从文体学角度看《政府工作报告》英译本句子特征
2010-12-29崔亚妮陈建生天津科技大学外国语学院天津300222
崔亚妮 陈建生(天津科技大学外国语学院,天津,300222)
从文体学角度看《政府工作报告》英译本句子特征
崔亚妮 陈建生(天津科技大学外国语学院,天津,300222)
语料库语言学为语言研究提供了一种新方法。基于语料库分析中国《政府工作报告》英译本会使得文体分析更具科学性和客观性。以此从文体学角度分析《政府工作报告》英译本在句子层面所表现出的一些特征,并与美国《国情咨文》进行对比。句子特征是文体特征的一个方面,反映某一类文体语法层面具有的独特风格。用客观数据表明两者在句子特征上存在的差异,并探讨了产生差异的原因,为《政府工作报告》的翻译研究提供了一个新的视角。
语料库语言学;《政府工作报告》英译本;文体分析;句子特征
进入新世纪以来,中国的改革开放进一步深化,国际交流日益频繁,在世界政治经济生活中的影响日益扩大,这也使中国在国际舞台上越来越令人瞩目。一年一度的《政府工作报告》是中国政府所作的工作总结和工作部署,对国家的发展具有重大而深远的意义,同时也是中国政府对外宣传的重要途径,是外界了解中国政治经济文化的权威来源。因此,《政府工作报告》的翻译对中国与外界的交流和发展起着举足轻重的作用。
从文体的角度来分析,《政府工作报告》属于政论文体,具有鲜明的特色,这主要体现在以下几个方面:第一,从形式来看,它由国务院总理在全国人民代表大会上宣读,但其内容又是经过精雕细琢的;第二,从内容来看,《政府工作报告》涉及过去一年的政府工作情况总结和下一年的工作部署以及政府自身建设,这些都是严肃的政治问题,因此其用语严谨,准确规范,书面语特征显著;第三,从正式程度看,《政府工作报告》属于非常正式的官方文件。这些特征要求译者在翻译《政府工作报告》时要忠实于原文的精神,同时译文的文体特征也要尽可能与原文的文体特征相同。
目前国内对《政府工作报告》翻译的研究主要集中在对单个译本的定性分析上,而从句子层面的定量分析却寥寥无几,更不用说与同文体的本族语文本进行对比。以此以中国《政府工作报告》和美国《国情咨文》为语料,采用语料库语言学的分析方法,对近几年我国《政府工作报告》英译本的句子特征进行研究,并与本族语文本对比,找出两者之间的差异,同时探讨产生差异的原因。
一、国内外文体学理论研究
文体学是研究文体风格的学科。但是,古往今来人们对文体风格的定义众说纷纭,难以定论。如Chatman所说,文体风格是一个意义含混的术语[1]。文体学在国内外早先是从修辞学衍生的一个分支,在较长时间内又被认为是文学批评的领域。随着现代语言学理论的发展,人们加深了对文体实质的认识,并试图将有关理论应用于文体分析,从而使这门学科相应地获得飞速的发展,获得了“新文体学”、“科学文体学”和“语言文体学”等名称[2]。
由于文体学运用不同的语言学理论和方法进行文体分析,因此国外学者提出了不同的理论模式。按照Carter和Simpson的区分,有“形式文体学”、“功能文体学”、“话语文体学”、“社会历史/文化文体学”、“文学文体学”、“语言学文体学”等六种模式[3]。
中国的外语学者中最早注意到西方现代文体学研究的当数王佐良先生。他在70年代末发表的“英语文体学研究及其他”吹响了英语文体研究的号角。徐有志和秦秀白等学者把文体学分为“普通文体学”和“文学文体学”,前者研究包括文学各体裁特征在内的各种文体(含语言使用变体),后者研究文学文体;胡壮麟和刘世生等倾向于把文体学分为“理论文体学”、“普通文体学”和“文学文体学”[4]。本文所研究的内容属于普通文体学范畴,对政论文体英译本句子层面所表现出的语言特征进行探讨。
