决策树在汽车评测中的应用研究
2012-01-04周凌云
周凌云
( 中南民族大学 计算机科学学院,武汉430074)
决策树是1986年由Quinlan提出的,它是以实例为基础的归纳学习算法,它从一个无次序、无规则的实例集合中归纳出一组采用属性结构表示的分类规则.决策树学习算法是最流行的归纳推理算法之一,已经被成功地应用到从学习医疗诊断到学习评估贷款申请的信用风险等广阔领域[1,2].随着中国经济的发展,购车人群增加,对汽车进行评测,给消费者在购车决策过程中提供参考显得十分必要[3].汽车评测是指根据汽车的性能、购买价格、保养费、安全性能、操控性、行李箱大小等指标来评价和预测它的购买指数,从而给消费者提供购车参考.
通过分析研究,本文提出应用决策树的经典算法——ID3算法进行汽车评测.ID3算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类,以此达到预测的目的[4].本文根据汽车各项性能指标,将ID3算法应用于汽车评测中,为深入开发汽车购买决策支持系统提供研究基础.
1 ID3决策树算法原理
ID3算法是一种由训练样例构造决策树的递归算法.该算法首先选择一个属性作为决策树的根结点,并对该属性的每一个值产生一个分支.然后,划分该结点上的数据集,并移到子女结点,产生一个局部树.对其他属性重复该过程[5-9].ID3算法的关键在于:1)生成决策树时,对于决策树的每一个结点选择属性的方法;2)确定停止树的生长的条件.
对于第一个关键问题,ID3 算法使用信息增益作为训练样本集合的划分度量标准.计算信息增益的具体方法可以分为以下3步.
(1) 计算目标属性的熵.目标属性也就是样例的分类,它不必被选作决策树路径上的结点,但它的值要作为决策树叶子结点的值.目标属性的熵根据以下公式计算:
(1)
其中,S是训练样例的集合,pi是S中属于类别i的比例,Σ 是对c求和.Entropy(S)反映了训练样例的纯度,当它的值为0时训练样例集合最纯,也就是此时训练样例集合中的所有样例属于同一分类.
(2) 计算候选属性的熵.计算候选属性的熵是为了选择当前决策属性,也就是选作为当前决策树的一个结点的属性.对于每一个候选属性A的熵可以根据以下公式计算:
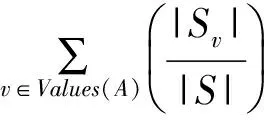
(2)
其中,Values(A)是属性A所有可能值得集合,Sv是训练样例集合中候选属性A的值为v的子集,|Sv| 是Sv中样例个数,|S|是S中样例的个数 .Entropy(Sv)是训练样例集合中候选属性A的值为v时训练样例集合的熵,它可以根据公式(1)求得.
(3) 计算候选属性的信息增益.信息增益反映了候选属性分类训练数据的能力.一个候选属性的信息增益越大,那么它对训练样例的分类能力越强.信息增益的计算公式为:
Gain(S,A)= Entropy(S)-Entropy(S,A),
(3)
算法的具体方法为:首先计算训练样本集合中所有属性的信息增益,选择取值最大的属性作为判断属性划分当前样本集,创建与判断属性值一一对应的各个分枝,得到代表各分支的训练样本子集,然后递归调用同样的方法继续划分.
ID3算法的第二个关键问题是确定停止树生长的条件.当决策树的某个分支下的样例都属于一分类时,这一个分支上样例的划分就结束了.另外,当所有的候选属性已经被这条路径包括时决策树的生长也结束了,因为任何候选属性在决策树的任意路径上最多只能出现一次.
2 建立汽车评测模型
本文根据汽车的特定属性来进行评测,预测它的购买指数.该应用的数据来源于UCI机器学习数据库中的标准数据集Car Evaluation Database,该数据集无缺失数据,并且各属性取值均为离散值,各属性取值个数分布均匀,都是3或4个,样本分类个数为4类.具备这样特征的数据集特别适合采用ID3决策树算法建立预测模型.
