一个用户行为相关的结构化对等网络维护代价削减协议
2010-08-01曹元大成保栋
张 昱,靳 军,曹元大,成保栋
(北京理工大学计算机科学技术学院智能信息技术北京市重点实验室,北京 100081)
结构化 P2P系统的优势在于节点加入和退出时,覆盖层(overlay层)可以自动更新路由状态,即使在大量节点崩溃后,仍然可以维持正确路由.但是这种优势是需要代价的:节点必须消耗大量的网络带宽来维护其自身结构,这就是本文探讨的结构化 P2P网络自身结构的维护代价.文献[1]对这种维护代价进行了关注.节点的每次加入和退出都要做繁琐的路由维护操作,如果节点出现故障,维护的代价更为高昂,这种维护操作甚至影响到了系统的可用性,限制了结构化 P2P系统在高动态性的网络环境下的使用.
Chord[2]是被广泛研究讨论的结构化 P2P系统之一.Chord中没有主动发现节点变化的机制,节点的加入、离开和失效都有可能造成 P2P网络的不一致.Chord采取稳定化的机制来更新路由:每个节点定期发送查询消息.在一个有 N个节点的 Chord网络中,节点加入时为构建它的路由表其查询开销为O(lb N)跳.Joung等[3]对Chord的维护代价进行了一个渐进分析.各种优化的 Chord结构被提出,如Garcés-Erice等[4]提出了一个 Chord 的改进版,底层覆盖被分成了许多子环,Chord2[5]利用超级节点削减维护代价.Ratul Mahajan等[6]在Pastry上进行了一个近似于真实动态 P2P网络环境下的代价削减研究.Xu等[7]在保持CAN的低维护代价的同时,将路由性能从 O(N1/d)提高到 O(ln N)等.上述系统虽然都在一定程度上削减了维护代价,但其共同的特点是仅仅针对系统结构或者节点加入、退出算法进行改进,而没有考虑实际使用过程中用户的行为特征,简单地把每次节点的加入作为全新的加入处理,而不能区别对待首次加入和再次加入系统的节点,造成维护操作的重复执行.
笔者把研究重点放在降低结构化 P2P系统自身的维护代价上,并重点考虑了 P2P系统中用户行为的特征,解决了同一节点多次重复加入、离开系统造成的高维护代价问题,提出了一个全新的克隆节点协议(clone node protocol,CNP).在大大降低结构化P2P系统维护代价的同时能有效改善查询效率.为了更好地描述笔者提出的克隆节点协议,本文以 Chord为例,将 CNP引入 Chord,实现了一个基于 CNP的Chord系统——Clone Node Chord based on CNP,简称 CNChord.
1 协议概述
CNP的基本思想是:在结构化P2P网络中,对网络中的节点进行克隆;通过克隆节点来维护被克隆节点的信息;在被克隆节点离线后,克隆节点接替其工作;当被克隆节点再次上线时,差异性地同步变化信息,并恢复被克隆节点之前的工作.CNP将大大减少系统的维护代价,为了更好地描述CNP协议,笔者以 Chord为例,实现了一个基于 CNP的 Chord系统——CNChord.
1.1 CNChord拓扑结构
在Chord中,一致性哈希将关键字组织在一个以2m为模的 ID环上.关键字被分配到节点的 ID等于或者大于关键字ID的第1个节点上,该节点被称为关键字(key)的后继节点,记为 successor(key).关键字ID被表示为一个从0开始编号到2m-1的环,基于此,successor(key)是从k开始,ID环上顺时针方向的第1个节点.在CNChord中,笔者采用如下定义.
定义1 后继节点:节点Nodex的后继节点 Nodes,是在 Chord环上,沿顺时针方向,位于 Nodex之后的第1个节点,记为successor(Nodex)=Nodes.
对一个拥有 n个节点的网络,节点集合 N={Node1,Node2,…,Noden}.各个节点首先按照 Chord的方式组成 Chord环.在此基础上,对于任意节点Nodex,1≤x≤n,假设其后继节点 successor(Nodex)为Nodes,则在 Nodex上克隆 Nodes(克隆算法参见 1.3节),完成CNChord的组建.