二、本研究使用的语料库
本文是一项基于可比语料库(comparable corpus)的研究,这个可比语料库由中国《政府工作报告》英译本和美国的《国情咨文》构成。《政府工作报告》子库收录了从2004年到2010年的中国《政府工作报告》英文译文,约11万词,并在句子水平上与中文原文(约13万字)对齐。《国情咨文》子库收录了从1994年到2010年美国公开发表的《国情咨文》原文,规模约为11万词。此外,根据研究的需要,这两个子库都使用CLAWS词性附码器做了词性附码,采用的是分类详细的CLAWS7词性附码集。
三、分析与讨论
本文针对中国《政府工作报告》英译本在句子层面体现出的特征进行研究,将从句子个数、平均句长和句长标准差、被动语态的使用以及复合句所占比例等几个方面对两个语料库进行对比分析。另外,文章还对中国《政府工作报告》中的特殊句式——无主语句子的翻译做了分析。
(一)句子个数、平均句长、句长标准差
句子个数和句子长度是研究文体特征的一个重要方面。平均句长是指文本中句子的平均长度。由于所选文本都属政论体裁,文本中句子以句号和分号结尾居多,因此本文所说的句子是从形式上定义为以句号、分号、问号和感叹号结尾的一个字符串。一个语料库的平均句长在某种程度上能反映出句子的复杂程度。Bulter指出,可以根据句子长度把句子分为三类:短句(1-9个词)、中长句(10-25个词)和长句(25个词以上)[5]。句子长度越长,句子越难理解。句长标准差表示句子长度在平均句长左右浮动的程度。以下是对两个语料库进行统计得出的结果。
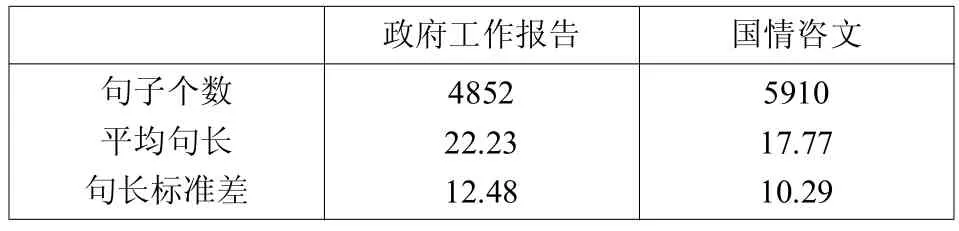
表1 两个语料库的句子个数、平均句长和句长标准差比较
表1的数据表明,《政府工作报告》与《国情咨文》在平均句长和句长标准差上存在差异。独立样本t检验的结果证明这个差异具有相当大的显著性(t=20.32,p<0.0001)。因此,《政府工作报告》在句子层面上比同文体的本族语文本较难理解,句子长短变化大。造成这一现象的原因可能是受汉语原文的影响。汉语句子常常结构松散,句子成分之间缺乏形式化联系,这一特点在《政府工作报告》中也有体现。政府报告句子偏长,句型结构单一,多用并列短句或并列谓语,“一逗到底”,连接成分使用不多,层次不太明显[6]。以下是历年《政府工作报告》原文和译文句子个数的统计结果,具体见表2。
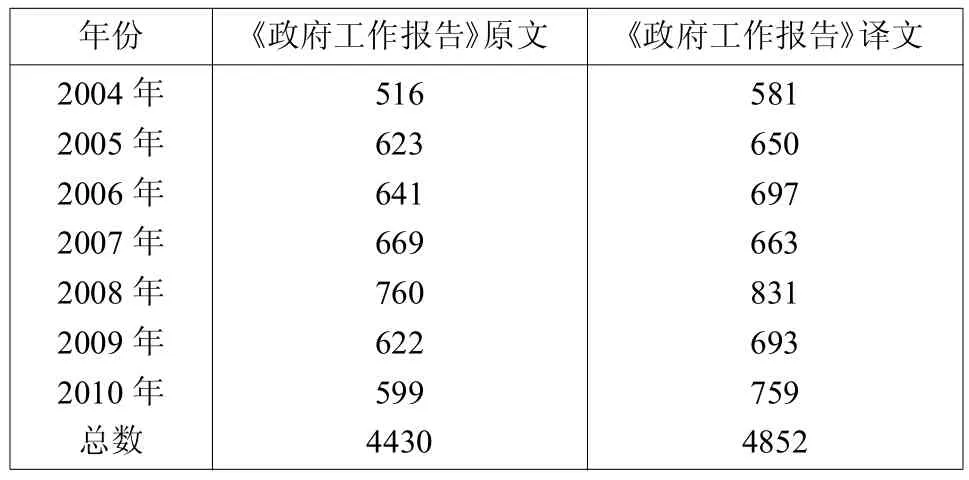
表2 历年《政府工作报告》原文和译文中句子的个数
从表2可以看出,《政府工作报告》译文文本句子个数除了2007年与原文句子个数相当之外,其余都多于原文文本。在观察双语平行语料库后发现,译者在翻译过程中既采用了分译也采用了合译的翻译策略。但是,分译的情况多于合译,这是造成译文句子个数多的一个原因。
汉语句子呈竹节式的流水句结构,而英语句子为树状结构,它有独立句表达重要的信息,各种从句和短语表示次要信息。译者在《政府工作报告》翻译中遇到流水句时,分析整句话中的几层含义以及主次逻辑关系,对原文进行恰当的断句翻译,即为分译。如:
原文:二是大力推进企业组织结构调整和兼并重组,支持优势企业并购落后企业和困难企业,鼓励强强联合和上下游一体化经营,提高产业集中度和资源配置效率。
译文:Second,we will energetically adjust the structure of enterprises and carry out mergers and reorganizations.
