舰船装备维修费预测的数据预处理技术研究
2010-03-06魏汝祥于伟宗
谢 力 魏汝祥 于伟宗 黎 利
1海军工程大学 装 备经济管理系,湖北 武 汉 430033
2中国人民解放军92848部队财务办,辽宁 大 连 116041
3中国人民解放军91224部队办公室,上海 200235
舰船装备维修费预测的数据预处理技术研究
谢 力1魏汝祥1于伟宗2黎 利3
1海军工程大学 装 备经济管理系,湖北 武 汉 430033
2中国人民解放军92848部队财务办,辽宁 大 连 116041
3中国人民解放军91224部队办公室,上海 200235
在预测舰船装备维修费时,收集足够多的、准确的费用数据是关键。根据舰船装备维修费的影响因素,将舰船装备维修费预测的相关原始数据分为基础数据、使用数据、维修数据和宏观经济数据,确定了相应的数据收集渠道。分析了收集到的原始数据可能存在噪声、缺失或异常数据、冲击扰动数据、不一致数据的问题,针对性地提供了相应的数据预处理技术,经过处理后的数据可以为舰船装备维修费预测提供良好基础,进一步提高预测的有效性。
舰船装备;维修费预测;数据预处理
1 引言
在舰船装备维修费预测中,存在的问题之一是很难收集到足够多的、准确的费用数据。因此在费用预测之前应做好数据的收集与预处理。如果没有充足的、有价值的数据,费用预测将很难达到预期的效果。
数据预处理是应用模型对数据处理分析的第一步。数据预处理期望达到的目的主要有4个[1]:1)提高数据的质量。通过对数据的预处理,发现不符合要求的数据并将其剔除,从而提高数据的整体质量;2)转换数据格式。有的模型要求一定格式的数据,对于不符合格式要求的数据,可以通过对数据格式的变换,达到模型的要求;3)提高处理效率。这是数据预处理的主要目的。通常数据预处理后,数据一般格式更为整齐,也更加简单,因此会提高模型的处理效率;4)进行简单的数据分析。一些简单的数据分析功能也归入到数据预处理模型中,比如简单统计量的计算,自定义函数等。目前,数据预处理常用于许多领域的数据分析中,如化工试验和处理[2-4]、变量选择[5]、色谱分析[6-7]、信号处理[8]、模式识别[9]、曲线拟合[10]、数据挖掘[11],以及预测[12-14]、决策[15]等方面。 而其中涉及到的数据预处理技术,都是从具体的背景出发,从数据分析和建模需要的角度对特定的数据进行的预处理,研究相对片面,并不适于推广应用。
本文将针对舰船装备维修费预测收集到的原始数据中可能出现的几种问题,尝试应用不同的数据预处理技术,为舰船装备维修费的预测提供良好的数据。
2 原始数据的收集
舰船装备维修费具有时间跨度大、影响因素多及费用数据离散等特点。原始数据的获取是舰船装备维修费预测过程中最困难、最花费时间的活动之一。在进行原始数据的收集前,首先必须对所需的数据进行分类,然后根据不同数据的类型确定数据收集的来源。根据舰船装备维修费的影响因素,可以将舰船装备维修费原始数据分为:基础数据、使用数据、维修数据和宏观经济数据。
1)基础数据
舰船装备维修费预测的基础数据,是指舰船装备生产后交付部队使用时所具有的一些基本数据,它不随舰船装备的使用而发生变化。如舰船装备的造价、排水量、下水时间以及舰船装备的固有可靠性、维修性等。