定义2 主节点:上述过程中,原Chord环上的任意节点称为主节点,用Node表示,如Nodes.
定义3 克隆节点:上述过程中,当主节点(例如Nodes)被克隆之后,其维护在 Nodex上的部分,被称为Nodes的克隆节点,记为CNodes.
图1(a)所示为典型的 4个节点的 Chord结构,图1(b)所示为图1(a)对应的CNChord结构.
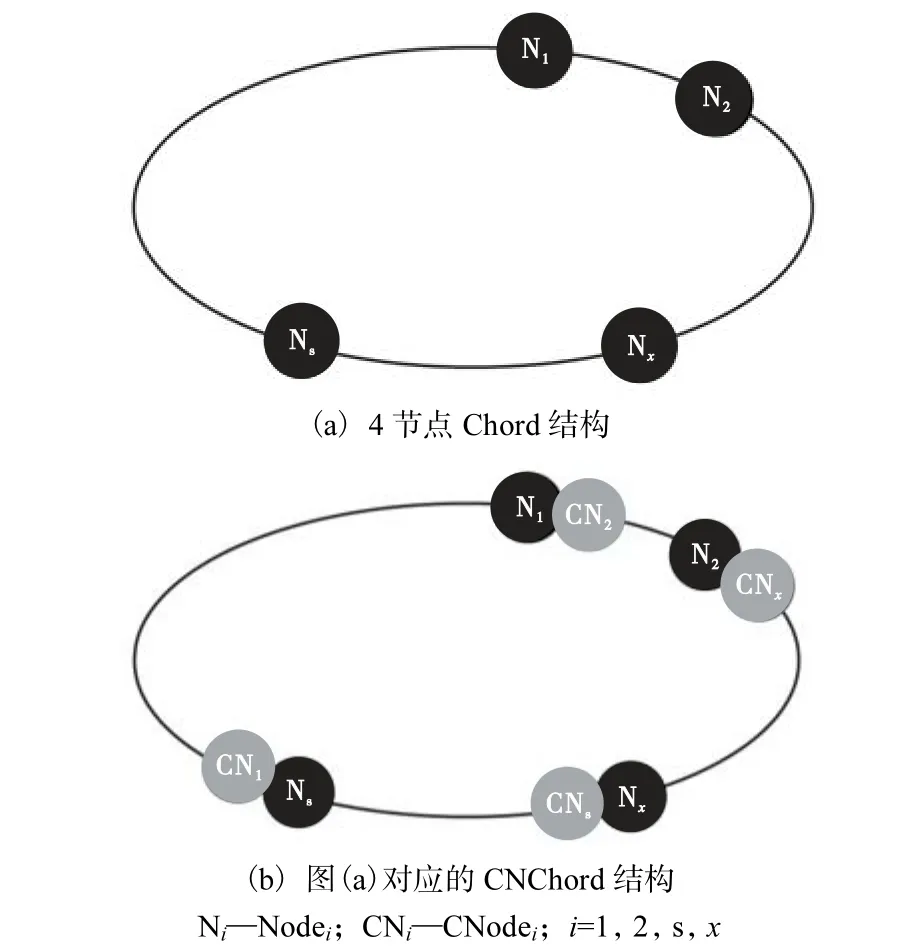
图1 4节点Chord结构及其对应的CNChord结构Fig.1 Structure of 4-node Chord and of the corresponding CNChord
1.2 CNChord路由表结构
CNChord节点路由表由两个相同结构的 finger table(finger表)组成,记为 FingerTable1 和FingerTable2,分别用来存放主节点和克隆节点的路由信息.FingerTable1和FingerTable2的结构见表1.
