基于遗传算法的中国股市波动性研究
2010-08-14□文/吴蕾
□文/吴 蕾
股票市场是现代市场体系的有机组成部分,也是现代金融市场中最有活力的增长点。我国的股票市场起步较晚,市场制度尚不完善,从而使得股票市场的发展起伏较大。随着市场经济的日趋成熟,股票市场的进一步开放和交易品种的不断丰富,对新形势下的股票市场发展的内在规律和实践进行深入的研究是非常有必要的。
近年来的很多实证研究表明,经济、金融系统中的时间序列大多具有非线形性,也就是说这些时间序列具有长期的记忆性。表现在波动性上的长期记忆型又称持续性。由于波动性不仅是资产风险的决定因素,而且还是衍生证券定价中的一个关键参数,因此很好地理解金融时间序列的波动性具有重要意义。
国外对股票市场价格的波动特征已经进行了大量的实证研究,其中最成功的模拟方差随时间变化的模型是由Engle(1982)首先提出的自回归条件异方差模型,即ARCH模型。ARCH模型实际上是对时间序列动态模型的推广,它将方差和条件方差区分开来,并且定义条件方差是过去误差的函数,为解决异方差问题提供了新的途径。然而,在实际应用中,当ARCH模型的阶数过大时,参数的估计则不再精确;除此之外,为了保证方差为正,还要求参数值为正,当参数过多时,实际数据的估计模型往往不能满足这一点,因此,Bollerslev(1986)在此基础上提出了广义自回归条件异方差(GARCH)模型。大量实验表明,金融数据扰动项异方差具有极大的持续性,这些现象促使Engle和Bollerslev(1986)提出了 IGARCH(q)模型,给出了单位根的许多特性。Bollerslev等人近期经过研究又提出了FIGARCH(p,d,q)模型,这种方法的目的就在于可以对模型方差灵活定阶,可以更好地解释金融市场的波动性。目前,ARCH模型和GARCH模型已经被广泛应用于股票市场、货币市场、外汇市场、期货市场的研究中,来描述股票价格、利率、汇率、期货价格等金融时间序列的波动性特征。Bollerslev等对美国标准普尔500复合指数进行FIGARCH建模研究,得到差分阶数d=0.447,显著不同于0和1,表明美国股市从波动性上表现出长期的记忆性。我国学者李汉东、张世英和汤果、何晓群等人分别从理论方法上和实证分析上对FIGARCH模型进行了研究,结果表明了我国股市收益存在长期记忆性。
本文利用遗传算法对上证综合指数的波动建立 FIGARCH(p,d,q)模型,从条件方差上研究了中国股票市场的长期记忆性。本文第一部分介绍了FIGARCH模型;第二部分介绍了遗传算法以及应用遗传算法进行C语言编程的步骤;第三部分对上证综合指数进行FIGARCH建模;第四部分给出了简要的结论。
一、FIGARCH模型概述和参数估计
(一)模型概述
1、GARCH模型。ARCH模型介绍了条件方差的短期记忆性,GARCH模型是对ARCH模型的扩展,因此GARCH模型具有ARCH模型的特点,但GARCH模型的条件方差不仅仅是滞后残差平方项的线性函数,而且是滞后条件方差的线性函数,模型如下:
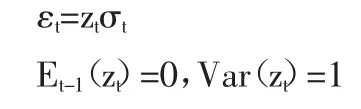
σ2t=Var是到 t时刻的信息集。

其中:ω为常数,L为推移算子。

GARCH(p,q)不仅反映了短期滞后,而且考虑到了长期滞后。而且研究表明,一般只需研究 GARCH(1,1)模型。
2、FIGARCH模型。FIGARCH模型是对GARCH模型的多项特征的整合和推广,是其更一般的情形,反映了金融时间序列的长期记忆性,模型如下:
令 v=ε2t-σ2t,代入(1)可得:

此时,vt是零均值不相关的时间序列。