2)使用数据
舰船装备维修费预测的使用数据,是指在舰船装备的使用过程中反映舰船装备所处状态的数据,它随着舰船装备的使用而发生变化,是动态性的数据。如舰船装备的新旧程度和使用强度等。
3)维修数据
舰船装备维修费预测的维修数据,是指在维修过程中反映舰船装备维修情况的数据以及各分项维修费用的具体数据。如舰船装备的维修级别、维修轮次、维修批量、维修地域、维修制度等。
4)宏观经济数据
舰船装备维修费实质上是维修过程中的一种经济活动的反映,任何经济活动都是在其宏观经济条件下进行的。舰船装备维修费预测的宏观经济数据,是指影响装备维修费的国家宏观经济数据。如物价指数、反映资金的时间价值的基准利率等。
对于不同类型的数据,需要明确其相应的数据来源,便于有的放矢地收集数据。数据类型及相应的来源见表1所示。

表1 数据类型及来源
3 原始数据可能存在的问题
由于舰船装备维修费预测中原始数据自身的一些特点以及数据收集过程中的一些特殊因素的影响,收集到的原始数据与最终数据分析时所需要的数据还存在一些差距,表现在作为统计过程,对数据表现形式和完整性的要求是很高的,而直接获得的数据往往达不到这些要求,也就是收集到的原始数据可能存在一些不利于舰船装备维修费预测的问题。
1)噪声
由于种种能控制的或不能控制的主客观条件的影响,以及数据传输过程中的错误等,使收集到的舰船装备维修费原始数据中可能会存在噪声。排除原始数据中噪声的影响,把真正有用的信息从原始数据中提取出来,再对信息作进一步的分析,才能得到更加可靠的舰船装备维修费预测结果。
2)缺失或异常
由于舰船装备计划修理的周期性,收集到的原始数据可能是不连续的,此外,由于资料上的管理不善或数据收集者认为某些属性不重要而在数据记录时忽略等原因也可能造成数据的缺失。数据的缺失可能会影响舰船装备维修费预测的顺利进行。由于一些特殊的情况的出现,有些原始数据可能并不能反映维修费变化的基本规律,也就是维修费预测中原始数据的异常值。这些异常值,可能会将舰船装备维修费预测引导偏离真实规律的轨道。
3)冲击扰动
收集到的舰船装备维修费原始数据,有时会由于受到政策和环境的冲击扰动而失真,亦即舰船装备维修费数据序列未能确切地反映维修费真实变化规律。在这种情况下,如果不事先排除冲击干扰,而用业已失真的数据直接建模、预测,则得到的定量预测结果很可能与人们直观的定性分析结论大相径庭,从而使预测结果令人感到难以置信。
4)不一致
由于舰船装备维修费预测中的原始数据来源于多个不同的单位,信息庞杂,采集和加工的方法有别,数据描述的格式也各不相同,缺乏统一的标准。在这种情况下,如果不事先对原始数据进行处理,就没法有效地对数据进行进一步的分析或导致对舰船装备维修费的预测过程偏离实际。
4 数据预处理技术
根据上面的分析,由于舰船装备维修费原始数据可能会存在一些问题,而影响其维修费预测。因此,要对所收集到的数据进行处理。
4.1 噪声数据的预处理技术
造成原始数据噪声的原因有很多,针对噪声问题,可以采用数据的横向或纵向比较,对数据进行平滑处理[16]。横向比较就是与同时期的类似装备的比较,纵向比较就是不同时期样本的变化规律的比较。
1)界限平滑
