IP报文分类算法研究
2010-12-12李学锋
李学锋
(襄樊学院 数学与计算机科学学院,湖北 襄樊 441053)
IP报文分类算法研究
李学锋
(襄樊学院 数学与计算机科学学院,湖北 襄樊 441053)
从报文分类算法的实现特征出发,对当前常用的报文分类算法进行分类评述,分析了它们的时间、空间和更新复杂度以及各分类算法的优势、存在的不足和适用环境;最后,就报文分类问题的研究方向作出展望.
IP报文分类;时间复杂度;空间复杂度;更新复杂度
IP报文分类技术是交换机、路由器、防火墙等网络设备必需的关键性基本技术. IP报文分类算法的优劣直接影响到网络区分服务、基于策略的路由、虚拟专用网、QoS、流量计费等网络服务的性能. 随着Internet应用的不断扩展,网络速率不断提升,出现了许多新型的网络应用,许多新应用对网络区分服务与性能也提出更高的要求. IP报文分类技术也随之成为网络研究的一个热点. 经研究,目前已经提出了多种IP数据包快速分类算法.
1 常见报文分类算法及分析
目前常见IP报文分类算法可分成5类:基于基本树结构的分类算法、基于几何算法的分类算法、启发式分类算法、哈希分类算法、基于硬件的分类算法. 为了方便说明各算法的工作机制,构造了一个规则表,每条规则由二个域组成,每个域的长度为4位,如表1所示.
1.1 基于树结构的报文分类算法
基于树结构的报文分类算法主要有:一维树结构算法、分层查找树算法[1]、集合归并查找树算法[2]、网格查找树算法[2-4]等. 它们的主要特点是通过构造一级或多级Tries树,并用Tries树特性进行算法优化.
一维树结构(Radix Tree)算法 它的左分支标为‘0’,右分支标为‘1’,结点表示从根到该结点路径的位串.前缀为p的规则存储在路径为p的结点中,例如前缀为0*的规则存储在根结点的左孩子中.
分层查找树算法(Hierarchical Tries) 它是一维树结构的改进,先对第一个域按一维树结构构造一棵树,然后对于有规则的结点,对于其上的规则按一维树的方式构造第二个域的树. 每维分类均排列为按比特的搜索树,并将树相互连接,算法维数一般不超过2.
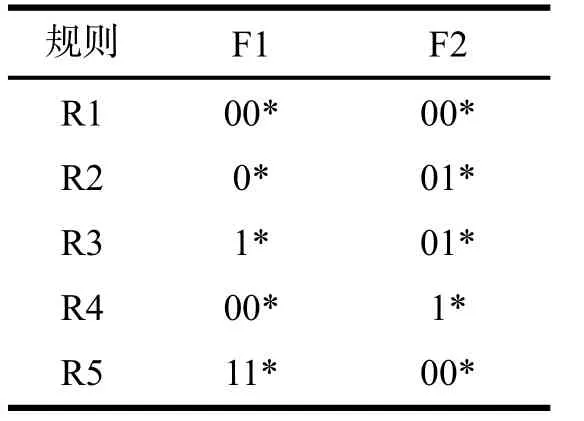
表1 二维分类规则
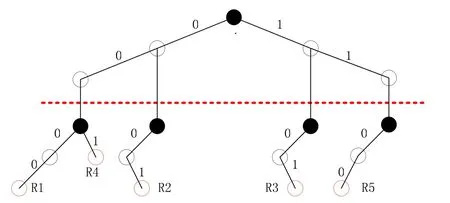
图1 对应于表1的分层查找树
在图1中,虚线以上是F1,虚线以下是F2. 时间复杂度为W,空间复杂度为ndW. 其优点是简单、实现容易;缺点是查找、更新较慢,规则数少,有回溯查找. 例如:对包(1100,0100)而言,有二条搜索路径,其中一条在F2域通向R5节点的路径不通,因此会退回到分叉的节点处,然后沿另一条路径搜索,最后找到规则R3.
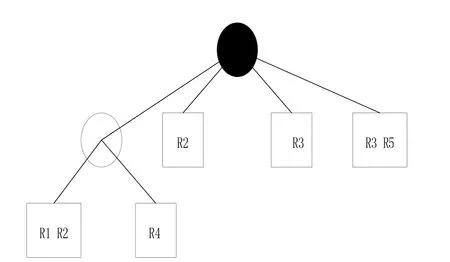
集合归并查找树算法(Set-Pruning tries) 它是对Hierarchical Tries的改进,通过复制部分树,可以不回溯搜索,此算法维数一般不超过2,规则数可以比较多. 这种方法是以增大存储空间来减少查找时间. 时间复杂度为dW,空间复杂度为nd,
上面图1经过复制后,结果则成为图2所示的结构. 其中R3是复制的.
