基于C64x+内核的H.264编码数据Cache优化
2011-03-15齐美彬陈俊峰
齐美彬, 陈俊峰
(合肥工业大学计算机与信息学院,安徽合肥 230009)
0 引 言
H.264实时视频编码系统,输入输出的数据量大,对算法的实时性要求较高[1,2],DSP芯片被广泛应用于 H.264视频编码系统中[3]。继以DM 642为代表的C64x系列DSP之后[4,5],TI公司推出了C64x+DSP内核[6],并且在达芬奇系列和OMAP系列中广泛使用。为了提高算法的实时性,可以从算法、指令、数据配置等方面对算法进行优化。文献[7,8]采用了线性汇编、内联函数来提高编码效率,但是未考虑数据分布在不同存储器中对算法速度的影响;文献[9]采用了EDMA且结合片内资源有限的特点,分批搬运数据,但未给出 QCIF、CIF、4CIF兼容的方案;文献
[10]根据H.264算法特点,将程序段拆分处理,提高了指令Cache命中率,该方法提高了L1P存储器的使用效率,但是要新增加数据缓冲区。文献[3-9]中,除文献[7]外其它均采用C64x平台,C64x+的优化策略与其基本一致。
C64x+内核因为采用了更为灵活的RAM和 Cache结构,因此对数据安排更为灵活,如何分配H.264编码器中的源帧、重建帧、参考帧、内插数据、预测数据等,对编码速度有较大的影响。本文在文献[8]工作的基础上,围绕RAM、Cache、缓存一致性3个方面进行分析,指出了提高运算速度的方法。
1 片上存储器资源性能分析
图1所示为C64x+内核存储架构示意图[11],分为片上的L1(包括L1D和L1P)和L2以及片外(ex ternalmemory)的DDR2,L1、L2和DDR2速度依次降低,L1D、L1P和 L2又各自分为RAM和Cache。每一级Cache只对下级存储器缓存,其中W rite Buffer的容量为4×128 bit。为了防止一些并发请求被堵塞,这些资源统一由Bandw idth M anagement(BWM)来管理,这些请求包括CPU、L1P、L1D、IDMA、EDMA等。
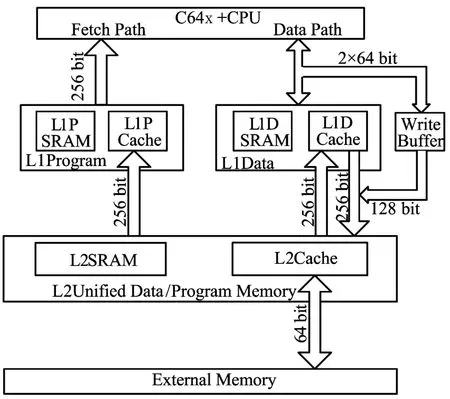
图1 C64x+Cachememoy架构
1.1 存储器级别与CPU访问速度之间的关系
对存储器中的数据访问均需要E1、E2、E3、E4、E5这5步,其中E3环节耗费的时间与存储器位置有关,数据在L1中需要1个周期,在L2中需要6~8周期,在DDR2中至少8个周期,因此数据所处位置应按照L1、L2、DDR2的顺序考虑。
1.2 RAM存储器结构
L1D memory最多支持至 1 M可编址的RAM,其起始地址为1 M边界对齐,长度为16 k的倍数,L1D memory被分成区域0和区域1,其中区域0的大小可以是0,也可以是2的倍数且介于16~512 k中间。区域1起始于区域0末端,大小是16 k的倍数且介于16~512 k之间。若区域0非0,则区域1必须不大于区域0。L1D Cache是从部分或全部区域1转换得到,转换从最高地址开始到低地址。
