基于X264多线程并行编码研究
2011-08-09魏妃妃梁久祯柴志雷
魏妃妃,梁久祯,柴志雷
(江南大学物联网工程学院,江苏 无锡 214122)
责任编辑:史丽丽
0 引言
随着网络电视、视频会议和高清视频的不断发展,人们对视频编解码的速度和其图像的清晰度提出了越来越高的要求,H.264/AVC作为最新的编码标准,代表着向低码率高质量发展的趋势。虽然H.264/AVC比以往的编码标准节省了码率,但因为其新增的编码特性,使其增加了编码复杂度,使用单处理器的编码速度已经不能满足视频的实时传输和大规模的共享要求,因此研究一种高效的视频并行编码策略是目前的重要课题。
作为一种开放的H.264/AVC编码器,X264比较注重实用性。它在保证了编码效率未明显降低的情况下,舍弃了如多参考帧和帧间预测中不必要的块模式等这些具有极高复杂性的技术;另外X264实现了指令级并行,在此基础上,人们又提出了线程级并行方法,其中包括GOP级、帧级、片级和宏块级并行策略[1-2]。但是其研究方法都不够充分,绝大多数还是针对单一粒度进行并行实施。本文主要研究通过多线程来实现片级和帧间宏块级的并行。
本文介绍片级多线程并行编码算法和帧间宏块级并行编码算法及其实现过程,片级多线程并行编码算法只对一帧图像进行编码,在系统中只需保存与该帧图像编码相关的一些参考帧图像数据便可,所以对内存需要量小[3],同时通过实验表明,在编码码率相对恒定的条件下,帧间宏块级多线程并行编码算法比片级并行编码具有更高的编码速度。本文提出可以根据两种算法的特点,运用POSIX线程库,进行多粒度并行编码算法研究,达到视频更好的实时编码的要求。
1 相关知识介绍
1.1 POSIX多线程
IEEE的开放系统接口标准POSIX线程,通常称为Pthreads标准。视频编码多线程应用程序可以在串行计算机上开发,并且不作任何改变地在并行计算机上运行,同时多线程化的视频编码程序要比使用别的并行程序容易编写得多,另外利用多线程能躲避延迟时间,当一个线程在等待通信操作时,其他的线程可以利用CPU,这样可以屏蔽相应的开销,因此本文使用多线程进行视频编码的并行处理[4]。
1.2 片
在视频编码的过程中为了限制误码的扩散和传输,一个图像帧可以被编码成一个或更多个片,编码的各个片之间是相互独立的,在同一帧中每个片的编码不依靠其他片作为参考,一个独立帧的搜索范围也不能超过片的边界[5-6]。
1.3 帧间宏块的关系
为了提高视频编码的性能,H.264/AVC需要以编码帧的重构图像作为参考来处理时间冗余,即帧间预测模式需要先前已经编码过的参考帧。当前帧的当前宏块能够编码之前,至少其参考帧中的对应位置和它附近的8个相邻宏块是可用的[7],如图1所示,因此实现帧间宏块级并行必须要考虑帧间各个宏块之间的依赖性。
