一种从高维向低维扫描的Apriori改进算法
2012-01-25刘骋昊王靖亚
刘骋昊, 王靖亚
(中国人民公安大学,北京 100038)
0 引言
数据挖掘的目的是从数据仓库或数据集中存放的大量原始数据中提取人们感兴趣的、隐含的、具有潜在应用价值的信息和知识。数据挖掘算法可分为三大类—关联规则算法、分类算法和聚类算法。其中关联规则算法可支持间接数据挖掘,易处理变长的数据,且算法的性能可以提前预测,更为重要的是关联规则算法的挖掘结果直观易懂,所以,基于关联规则的挖掘一直以来都受到众多行业和业内人士的青睐。
Apriori算法是最经典的关联规则的挖掘算法之一,1993年由R.Agrawal和R.Srikant针对购物篮问题而提出。Apriori算法的基本思想是重复扫描数据库,找出频繁项集,然后通过最小支持度和最小置信度进行剪枝,最终得到关联规则。该算法简单易懂且挖掘结果能很好地表示数据库中不同项集之间的关联关系,但该算法在性能上存在着一定的缺陷。本文提出了一种对Apriori算法的改进方法,并且证明了该算法可以有效提高传统的Apriori算法的运算效率。
1 传统Apriori算法
1.1 关联规则挖掘的相关概念和步骤
设任务相关的数据D是数据库事务的集合,其中每个事务T是项的集合,使得T包含于I。每一个事务有一个标识符,称作TID(Thing Identifier)。
项集:项的集合,包含k个项的项集称为k—项集,设项集 I={i1,i2,…,ik}[1]。
项集的频率:项集的出现频率是包含项集的事务数,简称为项集的频率、支持计数或计数。
支持度:support(X=>Y)=P(X∪Y),即X和Y这两个项集在事务集D中同时出现的概率。
频繁项集:如果项集的出现频率大于或等于最小支持度,则称为频繁项集频繁k—项集的集合通常记作Lk。
关联规则:形如X=>Y的蕴涵式,其中设X是一个项集,即事务T包含X;X、Y中的项均包含于D,且 X∩Y=Φ。
挖掘步骤:
(1)找出所有频率项集。即要求找出的项目集出现频繁度必须大于或等于用户自定义的最小支持度。
(2)由频繁项集产生强关联规则。即根据用户规定的最小置信度来确定产生频繁项集的取舍,从而确定强关联规则。
1.2 基本思想
发现关联规则的关键是频繁项集的发现。Apriori算法推导频繁项集的过程如下:
输入:事务数据库D,最小支持度min_sup。
输出:D中的频繁项集L。
(1)第一次扫描数据库,找出满足最小支持度的频繁1—项集L1。
(2)For(k=2;Lk-1≠;k++)
{由Lk-1中所含的项自连接,产生候选k项集Ck;
扫描数据库,计算这些候选集的支持度;
对候选K项集Ck进行剪枝,删除支持度小于最小支持度min_sup的项目,K项集Lk。
}
(3)对L1到Lk取并集,最终得到频繁项集L。
1.3 算法分析
该算法存在着两个大问题:
(1)算法运算过程中,通过频繁项集自连接产生了大量的候选集,即由K频繁项集自连接生成K+1候选集,使候选集的数量呈指数倍增长,如果频繁项集中的项数过多,则产生候选集所带来的时间和空间上的开销是非常惊人的;
(2)该算法要求多次扫描数据库,每得到一个频繁项集就要扫描一次数据库,由此可知,最大频繁项集中有多少项就需要对事物数据库扫描多少次,对一些大型数据库而言,扫描数据库所带来的时间开销和I/O负载过大。
2 已有的Apriori算法改进及其分析
针对Apriori算法的以上缺点和不足,引发了许多学者对Apriori算法进行改进。改进的两个主要方向是:
(1)减少候选集的生成数量,提高空间效率;
(2)减少数据库扫描次数或每次扫描的事务个数,提高时间效率。其中具有代表性的方法:
①基于散列的方法:1995年,由Park等人提出[2]。该方法通过引入hash技术来提高生成频繁2项集的效率并在循环过程中对事务进行消减,从而改善算法的运行效率,但对2阶候选集没有作用。
②基于划分的方法:1995年,由Savasere等人提出[3]。该方法把数据库从逻辑上划分成几个互不相交的块,算法分别对每个分块进行频繁项集的搜索,然后把产生的频繁项集合并生成所有可能的频繁项集,再对生成的频繁项集进行剪枝。该方法的优点在于只需两次扫描整个事务数据库,但对数据库划分时要求过高。
③基于抽样的方法:1996年,由 Toivonen提出[4],该方法首先对数据库进行采样,其次对样本数据库进行挖掘从中得到所需的规则,然后再将其带入数据库中进行验证。该方法显著提高了算法的运行效率,但有时生成的结果误差较大。
④0-1矩阵的方法[5]:该方法通过建立0-1 矩阵将项集和事务号联系起来,得到所有项目的关联组合,然后产生频繁项集。该方法只需扫描一次数据库,减少了数据库的扫描次数。但在挖掘具有大量频繁项集和长频繁项集或低支持度的数据集时,由于生成的0-1矩阵过多,会使其性能下降。
⑤基于频繁模式树的方法:2000年,由J.Han等提出[6],该方法是对数据库做第一遍扫描后,将频繁项目集压缩为一棵频繁模式树,然后对生成的频繁树分化成多个条件库,对每一个条件库逐一进行挖掘,产生关联规则。该方法不使用候选集,且数据库只需扫描2次,显著提高了算法的运行效率,但频繁树生成和遍历,也将消耗大量的时间和空间。
3 一种从高维向低维扫描的Apriori改进算法
3.1 算法原理及相关定义
最长项优先原则[7]:所含项目数最多的事务拥有优先被处理权。
Apriori性质[8]:频繁项集的所有非空子集也都必须是频繁的。由这个性质可知[9],如果项集I不满足最小支持度min_sup,则I不是频繁的,即P(A)<min_sup;如果向项集I添加项A,其合并项集A∪I不会比项集I的出现频率大,所以项集A∪I也不是频繁的,即P(A∪I)<min_sup。
K项事务集:事务集中的每个事务均含有K个项。
生成频繁项集:频繁项的所有非空子集的集合。
3.2 实现算法
该改进算法根据最长项优先原则和Apriori性质,从高维向低维逐层扫描过程。
输入:事务数据库D,最小支持度阈值min_sup。
输出:D中频繁项集L。
第一次扫描数据库,生成多个事务集,最长项K,每个数据集有mj个事务。