当此时的特征多项式 1-α(L)-β(L)=0有一个单位根时,就得了Engle和Bollerslev(1986)提出的 IGARCH 模型。如同从 ARIMA(p,d,q)模型推广到 ARFIMA(p,d,q)模型来观察经济现象中的长期记忆性一样,很自然的考虑到从I-GARCH(p,q)到 FIGARCH(p,d,q)的推广:

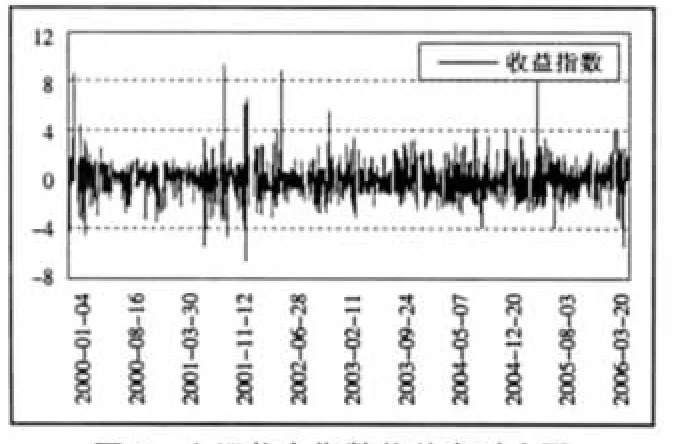
其中:0 显然,当 d=0 时,FIGARCH(p,d,q)模型就是 GARCH(p,q)模型;当 d=1 时,FIGARCH(p,d,q)模型就是 IGARCH(p,q)模型。 (二)参数估计 考虑一般的 FIGARCH(p,d,q): 常用的FIGARCH模型的参数估计方法是拟极大似然估计法(QMLE),FIGARCH(p,d,q)的似然函数如下: 其中 θ′=(ω,d,β1,β2,…,βp,φ1,φ2,…,φq),φk是 φ(L)的系数。 在对FIGARCH模型进行参数估计时,首先应该确定差分阶数d的值,常用的方法有四种:尝试法、GPH方法、周期图法以及重标极差方法(R/S分析法)。许多经济学家通过选取不同的d值进行尝试性的研究给出一个近似最优解,这种方法的计算过程是繁琐的,而且是不科学的。GPH方法是Geweke与Porder Hudak在1983年提出的一种最常见的估计阶数d值的半参数方法,它运用滤波理论,对谱密度对数的函数进行回归而得出d值。GPH方法意味着d可以通过一个简单的回归方程来估计得到,但当样本数足够大时,d的最小二乘估计才渐进服从正态分布,而实际中的样本量通常是有限的,尤其是起步较晚的我国股市,很难获得足够大的样本数。除此之外,这种方法所计算出的d值通常较小,不是明显异于0和1。周期图法是对加权的周期图量值最小化而求出d的估计值的一种方法,它是研究证券市场波动性的有效方法,能过滤大部分序列的相关因素,但不能完全剔除,而且由于没有考虑到宏观政策发布等因素,使得序列不相互独立。经典的R/S分析是通过计算赫斯特指数来计算d的一种方法,这种方法计算简单,但序列具有短期记忆和非平稳性。为了弥补这种方法的不足,Lo(1991)又提出了修正的R/S分析,目前已成为实证分析主要采用的方法,但这种方法所计算的d值通常较小。除此之外,王春峰和张庆翠对中国股市波动性的长期记忆性进行研究时,在OX统计语言环境下,应用G@RCH2.1软件包,经编程计算,也可以求解d,并且可以对所求的d值进行T统计量检验,这种方法是比较科学的,而且d值是显著异于0和1的。我国学者李颖和汤果在理论新探上还提出了BHHH算法和混合梯度算法,BHHH算法计算程序比较简单,但迭代次数较多,计算效果较差;混合梯度算法迭代次数少,收敛速度快,耗时较少,可以很大地提高计算效率。本文提出了对金融时间序列建立FIGARCH模型的一种新方法——遗传算法。 (一)遗传算法介绍。遗传算法简称GA,是1962年由美国Michigan大学的Holland教授提出的模拟自然界遗传机制和生物进化论而形成的一种并行随机搜索最优化的方法。他将物竞天择的生物进化原则引入优化参数形成的编码群体中,按所选择的适应函数并通过遗传中的复制、交叉和变异对个体进行筛选,使适应性强的个体得到保留,并组成下一代群体,新一代群体既继承了上一代的信息,又优于上一代。这样周而复始,群体中个体适应度不断提高,直到满足所给定的条件。遗传算法的主要特点是采用群体搜索策略和充分利用群体中个体间的信息交换,具有全局搜索、搜索空间维数较大等优点,尤其适用于处理传统搜索方法难于解决的复杂问题。其基本操作包括:复制、交叉和变异。 (二)C语言算法设计 1、理论说明。本文选取模型为FIARCH(1,d,1),如下所示: 其中:ω、β、φ都是未知参数。 