L2 mem ory是为了连接较快的 L1 memory和较慢的externalmemory,其优势在于能够提供较大于 L1的空间。L2 memory包括 port 0 (RAM/Cache)或port 1(RAM),前者支持将不多于256 k的空间转换为Cache[12]。
1.3 Cache存储器工作机制
C64x+内核具有强大的 Cache控制模块,Cache作为CPU(Core)和低速存储器之间沟通的桥梁,有效弥补了CPU与存储器之间的速度差异,基于代码和数据的空间和时间相关性,以块为单位由硬件控制器自动加载数据和代码,同时维护缓存一致性。
图2所示为CPU访问存储器内容的操作流程,在这个流程中,CPU对存储器的访问总是从离CPU最近一级存储器开始。如果命中,CPU可以直接得到数据/代码,否则,代码/数据会被加载到前几级的Cache中。
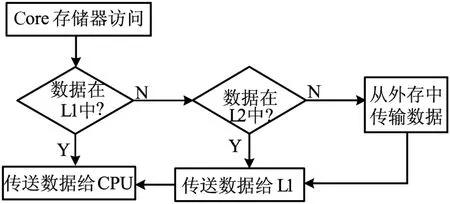
图2 CPU访问储存器内容流程图
L1D Cache属于read-allocate、回写、双路组关联结构,其原理如图3所示(本文所指的缓存空间均为 32 k字节)。L2 Cache属于read-andw rite allocate,回写,4路组关联结构,本文重点分析L1D Cache。
双路组关联结构Cache映射的规律是,凡16 k字节边界对齐的地址均从其中一路第0行开始映射,每行64字节,依此排列,因此是一行对应多个地址的关系。对于32位的存储地址,第6位代表一行中64字节的偏移,中间7位代表128行的偏移,高18位是 tag,tag是缓存的关键技术,是地址的唯一标志,此外还与Valid(是否有效)标志、Dirty(该地址是否最近更新过)标志、LRU(最近最少使用)标志在一起共同组成Cache控制模块的关键参数。这些参数的确定过程比较复杂,且在不同情况下使用不同的参数。本文只分析CPU读缓存命中和写缓存命中这2种最期望发生的情况,以及读缓存缺失和写缓存缺失这2种不期望发生的情况。
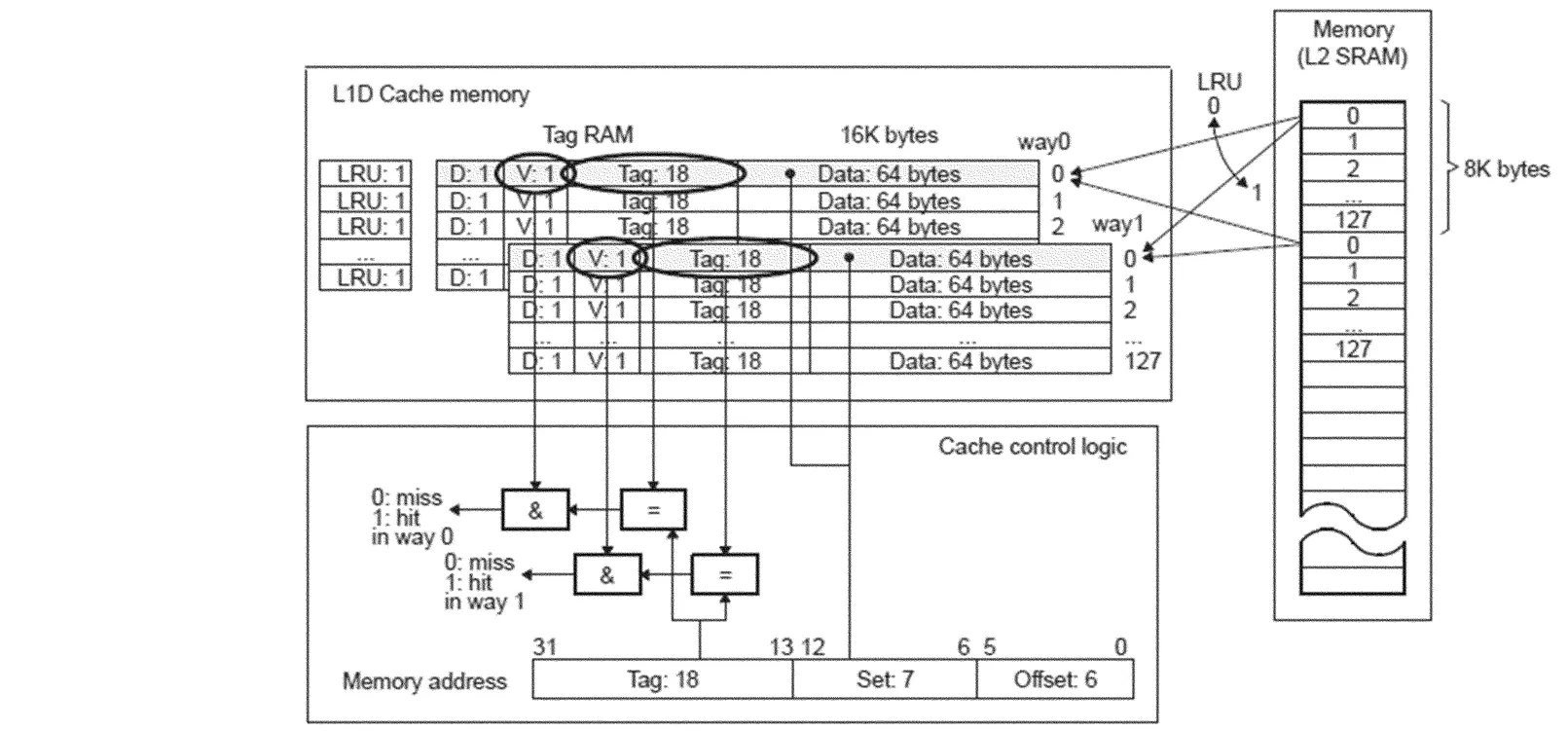
图3 L1D Cache结构
(1)读缓存命中。CPU取指令得到数据地址后,对此地址的32位经过拆分,若能找到匹配的某一路的某一行,且此行的V位有效,则为读命中。
(2)写缓存命中。CPU在得到将要写出去的数据的地址后,对其拆分,若匹配成功,则为写命中,再判断若Dirty位为无效则直接写入数据;反之,先将对应的数据回写到下级存储器中,再写入数据(此操作是为了维护缓存一致性)。
(3)读缓存缺失。与(1)类似,此时发现匹配不正确,则从下级存储器中取得数据,然后再根据地址和LRU将数据写到缓存中,LRU为0表示0路是最近最少使用,则写到way0,然后CPU再从缓存中取得数据送到寄存器。
