体育科研中定性数据的统计分析问题辨析
2010-09-06魏登云杨亚莉
魏登云,杨亚莉
体育科研中定性数据的统计分析问题辨析
魏登云,杨亚莉
针对定性数据的特殊性和应用中存在的困难,从总体和样本、抽样方式以及遗漏变量等方面讨论影响统计分析的因素,用直观的语言和手段阐述定性数据统计分析的思想,提出明确总体的两个重要因素——目标属性和附加属性,强调应用中值得注意的问题。
定性数据;定性变量;列联表;总体;样本;目标属性;附加属性
1 前言
定性数据在体育领域经常遇到,定性数据的特殊性不仅导致处理方法的特殊,而且在课题设计、数据来源、统计处理、信息反馈等各个环节都存在一定的难度。表面上看,数据的形式很简单(通常都被整理成列联表),但内在的情况却可能相当复杂。有时我们自以为提取的信息已经很明确了,但其实还有很多的不确定因素。有时候我们可能满怀信心地对某个处理结果下结论,但实际上真正的结论可能恰恰相反。原因可能出自数据的处理方法本身,但多数情况是错误的真正原因来自列联表之外。
已有不少文献对定性数据的统计处理进行探讨。概括起来可以分为两大类:一类,是运用统计方法解决一些具体问题,文献较多,涉及的领域也较广,这里不再赘述;另一类,是针对实际应用中已经或可能出现的困难,探讨如何运用的问题,这类文献不多,具代表性的有:吴嘉之[12]针对问卷调查数据分析中存在的问题,通过对二维列联表的分析来寻找相关的变量,提出对每一个问卷调查数据都应该进行探索性分析;冯士雍[4]针对列联表中类的归并,提出值得注意的问题;陆运清[8]讨论了用Pearson’s卡方统计量进行统计检验时应注意的问题,认为卡方数值的大小与样本容量有关,在卡方检验中需要报告关联系数,并且在实际应用中还需注意卡方检验的条件;高辉[5]就定性资料统计分析方法的合理选用问题,提出“正确识别、表达定性资料,切勿随意对高维列联表进行切割或压缩”等观点;胡良平[7]针对医学论文中常见的统计分析错误,提出合理选用定性资料统计分析方法应注意的问题。以上研究大多是基于已有的列联表,即在列联表之内讨论定性资料的统计处理方法。我们考虑,影响定性数据统计分析质量的因素很多,其中大部分在列联表之外。如果把“对列联表的定量分析”看作是一个系统的话,那么在这个系统之外,有很多因素对系统运行的效果起决定作用。更为重要的是,系统之外的影响因素极具隐蔽性,应用中很容易被忽视,如果我们跳出这个系统,从基于研究目的的顶层设计开始,审视各个环节,将有利于发现问题,实际应用中也便于明确目标,理清思路。
本研究拟从定性数据统计分析的原点出发,探讨各个环节可能遇到的问题,提出值得注意的地方,供应用者参考。
2 关于定性数据的总体与样本
众所周知,总体和样本是最重要的统计基本概念,明确总体也是统计应用的关键[9]。有关定性数据的总体和样本在一般教科书中很少具体给出,殊不知,定性数据的总体与样本事关课题设计,加之定性数据的特殊性,明确总体和样本显得格外重要。
2.1 总体与个体
涉及定性数据的研究目的,归根结蒂是描述定性变量的分布特征或推断定性变量之间的关系①定性变量包括分类变量和有序变量2种。有序变量较分类变量信息丰富一些,除了定量处理的某些具体细节方面有所不同外,有序变量与分类变量在研究思路上大致是相同的,不失一般性,本研究仅限于分类变量。。总体是变量的研究载体,从理论层面看,总体就是变量本身(随机变量)。
例1:考虑射击、跳水、足球3个项目运动员的个性心理特征有无区别,实际上是考虑2个定性变量“项目(X)”和“个性心理特征(Y)”之间的关系,X可取3个不同的值a1、a2和a3,分别代表3个不同项目,Y取4个不同值(b1, b2,b3,b4)代表4种不同的个性心理特征(多血质,胆汁质,粘液质,抑郁质),那么,总体是由变量X与Y构成的随机向量(X,Y)′。总体的分布指随机向量的概率分布P(X= ai,Y=bj)=pij,i=1,2,3;j=1,2,3,4。