界限平滑,是指在比较过程中,通过设定一定的范围(如±10%),当某个变量的数据超出(或低于)设定的范围,则以该范围的上限(或下限)来代替该变量值,以平滑噪声对数据过大的影响。
2)指数平滑
指数平滑,是指通过设定一个加权系数,在原始数据与相应的正常数据之间进行加权求和。

式中,α是加权系数,根据原始数据特征设定;x0是正常数据,对于横向那个比较来说,它是最相近舰船装备相应的数据,对于纵向比较来说,它是前一时期的样本值。
4.2 缺失值的预处理技术
对于缺失值的处理一般有两种处理方式:放弃和插值。由于舰船装备维修费样本数据具有小样本的特征,放弃缺失值会进一步减小原始数据的样本量,这显然是预测者所不愿意的。此外,由于舰船装备影响因素众多,不同样本中因素数据的缺失可能是不同的,如果因为样本中个别因素的缺失而放弃整个样本,未免代价太大。因此,对舰船装备维修费预测中缺失值主要考虑插值处理技术。
插值是指人为地为缺失的数据插入一个数值,参与运算。根据插值方法的不同,可以有许多种类型。
1)纯随机插值
这是根据统计中的“同等无知原则”,不考虑所获得的数据的情况,仅根据可能的选项,对缺失数据进行随机赋值,例如对于舰船装备使用强度假设有4种可能的情况(高、中、一般、低),缺失样本中具体插什么值应当由计算机随机完成,尽量不要有人为因素介入。纯随机插值没有考虑选项实际的分布情况,如果各个选项的实际比例相差较大,则插值是非常不严格的。
2)就近插值
利用与缺失样本相邻近的样本的值替代缺失样本的真实值,这种插值法的理论依据是相邻样本在某些方面具有相似性,例如同型号舰船装备相邻两次坞修费可能相差并不大。
3)按比例插值
根据提供的其他样本原始数据的情况,对样本中各种情况出现的频率进行统计,然后按各种情况的比例对缺失值进行插值;或者根据各样本中变量之间统计的相对稳定的比例关系,来对缺失值进行插值;或者根据缺失值邻近的两个值以一定的比例进行综合,来对缺失值进行插值等。这种方式纠正了纯随机插值中不考虑原始分布情况的问题,也克服了就近插值只考虑了单边邻近值的缺陷,相对更具有科学性。
4)拟合插值
根据舰船装备维修费影响因素之间的相关性,有针对性地对缺失部分进行预测建模,然后用建立的模型对缺失值进行拟合,用拟合值代替缺失值。这种插值方法有一定量的样本要求。
4.3 冲击扰动数据的预处理技术
针对冲击扰动系统数据序列在建模预测过程中常常出现的定量预测结果与定性分析结论不符的问题,20世纪80年代末,刘思峰教授提出了缓冲算子的概念,可以有效地解决这一问题[17]。下面介绍两种缓冲算子预处理技术:弱化缓冲算子和强化缓冲算子。弱化缓冲算子数据预处理技术,适合于原始数据由于受到冲击扰动而导致其变化速度先快后慢的情况;强化缓冲算子数据预处理技术,适合于原始数据由于受到冲击扰动而导致其变化速度先慢后快的情况。
1)弱化缓冲算子
设 X=(x(1),x(2),Λ,x(n))为系统行为数据序列,令 XD= (x(1)d,x(2)d,Λ,x(n)d)其中,
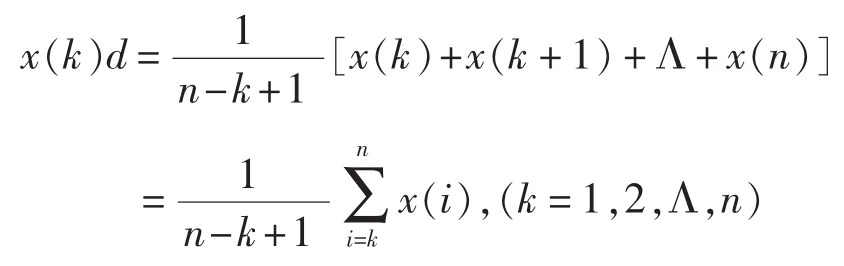
称XD为X的一阶弱化缓冲算子生成序列[18]。
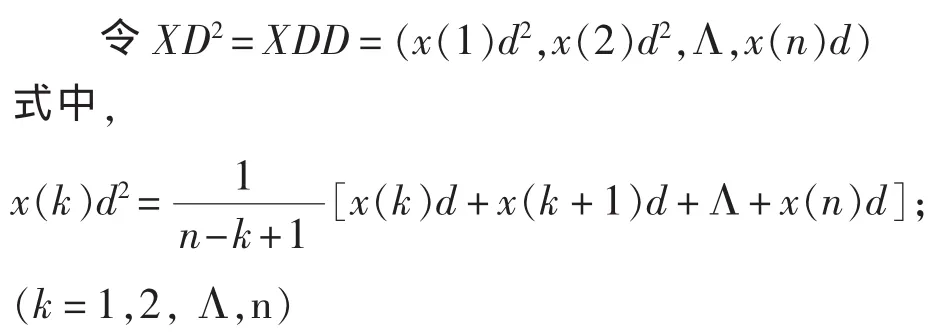