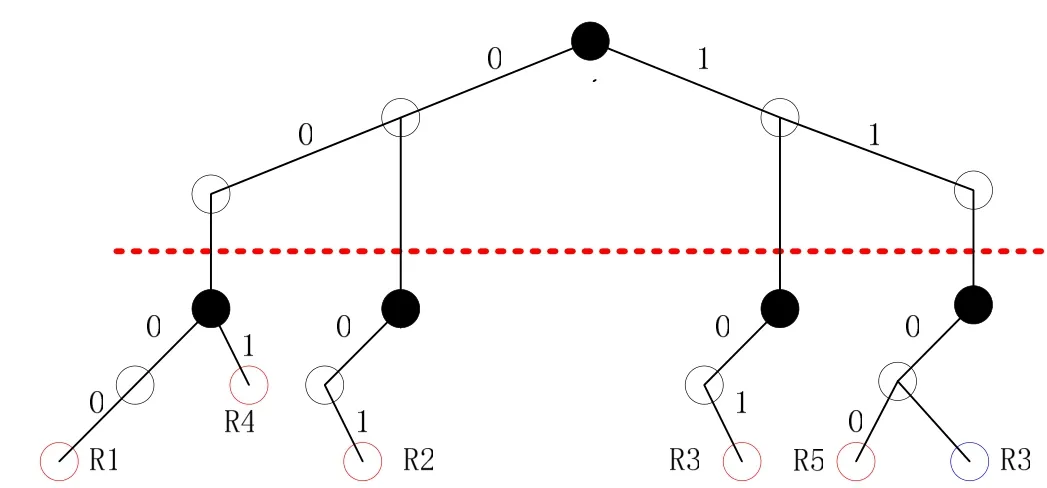
图2 对应于表1的集合归并查找树
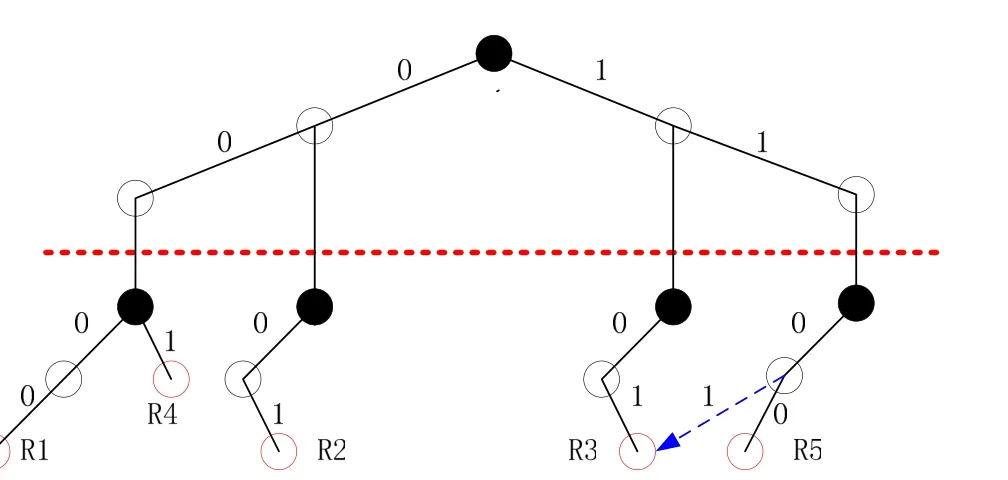
图3 对应于表1的网络查找树
网格查找树算法(Grid-of-Tries) 如图 3所示,该算法由华盛顿大学的 Srinivasan等提出,通过改进Set-Pruning tries算法,删除集合剪枝树中复制的子树,而保留被复制的子树,在被删子树的父结点中增加一个标有‘0’或‘1’的转移指针,用于指向保留的子树. 将复制功能通过指针实现,节约了空间. 具体的算法参见文献[5]. 这种算法既解决了回溯查找的问题,又解决了集合归并树的空间增长问题. 目前在VPN和多播转发中应用较为广泛. 空间复杂度为Wd-1,时间复杂度为ndW. 但是规则动态更新效率差,特别是引入转向指针后使得快速插入和删除过滤规则变得更加困难.
该算法虽然通过构造多维空间的层次 tries,也可使用于多维分类,但是要牺牲时间和空间复杂度. 所以该算法常只用于二维分类.
