基于逻辑回归的电子企业员工工作满意度研究
2010-02-26李霞
李霞
(南开大学 周恩来政府管理学院,天津 300071)
一、引 言
工作满意度是组织行为研究中的一个重要概念,是员工对自己的工作所抱有的一般性的满足与否的态度。多数学者发现工作满意度与离职呈负相关,与留任倾向呈正相关,与工作绩效呈正相关,所以工作满意度常被拿来作为离职和工作绩效的预测变量。研究员工的工作满意度,对于管理者及早发现人力资源管理中的问题、调整人力资源管理策略、提高人力资源管理的效率具有重要意义。
在工作满意度的量化研究中,测量工作满意度有两种方式:一种设计为连续变量,另一种设计为非连续变量。作为非连续变量测量时,常把工作满意度设计为二分类变量(如“满意”和“不满意”)或顺序变量(如“非常满意,比较满意,一般,比较不满意,非常不满意”)来编制量表。把工作满意度设计成连续变量还是非连续变量取决于研究的实际需求,但是有些学者怯于对顺序变量的处理,常避免使用顺序因变量,或把顺序变量作为分类变量来对待,甚至把它们作为等距变量来处理,从而导致错误的结论并损失变量的顺序等级所携带的大量有价值信息。因此,本文概略考察了近年发展起来的多分类顺序因变量Logistic回归分析(Ordinal Regression),并用该方法研究电子企业员工的工作满意度并建立预测模型。
二、资料与方法
(一)研究背景及变量
本课题组在天津市电子工业协会的支持下,对天津电子企业按照方便抽样的方法抽出600位员工进行问卷调查,其中有效问卷为500份。由于工作满意度不仅受有关工作内容、工作条件、工作环境等情境因素的影响,同时还受个体特质因素的影响。此外,人口统计学特征不同,也会对工作满意度产生不同的影响①。因此,本研究用个体特征变量和工作特性变量对工作满意度的影响情况进行考察,并用顺序逻辑回归分析法建立影响因素对工作满意度的预测模型。本研究中有关变量如下:
因变量为工作满意度。测量题目为:您对现在的工作满意吗?选项为:(1)非常满意或比较满意,(2)一般,(3)不太满意或非常不满意。该变量记为Y(非常满意或比较满意,Y=1;一般,Y=2;不太满意或非常不满意,Y=3)。
预测变量分别为:性别Sex(男=1;女=2)、年龄Age(30岁以下=1;30岁~39岁=2;40岁~49岁=3;50岁以上=4)、学历Education(初中及以下=1;高中和中专=2;大专=3;大学及以上=4)、婚姻Marriage(未婚=1;已婚=2)、职位Rank(工人=1;基层管理人员=2;办公室职员=3;中高层管理人员=4)、工龄LService(1年及以下=1;2年~5年=2;6年~9年=3;10年及以上=4)、同比报酬水平Pay(偏低=1;差不多=2;偏高=3)、同事关系RColleague(良=1;中=2;差=3)、上司关系RSupervisor(良=1;中=2;差=3)、时间压力PTime(高=1;中=2;低=3)、精神压力PMental(高=1;中=2;低= 3)、工作自主权Autonomy(高=1;中=2;低=3)。
预测变量均采用直接提问的方式,由被调查者自己回答。如对同事关系的测量为“您觉得您和您的同事关系如何?选项为:(1)良,(2)中,(3)差”。预测变量中,同比工作报酬是指个体的月平均工资与学历及工作经历相仿的朋友相比的结果,时间压力是指工作的量或速度所带来的时间上的紧迫感,精神压力是指工作所带来的厌烦或精神负担,工作自主权是指工作可自由支配的程度。
(二)统计分析方法
本研究用的统计方法主要为:频次分析、卡方分析和顺序逻辑回归。先用卡方分析筛选出关系显著的变量,然后再用顺序逻辑回归对这些变量进行分析。本研究使用的统计软件为SPSS 15.0。下面对本研究使用的核心方法,即顺序逻辑回归分析做简要介绍。
1.模型的基本原理
逻辑回归模型利用的是Logistic函数(即:f (z)=1/(1+e-z))②。若自变量为X,因变量γ为多分类顺序变量,水平数为n,分析时则需要拟合因变量水平数减1(即:n-1)个Logit模型③,即:
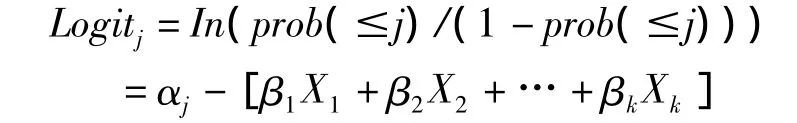
每个Logit方程都有自己的常数项αj,但这些方程中的β系数保持不变,即β的大小与j无关。这说明自变量在每个Logit方程中对因变量的影响是相同的,这是该模型的一个前提假设,所以该模型也被称为“等比例几率模型”③。
顺序逻辑模型(Ordinal Logistic Model)是广义线性模型名下囊括的众多模型之一,其广义线性的基本形式如下③:

在这里γj是因变量的第j类的累积概率,θj是第j类别的阈限值,β1…βk是回归系数,X1…Xk是自变量,k是自变量的个数。这个模型由三部分组成:θj是模型的“阈限成分”(Threshold Componet);由回归系数和自变量构成的部分[β1X1+β2X2+…+βkXk]是模型的“位置成分”(Location Component),位置成分是模型的基本形式,也是我们最常见到的形式,是模型的实质“meat”;方程右式的分母则是模型的“尺度成分”(Scale Component),τ1…τm是尺度成分的系数,Z1…Zm是尺度成分的自变量,m是自变量的个数,m可以小于或等于k。尺度成分在SPSS统计中属于可选部分,它是对位置成分的一种校正形式,即当某自变量X在不同水平的取值有较大差异时的一种校正方法。这里的“link(连接)”表示连接因变量与自变量的某函数,如Logit函数、补充log-log函数,等等③。