称XD2为X的二阶弱化缓冲算子生成序列。
继续进行弱化缓冲算子运算,可以相应地得到三阶弱化缓冲算子,一直可以作用到r阶算子,分别记为 XD3,…,XDr。
2)强化缓冲算子
设 X= (x(1),x(2),Λ,x(n))为系统行为数据序列,令 XD= X= (x(1)d,x(2)d,Λ,x(n)d),其中

称XD为X的一阶强化缓冲算子生成序列[19]。令XD2= XDD = (x(1)d2,x(2)d2,Λ,x(n)d2),式中
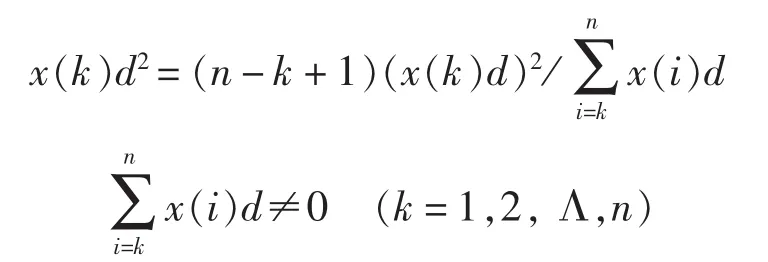
称XD2为X的二阶强化缓冲算子生成序列。
继续进行强化缓冲算子运算,可以相应地得到三阶强化缓冲算子,一直可以作用到r阶算子,分别记为 XD3,…,XDr。
缓冲算子的性质及其证明,见文献[20]。其他形式的强化缓冲算子[21-22]和弱化缓冲算子[23-25]的构建及其证明也得到了进一步的研究。
对于冲击扰动数据的预处理技术,在具体的应用中,首先要考虑在具体的数据收集背景中,冲击对数据变化趋势的影响,进行定性分析,然后再考虑采用哪一种缓冲算子技术进行处理,使这种定性的分析融入到数据序列中,便于进一步的定量分析,实现定性与定量的综合。
4.4 不一致数据的预处理技术
笔者认为,舰船装备维修费原始数据的不一致主要表现为定性信息与定量数据的不一致、极端样本数据与一般样本数据的不一致、原始数据量纲的不一致。下面分别针对这几种情况,介绍相应的数据预处理技术。
1)定性信息的量化处理
在收集到的舰船装备维修费原始数据中,某些变量的数据可能会存在一些主观的判断,对于这些主观的判断需要将其转化为量化的数据,才能够进行进一步的预测模型的分析。
(1)统计近似处理
某些舰船装备维修费影响因素,尽管难以收集到直接的定量数据,但是可以通过其他相关数据的统计,近似地得到相应的量化信息,这种量化处理方式,我们称其为统计近似处理。如维修地区的差异对舰船装备维修费的影响的量化处理。
(2)模糊隶属度函数
某些舰船装备维修费影响因素,收集到的数据只是一些定性上的判断,这些判断可以划分为不同的等级。对于这种情况,我们可以采用设定模糊隶属度函数的方式,将其转化为明确的定量数据。如使用强度、维修任务的量化处理。
(3) 专家打分
有时某些影响因素很难或根本不能用适当的统计数据来衡量其优劣,也难以明确地将其划分为不同的等级,就可以采用专家打分的方式来对其进行量化处理。如舰船装备维修费预测中的维修制度的量化处理。
2)数据的无量纲化处理
影响舰船装备维修费的因素很多,不同的影响因素从不同的侧面反映了舰船装备维修费的大小,由于大部分影响因素都具有各自不同的度量单位,导致这些因素之间不具有可比性,不利于比较它们对舰船装备维修费影响的分析;此外,有些预测方法对输入的变量具有一些特殊的要求,如神经网络预测。下面分别介绍几种常用的无量纲化处理技术。
(1)标准差标准化
标准差标准化处理可以使得各个变量数据的均值为0,标准差为1。处理公式为:

(2)极差正规化
极差正规化处理可以使得每个变量的最大值为1,最小值为0。处理公式为:
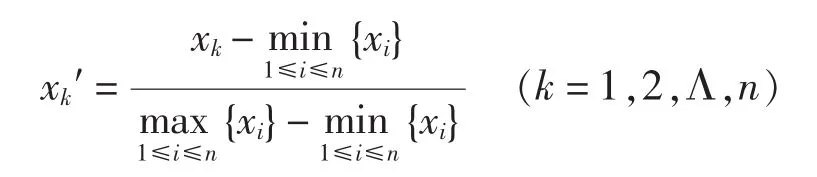