4 传统的Apriori算法与改进算法的示例比较
下面给出的信息表中i1到i5共5个属性,最小支持度 min_sup=2,事件集 T={T1,T2,…,T9}共 9个事件。我们现在对这个样本数据库采用本文中提供的改进Apriori算法进行演算。样本数据库如表1所示。

表1 事务数据集T
4.1 传统Apriori算法计算过程
(1)扫描事务数据库,对每个候选项计数得到候选1项集集合,如表2。
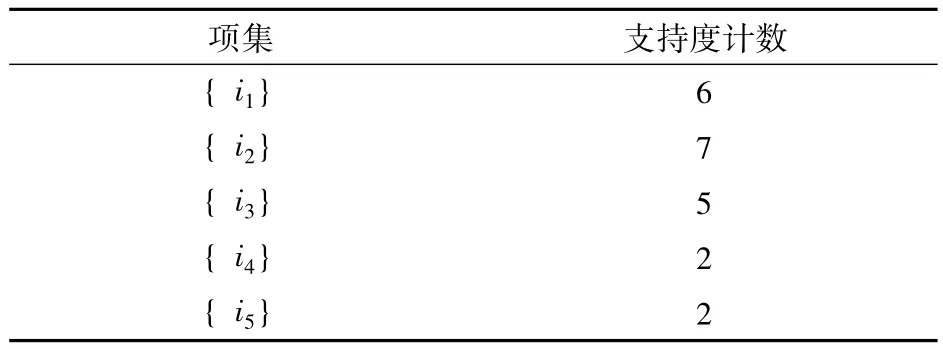
表2 候选1项集
(2)将支持度计数结果与最小支持度进行比较,保留满足最小支持度的项,得到频繁1项集,如表3所示。

表3 频繁1项集
(3)自连接频繁1项集,得到候选2项集,如表4。
(4)将支持度计数结果与最小支持度进行比较,保留满足最小支持度的项,得到频繁2项集,如表5。
(5)依次,连续剪枝,得到频繁3项式集合,如表6。
(6)对表3,表5,表6取并集,得到最终的频繁项集L。

