基于区域融合的单视点图像深度信息提取
2011-08-09张兆杨
王 平,安 平,2,王 奎,张兆杨,2
(1.上海大学通信与信息工程学院,上海200072;2.新型显示技术及应用集成教育部重点实验室,上海 200072)
责任编辑:哈宏疆
0 引言
虽然2D视频技术在现今多媒体服务中得到成功应用,但是由于3D视频技术令人震撼的立体视觉效果使该技术得到了社会各界的广泛关注并迅速发展。3D视频技术从3D内容的获取到3D显示器的制造,涵盖了很多技术手段。其中,3D内容的获取是3D视频服务核心部分。获取3D内容需要一些特殊的设备,比如立体相机(或摄像机)、多视点相机或深度相机。尽管通过这些手段能生成一些3D内容,但其中还有相当多的关键技术没有解决,导致3D视频内容的匮乏,从而限制了立体视频显示技术的推广及应用。因此,将传统的2D视频内容转换为3D,成为填补3D内容缺失的快捷高效的解决方案。
然而,传统的2D片源缺乏深度信息,而深度信息是构成立体视觉的最重要因素。场景中物点到相机焦点的法线距离被称为对应该物点的2D图像中的像素深度值,所有像素点的深度值构成的矩阵就是该图像的深度图。
由于深度图的准确度严重影响重建3D场景的质量,因此,深度图提取是2D至3D转换过程中的关键步骤。如果用多台相机同时捕获多视点图像,可以通过立体匹配算法来得到深度图。然而,由于缺少相机参数、视差信息等附加信息,从单视点图像中提取深度还是很困难的,因此,只能通过分析单视点图像的单目深度线索来提取相对的深度值[1]。
最近几年,产生了一些从单视点图像中提取深度图的方法。S.Batiato提出了一种经典的方法[2-3],通过以下步骤来产生深度图:从梯度平面的生成、梯度深度的分配、区域连续性的检测到最终深度图的生成。Jae-Il Jung和Yo-Sung Ho通过贝叶斯分类器分析图像中不同的物体类型和属性,并分别对其采用不同的算法来实现相对深度值的分配[4]。然而,这些方法大都需要对图像进行较复杂的处理,计算量大。笔者提出一种基于区域融合的单视点图像深度提取方法,只需由图像中各像素点色彩信息进行区域融合,即可准确地得到相对深度图。
1 深度信息提取
尽管从单视点图像中提取深度是一个病态问题,还是有一些深度线索和特性可以用来预测深度信息。假设图像中每个目标物体都可用一个完整区域表示,则可将目标物体区域的边缘看作是深度值的变化边缘。整个过程分为两部分:利用区域融合,得到图像中需要深度提取的目标物体区域;再根据先验假设深度梯度变化进行深度分配,提取出深度图。
1.1 区域融合
这里采用基于统计概率的区域融合[5]。通过融合属于同一目标物体相邻间区域来消除伪边缘,得到图像中各目标物体的区域图。
在融合过程中,通过融合小区域或像素迭代地成长生成大的区域,像素点被认为是最基本的区域。像素点上各通道值独立分布于[0,255]。这里假设属于同一目标物体上的像素点的RGB值具有相同的统计平均值,而不同目标物体区域上,至少有一个RGB通道的统计平均值是不同的。通过计算区域之间各颜色通道平均值的差异来判断是否进行融合。
整个融合过程主要由融合阈值和融合顺序决定。融合阈值如式(1)所示
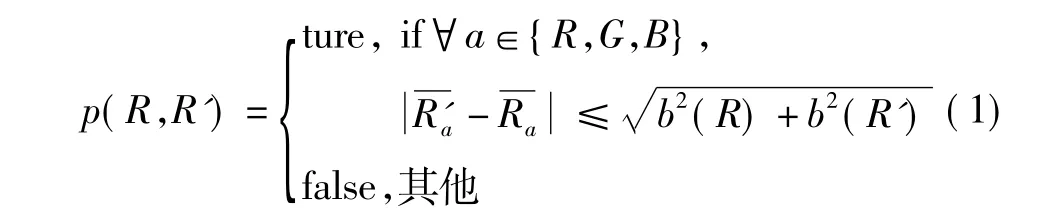
式中:Ra表示在彩色通道a中区域R的平均值;b(R)=g。|R|表示区域R中的像素个数;Q表示在各通道上可取随机变化取值的个数,Q值越大,像素点的变化就越丰富,这里一般取Q=24;δ表示允许的各通道统计均值变化范围,一般取δ=1/(6|I|2),|I|为图像I像素点个数。根据融合阈值,在区域间进行递增顺序的融合测试,即得到由关键区域组成的融合后的图像,这样就大大删减了与深度梯度变化无关的图像边缘。
1.2 深度分配
根据区域间的相对位置关系,由先验假设深度梯度变化对各像素点分配深度值。
单视点图像上像素点深度值变化是有方向性的,即沿着某一特定的方向,深度呈有规律的变化。大部分图像深度的变化规律是线性的,因此寻找到深度变化的方向就可对图像进行线性深度分配。单视点图像的先验假设深度变化图有很多种,如图1所示。但经过实验发现,大多数情况下,“bottom-up”模式是适合范围最广的模式,即深度值由下至上线性递增[6]。因此,这里先验假设深度梯度变化图就采用“bottom-up”模式。