We will support superior enterprises in acquiring ones that are backward or have financial difficulties.
We will encourage well-established enterprises to work with each other,and upstream and downstream enterprises to integrate their operations in order to raise the level of industry concentration and the efficiency of resource allocation.
以上例句摘自2009年《政府工作报告》中叙述2009年主要工作任务部分。原文用一句话概括我国为大力推进经济结构战略性调整所采取的措施中的一项。原文中的各个分句都是并列关系,而译者在翻译时采用分译的翻译策略,将每个分句翻译为独立完整的一句话,表达清晰,意义明确。
此外,汉语注重意合,句与句之间的联系依靠本身的语义,而英语注重形合,需要用连接词等手段反映句子之间的逻辑关系,译者在对待具有逻辑关系的句子时,适当的用连词将两个句子合为一句,即合译。如:
原文:调整对外贸易结构。完善出口退税、关税和加工贸易政策,控制高耗能、高污染产品出口。
译文:We adjusted the trade mix by improving policies concerning export tax rebates,tariffs and processing trade and by controlling the export of products whose manufacture is highly energy consuming or highly polluting.
原文是独立的两个句子,译者在翻译时用介词by将两个句子合译为一个,把句子之间的逻辑关系表达得更显化、更清晰,使译文更符合英语的表达习惯。
(二)被动语态
语态是动词的一种形式,它表示主语和谓语的关系。语态有两种:主动语态和被动语态。被动语态反映一种被动观念,被动观念是基于对客体处于被某种主体掌控之下所经历或形成的状态而出现的一种判断[7]。英语中的被动语态使用得比汉语要多,要普遍。一般说来,当强调动作承受者,不必说出执行者或含糊不清的执行者时,多用被动式。英语被动句是由“助动词be的某种形式+及物动词的-ed分词”构成。以下是对两个语料库中的被动语态进行统计的结果(见表3):
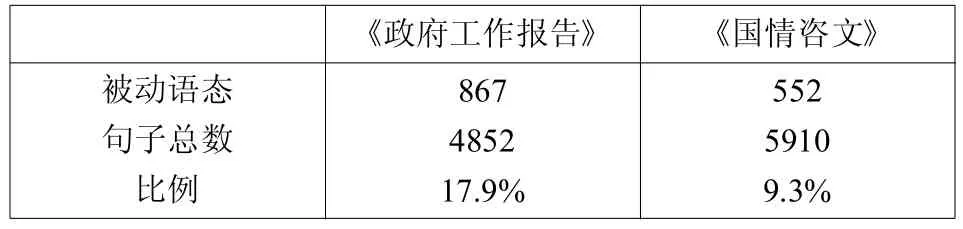
表3 两个语料库中被动语态的使用情况统计
从表3可以得到,《政府工作报告》的被动语态的句子有867个,占句子总数的17.9%;而《国情咨文》中被动语态的句子有552个,占句子总数的9.3%,前者远远大于后者。汉语中被动语态用得少,主要原因是大部分及物动词受到“被”字句“不幸语气”(inflicted tone)的限制不宜采用被动式,不仅如此,使用汉语结构被动式时,一般要求施动者同时出现,否则用主动句结构[8]。政府工作报告原文中被动语态很少出现,但译文却大量使用了被动语态。通过观察双语平行语料库可以作以下分析:
(1)政府报告原文中以宾语提前作为说话的主题,使用的动词暗示被动语态,译者在翻译为英文时直接用被动语态的形式。
(2)政府报告原文中无主语句子居多,是该类文体的显著特征,这个现象将在下一节具体分析;其中一些无主语句子的翻译中,译者把宾语作为主语,句子用被动语态。如:
原文:建立突发公共卫生事件预警和应急机制。
译文:A system was set up for early warning and response for public health emergencies.
