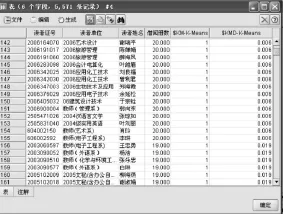
图3 以表格方式显示读者聚类结果中部分数据
以上的挖掘仅从读者的借阅册数角度来衡量读者的需求。根据聚类结果,可以适当为活跃型读者提供一定的便利,比如增加这些读者的允借册数,而不是使用同一标准对待不同的读者,为读者提供更加便利的服务。对一般型读者,可以进一步挖掘他们的借阅兴趣,为他们提供更主动的推荐服务。而对那些消极读者,图书馆可以适当地开展图书宣传,使他们转消极为积极,提高图书馆的利用率。
3.2 图书聚类挖掘及结果分析
在Clementine软件中导入待分析数据tushujl.xls(在Visual FoxPro中将tushujl.dbf导出成tushujl.xls),使用type节点对数据的属性进行设置,这里针对读者的图书流通量进行分类,所以,在type节点设置流通量字段方向为输入,复本数、索取号、正题名、出版日期、标准编号、文献类型6个字段方向都为无。使用Clementine进行聚类分析。本文继续选择“K-means”模型进行聚类挖掘。在该模型的属性设置上,聚类数k=3,分别为“热门书”“冷门书”“一般书”,最后将聚类结果以表格形式显示出来。从图书流通量角度进行聚类分析的整个流程与读者聚类挖掘流程相似,这里不再列出。聚类挖掘的最终结果如图4所示。
图4 图书流通量聚类结果中部分数据
根据对图书聚类挖掘的结果,对那些热门书(图4中类别为1的图书)建议图书馆可以专门设一个“热门借书区”,方便读者快速查找想借阅的图书。而将一些“冷门书”可以做相关处理,比如文献剔旧或下架,为图书馆节省藏书空间。同时那些复本量过大的”冷门书”(在聚类结果中类别为2的图书)也可以为图书采购部门提供参考。还有一部分未流通的书籍(流通量为.null.),图书馆工作人员可以做适当分析,对那些新采购的书籍可以多做宣传,增加图书利用率,而对那些旧的书籍,可以做适当剔除。
4 结束语
本文对武夷学院图书馆提供的流通数据进行了处理,主要采集读者借阅册数和图书流通量2类数据。在Clementine中使用K-means模型进行聚类分析,从读者的借阅册数角度进行分类,将读者划分成“活跃读者”“消极读者”及“一般读者”3类;根据图书流通量进行分类,将图书分成“热门书”“冷门书”及“一般书”3类。根据聚类挖掘的结果,为不同类的读者提供不同的服务,针对不同类的图书采取相应的措施。
[1]苏静.基于聚类分析的河南城乡一体化区域差异研究[J].安徽农业科学,2011(21):13224 -13225.
[2]杨军,巩珏,邓文兵.火炮射击精度的模糊等价关系聚类分析[J].四川兵工学报,2010(1):28 -29,37.
[3]余肖生,司新霞.基于聚类分析的元搜索引擎模型[J].重庆理工大学学报:自然科学版,2011(6):69-72.
[4]陈桂枝.湖北省县域城镇化水平的聚类分析[J].安徽农业科学,2011(29):18352-18354.
[5]李凤兰,樊逾,苏理云.层次聚类的重庆市高校图书馆分类评估[J].重庆理工大学学报:自然科学版,2011(9):121-126.
[6]张林林,周毅,周瑞有,等.对空目标射击有利度模糊聚类分析[J].四川兵工学报,2010(12):145-146.
[7]Han jiawei,Micheline,Kamber.数据挖掘概念与技术[M].范明,孟小峰,译.北京:机械工业出版社,2006.
[8]陆云.聚类分析数据挖掘方法的研究应用[D].合肥:安徽大学,2007.
[9]岳小婷.数据挖掘工具Clementine应用[J].牡丹江大学学报,2007(4):103-105.
[10]刘利俊.利用Clementine进行试卷质量分析[J].现代计算机,2008(5):115-117.