图1 先验假设深度变化图
首先对图像中的关键区域进行深度分配,得到反映场景大体深度变化情况的相对深度图。本文分配深度值的原则有2个:1)关键区域中像素点深度值是一致的;2)关键区域的深度值由区域最下端像素点在先验假设深度变化图中的值决定,如图2所示。这里假设对象都是平面对象,即在对象平面区域上深度值是一致的。该假设忽略了立体对象深度值的变化,突出了关键区域之间的深度变化;从场景的大尺度角度出发,强调了对象之间深度层次关系。

图2 关键区域深度值
2 实验结果及分析
采用分辨力为1440×900的图像“远山”来做实验,实验结果如图3所示。并运用DIBR(Depth Image-Based Rendering)算法[7-8],绘制出3D 图像。通过 3D 显示器可观看3D图像,具有强烈的3D立体视觉效果。

图3 图像“远山”的实验结果图
图4给出了实验测试的部分图像及生成的对应深度图。本文方法与其他方法相比,优点在于无须提取出过多的深度线索,利用区域融合提取出单视点图像中深度变化边缘,生成了反映深度层次相对变化的深度图。实验时,可根据图像中目标物体区域之间色彩变化的复杂度,对Q值进行调节。对于场景色彩变化复杂的,可以适当增大Q,从而增加了融合后物体区域个数,来达到更好的视觉效果,反之亦然。

图4 实验结果
3 结论
本文提出了一种从单视点图像中提取出深度信息的方法。对图像中像素点色彩信息进行差异统计分析,并进行区域融合,生成关键区域;利用先验假设深度梯度图进行区域间的深度分配,绘制出深度图。本文方法可简单、有效的绘制出深度图,并生成具有强烈立体视觉效果的3D图像,适用于实时室外场景立体演示等相关应用。由于本文方法是假定于目标区域是垂直于拍摄方向的,即区域中像素深度值是一致的,对图像中垂直于拍摄方向的平面深度提取效果最优。
[1]CHENG C,LI C,CHEN L.A 2D-to-3D conversion system using edge information[C]//2010 Digest of Technical Papers International Conference on Consumer Electronics.[S.l.]:IEEE Press,2010:377-378.
[2]BATTIATO S,CURTIS,CASCIA M L,etal.Depth map generation by image classification[C]//Proc.SPIE:vol.5302.[S.l.]:SPIE Press,2004:95-104.
[3]BATTIATO S,CAPRA A,CURTI S,et al.3D stereoscopic image pairs by depth-map generation[EB/OL].[2010-04-01].http://cgit.nutn.edu.tw:8080/cgit/PaperDL/WSY_100506083318.PDF.
[4]JUNG J,HO Y.Depth map estimation from single-view image using object classification based on Bayesian learning[C]//3DTV-Conference:The True Vision – Capture,Transmission and Display of 3D Video.[S.l.]:IEEE Press,2010:1-4.
[5]NOCK R,NIELSEN F.Statistical region merging[J].IEEE Trans.Pattern Anal.Mach.Intell.,2004,26(11):1452-1458.
[6]KO J,KIM M,KIM C.2D-To-3D stereoscopic conversion:depth-map estimation in a 2D single-view image[EB/OL].[2011-01-23].http://koasas.kaist.ac.kr/bitstream/10203/24829/1/2D-To-3D%20Stereoscopic%20Conversion.pdf.
[7]安平,张倩,鞠芹,等.用于3DTV的图像绘制技术[J].电视技术,2010,34(1):49-51.
[8]鞠芹,安平,张倩,等高质量的虚拟视点图像的绘制方法[J].电视技术,2009,33(9):9-11.