(3)数据百分化
数据百分化就是计算各个变量的百分比,处理后变量的和为1。公式为:
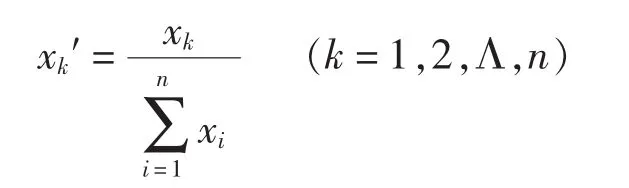
(4)向量规范化
向量规范化处理也是线性变化,处理后的变量满足向量的模为1。
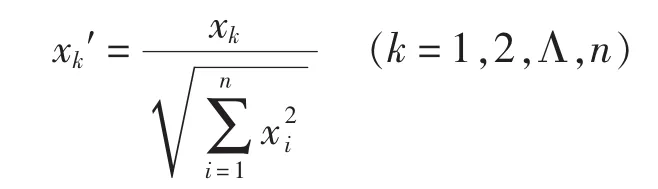
以上几种数据的无量纲化处理技术各有特点,在舰船装备维修费预测过程中,可以根据不同方法的要求,选择合适的方法进行处理。
3)极端样本数据的处理
有些时候各个样本的原始数据往往相差极大,或者由于某种特殊的原因,只有某个样本的原始数据特别突出,如果不作适当的处理,会使整个舰船装备维修费预测结果发生严重扭曲。为此可以采用类似与评分法的统计平均-方法。具体的做法有很多,其中之一是设定一个百分制平均值M,将样本集X中各个方案该变量的均值定位于M,再用下式进行变换[19]:


5 数据预处理举例
为了便于上面所给出的方法在工程实际上得到应用,下面采用模拟的一组舰船装备维修费相关原始数据,并对其进行适当的数据预处理。假定经分析影响某单位舰船装备维修费的主要因素为A和B,且收集到A、B以及舰船装备维修费Y的原始数据如表1所示。

表1 维修费及其影响因素A和B原始数据(单位为基数)
从表1中的数据,我们发现因素A的增长率波动幅度较大,特别是2004年的增长率达到54.08%,而 2003 年的增长率为 9.22%,可以认为这主要是由于噪声引起的,这里采用使用界限平滑法对A进行平滑处理,设定界限范围为±25%,处理后的数据见表2(如处理后2004年的数据为3186× (1+25%)=3823.2)。
同时,在因素B原始数据中,2001、2002和2007年的数据缺失,这里采用相邻两个数据的等比例进行插值,插值后的数据见表2(如处理后2004 年的数据为 0.5×1083+0.5×1920=1501.5)。
对于维修费Y的数据,容易发现其前期增长率较小,而后期增长率较大,可以认为是由于冲击的扰动所致,这里采用一阶强化缓冲算子对其进行处理,处理后的值见表2(如处理后2004年的数据为(8-5+1)×712/(71+77+85+94)≈61.66)。
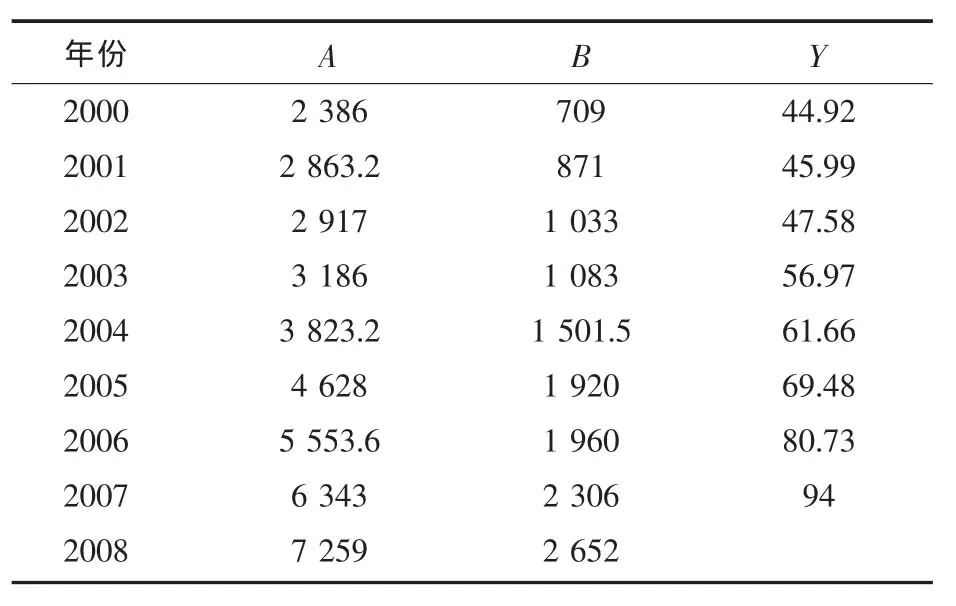
表2 预处理后的数据(单位为基数)
经过上述数据的预处理,表2中的数据已可以用于舰船装备维修费的预测。此外,根据某些预测方法(如神经网络方法)的要求,有时还需要对表2中经过预处理后的数据进行无量纲化处理,这里采用向量规范化方法进行处理,见表3。
如2004年Y的数据计算如下:


表3 数据的无量纲化处理
6 结束语
本文根据舰船装备维修费的特点,将原始数据分为基础数据,使用数据,维修数据和宏观经济数据,并汇总了各种数据收集的来源。根据不同舰船装备维修费预测方法对输入数据的要求以及收集到数据自身的特点,分析了原始数据可能存在影响预测效果的一些问题,根据舰船装备维修费预测的需要,针对每一种问题提供了相应的几种数据预处理技术,通过预处理后的数据可以为舰船装备维修费预测提供良好的数据基础,更好地保证预测效果。同时,本文归纳的各种舰船装备维修费数据预处理技术,也可以推广用于其他预测过程中存在类似问题的数据预处理中。
