基于互信息的识别中文地名未登录词技术研究
2011-10-25付海辰
付海辰
(唐山学院 计算机科学与技术系,河北 唐山 063000)
在大规模真实文本处理中,有一些词依靠分词词典是无法识别出来的,这些词被称为未登录词,以中文人名、地名、机构名为三种主要形式。未登录词的识别,是中文文本自动分词中遇到的除歧义识别外的另一难题。
在现在正蓬勃发展的信息检索和数据挖掘研究领域中,未登录词的识别具有十分重要的意义:识别未登录词可以提高分词和抽词的精度,扩充依据词典提取的关键词集合,从而更加准确的对信息资源进行描述、分析与理解[1]。
1 未登录词识别的困难
产生未登录词的原因主要有两点:机器可读词典中词条的选择和词条的数量;机器可读词典与待处理文本中的词条匹配关系,包括机器可读词典对待处理文本中词汇的覆盖率[2]。汉语语言丰富灵活,汉语词种类繁多,构词法样式不一,都给未登录词的识别造成了很大的困难。另外,一些未登录词与词典中已经存在的词相互交叉结合,也使得未登录词识别的正确率不高。例如,在句子“小梅花光了她所有的积蓄”中,“小梅”是一个中文人名,应该被作为一个词切分出来,但是实际切分时因为词典中不存在这个词,所以无法得到正确的切分,且由于词典中收录了“梅花”一词,因此此句将被切分为“小/梅花/光/了/她/所有/的/钱”。
未登录词的出现是中文文本不可避免的问题,其直接影响了中文文本处理的正确率,所以目前未登录词的识别是一个迫切需要解决的问题。
中文人名、地名、机构名是三种最主要的未登录词形式,它们的识别都有相当重要的意义,本文主要侧重于中文地名的识别。
2 中文地名的的未登录词识别
2.1 中文地名特点
中文地名的识别困难不仅在于中文地名的多样性和任意性,而且在很多情况下,其又可以作为句子的其他成分参与句子的构造和活动。虽然中文地名在文章中的出现频率不是很高,但绝不可以忽略,否则在分词系统中会出现不可预料的错误。中文地名主要有如下特点:
(1)中文地名数量大,且用词分散、自由,到目前为止,还没有完整的地名库可供使用,随着社会的发展,生疏地名也在不断增加,较难完善。
(2)地名长度无严格限制,短的如“京”,长的如“新疆维吾尔自治区”;且地名结尾经常有地名特征词出现。
(3)可作单字词的汉字在地名中经常出现,如“西/直/门”,给地名识别带来困难,容易造成只识别出单字,而未识别出地名的错误。
(4)多个地名一起出现,难以一一正确划分,如“河北省/唐山市/建设北路/鹤祥园/106楼”。
这些中文地名的特点,都给地名的识别和切分带来了困难。在无法穷举所有地名的条件下,引入互信息这一概念,有助于克服以上地名识别困难。
2.2 基于互信息的地名识别方法
目前,国内关于中文地名的研究主要有基于交换的地名识别方法,得到地名上下文的规律,对规律再进行筛选。本文提出了一种基于互信息的中文地名识别方法,提出中文地名的上下文互信息概念,引入互信息对其进行描述,并通过引入调整阀值进行矫正,有效地提高了中文地名识别的效果,保证了较高的召回率,有助于中文自动分词系统中未登录词识别的提高。
互信息一般反映的是字与字之间的静态结合,因为它计算的就是相邻字出现的频率,根据这个频率与字单独出现频率进行比较,计算出互信息来判断什么时候组成词语。互信息的概念最早见于信息论,其中互信息被作为一种衡量两个信号之间相互依赖的尺度[3]。在信息论中,这种二元互信息可以表示为两个信号发生概率的函数。具体在自然语言处理领域中,就是把句子中词或词序列作为一系列可能有关联的随机事件,然后用互信息对它们进行分析与研究。对有序汉字串AB中汉字AB之间的互信息I(A,B)定义如下:

互信息体现了汉字之间结合关系的紧密程度,当紧密程度高于某一阀值时,便认为此字组可能构成了一个词。其中,P (A,B)为汉字串 AB联合出现的概率,P(A)为汉字串 A的出现概率,P(B)为汉字串B的出现概率,它们在汉字字符串中出现的次数分别计为n(A),n(B),n(AB),n是词频总数,则有如下公式:

互信息反映了汉字串AB间相关的程度。
如果 I( A,B) ≥0,即 P (A,B)≥ P(A)P(B),则AB间是正相关的,随着I(A,B)增加,相关度增加,如果I(A,B)大于给定的一个阀值,这时可以认为AB是一个词;
如果 I( A,B) ≈0,即 P (A,B)≈ P(A)P(B),则AB间是不相关的;
如果I(A,B)<0,即 P(A <B)< P (A)P(B),则AB间是互斥的,这时AB间基本不会结合成词。
在汉字处理中,互信息描述的是两个字或者词之间的关联程度大小。定义y∈Y,其中y为某一具体的地名,Y为文本中所有地名的集合;x∈X,x为上下文信息,X为由x组成的集合。
由于地名识别中,判断一个句中是否含有地名,常常需要用到地名的左右指界词,根据上述定义,I(x,y)表示上下文信息x与地名y的互信息,它的大小描述了x与y的关联程度,此时的地名左右指界词即为上下文信息x,指界词与地名的共现频率即为互信息I(x,y)。例如,两个句子中分别有“到达”和“扣留”两个词,判定“到达”的后同现词(出现在单词右边的词)是地名的概率要大于“扣留”的后同现词是地名的概率。引入互信息可以准确的描述上下文信息x与地名y的关联程度。
2.3 基于互信息的地名识别方法
2.3.1 地名的上下文互信息
中国地名的自动识别策略是:在对文本分词的基础上进行常见地名匹配后,利用概率估值公式在文本中初步筛选出候选地名,然后根据互信息方法计算出地名的上下文信息,再通过规则对候选地名进一步确定,直至得到真正的地名。本文的互信息地名识别方法也是建立在已利用现有的地名识别资源,初步选出了侯选地名的基础之上。识别原理如图1所示。
在信息论中,互信息 I( x,y)= I(y,x),两者是对称的;而在互信息的地名识别中,互信息 I( x,y)≠ I(y,x),因为在自然语言中,一个句子里汉字的排列顺序是不能改变的。设地名与前同现词的互信息为上文互信息,用Il表示;地名与后同现词的互信息为下文互信息,用Ir表示。则定义如下:
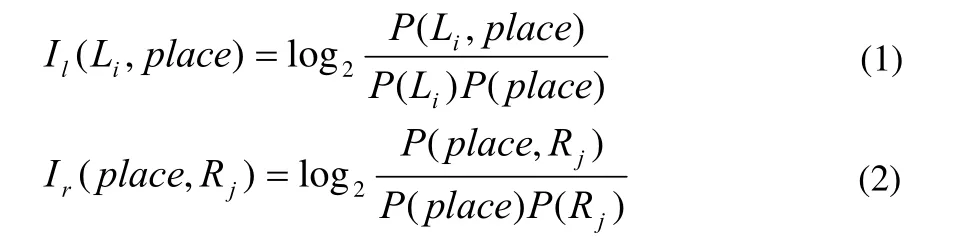
其中,place为一个侯选地名;Li、Rj分别为侯选地名place的前同现词和后同现词(i,j分别是自然数,i≥1,j≥1;P (place)为真实地名集合在实际语料词语中的概率(place为实际语料中的真实地名集合);P (Li, place) 、P( place,Rj)分别为真实地名集合与前同现词的同现概率、真实地名集合与后同现词的同现概率。地名的前同现词与后同现词使用概率是不同的,因此它们与地名的互信息Il和Ir的分布不同。

图1 中国地名自动识别原理图
例如,我们经常遇到的地名前同现词有“到达”、“开赴”、“靠近”等,后同现词有“省”、“市”、“街”等。根据地名的上下文信息,将其互信息定义如下:

其中,E是互信息 Il(Li, place)与 Ir(place,Rj)的均值,D为互信息 Il(Li, place)与 Ir(place,Rj)之间的方差。当给定上下文环境时, Icon(Li,place, Rj)的数值可定量的描述place是真实地名的可能性。
2.3.2 调整阀值确定
为了对地名识别召回率进行调整,将上下文互信息的调整阀值定义为:

其中,
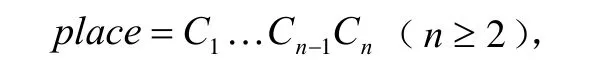
定义概率估值 P (place)的计算公式如下:
n=2时,
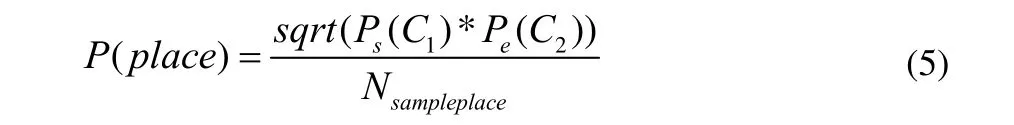
n>2时,

其中,

公式中,对每个中国地名用字c, Nsampleplace表示在真实语料中出现的中国地名个数。Ps(c)、Pm(c)、Pe(c)分别是汉字c作地名首字、中间字和尾字的概率;Nps(c)、Npm(c)、Npe(c)分别是汉字 c在中国地名样本库中作地名首字、中间字、尾字的总次数;Nts(c)、Ntm(c)、Nte(c)分别是汉字 c在真实文本中作地名首字、中间字、尾字的总次数;Nt(c)是汉字c在真实文本中出现的总次数,Nc(c)是汉字c在中国地名样本库中出现的总次数。
2.3.3 地名识别过程
中国地名的自动识别过程可以描述为:首先参照地名用字表进行常见地名匹配,产生初步的候选地名字串,结合从真实文本中统计得到的词频信息进一步确定候选地名的起止位置;其次计算候选地名的概率估值,并计算地名的互信息,结合上下文互信息进行阀值筛选;最后利用规则对通过阀值筛选的候选地名进行调整,产生正确的地名结果。具体步骤如下:
(1)产生侯选地名字串。在分词过程中,如果字串