原文:加强公共卫生设施建设。
译文:Public health infrastructure was improved.
(3)原文句子结构完整,但是译者为了强调宾语部分,也采用了被动语态。如:
原文:中央财政和国债资金加大了对农村教育的支持力度。
译文:Increasedfinancial supportwasextendedtoruraleducation from the central budget and treasury bonds.
原文:一年来,我国基础研究、战略高技术研究和高新技术产业化取得重要进展。
译文:Great progress was made last year in basic research,strategically important hi-tech research,and industrial application of new and high technologies.
⑷原文中有些句子主语较长,译者在翻译时为了避免头重脚轻,把宾语提前。如:
原文:国土资源管理、环境保护、林业发展和生态建设等方面都做了大量工作,取得新成效。
译文:Fresh progress was made in the areas of land and resources administration,environmental protection,forestry development andecological improvement.
原文:宏观调控体系建设、国有资产管理体制改革和银行业监管体系建设取得重要进展。
译文:Significant progress was made in establishing a macro-control mechanism,restructuring the management of state assets and establishinga mechanismfor oversightandmanagement of the banking sector.
此外,被动语态比主动语态结构更加简短也是造成译者在翻译时大量使用被动语态的原因。
(三)无主语句子的翻译
《政府工作报告》是总理代表政府向全国人民代表大会作的报告,无论是总结过去的工作还是报告未来的工作计划和目标,句子的主语绝大多数都应该是“本届政府”或“我们”。但是,汉语是非形态语言,并不注重句法结构形式上的完整,只要在上下文中句子意思清楚,省去句子的主语或其他成分是常见的。汉语是主题显著的句子,其突出的是主题而不是主语;而英语中形合法现象较为普遍,为了保持句子形式上的完整,绝大部分句子都不能没有主语,英语是主语显著的语言[9]。在《政府工作报告》的原文中,出现了大量的无主语句子,如:
原文:健全利率形成和传导机制。
译文:We will improve the mechanisms for setting and transmitting interest rates.
原文中“健全”的主语显然应该是“本届政府”或“我们”。但是,在《政府工作报告中》,“我们”要做的事情非常多,如果都把主语加上去读起来不符合汉语的习惯。但是,在译成英语时,由于英语语言的特点,如果大量使用这样的无主语的句子,会使人感觉好像是在发出命令,因为英语的祈使句一般没有主语,而且其中动词表示的动作是要求别人来做的。因此,译者在翻译这些无主语的汉语句子时采用了添加主语we的方法,使意义传达得更准确。如果分别统计一下作主语的“我们”和“we”在两个语料库中的词频,就可以非常清楚地了解到《政府工作报告》英译文的这一特点。

表4 两个语料库中“我们”和“we”词频的比较
从表4的数据可以看出,《政府工作报告》原文中的“我们”作主语时仅出现了202次,而译文中we却出现了2955次,可见译文中存在大量的添加主语we的现象。正是由于原文中这一特殊句式以及译者在翻译时采用的这一特殊方法,使得其译文中we的词频高于本族语文本。在《国情咨文》中,we仅出现了1892次,两者的差异相当显著。
(四)复合句
一般来说,英语的句子类型按句子结构可以分为简单句、并列句、复合句和并列复合句。简单句和并列句是两种较基本、较自然的句子类型;而复合句和并列复合句是较为复杂的句子类型。在英语中,从属连词用以引导从句,含有从句的句子称为复合句。复合句是用从属连词将有逻辑关系的句子连接而成的,文本中复合句所占比例越高,说明文本句子结构紧密,逻辑清晰,反之亦然。英汉两种语言在复合句的表达上存在着形合和意合的本质区别,即句与句之间的连接成分是保留还是省略的区别。英语重形合,其句子结构严谨,逻辑关系清楚;而汉语重意合,少用甚至不用形式连接手段,汉语语句结构松散。利用语料库检索软件wordsmith中的concord功能将两个语料库中的从属连词检索出来,根据从属连词的数量可以判断两个语料库中复合句的个数,以下是统计结果(见表5):

表5 两个语料库中复合句个数比较
从表5可以得出,《政府工作报告》英译文的复合句个数远远少于国情咨文。这是由于译者在翻译过程中受到原文汉语的影响。在观察语料库发现,译者翻译时使用了 while,when,so,because,if,since,although等从属连词将句子之间的逻辑关系表现出来,但是与本族语文本相比,这些连词所占的比例还是远远不够的。因此,译者应首先梳理原文的重要信息,使其成为英语主句,其他次要信息作为英语从句,并添加形式标记和连接词,从而使译文具有英语高度形式化和严密逻辑性的句法特征。