从应用层面看,总体是由个体组成,个体是带有特定属性的研究对象,针对上述例子,个体是带有“项目”和“个性心理特征”两种属性的运动员,如果用变量取值代表属性的话,个体即是一对数值(ai,bj)′。例如(a1,b3)′代表从事射击项目并具有粘液质的一个个体。总体是具有以上两种属性的所有运动员的全体,即形如(ai,bj)′的向量的全体。
2.2 样本的形式与列联表的形成
样本由来自总体的若干个个体组成,在例1中,个体是形如(ai,bj)′的一个向量,如果按某种抽样方式抽取n个运动员,同时,测量每个运动员的“项目”和“个性心理特征”两种属性,则样本是n个形如(ai,bj)′的向量构成的集合,其中ai和bj分别代表两种属性的观测值。由此得到的样本数据称为定性数据,定性数据不能进行数值运算,因为ai和bj只代表不同的属性,不具有其他任何信息。
注意到,在n个数据向量中有很多是相同的。比如n11个(a1,b1)′,n12个(a1,b2)′,…,nij个(ai,bj)′,…,n34个(a3,b4)′等,为了数据陈列方便,在不损失任何数据信息的前提下,将其整理成列联表的形式(表1)。

表1 列联一览表
表1中nij是属性观测值为(ai,bj)′的频数,属于定量数据,可以进行数值运算,而且在随机样本的视角下,nij均为随机变量,所以,对定性数据的统计处理往往是基于列联表,针对其中的频数进行的,这是定性数据与定量数据在统计处理上的最本质不同之处。
3 总体的内容对统计分析的影响
定性数据的统计处理是针对频数进行的,频数是属性相同的个体数。因此,个体的属性在统计分析中是要始终明确的。个体的属性反映了总体的内容,统计总体有2个要素,即总体的内容和范围,其中总体的内容起决定作用。实际运用中,明确总体实质上就是明确总体的内容,总体的内容体现在个体上。在定性数据的统计分析中,总体的内容是课题所要考虑的所有属性,其中有些是课题研究的目的所在,而且明确反映在列联表中,称之为目标属性。例1中的“项目”和“个体心理特征”就是目标属性;另外一些是课题研究中根据研究目的所选择、约定或控制的属性,在列联表中往往不能明确反映,称之为附加属性。例1中如果仅仅是针对男性优秀运动员,那么“男性”和“优秀运动员”就是附加属性。附加属性是被控制的属性,每个个体都具有相同的附加属性,所以,在列联表中往往没有明确反映,在统计分析中容易被忽视。
目标属性和附加属性对统计分析均有不同程度的影响,我们先考虑目标属性。
3.1 变量之间的关系与变量的分类有关
作为定性分析的主要目的,考察定性变量之间的关系,实质上是研究几种目标属性之间的关系,各个属性的划分(变量的分类)对统计结果有直接的影响。看一个例子。
例2:考虑甲、乙两支排球队在某次大赛中得分构成比是否有显著差异。
很显然,队别(X)和得分手段(Y)是2个分类变量,队别变量X的分类是固定的,但得分手段变量的分类却有多种。我们列举几种于表2。不同的分类体现了不同的研究目的,分类不同,结论可能不同。比如,按第1种分类,甲、乙两队的得分构成比有差异,而按第3种分类,得分构成比可能没有差异。也就是说,按第1种分类,队别变量与得分手段变量是关联的,而按第3种分类,2个变量之间可能是独立的。
注意到,表2中第1、2两种分类较细,第3、4两种分类较粗,并且第4种分类是不完备的,这就意味着研究目的在于比较甲、乙两队“发球、扣球和拦网”3方面得分的构成比,如果检验结果不显著,说明队别变量与得分手段变量之间关联不显著,这时需要注意“得分手段变量”只有3类。
一个有趣的问题是:例2中的总体和个体分别是什么?甲、乙两队所得的每1分都有两种明确的属性,即“队别”和“得分手段”,带有这两种属性的每1分均为一个个体。属性变量“得分手段Y”如果按表2中第4种分类,则Y可取3个不同的分类值b1、b2和b3,队别X可取2个分类值a1和a2,两队所得的每1分将对应一个属性观测值向量(ai,bj)′,称为一个个体。总体是具有这两种属性的所有个体的全体。这两种属性明确了总体的内容,也界定了总体的范围。例如,按表2中第4种分类,因“对方失误”得的分,就不在总体范围内。

表2 得分手段变量分类一览表
3.2 附加属性对统计结果的影响