CNChord的两个路由表各含有 m个表项,m为节点 ID 标识符位数,且满足 lim(PHash(X)=Hash(Y))=0,X、Y∈{Node1,Node2,…,Noden},其中 Hash(X)和Hash(Y)分别代表 NodeX和 NodeY的 ID 哈希值,PHash(X)=Hash(Y)代表 NodeX和 NodeY的 ID 哈希值相等的概率.每个表项用三元组(序号 Sequence,距离Distance,值 Value)表示,其中 Sequence∈[0,m-1],Distance=2i,i∈{0,1,…,m-1}.记 CNChord 中Nodex路由表中 Sequence=i的表项 Value字段指向的节点为 Nodei,则 Nodei满足:|ID(Nodei)-ID(Nodex)|≥ 2i,且 |ID(Nodei)- ID (Nodex)|=min{|ID(NodeY)-ID(NodeX)|≥2i,i∈{0,1,…,m-1},X、Y∈{Node1,Node2,…,Noden}.特殊地,successor(Nodex)=Nodex.Finger Table1[0]. value.

表1 FingerTable1和FingerTable2的结构Tab.1 Structures of FingerTable1 and FingerTable2
1.3 初始化过程
定义4 基本时间单位T:在overlay层进行一跳的时间,单位通常为ms(毫秒),具体数值由Chord网络状态决定.
定义5 节点状态:节点 i状态 STAi,STAi∈{idle,busy,waiting},i∈{1,2,3,…,n},n 为系统中节点个数.其中idle代表节点空闲,busy代表节点繁忙,waiting代表节点空闲等待.
记节点最后一次完成某动作的时刻为 Tlast,记系统当前时刻为Tcur,则有下述定义.
定义6 当前空闲时间 Tnoact:Tnoact=Tcur-Tlast,其中 Tcur≥Tlast.
定义7 空闲触发阈值 Tts,Tts=max{Tcuri-Tlasti},i∈{1,2,3,…,n},n 为系统中节点个数.
CNChord是建立在 Chord的基础上的,因此,在建立 CNChord之前,各个节点需要先按照文献[2]中描述的方法建立一个 Chord环,具体过程不再重述.之后,各个节点执行克隆算法,将自己的直接后继节点的信息克隆到本地,如果 CNChord中大量节点同时执行克隆算法,势必会造成网络中同时产生大量的复制信息流.为了避免出现这一问题,笔者提出了一种被动式克隆算法,在主节点空闲的时候通过Pull(主动拉)操作来完成CNChord的组建.
算法1 被动式克隆算法——Pull Clone(Nodex)
步骤1:Nodex首先执行ISBusy(Nodex)函数判断自己当前的状态,如果 STAx=idle,转步骤 2;否则等待直至 STAx=idle,转步骤 2.也就是说主节点(Nodex)在自己空闲的时候执行本算法,而不用区分此时被克隆节点(Nodes)的状态.
步骤 2:Nodex计算 Tnoactx=Tlastx-Tcurx,判断如果 Tnoactx≥Tts,执行步骤 4;否则 STAx=waiting,转步骤3.
步骤 3:Nodex有新的操作,STAx=busy,转步骤1;否则等待直到Tnoactx≥Tts,执行步骤4.
步骤 4:Nodex查找得到其后继节点,Nodes=Find_successor(Nodex),执行 ISBusy(Nodes)函数判断 Nodes的状态,STAs∈{idle,waiting}则转步骤 5;否则,STAs=busy,系统等待直至 STAs∈{idle,waiting},转步骤 5.
步骤 5:执行 Clone(Nodes,Nodex)函数,将 Nodes克隆到 Nodex,完成 Nodes的被动式克隆操作.Clone(Nodes,Nodex)函数只需将 Nodes的FingerTable1复制到 Nodex的 FingerTable2即可,不需要进行额外的复制操作.限于篇幅,复制函数在此不做进一步描述.
Chord中各个节点按照算法 1描述的过程在各自空闲的时候对其后继节点进行克隆操作,在一段时间后,完成CNChord的组建,系统达到稳定状态.
1.4 查询机制
CNChord查询机制的基本思想是:节点收到查询请求后,对于没有克隆节点的单一主节点,在FingerTable1中查找;对于已经同时拥有克隆节点和主节点的节点,同时在 FingerTable1和 FingerTable2中查找.