四、结论
通过以上基于语料库的分析与对比,可以得出中国政府工作报告英译本在句子层面所表现出的特点,从而反映其文体在语法层面的风格特征:(1)句子个数少,平均句长比《国情咨文》的平均句长更长,句子长短变化大;(2)被动语态的句子所占比例较大;(3)《政府工作报告》原文中无主语句子居多,其中一部分无主语句子采用了添加主语we的翻译方法,这一点在译文中体现出来;(4)根据从属连词的使用情况,可见其复合句所占比例远远少于本族语文本,译文在逻辑关系的表达上没有本族语文本充分。
从文体的角度来看,《政府工作报告》属于政论文体,此类文体用词严谨,语言规范,非常正式,在句子结构上具有属于该类文体的显著特点,如无主语句子居多,句子较长,句子之间逻辑关系不太紧密等等。因此,译文势必会受到原文文体特点的影响。与此同时,《政府工作报告》的翻译是为了达到中国政府对外宣传的目的,在保持原文文体风格的前提下,其译文在句子结构方面应符合外界读者的阅读习惯,接近本族语句法特点。因此,译者在翻译时,采用分译和合译翻译策略以符合本族语者表达习惯,被目的语所接受。在翻译原文中较长句子时,要分清主次关系,使用适当的从属连词将句子之间的逻辑关系清晰地表达出来。另外,《政府工作报告》译文中被动语态使用较多,一部分无主语句子翻译时添加主语的现象都与其原文特点有关。在今后《政府工作报告》的翻译中,应结合使用多种翻译策略,使得译文句子特征接近本族语者的使用习惯。
[1] Chatman,S.Literary Style.A symposium[M].London:Oxford University Press,1971.
[2] 胡壮麟,刘世生.文体学研究在中国的进展[J].山东师大外国语学院学报,2000(3).
[3] Carter,R&Simpson,P.Language,Discourse and Literature:An Introductory Reader in Discourse Stylistics[C].London:Unwin Hyman,1989.
[4] 吴显友.试论普通文体学的理论框架及其应用研究[J].外语教学,2003(9).
[5] Butler,C.Statistics inLinguistics[M].Oxford:Basil Blackwell,1985.
[6] 贾毓玲.从《政府工作报告》的翻译谈如何克服“中式英语”的倾向[J].上海科技翻译,2003(4).
[7] 王芳.浅谈汉英被动语态的应用差异[J].读与写杂志,2007(2).
[8] 闫新江.英汉被动句的比较与翻译[J].JournalofHuaiBei Professional and Technical College,2007(8).
[9] 司显柱,曾剑平.《汉译英教程》[M].上海:东华大学出版社,2006.
Stylistic Analysis of Sentence Features of English Translation of Government Work Reports
CUI Ya-ni,CHEN Jian-sheng
Corpus linguistics provides a new approach for language study.A corpus-based analysis of the English translated versions of the Reports on the Work of the Government(RWGs)makes the stylistic analysis more scientific and objective.This paper analyzes the syntactic features of English translated versions of RWGs fromthe perspective of stylistics,and compares them with those of State of the Union Addresses of the United States.Sentence feature is one aspect of stylistic features,which reflects distinct style in grammar of a certain genre.This paper,based on the data from the corpora,analyses the differences of syntactic features between the two texts and explores the possible reasons,thus providing a new perspective for researches on translation of the RWGs.
corpus linguistics;English translated version of the Report on the Work of the government;stylistic analysis;sentence features
H315.9
A
崔亚妮(1986-),女,硕士研究生,研究方向为语料库语言学。