(4)写缓存缺失。与(2)类似,但此时发现匹配不正确,则直接将数据送入W rite Buffer。当发生读缺失或W rite Buffer已满等情况时,立即先执行将W rite Buffer的内容清空并写到下级存储器的操作(此操作也是为了维护缓存一致性)。
综上所述,读和写缓存缺失都会使效率降低。一般而言,理想情况是读写皆命中,最不利的情况是:读缓存缺失重新往缓存写入新数据时,将其中没有使用的数据冲刷掉,导致新的缺失[13]。
1.4 缓存一致性
在基于Cache的运行机制下,如果所有的代码和数据的存取都由CPU来完成,CPU始终能得到存储器中最新的数据,但当有其它更改存储器内容的部件存在时(如不需要CPU干预的EDMA引擎),可能会出现由于Cache的存在而导致CPU或DM A不能得到最新数据的现象,也就是Cache一致性问题,这个问题多数情况会导致运算结果的不正确。
在一个特定的时间范围内,缓存和存储器中内容可能不一致,因为缓存的作用是将低速存储器中的内容自动搬运到高速缓存中反复使用,当其它数据发生读缺失时,其空间才可能被占用,然后回写。回写之前,缓存中的内容和存储器中临时不一致是正常的。
2 提高片上存储器使用效率
2.1 提高RAM存储器使用效率
有2种情况会影响对RAM访问的效率:①存储体内部阻塞,同时读或写的地址在同一个存储体内会引起CPU阻塞,需要同时访问的2个地址应该位于不同的存储体;②边界没有对齐,地址不对齐降低访问效率,根据被Cache的级别不同,对齐的字节不小于上一级缓存的行宽的整数倍,即数据处于L2D RAM中为64字节,在DDR2中则为128字节。
数据应优先放在L1 RAM中,若空间不足再根据算法需要把某些数据放在L2 RAM中。
2.2 提高L1D Cache存储器使用效率
(1)提高CPU读缓存命中的方法。Cache控制器功能,即如果CPU访问某一行某一个字节(地址)读缺失,则会按照映射规律,将下级存储器中对应的所有64个字节(地址)都Cache到此行,因此每一行只有第1个字节是读缺失,此行后续字节皆可读命中。
若数组A和B同时参与运算,数组A占用的长度小于16 k,要保证已经Cache进来的行不会被数组B占用,则数组B和A的长度之和不要超过16 k。若数据长度大于16 k,则应尽量调整算法,使得数据分成若干个16 k以内的逻辑块,保证已经Cache进来的数据尽可能少地被替换掉。
(2)提高CPU写缓存命中的方法。CPU写缓存,即CPU需要将数据从寄存器写到Cache,发生写缓存命中的条件是:此地址已经按照映射规则被Cache进来了。由于L1D Cache是 readallocate的,有2种方法可以采用:①若此地址同时需要参与输入运算,即CPU需要先读入地址,则采用(1)的方法;②若此地址不需要参与输入运算,即CPU仅需要向此地址写数据,则需要采用TI提供的touch函数[4]。
2.3 维护缓存一致性
数据段除了硬件自动维护缓存一致性以外,有4种典型的需要人为维护的情形。