同时,笔者对具体查询的过程进行了优化,提出了一种快速定位算法(算法2).
算法2 快速定位算法


算法 2中,提出并采用了一种先两端定位后倒查搜索的快速确定搜索范围的方式,用该方式完成对FingerTable的处理,可以加快CNChord系统定位搜索范围的速度.
图2所示为一个典型的可容纳 256个节点的CNChord系统,图中给出了节点 N1按照算法 2中描述的步骤查询关键字185的查找过程.
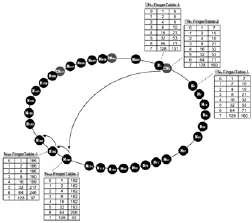
图2 256个节点的CNChord中N1查找关键字185的过程Fig.2 Searching process of N1 for key word 185 in a typical Fig.2 CNChord with 256 nodes
在图 2中,N1首先查询其 successor节点,successor(N1)= N1.FingerTable1[0].value=6,因 为185∉(0,6],且N1的FingerTable2也不为空,所以从其 FingerTable2的最后一项查找,N1.FingerTable2[7]. value=160<185,所以将查询转发到 N160;同样 N160的后继节点为 N182,185 ∉ ( 0,182],而 N160的 FingerTable2为空,所以从其 FingerTable1的最后一项查找 N160.FingerTable[7].value=182<185,所以将查询转发到 N182;类似的,得到 N182的后继节点为 N186,此时185 ∈ ( 0,186],返回节点 N186,查询成功.
在基于Chord的文件共享系统中,通常的机制是各个节点自主决定存储资源,而将(NodeID,ObjID)对存储在 successor(ObjID)节点上.其中 NodeID为节点标识,ObjID为对象标识.可能会出现资源存在、却无法查到的情况.例如,某节点 Node1上有全局唯一资源 Obj1,经过哈希后,将(Node1,Obj1)对存储在successor(Obj1)=Node57的节点上.某一时刻,Node57发生异常离开系统,系统不能立即对此变化进行响应,尚未完成对应表项的更新.则即使此时拥有Obj1的节点,Node1仍然存在于系统中,对于 Obj1的查询仍将返回失败结果.而 CNChord在面对同样情况时,Node57失效,无论 Chord结构是否检测到了异常,也不管此时的路由表项是否已经得到修复,原先路由到Node57的查询请求,将直接路由到其克隆节点CNode57,并返回正确的查询结果(Node1,Obj1).所以在应对稀缺项的查找方面,CNChord的表现要优于Chord:只要出现在 CNChord中的资源,甚至曾经出现过的资源(查询时刻拥有该资源的节点不在线),就一定会被检索到.
定理 1 在一个 N个节点的 CNChord网络中,查询复杂度的最优值是
证 明 首先一个 N个节点的 Chord网络中,查询复杂度是O(lg N)[2].在CNChord中,每步查询,可以到达之前Chord中需要2步才能访问到的节点,图 3分别给出了对应于图 2结构的 Chord和CNChord中Node1查询关键字160的过程.
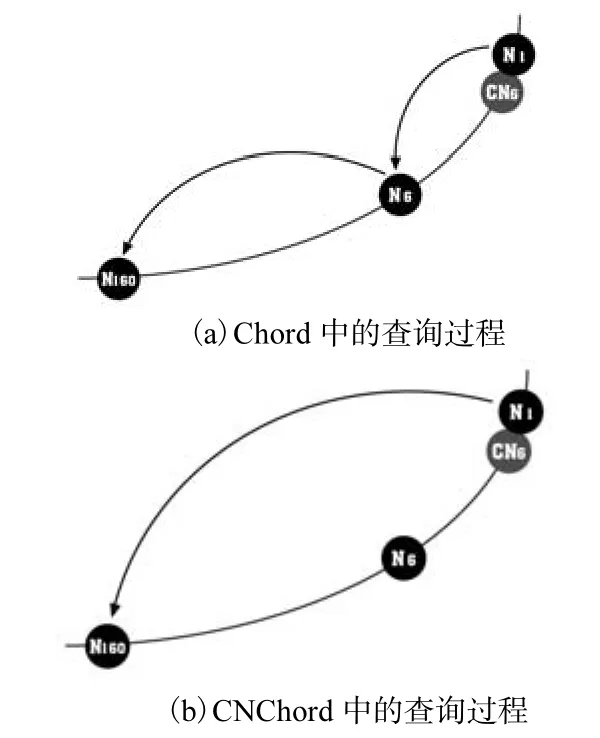
图3 Chord和CNChord中的查询过程Fig.3 Searching processes in Chord and CNChord
可以看出,CNChord中节点可以在本身和其successor节点的克隆节点上同时查找,原来Chord中需要2步完成的查询在CNChord中只需1步就完成了,所以 CNChord的查询复杂度的最优值为
2 动态操作和维护
2.1 节点加入
CNChord的加入过程大致可以分成2个阶段.