2.1 训练样本描述
评测汽车的属性也就是对分类结果有影响作用的属性有6 个,分别是购买价格(buying)、保养费(maint )、门的个数(doors)、座位数(persons)、行李箱容量(lug_boot)和安全性能(safety),它们的取值描述如下.
buying = { v-high,high,med,low }
maint = { v-high,high,med,low }
doors = { 2,3,4,5-more }
persons = { 2,4,more }
lug_boot = { small,med,big }
safety = { low,med,high }
这6个属性对分类结果有影响作用,也就是生成汽车评测决策树的候选属性.汽车的购买指数通过汽车的目标属性也就是决策属性来描述.目标属性class描述如下.
class = { unacc,acc,good,vgood }
评测汽车的结果分为4类:不可接受(unacc),可接受(acc),比较好(good),很好(vgood),也就是训练样本集被分为4 个类别.表1给出了一个关于汽车评测的部分训练样本.
2.2 详细算法
建立汽车评测模型的决策树算法流程[10]描述如下.
算法:Generate_CarEvaluationTree(samples,attribute_list)
输入:samples为训练样本;attribute_list为候选属性的集合.
输出:一棵汽车评测决策树.
伪代码:
Generate_CarEvaluationTree(samples,attribute_list)
{
N = Create_Node(); //创建汽车评测决策树的一个结点
if( samples 都在同一个类C )
{ return N 作为叶结点,以类C 标记; }
if( attribut_list 为空 )
{ return N 作为叶结点,标记为 samples 中最普通的类; }
N = Choose_best_attribute( attribute_list );
//选择当前最高信息增益属性作为当前汽车评测决策树的结点
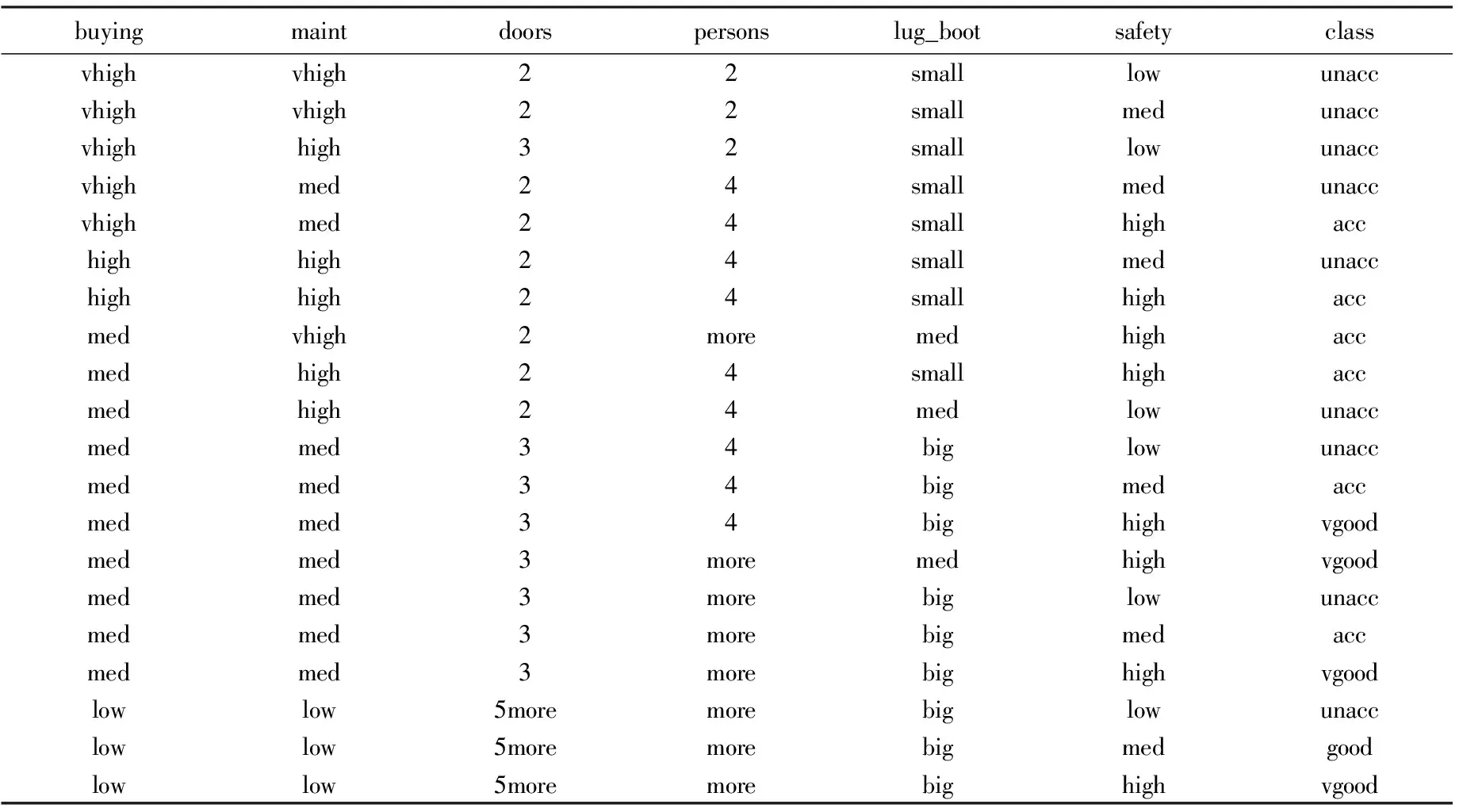
表1 汽车评测的部分训练样本
for best_attribute 的每一个取值ai
{
Create_branch(); //每一个取值ai都建立一个新的分支;
Divide(); //在每一个分支上划分当前汽车训练样本集
if( 如果新分支下的汽车训练样本集为空 )
Create_LeafNode();
//建立叶子结点,以当前样本中类别个数最多的类别标记;该分支生长结束
else
Generate_CarEvaluationTree(si,attribute_list-best_attribute) //递归
}
}
2.3 汽车评测模型测试
建立好汽车评测决策树后就可以用该模型对未分类的汽车样例进行分类预测了.为了测试该模型分类预测的准确率,本文将已知样例分为两个部分,一部分作为训练样例,用来生成汽车评测决策树模型.另一部分作为测试样例,用来测试生成的模型对样例分类预测的准确率.在测试的过程中,记录分类正确的样例的个数,与预测样例的个数相除计算出分类预测的准备率.考虑到保证实验结果的准确性,该实验在相同的软硬件平台下测试多次,取其平均值作为最后结果.