(1)其它m aster更新DDR2中的内容后,在CPU读取此内容之前,需要将 L1D Cache、L2 Cache中此内容无效。
(2)CPU更新数据到DDR2后,更新的数据可能只是被保存在了L1D Cache、L2 Cache中,在其它master读取DDR2的被更新的内容之前,需要将Cache回写。
(3)在L2存储器中开辟了缓冲区并且其它master对数据不断进行更新后,在CPU读取此数据之前,需要将L1D Cache中的对应数据进行使无效操作。
(4)在L2存储器中开辟了缓冲区并且CPU对数据进行循环更新后,在其它m aster读取此数据之前,需要将L1D Cache中的此内容回写。
第(3)、(4)种的情形通常在编码中比较常见,即单帧数据不断写到DDR2上,但是需要EDM A分块搬运到L2存储器固定的乒乓结构中。
3 H.264编码存储器优化及实验验证
结合上述思想,本文采用H.264编码器作为实验,H.264数据分类见表1所列。
实验平台为SPECTRUM DIGITAL公司的TMS 320DM 6437EVM板,时钟周期600 MH z,具有128M DDR2空间、32 k L1P Cache/RAM、80 k L1D Cache/RAM、128 k L2 Cache/RAM。采用下列划分方法,即32 k L1PCache、48 k L1D RAM、32 k L1D Cache、64 k L2 RAM、64 k L2 Cache。
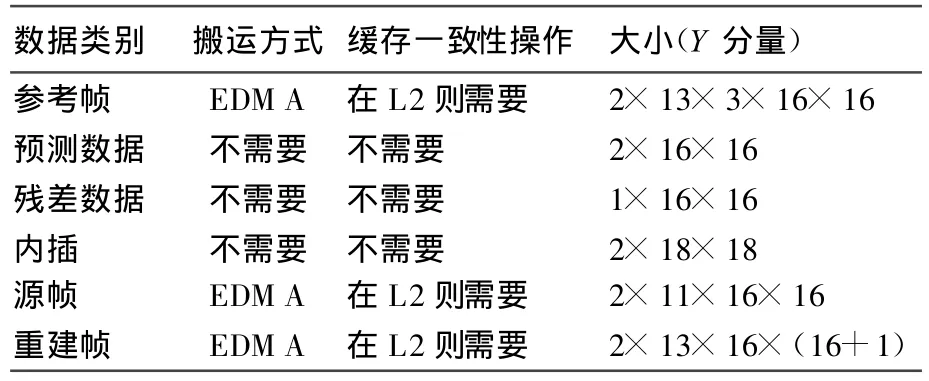
表1 H.264数据分类表
为了充分发挥C64x+内核的性能,本文充分利用L1 RAM和L2 RAM并且尽可能地提高L1D缓存命中率的方案,因此需要对关键数据在L1和L2 RAM中如何分布进行实验。以下实验都是以第1个P帧作为代表测试CIF序列,P帧采用16×16分块。共6种数据,通过表2~表4所列的结果来确定最优组合。
表2所列是对参考帧、重建帧、原始帧3种数据在L1、L2的不同组合进行实验,其条件是将预测数据、残差数据、内插数据置于L1,按照64字节对齐;表2中未列出的3种组合会导致L1或L2空间不够,故予以排除。
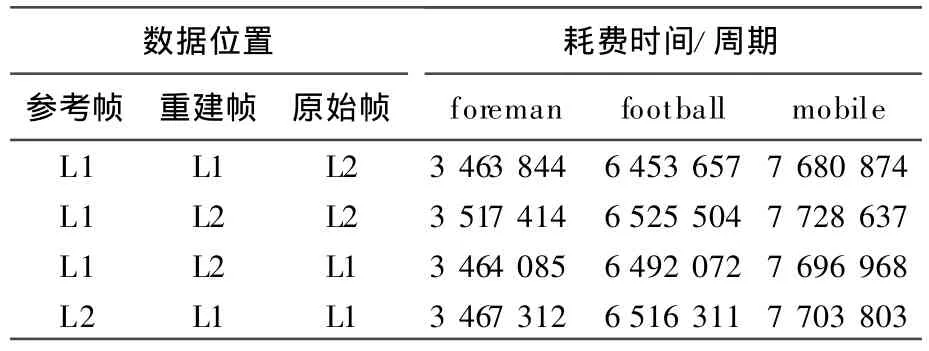
表2 实验方案1
表3所列是对预测数据、残差数据、内插数据3种数据(数据均为64字节对齐)在L1、L2中的不同组合进行实验,是实验方案1的延续,即在表2中耗费时间最少的组合基础上完成。
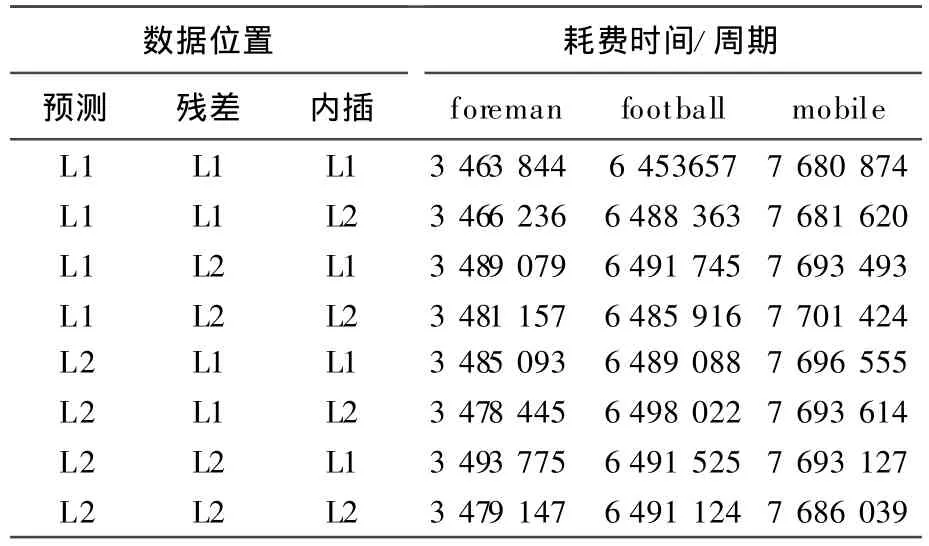
表3 实验方案2
表4所列在实验方案1、实验方案2所决定的最优组合的基础上,对6种数据在不同存储器中边界对齐进行实验。
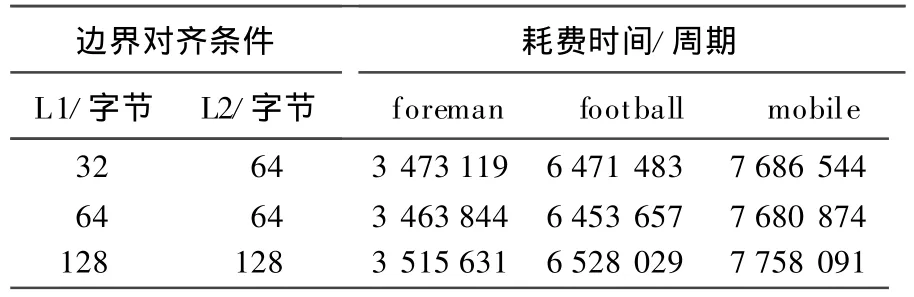
表4 边界对齐不同时所耗费的时间