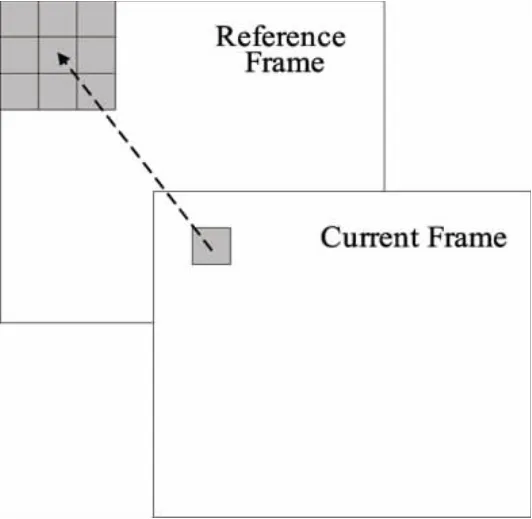
图1 帧间预测模式的数据依赖关系
1.4 并行编码的加速比
加速比是度量采用多线程并行处理比采用单个线程处理的加速倍数,用来衡量并行算法性能的重要指标,着重于并行处理相对于串行处理的优化效果。在H.264/AVC中加速比主要用来表征采用并行算法后编码帧率前后的变化情况。

加速比越大,算法的编码速度越快,并行性能越好,视频编解码的实时性越强。
2 X264片级并行编码算法
2.1 片级并行
根据片与片之间相互独立的特点,同一帧内的各个片可以并行编码。每一帧分成固定数量的片,为每个片分配一个线程进行编码[8]。在进行编码之前需要对每个线程进行同步,其中主要操作就是参考图像帧需要同时进行更新。片级并行不用考虑前后帧之间的参考问题,每一帧的分片数可以人为设定,因此使并行编码具有更大的自由度。片级的并行程度理论上取决于帧的分片数,分片数越大,获得的并行加速比越大,但由于在编码过程中要加入片头等信息,这样就增加了系统开销,因而在采取片级并行时,不能无限制地提高分片数目来获取加速比,需要对图像质量、视频压缩率和并行效率三者做权衡,来决定每帧采用的分片数。假如帧I,P和B的排列顺序为IBBPBBP,其N个线程的Slice级并行方法如图2所示。
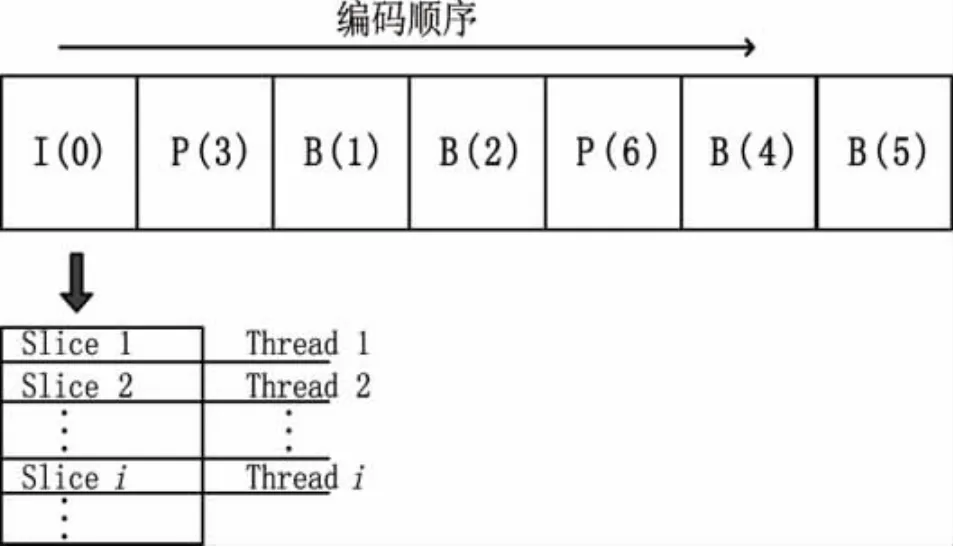
图2 Slice并行方法示意图
2.2 算法实现描述
片级多线程并行编码算法实现过程如下:
步1:主线程依次读入帧,对每一帧按照设定的thread来进行slice划分,通过主线程来创建各个片的线程,每个片独立进行编码。
步2:当创建的片级线程数目达到设定的线程数时,主线程将处于堵塞状态,几个slice并行编码,各个片之间不相互参考,仅参考已经编码完的图像。
步3:当所有片级线程都编码完成时返回到主线程,主线程继续读入下一帧,如果所有的帧都编码完成则结束,否则转入步2。
3 帧间宏块级的X264并行编码算法
3.1 帧间宏块级并行
帧间宏块级并行方法如图3所示,当Img0中的第一行已经被处理完的时候,它还不能被立即编码。这是因为运动估计的搜索范围要大于两个宏块大小。为了准确地预测帧的运动区域,必须等去块滤波和四分之一像素插值之后的编码宏块被重构。如果运动估计的搜索范围是宏块的两倍大,那么直到Img0的第三行被编码完成后Img1左上角的第一个宏块才能被编码。在图3中,Img1中当前正在编码的宏块可以和Img0中带有相同颜色的宏块同时进行编码。此后,只要判断宏块间不存在数据依赖性,Img1中的宏块就可以和Img0的一些宏块同时进行编码。通过增加帧间并行,在X264编码器中提供了更多的并行性[9]。此算法的并行机理在于:当前帧要编码的宏块跟其余帧的其他宏块同时编码的条件是必须等当前帧的宏块要参考的其余帧的宏块编码完成。