3 实验结果
实验采用的数据集为UCI机器学习数据库中的标准数据集Car Evaluation Database.该数据集中一共有1728个实例.本实验方案从中选取10%、20%、40%、50%、60%,以及70%的样例分别作为训练数据集,而对应的剩余部分样例作为测试数据集,在相同的软、硬件平台下进行多次实验,得出的实验数据如表2所示.

表2 实验结果数据
从表2的实验结果可以看出,当训练样例在20%以上时,预测的准备率较好,均能达到80%以上,当训练样例所占比例更大时,分类预测的准备率相对更高.
4 结束语
利用机器学习方法处理分类预测问题是近年来分类领域一个新兴的研究热点.决策树是一种机器学习常用的分类方法.本文通过系统阐述决策树方法的原理和适合范围,并分析了汽车评测数据适合决策树ID3算法,所以利用ID3决策树方法来建立汽车评测模型,并给出详细的步骤.最后在Car Evaluation Database数据集上对该模型进行实验测试,可以看出此方法是比较有效的,并能证实该模型获得较好的分类预测准确率.
[1]Quinlan J R.Induction of decision trees[J].Machine Learning,1986(1): 81-106.
[2]米切尔.机器学习[M].曾华军,张银奎,译.北京:机械工业出版社,2003:38-43.
[3]朱鋐瑛,郭乃幸.能源约束下中国新能源汽车的发展及政策建议[J].陕西科技大学学报,2012,30(1):131-134.
[4]黄爱辉,陈湘涛.决策树ID3算法的改进[J].计算机工程与科学,2009,31(6):109-111.
[5]徐 鹏,林 森.基于C4.5决策树的流量分类方法[J].软件学报,2009,20(10):2692-2704.
[6]张 琳,陈 燕,李桃迎,等.决策树分类算法研究[J].计算机工程,2011,37(13):66-70.
[7]丁智斌,袁 方,董贺伟.数据挖掘在高校学生学习成绩分析中的应用[J].计算机工程与设计,2006,27(4):590-592.
[8]Long Xiaojian,Wu Yuchun.Application of decision tree in student achievement evaluation[C]//ICCSEE.2012 International Conference on Computer Science and Electronics Engineering.Hangzhou:Missouri Western State University,2012:243- 247.
[9]安立奎,钱伟懿,韩丽艳.集群系统中基于MPI的关联规则快速挖掘算法[J].三峡大学学报:自然科学版,2010(1):95-97.
[10]王 苗,柴 瑞.一种改进的决策树分类属性选择方法[J].计算机工程与应用,2010,46(8):127-129.