对于原始帧数据,其长度小于16 k,将其放在L2 RAM中,可以使L1D Cache的缓存读命中率很高。对于预测数据、残差数据、内插数据、重建帧数据,放在L2中会存在L1D Cache写缺失的问题,在L1RAM中会使CPU阻塞的可能性增加,实验表明后者更有利于效率的提升。对于参考帧、数据长度大于16 k,放在L2中不利于提高L1D Cache缓存读命中率。从中可以看出,最优组合的结果与本文分析的一致。
表2中最差的一种组合同样按照表3、表4的方法去实验,最后可得到一种最差结果,2种结果对比见表5所列。
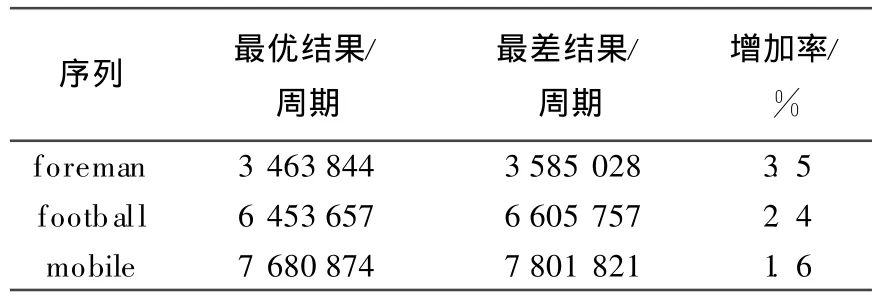
表5 最优组合和最差组合耗费时间比较
由表5可以看出,最差结果比最优结果有不同程度的时间增加。另外,在最优结果下foreman可以更为流畅的实现4路CIF,相当于同等复杂度的一路D1,而后两者由于较为复杂只能实现约2~3路CIF,这与本工程实际测试结果相吻合。
4 结束语
本文针对C64x+内核的存储器结构进行详细分析,给出了提高性能的策略,并在本文所采用的片上资源分配方案下,针对H.264编码器所涉及的数据特点,提出了一种最优分配方法并经实验验证,对于其它领域应用C64x+内核进行开发有一定的参考价值。
[1] Telecommunication Standardization Sector of International Telecommunication Union(ITU-T).H.264:advanced video coding for generic audiovisual services[EB/OL].[2010-04-01].h ttp://www.itu.int/rec/dologin-pub.asp lang=e&id =T-REC-H.264-200503-S!!PDF-E&type=items.
[2] 窦建华,王 英,李长凯,等.基于CPLD和DSP的线阵CCD数据采集系统设计[J].合肥工业大学学报:自然科学版,2010,33(5):690-693.
[3] 李方慧,王 飞,何佩琨.TMS320 C 6000系列DSPs原理与应用[M].第2版.北京:电子工业出版社,2003:315-326.
[4] Texas Instrumen ts Incorporated.TMS320C6000 DSP cache user'sguide(sp ru656)[EB/OL].[2010-04-01].h ttp://focus.ti.com/lit/ug/spru656a/spru656a.pdf.
[5] Texas Instruments Inco rporated.TMS320 C64x DSP tw olevel in ternalm emory reference guide(sp ru610)[EB/OL]. [2010-04-01].http://focus.ti.com/lit/ug/spru610c/spru610c.pdf.