3.2 算法实现描述
帧间宏块级多线程并行算法实现过程如下:
步1:主线程依次读入帧,然后通过主线程来创建辅助线程,先创建的线程进行编码,随后的帧只有当其参考帧中所依赖的宏块编码完成后才能开始编码。
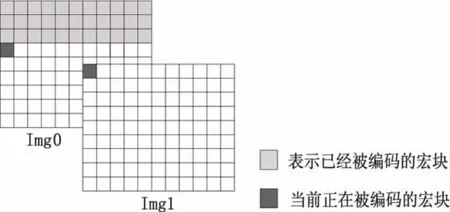
图3 帧间宏块级并行方法示意图
步2:当创建的辅助线程达到设定的线程数时,主线程将处于堵塞状态,辅助线程并行的编码各帧中没有相互依赖关系的宏块。
步3:当最先被创建辅助线程的帧编码完成时将返回到主线程,主线程继续读入新帧(直到没有新帧转步4)并为其创建新的线程,以保证用于并行编码的线程达到设定的线程数,然后重复步2。
步4:当所有的帧编码完成之后,辅助线程释放,主线程完成后续工作并退出。
4 两种算法实验结果与分析
算法使用VS2008开发平台,以X264为研究对象,实验用C语言编写。实验设备是一台双核PC机:操作系统为Microsoft Windows XP Professional(SP3),CPU规格为Intel Core 2 Duo CPU T5800(2.00 GHz),内存为 2.00 Gbyte,硬盘为 160 Gbyte。
实验采用主要编码档次,其主要的编码参数设置为:B帧为2帧;参考图像为1帧;环路滤波可用;CABAC熵编码算法可用;运动估计的搜索范围为正负16个像素点。
实验选取了运动缓慢的Akiyo和运动剧烈的Coastguard两个视频序列,对片级并行编码算法和帧间宏块级并行编码算法分别在QCIF和CIF两种不同的格式下进行测试,测试序列均为300帧,设置keyint_max为250。
表1是片级多线程并行和帧间宏块级多线程并行两种方法在不同线程数下编码帧率(单位为f/s)的测试结果。
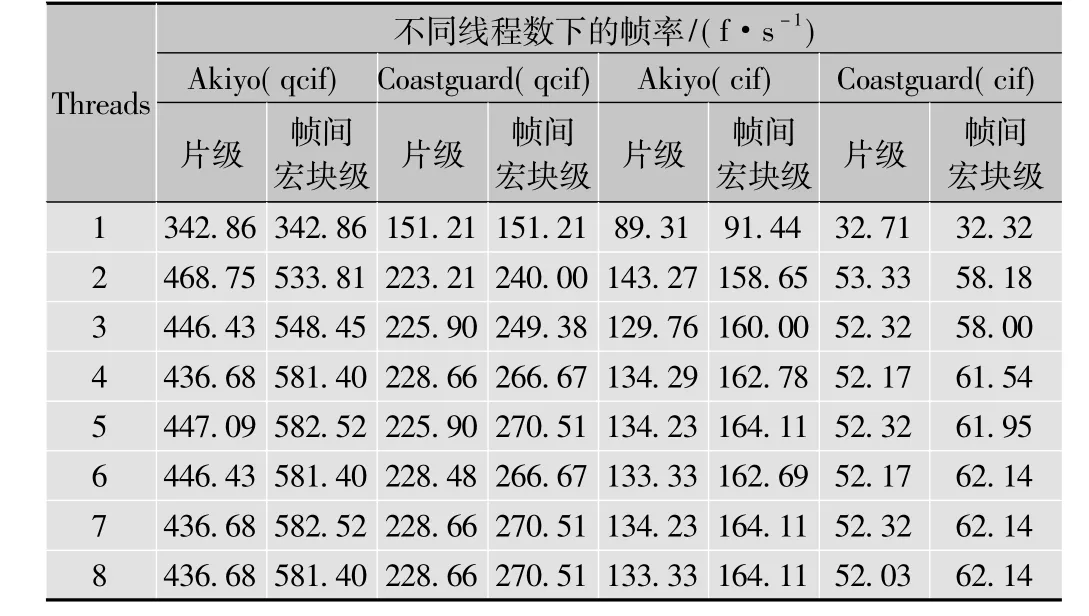
表1 两种并行方法在不同线程数下的帧率
图4和图5分别是视频序列Akiyo和Coastguard在两种并行算法实验测试下,不同线程数目对应的加速比的关系图。
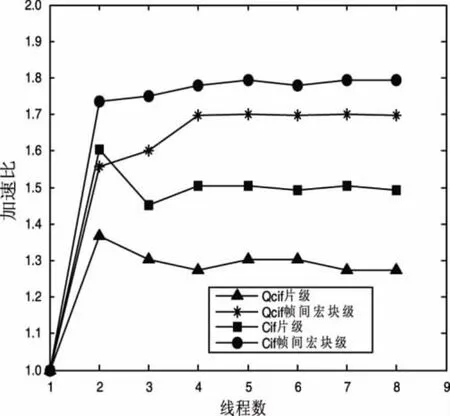
图4 Akiyo两种算法下加速比和线程数目关系
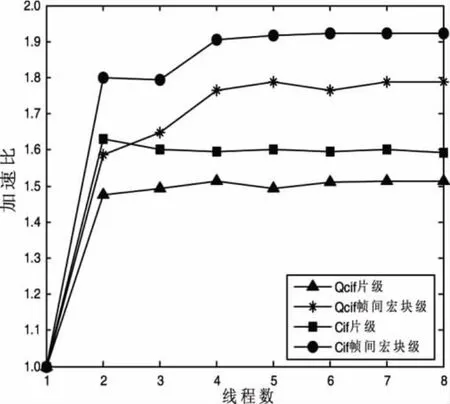