[1]张伟,顾朝林.城市与区域规划模型系统[M].南京:东南大学出版社,2000.
[2]RICARDO J N,SILVA da B,FIGUEIREDO H,et al.E-valuation of sample processing and sub-sampling performance[J].Analytica Chimica Acta,2003,477:169-185.
[3]AZZOUZ T,PUIGDOMÉNECH A,ARAGAY M,et al.Comparison between different data pre-treatment methods in the analysis of forage samples using near-infrared diffuse reflectance spectroscopy and partial least-squares multivariate calibration method[J].Analytica Chimica Acta,2003,484:121-134.
[4]GABRIELSSON J,JONSSON H,AIRIAU C,et al.OPLS methodology for analysis of pre-processing effects on spectroscopic data[J].Chemometrics and Intelligent Laboratory Systems,2006,84:153-158.
[5]PAPADOKONSTANTAKIS S, MACHEFER S, SCHNITZLEIN K,et al.Variable selection and data pre-processing in NN modelling of complex chemical processes[J].Computers and Chemical Engineering,2005(29):1647-1659.
[6]YAMAUCHI Y,NAKAMURA A,KOHNO I,et al.Quasiflow injection analysis for rapid determination of caffeine in tea using the sample pre-treatment method with a cartridge column filled with polyvinylpolypyrrolidone [J].Journal of Chromatography A,2008,1177:190-194.
[7]IDBORG H,ZAMANI L,EDLUND P O,et al.Metabolic fingerprinting of rat urine by LC /MS Part 2.Data pretreatment methods for handling of complex data[J].Journal of Chromatography B,2005,828:14-20.