一般来说,定性数据中附加属性总是有的,例2中“队别”和“得分手段”是目标属性,与此同时,“比赛级别”和“得分”就是附加属性。如果研究者考虑两队的“失分”情况,那么,附加属性就由“得分”变为“失分”了。
附加属性在列联表中有时很难反映出来,看一个具体的例子。
例3:在一项被告人种族与被害人种族关系的研究中,分别调查了被告人320人,被害人400人,数据列于表3和表4。
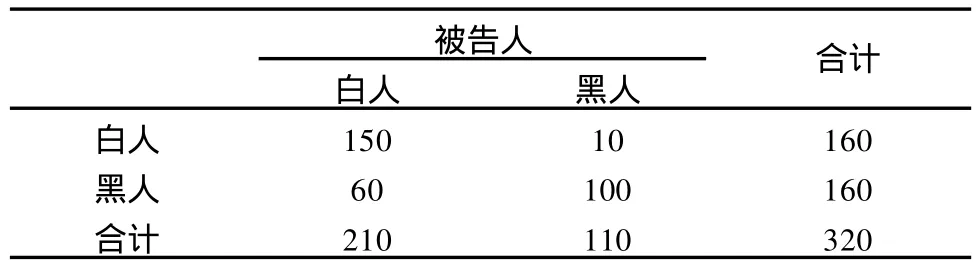
表3 被告人数据列联一览表
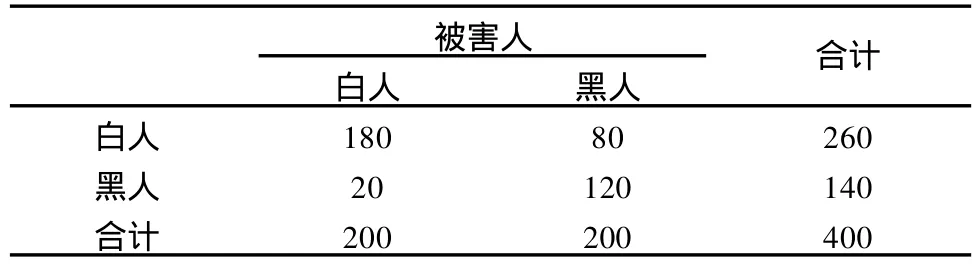
表4 被害人数据列联一览表
两张表都反映被告人种族与被害人种族之间的关系,目标属性一样,但附加属性不同,表3中附加属性是“被告”,表明320个被告中,有210人伤害了白人,110人伤害了黑人。表4中附加属性是“被害人”,表示400个被害人中有200人被白人所害,200人被黑人所害。
在定性数据的统计分析中,附加属性是在课题设计时就应该明确的。明确了个体的属性,也就明确了总体的内容,从而界定了总体的范围,不仅在抽样时能保证附加属性相同(即资料的同质性),而且能使我们对统计结果的解释具有针对性。举一个例子。
例4:表5是参加体操、排球和田径三个项目运动损伤人数的列联表,“性别”和“项目”是两个目标属性,“损伤”是其中一个附加属性。统计检验的结果是“关联”显著,说明在不同项目上,男女受伤比例有区别,这是否意味着某个项目男性更容易受伤,而对另一个项目女性更易受伤?不能轻易下结论。事实上,如果参加各个项目运动的男女比例有区别,那么参加运动人次多的项目受伤人次自然也多。本例中的附加属性将总体的范围缩小至“受伤人群”,不能说明更多的问题。
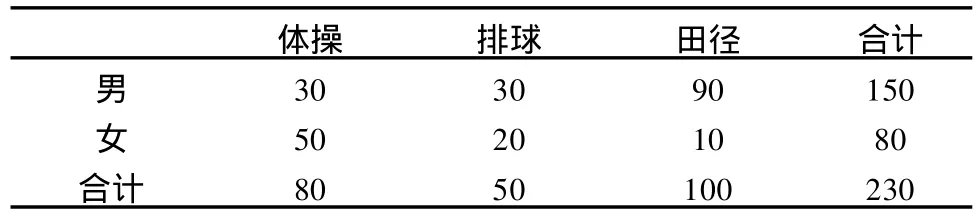
表5 损伤人数列联一览表
4 抽样方式的选择
在定性数据的统计分析中,总体中的个体都有目标属性和附加属性,附加属性是控制属性,每个个体都具有相同的附加属性。收集样本应在附加属性限定范围内。目标属性是课题研究的目的所在,表现为定性变量。按定性变量的具体分类,总体被划分为若干部分,类似于列联表中的单元格,称之为总体单元格,每个单元格内个体的属性相同,各单元格内的个体数共同反映了总体的分布。列联表是在总体划分的模式下样本的一种陈列形式,是对样本内所有个体的划分。所以,从样本信息反映总体信息的需要来看,应采用完全随机的抽样方式获得样本,即先不管总体是如何划分的,从所有个体中随机抽取一部分,按个体属性放入列联表相应的单元格中。这种抽样方式是最理想的,对几乎所有的研究目的和统计模型都适合,称之为随机抽样。但在实际工作中,资料来源多种多样,数据的收集受历史的、客观条件限制,有时难以做到随机抽样,很多情况下,资料的收集可视为分类抽样,即按某一个定性变量将总体划分为几大块,在每一块中随机抽取一定数量的个体,然后根据个体的具体属性放入列联表。
分类抽样对数据分析最直接的影响就是歪曲了相应的分类变量在总体中的边际概率分布事实,所以,如果研究目的是描述总体中各定性变量的概率分布,那么采用分类抽样是不妥的。但如果研究目的是分析定性变量之间的关系,分类抽样是可以的。理论上已经证明:基于随机抽样所得到的变性变量之间的独立性检验方法,对分类抽样同样适用[1]。
一般来说,在以下几种情况下,可以或不得不采用分类抽样:第一,一个定性变量已经明确分类,研究目的是讨论其他变量的条件分布,例如,比较甲、乙、丙三支排球队的得分构成比有无显著差异,队别变量分类明确,得分构成比的比较实际上是比较“得分手段”变量在三支球队中的条件分布,这时各支球队的总分多少对研究目的没有影响。第二,研究目的已经显示,自变量和因变量很明确,考虑自变量对因变量的影响。例如logistic回归模型。第三,总体结构特殊,具有某种属性的个体数很少,例如,比较残疾人运动员与正常运动员的意志品质,残疾人运动员人数相对较少,调查时需要分类抽样。
5 遗漏变量对数据分析的影响