图5 Coastguard两种算法下加速比和线程数目关系
由测试结果可以看出,在设定的实验条件下,帧间宏块级多线程并行编码算法比片级多线程并行编码算法具有更高的加速比。另外,对于片级并行算法,并不是设定的线程数越多,得到的加速比就越高,尤其对于运动缓慢的视频序列,而当线程数为2时,加速比达到了最大。
表2是片级并行和帧间宏块级并行两种方法在不同线程数下编码码率(单位为kbit/s)的测试结果。
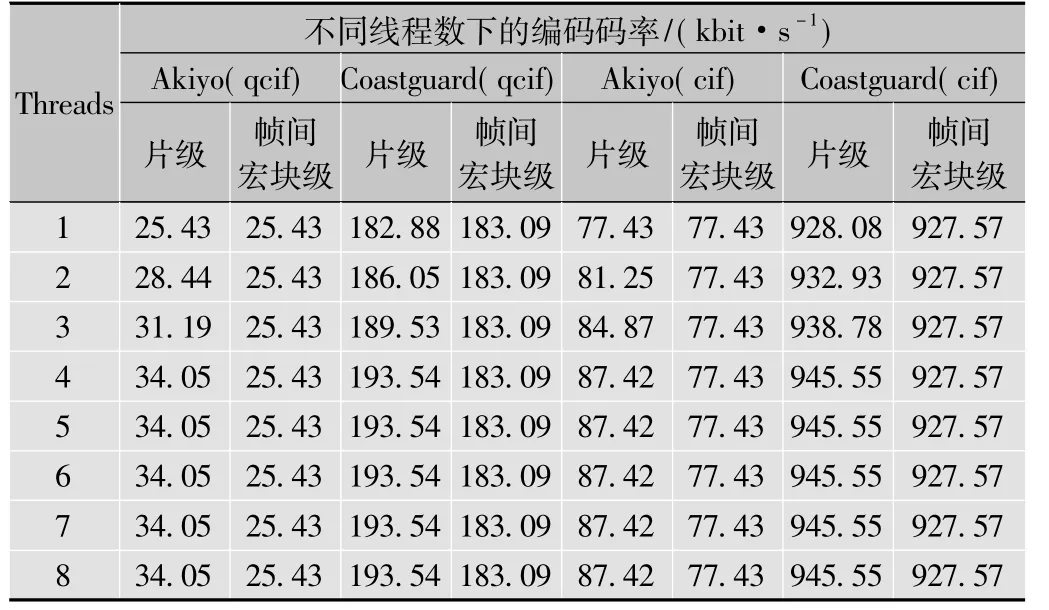
表2 两种并行方法在不同线程数下的编码码率
表3是片级并行和帧间宏块级并行两种方法在不同线程数下峰值信噪比(单位为dB)的测试结果。

表3 两种并行方法在不同线程数下的峰值信噪比
由表2的测试结果可知,帧间宏块级多线程并行编码算法得出的编码码率相对恒定,基本保持不变;片级多线程并行编码算法的编码码率随着线程数目的增大先增加后保持不变。由表3可以看出,两种算法下的峰值信噪比变化不大,片级多线程并行编码算法的相对偏低,因片与片之间的独立性破坏了片与片边界处数据的相关性。
通过上面研究和实验可以得出,在编码码率相对恒定的条件下,帧间宏块级多线程并行编码算法比片级并行编码具有更高的编码速度,同时因为片级并行编码方法容易产生条带效应,所以要考虑图像质量,但是片级并行编码因只对一帧图像进行编码,在系统中只需保存与该帧图像编码相关的一些参考帧图像数据便可,对内存需求要少,系统开销要少,所以在进行X264并行编码的过程中,需要对图像质量、内存利用率和并行效率三者做权衡来折中考虑这两种算法,同时也可折中这两种算法的优缺点来研究视频编码的并行处理。
5 结束语
本文分别研究了片级多线程并行编码算法和帧间宏块级并行编码算法,通过实验得出了这两种算法的优劣势。对比实验结果表明,在编码码率相对恒定的条件下,帧间宏块级多线程并行编码算法比片级并行编码具有更高的编码速度,但因其需要对多帧图像进行并行编码,在系统中需保存与多帧图像编码有关的参考帧图像数据,所以占用大量的内存,于是提出可以结合两种算法的特点,将两种算法结合进行多线程并行编码算法研究。另外,因实验条件的限制,没有在更多核上进行这两种算法的比较,所以实验结果不够全面,未来的研究重点是实现X264最大粒度的并行。
[1]蒋兴昌,周军,罗传飞.H.264并行编码算法的研究[J].电视技术,2008,32(2):33 - 35.
[2]MEENDERINCK C,AZEVEDO A,ALVAREZ M,et al.Parallel Scalability of H.264[C]//Proceedings of FirstWorkshop on programmability issues for multi-core computers.Goteborg:[s.n.],2008:1 -164.