按公式(4)取(1-L)d的 20阶泰勒展开式,将 FIGARCH(1,d,1)模型展成含参数的GARCH模型: 其中:a[i]含有未知参数 φ,i=0,1,2,…20。 由已知的时间序列{ε2t}按公式(6)可计算出{σ2t}的真实值。 由GARCH模型可知其一步预测为: 用上述{ε2t}的值根据公式(7)可计算出{σ2t}的预测值{}。 2、算法设计步骤 步骤1:外层循环 (1)给出下列参数的取值:种群大小(POP_SIZE)、交叉率(P_CROSSOVER)、变异率(P_MUTATION)、最大进化代数(GEN)。 其中:ρk为 βk的自相关函数,T 为 ρk的样本数,,R为βk的样本数。 由于Q~x(m),若选取的参数满足Q<x0.05(m),则说明{βk}是白噪声,即所建立的模型即消除了短期记忆性又消除了长期记忆性。 步骤2:内层循环——遗传算法(复制、交叉、变异) (1)初始化。在[0,1]之间随机选取POPSIZE个d值,组成向量d[POPSIZE],对每个 d[i](1≤i≤POPSIZE),再次使用遗传算法选择参数,具体做法如下: ①初始化。给出下列参数的取值:种群大小(POP_SIZE1)、交叉率(P_CROSSOVER1)、异率(P_MUTA -TION1)、最大进化代数(GEN1)。 选择适应函数为:L(θ)=-(T/2)log ②复制。随机选取三组POP_SIZE1个[0,1]之间的数 ω[POPSIZE1]、β[POPSIZE1]、φ[POPSIZE1]作为初始的种群,把每一组 ω[i]、β[i]、φ[i](1≤i≤POPSIZE1)及相应的 d值代入公式(6),将使条件方差为正的 ω[i]、β[i]、φ[i]保留下来,再根据适应函数(9),按照遗传算法选择的步骤选取一组值(每个值都包含ω、β、φ三个参数)作为新一代种群。 ③交叉。把新一代种群两两配对,对每一对包含ω、β、φ三个参数的向量都随机产生一个[0,1]之间的数,这里设为r,如果r ④变异。对每一个包含ω、β、φ三个参数的向量都随机产生一个[0,1]之间的数,如果这个数小于P_MUTATION1,则发生变异,变异的方法为:随机产生一个[0,1]之间的数作为变异点,如果这一点的二进制编码为1就改为0,反之亦然。 ⑤将使适应函数依次变大的参数值保留下来。 ⑥循环步骤②、③、④、⑤直到达到最大进化代数GEN1,则得到的ω、β、φ的值就为d[i]所对应的极大似然估计的参数估计值。 (2)复制。对每一个 d[i](1≤i≤POPSIZE)值及经过上述①-⑥所选取的相应的最优参数ω、β、φ的值计算适应函数(8),同样按遗传算法的选择步骤选取一组值作为新一代种群。 (3)交叉。将选择出的新一代种群两两配对,对每一对 d[i](1≤i≤POPSIZE)随机产生一个[0,1]之间的数,如果小于P_CROSSOVER,则发生交叉,交叉方法同上。 (4)变异。对每个 d[i](1≤i≤POPSIZE)随机产生一个[0,1]之间的数,如果小于P_MUTATION,则发生变异,变异方法同上。 (5)重复上述复制、交叉、变异,直到所计算的Q值满足Q<x0.05(m)(此时迭代次数不应超过最大迭代次数GEN),则得到的d值就为最优的差分阶数。 (一)变量说明。T:样本容量,这里选取2000年1月4日到2006年6月30日的收盘指数,共1,555个;Pt:每日收盘指数,t=1,2,3,…T;Rt=100(logPt-logPt-1):每日收益率,t=1,2,3,…T;εt:对 Rt作确定性分析后的残差项,t=1,2,3,…T;d:差分阶数。 (二)数据分析:对上证综合指数每日收盘指数进行Eviews分析,其走势如图1所示。(图1) 收益率具有明显的聚类现象,时序图如图2所示。