实际工作中,变量之间关系错综复杂,相互影响,2个变量之间的关系可能受第3个变量的很大影响,也就是说,如果忽视第3个变量,那么,我们得出的2个变量之间的关系可能是虚假的。忽视某个或某几个变量的现象,我们称之为变量遗漏。遗漏变量对定量数据统计分析的影响在文献[10]中有过探讨。然而,对于定性数据分析,遗漏变量造成的影响更大,而且更具有隐蔽性,可能会得出完全相反的结论。我们从2个方面指出遗漏变量对定性数据分析的危害。
5.1 掩盖变量之间的关联性
为了很好地说明这一现象,我们不妨借用社会领域的一个典型的例子(数据来源于文献[9])。
例5:调查1976—1977年佛罗里达州20个地区杀人案件中326个被告,数据列于表6。问法院判处死刑是否与被告种族有关?
通过简单的统计推断就可以得出结论:是否判死刑与被告种族无关。可是如果同时考虑被害人种族,情况就不一样了。数据见表7。
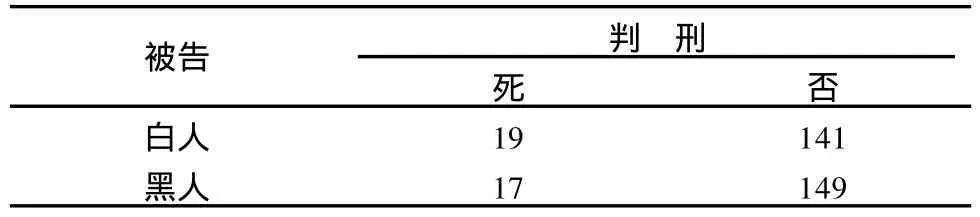
表6 被告肤色与判刑分类一览表

表7 被告种族、被害者种族与死刑判决数据一览表
运用对数线性模型[13]推断出3个定性变量之间的关系是:被害人种族与被告人种族、死刑判决都有关,而且给定被害者种族时,被告种族与死刑判决无关。可以发现,被告种族与死刑判决2个定性变量有内在关联,只是因为同种族自相残杀较多,掩盖了事实真相。这就说明:忽视了“被害者种族”这个变量,得出的结论恰恰相反。
5.2 因果关系的误导
与上节的情况相反,有时候从数据上看2个定性变量之间有关联,实际上是第3个变量在起作用,2个定性变量之间却毫无关系。借用文献[15]中的一个数据例子。
例6:考虑性别与投票倾向之间的关系,数据见表8。
作卡方检验,结果显示:性别与投票之间有关联。这是否意味着男性赞成共和党,而女性更亲睐民主党呢?如果把经济收入状况考虑进来,分别统计低收入和高收入人群的“性别—投票”数据,得到表9和表10。

表8 性别与投票数据列联一览表

表9 低收入人群性别—投票列联一览表表
对表9和表10做统计检验,结果都表明:性别与投票之间独立。说明性别变量并不影响投票变量,倒是经济收入与性别和投票都有关联。表8中遗漏了一个重要变量——收入状况,导致虚假的因果关系。
由例5和例6不难看出,分析定性变量之间关系,如果遗漏了重要变量,结果是很危险的。实际应用中,多变量问题应尽量使用多维列联表,有时为了降维合并列联表,也要先检验被合并的变量与其他变量的关系,独立时方可合并。
6 小结
定性数据(尤其是分类数据)是各种数据资料中比较特殊的一类,适用面相当广,几乎所有的专业领域都有,尤其在社会科学领域普遍存在。与定量数据相比,定性数据统计的是带有特定属性的个体的频数,其中的测量工作表现为对研究对象属性的认定。因此,明确个体的属性是确定研究总体的关键,不仅指导着数据资料的收集与整理,而且,影响统计方法的运用,甚至对统计结果的解释和应用也起决定作用。属性的确定,看似简单,实则事关全局,变化多样,任何一个附加属性,实质上都是某个定性变量的一个类,实际应用中同时考虑这个变量的其他类通常是必要的,因为有时变量在暗中起作用,研究者起初是不知晓的。
从具体的定量处理方法角度看,定性数据统计分析面临的问题还比较多,尽管目前对数线性模型、logistic回归模型以及多元分析方法已使定性数据的统计处理跃上了一个高的平台,然后很多具体问题仍在探讨之中。从实际工作者的角度看,统计分析的直观思想永远是第一位的,那么统计运用的起点——总体和样本是最不容忽视的,思想的产生,方法的创新,都源于此。
[1]陈希孺.概率论与数理统计[M].合肥:中国科技大学出版社, 2002.
[2]陈雪东.列联表分析及在spss中的实现[J].数理统计与管理, 2002,(1):51-54.
[3]邓正林.问卷调查中定性数据分析方法及其应用[J].江苏统计, 2002,(12):70-74.
[4]冯士雍.属性统计与列联表分析(Ⅰ)[J].统计研究,1985,2(3): 41-47.