[3]许昌满,李国平,王国中.AVS编码器Slice并行编码算法研究与实现[J].中国图象图形学报,2009,14(6):1108 -1113.
[4]BUTENHOF D R.Programming with POSIX threads[M].[S.l.]:Addison -Wesley,1997.
[5]WIEGAND T,SULLIVAN G J,BJONTEGAARD G,et all.Overview of the H.264/AVC video coding standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2003,13(7):560 -576.
[6]SULLIVAN G,TOPIWALA P,LUTHRA A.The H.264/AVC advanced video coding standard:Overview and introduction to the fldelity range extension[C]//Proceedings of SPIE conference on applications of digital image processing XXVII.[S.l.]:SPIE,2004:454 -474.
[7]ZHAO Z,LIANG P.Data partition for wavefront parallelization of H.264 video encoder[J].IEEE International Symposium on Circuits and Systems,2006(5):21 -24.
[8]MEENDERINCK C,AZEVEDO A,JUURLINK B,et al.Parallel scalability of video decoders[J].Journal of Signal Processing Systems,2009,57(2):173-194.
[9]CHEN Y,LI E,ZHOU X,et al.Implementation of H.264 encoder and decoder on personal computers[J].Journal of Visual Communications and Image Representation,2006,17(2):509 -532.