阶段 1:节点加入 Chord环.新节点在加入时至少需要知道1个已知节点的信息,然后只要按照文献[2]中 Chord的加入算法,完成新节点的加入过程即可.如果新加入的节点是Chord环上的第1个节点,执行文献[2]中描述的create()过程.
阶段 2:新加入节点的直接前驱,即其 predecessor,按照算法 1,完成新加入节点的克隆过程,将新节点并入CNChord.
2.2 更新机制
当 CNChord中主节点自身表项发生变化时,系统必须将相应的变化同步到克隆节点.在此,为了减少算法1中PULL操作产生的查询信息消耗,同时尽量减少同步过程中需要传递的信息数量和大小,笔者提出了差异性push同步算法.
算法 3 差异性 push同步算法——Push Sync(Nodes,Nodex)
//差异性同步Nodes变化到Nodex
步骤 1:当 Nodes.FingerTable1[i].value变化时转步骤2.
步骤 2:执行 ISBusy(Nodes)判断 Nodes当前的状态,如果 STAs=idle,转步骤 3;否则等待直至STAs=idle后再转到步骤 3.ISBusy()函数的引入可以有效利用节点的空闲时间,降低节点的瞬间负载,也可以确保路由操作在同步之前得到优先处理.
步骤 3:Nodes执行 Send(Nodes.FingerTable1[i],Nodex)函数,send()函数只将 Nodes中 FingerTable1发生变化的表项序号和变化后的值传递到克隆节点CNodes,大大减少了传递的消息数量,转步骤4.
步骤 4:CNodes接收到 send()函数发送的内容后,立即对其所在节点Nodex的FingerTable2中对应的表项值进行更新.至此算法3完成一次差异性同步.
例如,在图 2中,假设 Node21离开,则 Node6.FingerTable1[3].value由 21变为 32,发生该变化后,首先执行 ISBusy(Node6)判断节点的状态是否繁忙,忙则等待;空闲则执行 sync(Node6,Node1)发送Node6.FingerTable1[3].value=32给 CNode6,然后更新Node1.FingerTable2[3].value=32.完成同步过程.
2.3 节点退出
现有研究体现了用户的活动随天呈现出很强的周期性[8].分布稳定指的是节点每天的活动在时间区间上分布是相似的,这样就可以通过当前的可用性分布来预测和描述节点以后的分布状况[9].考虑一个典型的文件共享系统中用户(记为A)的行为.A每天在工作时间段参与共享行为,早 9:00左右上班后登录系统,晚 17:00左右下班注销.按照传统Chord的策略,A离开系统后,将由A的successor(记为B)接替A的工作,这样,原来存储在 A上的数据就要转移到B上,当第2天A再次登录系统的时候,需要重复一次加入过程,A被视为全新的节点.然后再将B上存储的信息分担一部分(也就是昨天存在 A上的那部分数据)重新取回.这种转移→取回的过程每天都要重复进行,而且,如果用户临时离线(如重启系统或者由于网络不稳定等原因造成的离线),也会引发Chord的这一维护过程.从中可以看出,用户的上述行为特征(即规律性地频繁加入或退出系统)频繁发生时,Chord为了维护自身的环状结构,必然产生大量的维护信息.笔者在 CNChord中提出了优化维护算法,来解决节点频繁加入或退出系统引发的维护代价过大的问题.优化维护算法的逻辑描述如下所述.