[5]高辉,胡良平,李长平,等.如何正确处理定性资料(二)[J].中西医结合学报,2008,17(11):21-29.
[6]郭大伟.定性数据的统计处理[J].安徽体育科技,1993,14(3): 28-31.
[7]胡良平.医学研究论文中常见统计学错误分析(6)定性资料统计分析错误辨析与释疑[J].基础医学与临床,2007,(12):81-85.
[8]陆运清.用Pearson’s卡方统计量进行统计检验时应注意的问题[J].统计与决策,2009,(15):21-24.
[9]魏登云.提高体育统计应用水平的关键——正确认识统计总体[J].体育科学,1997,17(2):87-91.
[10]魏登云.主成分与因子分析在体育综合评价中的应用监测[J].体育科学,2003,23(4):48-51.
[11]魏捷.关于调查定性数据处理产生的探讨[J].统计与决策, 2008,(20):19-24.
[12]吴喜之,骆鹏,罗玉波.从问卷调查数据中可以得到什么?[J].统计研究,2004,21(8):91-95.
[13]张尧庭.定性资料的统计分析[M].桂林:广西师范大学出版社,1991.
[14]朱建平.数据挖掘中属性项压缩的统计方法研究[J].统计与信息论坛,2006,(5):61-64.
[15]GUDMUND R IVERSEN,MARY GERGEN.统计学[M].北京:高等教育出版社,2002.
The Debate of Statistical Analysis on Qualitative Data in Research of Sports Science
WEI Deng-yun,YANG Ya-li
For the specificity of the qualitative data and the difficulties in application,this paper tries to discuss the factors that affect the statistical analysis from the population and sample, sampling,and missing variables,etc.Using simple and clear language and means,the author elaborates the idea of statistical analysis of qualitative data.It is put forward that there are two important factors,target attribute and additional attribute,in population.In the same time, some noteworthy issues are emphasized in application.
qualitative data;qualitative variables;contingency table;population sample;target attribute;additional attribute
G80-32 文献标识码:A
1000-677X(2010)06-0092-05
2010-03-26;
2010-04-15
安徽省高校省级自然科学基金重点项目(KJ2007A-120ZC);中国体育科学学会体育科技项目(2006TJ20)。
魏登云(1963-),男,安徽肥东人,教授,硕士,研究方向为体育计量学,Tel:(0553)5910706,E-mail:dywei191@ vip.sina.com;杨亚莉(1983-),女,安徽旌德人,硕士,研究方向为体育计量学,E-mail:lucyxiaoyang@126.com。
安徽师范大学体育学院,安徽芜湖241003 Institute of Sport Science,Anhui Normal University, Wuhu 241003,China.