[6] Texas Instrumen ts Inco rporated.TMS320C 64x/C64x+DSP CPU and istru ction set reference guide(spru732)[EB/ OL].[2010-04-01].http://focus.ti.com/lit/ug/spru732h/ spru732h.pdf.
[7] M ohammadnia M R,Taheri H,Motamedi SA.Im plementation and optim ization of real-time H.264/AVC main p rofile encoder on DM 648 DSP[C]//Proceedings of 2009 In ternational Conference on Signal Acquisition and Processing. New York:IEEE Press,2009:48-52.
[8] 李小红,蒋建国,齐美彬,等.基于DSP的H.264关键模块技术的研究及实现[J].仪器仪表学报,2006,27(10): 1330-1333.
[9] Zhuo L,W ang Q,Feng D D,et al.Optim ization and im plementation of H.264 encoder on DSP platform[C]//Proceeding of IEEE In ternational Conference on Multim edia and Expo.New York:IEEE Press,2007:232-235.
[10] 宋立锋,戴青云.H.264实时编码的指令Cache优化[J].电子学报,2008,36(8):1615-1619.
[11] Texas Instruments Incorporated.TMS320DM 643x DMP DSP subsystem reference guide(spru978)[EB/OL]. [2010-04-01].h ttp://focus.ti.com/lit/ug/sp ru978e/spru978e.pdf.
[12] Texas Instrum en ts Inco rporated.TMS320C64x+DSP megamodule reference guide(spru871)[EB/OL].[2010-04-01].http://www.ti.com/litv/pdf/spru871j.
[13] Texas Instrum ents Incorporated.TMS320C64x+DSP cache user's guide(spru862)[EB/OL].[2010-04-01].http://focus.ti.com/lit/ug/spru862b/spru862b.pdf.