算法4 优化维护算法
步骤1:NodeA离开后,由它的克隆节点CNodeA来接替NodeA的工作,原先转发到NodeA的所有信息都将转发到 CNodeA进行处理.对于系统中的其余节点来说,这一过程是透明的,感觉不到 NodeA已经离开,仍然进行正常的工作.
这一机制适用于节点主动离开和因故障离开的情况:在主动离开时,NodeA在离开之前发送信息告知 CNodeA接替自己的工作;而在故障离开的情况下,是由 predecessor(NodeA)节点发现 NodeA的离开,并启用CNodeA.
CNodeA接替 NodeA工作时,启动 Log日志,开始记录所有产生变化的表项,只需记录发生变化的表项的序号即可,这样做的好处是在下述步骤 3中更新的时候,只需将发生变化的表项的最终状态传递给主节点即可,减少了日志的长度和传递的信息数量;而对于Chord来说,在NodeA离开后,原来存储在NodeA上的信息都要转移到 successor(NodeA)上,同时,还要对所有涉及NodeA的路由表项进行更新.
步骤2:NodeA离线后,对于其上的路由表项等信息不予删除,以备再次加入系统时使用.而 Chord中,在离线后,删除 NodeA上的所有信息并移动到successor(NodeA)上,当NodeA再次登录时,仍然要花费巨大的代价来重建这些信息,并重新拷贝回NodeA上.在CNChord中,系统提供机制,在用户需要的时候(比如用户永久退出系统)人工触发删除信息的操作.
步骤3:当 NodeA在某时刻再次加入系统时,判断CNodeA是否存在:如果不存在则将NodeA作为全新节点加入系统;如果存在,执行 Opti_maintenance(CNodeA,NodeA)子算法将 CNodeA的变化同步给NodeA.这一过程,又可细分为 CNodeA端子算法和NodeA端子算法,分别描述如下.
1)CNodeA端子算法
步骤1:判断Log是否为空,为空则说明从NodeA离开后CNodeA没有产生任何变化,不需要同步,转步骤4;相反,Log不为空,定位到Log文件头,执行步骤 2.
步骤2:从 Log中读入一个序号值 k,查找CNodeA.FingerTable2[k].value=v,将(k,v)发送给NodeA,转步骤 3.
步骤3:是否是 Log文件尾,是则转步骤 4;不是则转步骤2.
步骤4:清空 Log,向 NodeA发送消息 takejob(),通知NodeA接替CNodeA的工作.
2)NodeA端子算法
步骤1:判断收到的消息是takejob()还是(k,v)消息,是 takejob消息则转步骤 3;是(k,v)消息则转步骤 2.
步骤2:同步变化,令 NodeA.FingerTable1[k].value=v.接收下一条消息,转步骤1.
步骤 3:NodeA接替 CNodeA的工作,向 CNodeA发送消息,告知自己已经接替其工作.两者按照CNChord描述的机制继续工作.
可以看出,优化维护算法即使在节点频繁加入和离开系统的时候,CNChord维护自身结构所需的消息量也是非常少的.
3 实验结果与分析
3.1 实验环境
笔者用 Java编程模拟实现了一个完整的 Chord算法,并且在此基础上,构建了CNChord.
每个实验都分成 5组,每组中节点的数目 N分别为 28、210、212、214、216,系统中资源的总数为 106,对应于每组具体实验参与的资源的数目为 10N,从资源总数中随机选取.每组实验分别进行 20次,记录各次的结果,计算平均值,作为该组实验的取值.对于各组实验,10N个资源一经选取就不再改变,直到下组实验开始后重新选择.资源在分配给节点的过程中,采用随机算法,每个节点获得的资源数目限定在区间[0,100]之间.
为了验证 CNP协议的性能,针对 P2P系统引发维护操作的 3种行为,分别设计了 3个实验来对比CNChord和原Chord协议的维护代价.