满足以下条件,则认为place为侯选地名字串。
(Ps( C1)>thor C1为非词字)
and
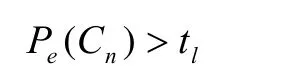
and
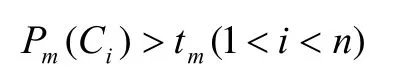
其中th、tm、tl分别是地名首中尾字对应的频数阀值,随着地名用字库容量的改变,各阀值也不断变化,但选择阀值应保证覆盖样本库中99%的地名。
(2)计算侯选地名的概率估值 P (place),并根据概率估值进行初步调整,去掉部分概率过低的侯选地名。
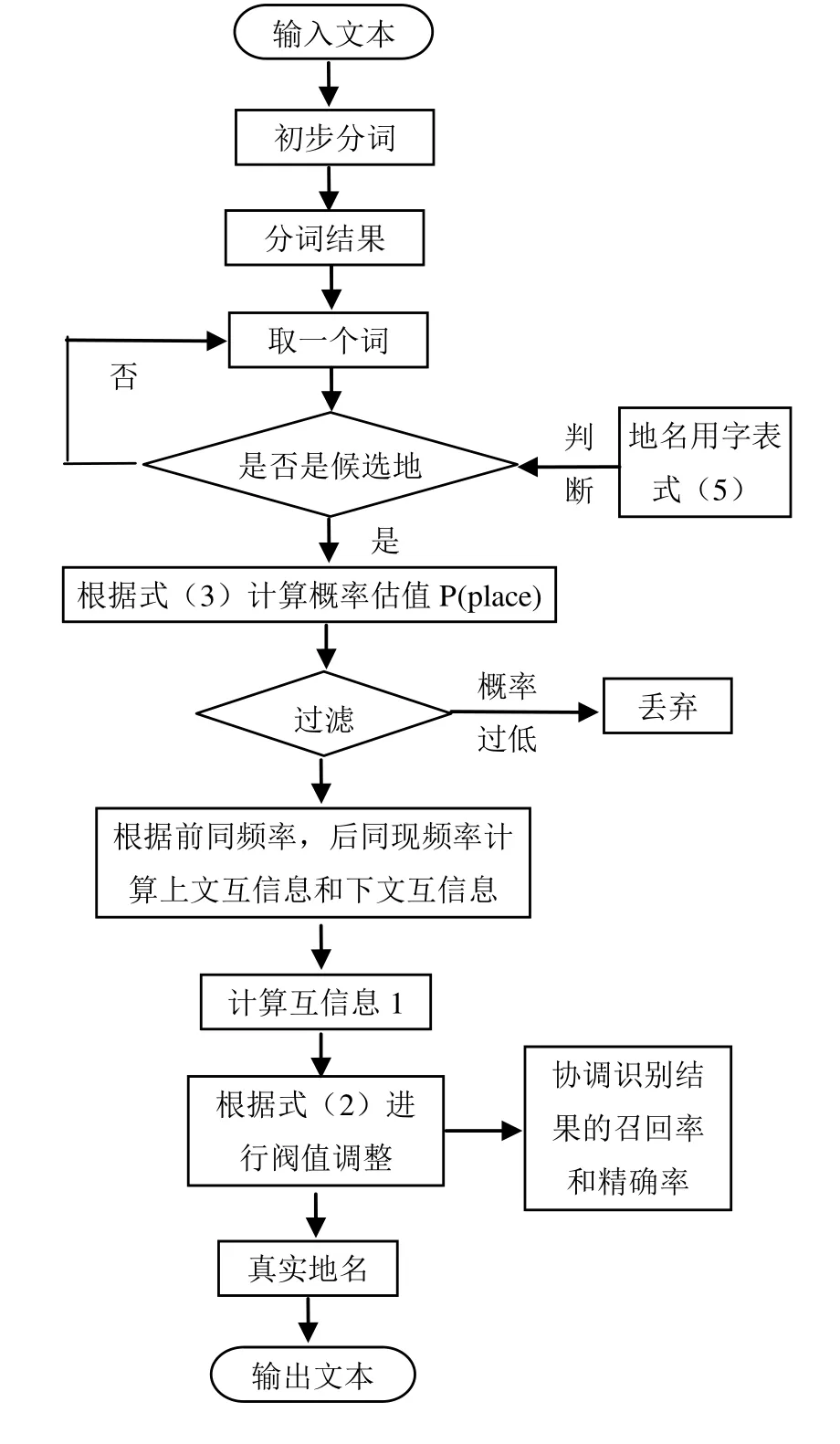
图2 地名识别过程流程图
对于侯选地名
place =C1…Cn=1Cn(n≥2),
利用概率估值 P (place)计算公式(5)、(6),可得到侯选地名的概率估值。当侯选地名的概率估值 P (place)越大,认为是真实地名的概率越大,调整阀值的取值越小;侯选地名的概率估值越小,认为是真实地名的概率越小,调整阀值的取值越大。
(3)根据地名的前同现频率 P (Li, place)和后同现频率P(place,Rj)计算侯选地名的互信息 Icon(Li,place, Rj),利用公式(3)。当给定上下文环境时,互信息的数值可定量描述place是真实地名的可能性。
(4)根据侯选地名上下文互信息的调整阀值公式(4)进行调整校正,以协调识别结果的召回率。
(5)生成有地名切分标志的分词结果,输出文本。
识别过程如图2所示。
3 结论
中国地名是汉语真实文本中最常出现的未登录词类型之一,仅次于人名的出现频率。近年来,在对中国人名识别取得很大研究成果的基础上,地名识别的研究也渐增多。本文提出的基于互信息的地名识别方法,提出中文地名的上下文互信息概念,引入互信息对其进行定量的描述,本方法达到了较好的中文地名识别效果。