1.2 基于几何空间的报文分类算法
基于几何算法的报文分类算法主要有:Cross-Producting算法[6]、AQT算法[7]、FIS算法[7]等. 它们的主要特点是针对规则的前缀分布,按照0l序列的排列不同,将规则分为不同的等价类.
交叉乘积算法(Cross-Producting) 它是一种适合任意维数的流分类算法,其主要思想是将d维分解成d个一维的查找,并将分解的结果通过交叉相乘的方法建立一张查找表. 从算法的空间复杂度可知,Cross-Produeting算法只适合于小规则集的场合. 此外,Cross-Produeting是一个静态算法,因为每更新一条规则,其范围集都会发生变化,从而导致每次更新都必须重建交叉乘积表. 该算法的时间复杂度为O(dW),空间复杂度为O(Nd).
AQT算法 该算法由贝尔实验室的Buddhikot和华盛顿大学的Suri等提出,使用过滤器和数据包查找空间定位的原理,将查找空间作为整个四叉树的根节点.并对空间进行递归划分,得到四个方向的子空间,作为根节点的四个子节点,直到找到匹配过滤器的最小正方形(二维情况中). 在建立四叉树的过程中引入了过滤器集、相交过滤器集的概念,并使用面积比较,这就使得算法实现较为复杂.后来提出利用空间定位代码来构造四叉树的方法,使得实现与查找变得简便. 此算法具有O(N)的空间复杂度,最坏情况下有O(aW)的时间复杂度. 此算法只适用于二维情况.
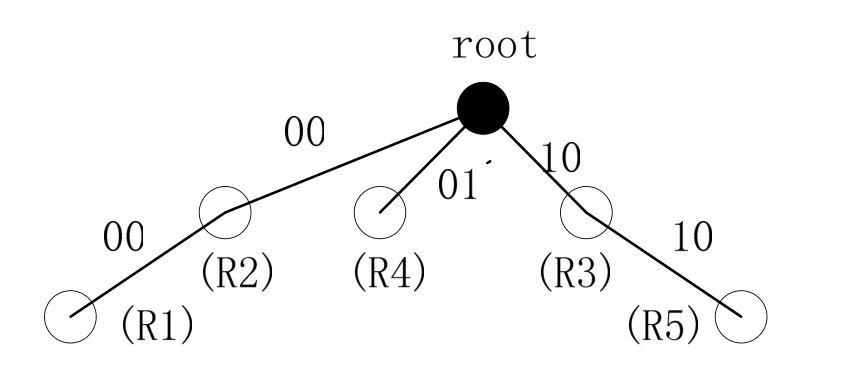
图4 对应于表1的AQT算法的查找树
FIS算法 贝尔实验室的Feldman和Muthukrishman提出该算法,通过改进SegmentTree(利用规则之间的覆盖关系构造Fat Incest Segment tree),允许通过调整树的层数 L,牺牲空间来换取较快的匹配速度. 其时间复杂度为O((L+1)W),空间复杂度为O(L*NL+1/L). 该算法一般用于二维分类,其时间复杂度和空间复杂度与树的层数相关,并随规则数目的增加而增长.
1.3 启发式报文分类算法
基于启发的IP数据包分类算法有RFC算法[8]、HiCuts算法[9]等. 它们的主要特点是利用规则的某些特性来构造查找数据结构,从而形成查找入口,加快查找速度.