3.2 初始维护代价
让系统的初始节点数目为0,之后N个节点在T时间段内随机加入,T的选择要大于 Chord和CNChord达到稳定所需的时间.假设节点在加入后不再退出.以此来模拟 Chord和 CNChord的构建过程,记录两者在达到稳定状态后产生的维护信息数量(实验均值),如图4所示.
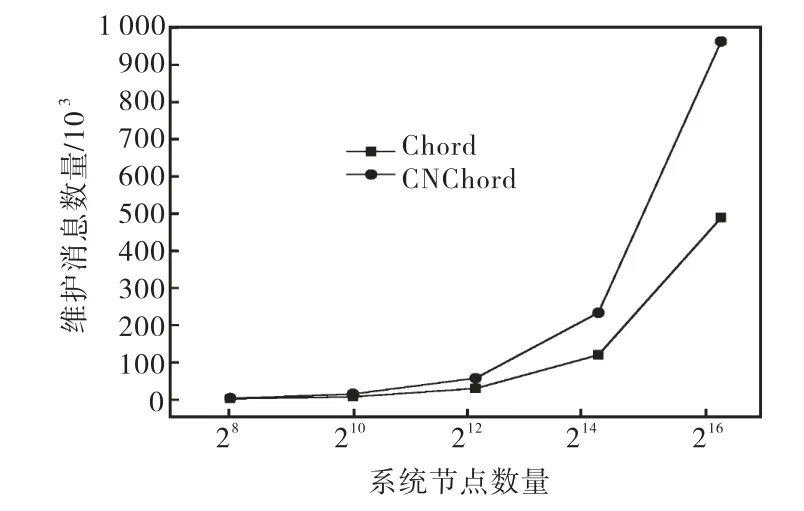
图4 初始化维护消息数量Fig.4 Number of maintenance messages caused by initialization
从图 4中可以看出,在构建过程中,CNChord的维护信息数量基本为Chord的2倍左右.这是因为,CNChord建立之前,不仅需要建立 Chord的结构,还需将所有 Chord节点克隆到新的位置.第 N个节点首次加入时维护代价分两部分:首先维持Chord环的O(1/N)部分的关键字移动到新的位置;接着这部分关键字移动到其克隆节点,也是 O(1/N),造成双倍的信息流动.
3.3 节点退出维护代价
接着,让每组的主节点随机地退出系统,同时设定没有新节点加入.主节点退出的方式分为主动退出和故障退出两种情形,两者的区别是主动退出的节点会给其克隆节点发送退出消息,告知自身的状态变化,让克隆节点接替自己的工作.而节点因故障退出后,由其 predecessor检测到异常信息,并激活克隆节点.记录Chord和CNChord的维护代价,如图5所示.
从图 5中可以看出,在节点随机退出系统的时候,Chord的维护代价要远远大于 CNChord.这是因为Chord在节点离开后,需要将原来保存在该节点的资源移动到其successor上,而CNChord没有上述操作.CNChord中仅有的一些维护操作,也是对个别路由表项的修改.在节点只退出不加入的情况下,这些维护基本可以忽略.
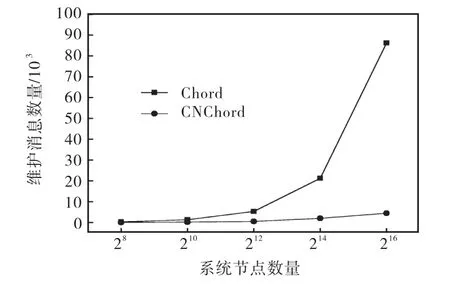
图5 节点离开时产生的维护消息数量Fig.5 Number of maintenance messages caused by departure of node
3.4 节点频繁加入/退出维护代价
令参与系统的节点数目为212.分成5组,时间段分别为 0.2,h、1,h、6,h、12,h、24,h 和 36,h.每组实验中,让系统中 10%的节点在对应的时间段内随机退出并再加入系统一次,记录 Chord和 CNChord的维护代价,如图6所示.