表4 候选2项集

表5 频繁2项集

表6 频繁3项集
4.2 从高维向低维扫描的Apriori算法计算过程
(1)预处理事务数据库,根据每个事务所含项数不同,划分为不同的数据集。生成3项事务集如表7和2项事务集如表8。
(2)由最长项优先原则,先处理3项事务集,所含事务个数=4,从TID号小的开始处理。
① 选取事务T1中所含项{i1,i2,i5}作为候选3项式,扫描该事务数据集得其支持度为2。由最小支持度min_sup=2,可知该候选集为频繁3项式,生成该频繁项的所有非空子集,取其并集,得到生成频繁项集 L31={{i1,i2,i5},{i1,i2},{i2,i5},{i1,i5},{i1},{i2},{i5}}。
②选取下一个事务T4为候选项,因为T4包含于L31中,则跳过,选取下一个事务。以此类推,因为T8,T9支持度均小于最小支持度min_sup,舍去。
③合并所有3项事务集的生成频繁项集,得到3项事务集的频繁项集:

(3)处理2项事务集,所含事务个数=5,选取T2中所含的项为候选项,判断该候选项是否是L3中元素,如果是,跳过,选取下一事务;如果不是,扫描2项事务集,支持度为1,舍去。以此类推,得生成频繁项集 L22={{i2,i3},{i2},{i3}},L23={{i1,i3},{i1},{i3}}。取并集,则2项集频繁项集 L2={{i2,i3},{i1,i3},{i1},{i2},{i3}}。
(4)取L2和L3的并集,得到最终的频繁集L={{i1,i2,i5},{i1,i2},{i2,i5},{i2,i3},{i1,i3},{i1},{i2},{i3},{i5}}。

表7 3项事务集

表8 2项事务集
4.3 算法效率比较分析
通过上述实例比较,我们可以发现从高维向低维Apriori算法有着显著的优点。
(1)空间效率角度分析:从高维向低维逐层扫描,剔除了传统Apriori算法中最终的频繁项集中不会出现的候选项,减少了额外空间的占用量;且算法的预处理阶段,将原有的数据库划分为不同的数据集,再对每个数据集分别进行处理,使算法的额外空间占用量只等于原始数据库的大小,与传统Apriori算法中候选集呈指数倍增长,使额外空间占有量的快速增长相比,提高了算法的空间效率。
(2)时间效率角度分析:该算法中只有首次是对整个事务数据库进行扫描,除此之外每次扫描的都是含有相同项数的事务数据集,这大大减少了扫描的事务个数,缩短了扫描时间;再次,对于已存在频繁集中的项目集,则可以直接跳过,不必再重复扫描事务集,从而减少扫描次数,最终达到提高算法时间效率的目的。
5 结语
本文在传统的Apriori算法的基础上,提出了一种新的改进算法,该算法将原始的事务数据库划分为具有相同数量项的事务集,减少了对数据库的扫描次数和每次扫描事务的个数;快速查找到频繁项集,剔除频繁项集不包含的候选项,减少中间项的生成数量,因此该算法在时间效率和空间效率上都得到了一定的提高。
[1] 马廷斌,徐芬.关联规则挖掘中Apriori算法的研究与改进[J].兰州工业高等专科学校学报,2010,17(1):13-15.
[2] Sing Li.Making P2P interoperable:The JXTA command shell[M].Bimaingham:Wrox Press,2001.
[3] Jameela A J,Nader M,Hong Jiang.Agent-based parallel computing in java proof of concept[R].Technical Report TR-UNL-CSE-2001-1004,Slimmer,2001:5 -12.
[4] 包林玉,袁平,彭春燕,等.基于JMS和XML的异构数据集成技术的设计与实现[J].电脑知识与技术,2008,13:684 -685.
[5] 马晓辉.一种基于关联规则Apriori算法的改进研究[J].现代计算机,2011,3(6).
[6] Han J,Pei J,Yin Y.Mining frequent patterns without candidate generation[C]∥Proceedings of the Special Interest Group on Management of Data,2000:1-12.
[7] 谈丽,王建东.长项优先的产生算法——改进的Apriori算法[J].计算机与现代化,2007(8):53-55.
[8] 綦孝姬,于红,刘溪婧,等.基于候选项目集特性的改进Apriori算法研究[J].郑州大学学报,2009,41(1):36-39.
[9] 钱雪忠,孔芳.关联规则挖掘中对Apriori算法的研究[J].计算机工程与应用,2008,44(17):138 -140.