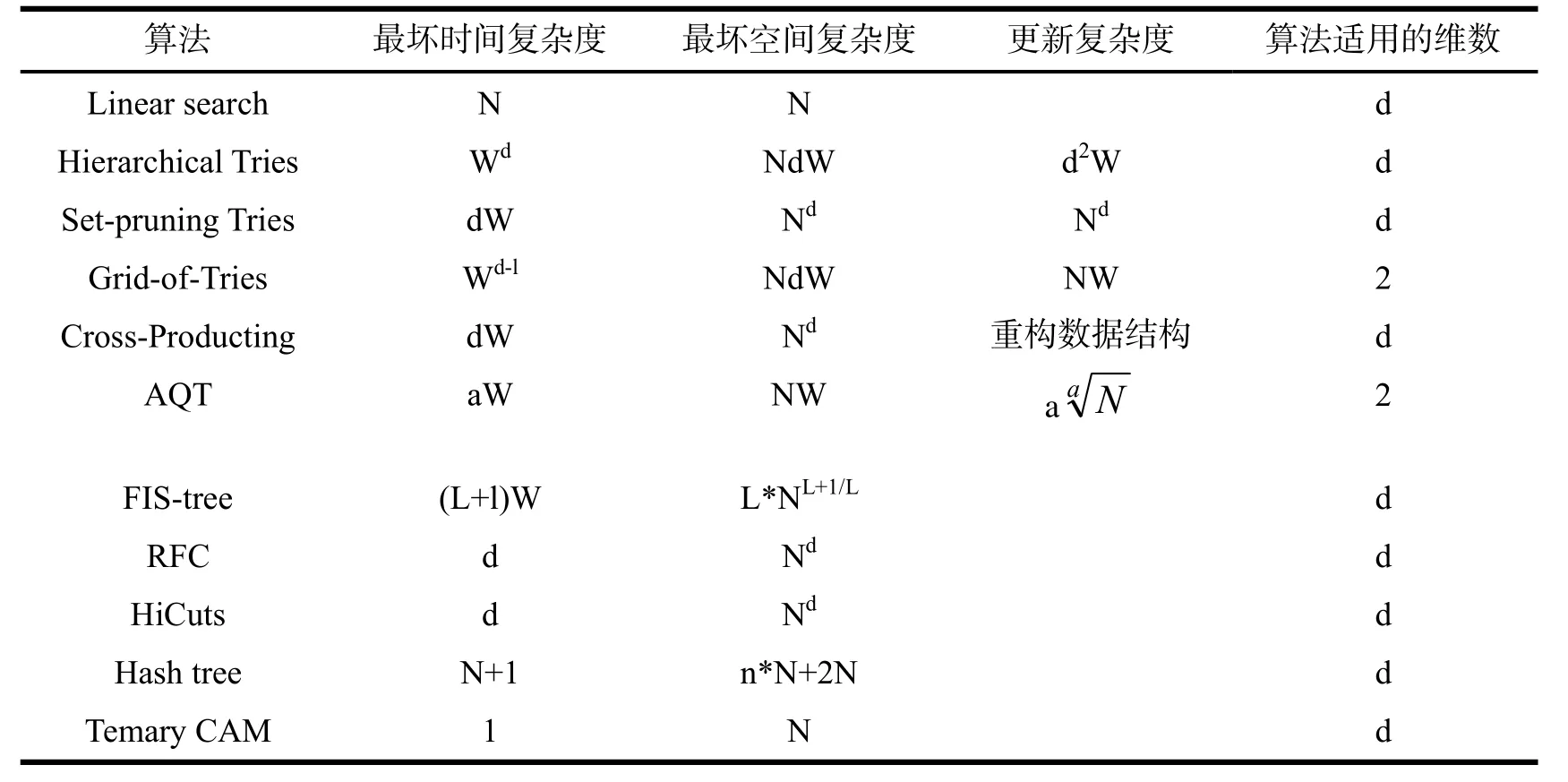
RFC(Recursive Flow Classification,递归流分类)算法 其主要思想是把报文分类问题视作报文头的S位到T位的classID之间的一个映射,T=logN 且T< RFC算法是一种速度较快的常用分类算法 它对一个报文的分类分为多个阶段实现,充分利用硬件流水线技术,具有很高的吞吐量;主要缺点是存储需求大,不能用于大型数据库,不支持过滤规则的快速动态更新,预处理时间较长. 智能层次切分算法(Hierarchical Intelligent Cuttings) HiCuts是1999年由斯坦福大学的Pankaj Gupta博士和Nick McKeown教授提出的一种灵活的报文分类算法,基本思想是以每个报头域为一个层次,将报文空间逐层等距分组,生成报文分类决策树. 当报文到达时,遍历决策树找到一个与之匹配的存储少量规则的叶结点,再使用线性查找算法,找到最佳匹配. 图5 对应于表1的空间切分 图6 对应于表1的Hicuts树 HiCuts算法在规则表达能力、分类速度和空间占用上与其它算法相比具有明显的优势,但是在某些情况下会出现空间膨胀与树的平衡问题. 文献[10]针对上面的问题提出了改进的方法. 1.4 哈希报文分类算法 针对报文分类的哈希分类算法(Hash算法)可以分为冲突哈希报文分类算法和无冲突哈希报文分类算法二类. 常用的有冲突的Hash算法用于多维IP包分类,由于规则的比特数很长,所以要将大量规则映射到一个较小的空间,冲突率非常高,从而导致查找和更新时间不确定,影响了算法的性能. 无冲突哈希查找算法的基本思想是将多维分类算法转化为二维分类算法,基于源/目的端口和协议三域交叉组合情况较少,利用这三个域构造无冲突函数,而对于IP地址部分仍采用其他分类方法. 因此,无冲突Hash算法一般作为多维IP包分类算法中的一部分,不是完整意义上的Hash算法,无法完全具备Hash算法的优点,算法预处理过程复杂、对内存需求较大、支持的匹配规则集有限. 文献[11]中提出的一种哈希树的分类算法,时间复杂度为O(n+1),空间复杂度为O(n*N+2N). 1.5 基于硬件的报文分类算法 基于硬件的算法,具有最快的分类时间,但需要增加一个容量为dNW(w为每一维的长度)的TCAM存储器,由于这种存储器价格高,耗电量大,不能直接支持范围匹配,因而对规则数量、规则维数和每维宽度的可扩展性均较差,只能用于较小的数据包分类问题. 上述各IP综合算法的综合比较如表2所示. 表2 各类IP算法性能综合比较 IP报文分类算法的性能主要受处理速度、存储空间、规则维数(d)、长度(W)、更新难度、可扩展性和移植性等因素影响,每一种算法往往只能在某一方面具有优势. 随着网络带宽的增加和用户对网络服务多样性需求的增长,对 IP报文分类算法也必将提出新的要求:IP报文分类算法能提供更高的分类速率;IP报文分类算法尽量不受或少受规则个数N、维数d和匹配长度W等参数影响;更好的可扩展性和移植性. [1] GUPTA P, MCKEOWN N. Algorithms for packet classification[J]. IEEE Network Special Issue, 2001, 15(2): 24-32. [2] SRINIVASAN V, VARGHESE G, SURI S, et al. Fast and scalable: ayer four switching[C]//Proc. of ACM SIGCOMM. Vancouver:[s.n.],1998. [3] 张 李, 涂晓东, 何 诚. 