从图6可以看出,Chord维护代价曲线随着节点变化频繁程度的降低也逐渐降低,并趋于稳定;而且开始的时候变化明显(直线的斜率大),到后面渐渐趋于水平.这是由于 Chord中节点变化越缓慢,触发的维护操作越少,对系统的影响越小.同时,可以看出,CNChord维护代价占 Chord维护代价的比重越来越多,也就是说,CNChord对减少 Chord维护代价的作用越来越小,比重由 0.2,h的 68.5%(CNChord比Chord减少了 31.5%),增加到 32,h的 96.5%(CNChord仅比Chord减少3.5%).可见,节点的动态性越强,CNChord的作用越明显;反之,则越弱.可见CNChord比 Chord更能适用于节点具有高度动态性的结构化P2P系统.
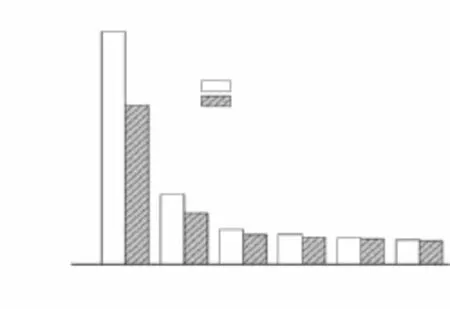
图6 节点频繁加入/退出系统的维护消息数量Fig.6 Number of maintenance messages caused by frequent joining or departure from system of node
4 结 语
笔者为今后对 P2P网络自身维护代价的削减研究做出了一些基础性的工作——和用户行为特征相结合,提出一种克隆节点协议 CNP,有针对性地降低结构化P2P系统自身结构的维护代价,并针对具体的结构化 P2P系统 Chord,实现了一个基于 CNP的Chord系统 CNChord.CNP不光可以用于 Chord,还可以应用到类似的结构化 P2P系统中.理论分析和实验表明,CNP是一种较为有效的协议,可以有效削减高度动态的P2P系统自身的维护代价.
[1] Kersch P,Szabo R,Cheng L,et al. Stochastic maintenance of overlays in structured P2P systems[J]. Computer Communications,2008,31(3):603-619.
[2] Stoica I,Morris R,Karger D,et al. Chord:A scalable peer-to-peer lookup service for Internet applications[C]//Proceedings of ACM SIGCOMM 2001. SAN Diego,CA,USA,2001:17-32.
[3] Joung Y,Wang J. Reducing maintenance overhead in Chord via heterogeneity[C]//Cluster Computing and the Grid,CCGrid 2005. Cardiff,UK,2005:221-228.
[4] Garcés-Erice L,Biersack E W,Ross K W,et al. Hierarchical peer-to-peer systems[J]. Parallel Processing Letters,2003,13(4):643-657.
[5] Joung Yuh-Jzer,Wang Jiaw-Chang. Chord2:A two-layer Chord for reducing maintenance overhead via heterogeneity[J]. Computer Networks,2007,51(3):712-731.
[6] Mahajan R,Castro M,Rowstron A. Controlling the cost of reliability in peer-to-peer overlays[C]// Peer-to-Peer SystemsⅡ:Second International Workshop,IPTPS 2003.Berkeley,CA,USA,2003,2735:21-32.
[7] Xu Z,Zhang Z. Building Low-Maintenance Expressways for P2P Systems[R]. Palo Alto,CA:Hewlett-Packard Labs,2002.
[8] Tati K,Voelker G M. On object maintenance in peer-topeer systems[C]//Proceedings of the 5th International Workshop on Peer-to-Peer Systems,IPTPS2006. Santa Barbara,CA,USA,2006:1-6.
[9] 刘翰宇.P2P文件共享系统Maze中资源及用户行为特征分析[D].北京:北京大学信息科学技术学院,2005.Liu Hanyu. Analysis of Resource Characteristics and User Behavior in P2P File Sharing System Maze[D].Beijing:School of Electronics Engineering and omputer cience,Peking University,2005(in Chinese).