(图2) 由于股指内部各种股票的非同步交易会导致股指收益序列的自相关性显著,为了滤除序列中这种短相关因素而突出长相关因素,我们建立辅助自回归模型,分析其残差序列。 图1 上证收盘指数走势图 图2 上证收盘指数收益率时序图 对上证收益率建立辅助自回归AR(2)模型:Rt=0.0060+0.0449×Rt-1-0.0159×Rt-2+εt 对模型进行SPSS分析,如表1所示。(表1)从表1中可看出AR(2)模型中常数项和Rt-2的系数的尾概率分别为0.85784494和0.52724769,说明所建立的AR模型是不显著的。这是因为AR模型建立的前提条件是残差项εt必须是白噪声,这也就说明上证指数收益率的残差项不是白噪声,事实上,它具有显著的异方差性,因此,有必要对AR模型的残差项进行建模分析。 首先,由收益率和AR(2)模型我们可以计算出残差项εt的值,进而可得出残差平方项ε2t的值,用Eviews分析如图3所示,具有明显的异方差性。(图3) 图3 残差平方项时序图 由于我国股市具有长期记忆性,我们对扰动项平方项 ε2t建立 FIGARCH(1,d,1)模型,这里我们对1,555个数中连续的900个数进行实证研究,查表可知x0.05(30)=43.8,只要所计算的 Q<43.8,就说明所建立的模型是正确的。 应用遗传算法编程,选取参数值为: 对 FIGARCH(1,d,1)进行参数估计和差分阶数的计算得出结果,如表2所示。(表 2) 经过134次迭代后,Q=2.1950<43.8=x0.05(30)。 说明在建立了AR模型和FIGARCH模型后,所得到的误差项{βt}是白噪声,不存在短记忆性和长记忆性,所建立的模型是正确的,此时: 差分阶数:d=0.6162 参数:ω=0.4225 β=0.9928 φ=0.8802 似然函数值为:-2373.9469 由此可得,上证综合指数收益率(2000-01-04~2006-06-30)符合 AR(2)-FIGARCH(1,0.6162,1) 其中:βt是白噪声。 股票价格指数的变动反映出了股票市场所在国的政治、经济、社会和其他状况的变化,人们常常称其为“晴雨表”,因此研究股票市场的波动性是很有必要的。FIGARCH模型擅长于反映金融资产的异方差特性以及长记忆型的波动特性,它的主要应用领域是金融资产,包括证券、期权、利率等多方面。从提出至今,它已被许多人成功地应用到证券市场及汇率市场,很好地反映了金融市场的这种波动性。 本文应用遗传算法的思想进行编程,建立FIGARCH模型,模拟了中国股票市场的波动性过程。结果表明,对收益率进行AR建模后,再对FIGARCH模型进行一阶预测的值与真实值的差得到的时间序列是白噪声,也就是说经过建立自回归模型和FIGARCH模型后,金融时间序列已经消除了短记忆性和长期记忆性。上海股市d=0.6162,显著不同于0和1,说明过去的冲击对未来股市的影响将会持续相当长的时间,即中国股票市场的波动性过程具有长期记忆性。这也就意味着可以用过去的历史收益和波动情况来预测未来的收益情况,从而能利用过去的波动性建立风险控制模型和增加获取投机利润的机会。除此之外,模型中的β值为:0.9928,非常接近于1,这意味着条件方差收敛于无条件方差的速度较慢,因此对条件方差的冲击经过相当长一段时间才会消失,也就是说波动性是持久的,进一步反映了股市的长期记忆性。 表1 AR(2)模型的SPSS分析 表2 基于遗传算法的C语言程序求解 遗传算法不同于传统的优化和搜索方法,它具有智能性和并行性。智能性使得所选择的子代具有很强的适应性,通过交叉和变异所得到的后代更适应环境;而并行性则实现了空间中的多个区域的同时搜索,保证了大规模计算在短时间内完成。遗传算法为建立FIGARCH模型提供了一个平台,我们可以通过优化目标函数的方法来获得差分阶数d的值,这种做法是科学的,所计算出的d值是显著异于0和1的。