流分类技术研究[J]. 电子科技大学学报, 2004, 33 (6): 678-681. [4] 单 征, 赵荣彩, 张 铮. 报文分类算法研究[J]. 计算机工程与应用, 2005(7): 149-152. [5] 孙 毅, 刘 彤, 蔡一兵, 等. 报文分类算法研究[J]. 计算机应用研究, 2007, 24 (4): 5-11. [6] 叶满谷. 基于FPGA的高速流分类算法研究[D]. 西安: 西安电子科技大学硕士论文, 2008. [7] 张庆宏. 高性能包分类算法研究[D]. 西安: 西安电子科技大学硕士论文, 2008. [8] GUPTA P, MCKEOWN N. Packet classification on multiple fields[C]//proc. of ACM SIGCOMM. Cambridge:[s.n.],1999. [9] GUPTA P, MCKEOWN N. Packet classification using hierarchical Intelligent cuttings[J]. IEEE Micro, 2000, 20(1): 34-41. [10] 龚 俭, 魏 薇, 周 鹏. 适用于GIDS报文分类的P-HiCuts算法[J]. 哈尔滨工业大学学报, 2008, 40(3): 448-452. [11] 殷 科, 邓亚平, 唐 红. 基于Hash_tree的多维IP包分类算法[J]. 计算机工程与应用, 2005(32): 123-125. Research on IP Packet Classification Algorithm LI Xue-feng According to their implementation features, this paper divided IP packet classification algorithms usually used into different types and described them one by one in detail. It also gives the time complexity, space complexity, update complexity of the algorithms. It summarized the advantages, disadvantages as well as suitable application environments of different kinds of packet classification algorithms and prospected the future research issues on packet classification problem. IP packet classification; Time complexity; Space complexity; Update complexity TP393 A 1009-2854(2010)08-0038-04 2010-07-02 李学锋(1968— ),男,湖北随州人,襄樊学院数学与计算机科学学院讲师. 陈 丹)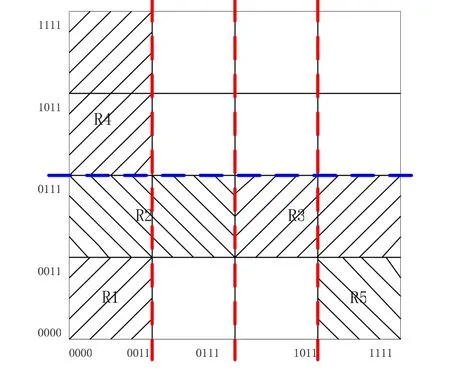
2 各类IP分类算法性能综合比较
3 总结与展望
(School of Mathematical and Computer Sciences, Xinagfan University, Xinagfan 441053, China)