[8]GNANI D,GUIDI V,FERRONI M,et al.High-precision neural pre-processing for signal analysis of a sensor array[J].Sensors and Actuators B,1998,47:77-83.
[9]KUZ'NIAR K,WASZCZYSZYN Z.Neural analysis of vibration problems of real flat buildings and data pre-processing[J].Engineering Structures,2002,24:1327-1335.
[10]HARLEY M D,TURNER I L.A simple data transformation technique for pre-processing survey data at embayed beaches[J].Coastal Engineering,2008,55:63-68.
[11]安淑芝.数据仓库与数据挖掘[M].北京:清华大学出版社,2005.
[12]ESEN H,INALLI M,SENGUR A,et al.Forecasting of a ground-coupled heat pump performance using neural networks with statistical data weighting pre-processing[J].International Journal of Thermal Sciences,2008,47:431-441.
[13]张文哲,陈刚,吴迎霞.基于小波理论对负荷预测中不良数据的处理[J].重庆大学学报,2004,27(6):77-81.
[14]韦钢,王飞,张永健,等.负荷预测中历史数据缺损处理[J].电力科学与工程,2004(1):16-19.
[15]TERABE M,WASHIO T,MOTODA H,et al.Attribute generation based on association rules [J].Knowledge and Information Systems,2002(4):329-349.
[16]胡上序,陈德钊.观测数据的分析与处理[M].杭州:浙江大学出版社,1996:85-106.
[17]刘思峰.冲击扰动系统预测陷阱与缓冲算子[J].华中理工大学学报,1997,25(1):25-27.
[18]党耀国,刘思峰,刘斌,等.关于弱化缓冲算子的研究[J].中国管理科学,2004,12(2):108-111.
[19]党耀国,刘斌,关叶青.关于强化缓冲算子的研究[J].控制与决策,2005,20(12):1332-1336.
[20]刘思峰,党耀国,方志耕.灰色系统理论及其应用[M].第 3 版.北京:科学出版社,2004:26-49.
[21]崔杰,党耀国.一类新的弱化缓冲算子的构造及其应用[J].控制与决策,2008,23(7):741-744,750.
[22]关叶青,刘思峰.关于弱化缓冲算子序列的研究[J].中国管理科学,2007,15(4):89-92.
[23]谢乃明,刘思峰.强化缓冲算子的性质与若干实用强化算子的构造[J].统计与决策,2006(4):9-10.
[24]关叶青,刘思峰.强化缓冲算子序列与m阶算子作用研究[J].云南师范大学学报,2007,27(1):32-35.
[25]关叶青,刘思峰.基于辅助函数的强化缓冲算子及其作用[J].统计与决策,2007(6):20-21.
Data Pre-Processing Techniques for Maintenance Cost Prediction of Ship Equipment
Xie Li1 Wei Ru-xiang1 Yu Wei-zong2 Li Li3
1 Department of Economic Management,Naval University of Engineering,Wuhan 430033,China
2 Finance Affair Office of the 92848thUnit of PLA,Dalian 116041,China
3 The 91224thUnit of PLA,Shanghai 200235,China
To collect data precisely and adequately is key concern to the maintenance cost prediction of ship equipment.This paper incorporates pre-processing techniques to deal with the cost prediction-related data.As a wide range of data will affect the prediction, data are to be categorized into different groups, such as basic data, operational data, maintenance data and macroeconomic data.However, by what means data acquisition can be achieved efficiently should be confirmed.The original data from different sources will likely to be of noise, default or abnormity and discrepancy.Various pre-processes are needed to handle these data respectively.The pre-processed data may provide a good basis for the maintenance cost prediction and improving the efficiency.
ship equipment; maintenance cost prediction; data pre-processing
U672.7
A
1673-3185(2010)06-87-06
10.3969/j.issn.1673-3185.2010.06.018
2009-09-07
海工自然科学基金(HGDQNJJ041)
谢 力(1980- ),男,博士研究生。 研究方向:系统工程,装备经济管理。E-mail:xieli_hg@ yahoo.com.cn