然而,我们事先无法预测遗传算法中的最大迭代次数(GEN),只能通过大量的实验或是预先给出一个比较大的值来进行定性的检验。遗传算法是通过交叉和变异来实现结果优化,当迭代到一定次数以后,收敛的速度就会减慢,增加了运算的时间。除此之外,对于不同的适应函数、不同的数据,应如何确定遗传算法中的参数,即如何确定P_CROSSOVER和P_MUTATION的值,也有待于进一步的研究。 [1] R F.A Engle utoregressive conditional heteroscedasticity with estimates of the variance of U.K.Inflation[J].Econometrica,1982. [2] Bollerslev T.Generalized autoregressive conditional heteroskedasticity[J].Journal of Econometrecs,1986. [3] Engle R F.Bollerslev T,Modeling the persistence of conditional variances[J].E-conometric Reviews,1986. [4] Richard T.Baillie,Tim Bollerslev,Hans Ole Mikkelsen.Fractionally integrated generalized autoregressive conditional heteroskedasticity [J].Journal of Ecometrics.1996.Vol.74. [5] Bollerslev T,Mikkelsen H O.Modeling and pricing long memory in stock market volatility[J].Journalof Econometrics,1996. [6] 李汉东,张世英.自回归条件异方差的持续性研究[J].预测,2000.1. [7] 汤果,何晓群,顾岚.FIGARCH模型对股市收益长记忆性的实证分析[J].统计研究,1999.7. [8] 李颖,汤果,陈方正.FIGARCH模型的参数检验与估计[J].统计与决策,2003.1. [9] Geweke J.Porter—Hudak.Estimation and Appli—cation of Long Memory Time Series Model[J].Journal of Time Series Analysis,1983.4. [10] Andrew W.Lo (1991),Long-Term Memory in Stock Market Prices[J].Econometrica,59(5),September. [11] 王春峰,张庆翠.中国股市波动性过程中的长期记忆性实证研究[J].系统工程,2004.1. [12] 王小平,曹立明.遗传算法——理论、应用于软件实现[M].西安:西安交通大学出版社,2002. [13] 张晓峒.计量经济学软件Eviews使用指南[M].天津:南开大学出版社,2003.


二、基于遗传算法的C语言算法设计
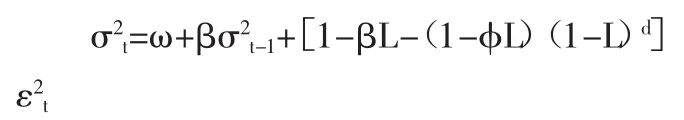
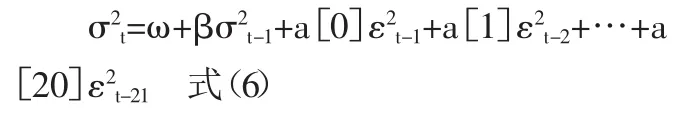

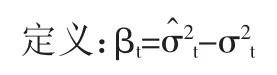

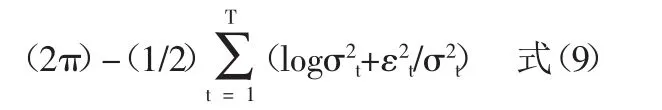
三、上证综合指数分析




四、结束语