2.顺序逻辑回归分析的SPSS操作
顺序逻辑回归分析在SPSS中是采用Ordinal Regression程序,即用PLUM(Polytomous Universal Model的简称)模型来分析顺序数据的。在主菜单中分别点击:Analyze→Regression→Ordinal,即可进入Ordinal Regression对话框。然后设置模型,选择因变量移入Dependent框,选择分类自变量移入Factors框,若有连续自变量则移入Covariates框。在Options对话框的link下拉菜单中选择合适的连接函数。在Output对话框中,选择Test of parallel lines,Estimated response probabilities和 Predicted category,其余为系统默认值,单击Continue返回。最后在Ordinal Regression对话框,单击OK,运行Ordinal Regression过程。值得注意的是,许多学者在处理分类自变量时犯了错误,把分类自变量也放入Covariates框,这样做实际上是把分类自变量作为连续自变量处理了,会导致错误的预测模型。
三、分析过程与结果
(一)变量的描述
工作满意度的3个类别“非常满意或比较满意”、“一般”、“不太满意或非常不满意”所占百分比分别为51.6%、38.7%、9.7%。
样本中,男性占51.4%;未婚者占50.5%;30岁以下占71.0%,30岁~39岁占24.4%;高中和中专学历占53.3%,大学及以学历占18.6%。从职业上看,工人占26.3%,办公室职员占44.8%,基层管理人员占16.0%,中高层管理人员占12.9%。从工龄来看,工龄中 1年及以下占13.9%,2年 ~5年占60.2%,6年 ~9年占23.7%,10年及以上工龄占2.2%。
在自评的工作特性中,同比工资选择“低或偏低、差不多、高或偏高”的百分比分别为55.6%、38.2%、6.2%。同事关系项选择为“良、中、差”的百分比分别为66.0%、32.0%、2.0%。上司关系项选择为“良、中、差”的百分比分别为52.3%、41.8%、5.9%。工作的时间压力项选择“高、中、低”的百分比分别为45.0%、48.0%、7.0%。工作的精神压力项选择“高、中、低”的百分比分别为37.9%、46.4%、15.7%。工作自主权项选项为“高、中、低”的百分比分别为29.0%、32.6%、38.4%。
(二)工作满意度影响因素的方差分析
对人口统计学变量的卡方分析结果表明:性别、年龄、工龄对工作的满意度的影响不显著,学历、婚姻、职位对工作满意度影响显著,具体的卡方分析结果分别为:性别(X2=2.586,df=2,p>0.05)、年龄(X2=4.071,df=6,p>0.05)、工龄(X2=8.012,df=6,p>0.05)、学历(X2= 21.344,df=6,p<0.01)、婚姻(X2=6.249,df= 2,p<0.05)、职位 (X2=13.913,df=6,p<0.01)。
对工作特性变量的卡方分析表明:同事关系(X2=8.176,df=4,p>0.05)、时间压力(X2= 5.460,df=4,p>0.05)对工作的满意度的影响不显著,同比报酬水平(X2=31.688,df=4,p<0.01)、上司关系(X2=36.092,df=4,p<0.01)、精神压力(X2=12.891,df=4,p<0.05)、工作自主权(X2=33.102,df=4,p<0.01)对工作满意度的影响显著。
(三)工作满意度影响因素的回归模型
我们把以上卡方分析显著的人口统计学变量和工作特性变量纳入自变量来建立回归模型,并通过逐步剔除不显著的自变量来精简回归模型。依次剔除的不显著的自变量“职位”和“学历”后,回归模型中的所有自变量都达到显著水平。工作满意度最终模型中的预测变量为:婚姻、同比报酬水平、上司关系、精神压力和工作自主权。模型的条件检验、拟合指标及参数估计结果如下:
1.平行线检验的结果
在顺序逻辑回归分析中,由于每个回归方程中自变量前的回归系数都一样,即一组回归方程为一组平行线,这个前提假设需要检验④。若似然比卡方检验结果p>0.05说明平行假设成立,若p<0.05则假设不成立。在这里,平行线检验的结果为p=0.305(p>0.05),说明平行线假设成立。
2.模型的拟合结果
拟合模型的选择一般基于模型的拟合度统计检验结果。本研究采用Logit连接函数得到模型的拟合结果显示,仅有常数项的无效模型与最终模型的 -2 Log Likelihood之差的卡方值为87.212,差异显著(p=0.00,p<0.05),说明最终模型有意义。Pearson和Deviance是拟合优度统计量,若p>0.05则说明模型拟合良好,若p≤0.05就说明模型拟合效果较差。此处这两个拟合优度指标都大于>0.05,说明最终模型是对测量数据的良好拟合。三种伪-R2值,即Cox and Snell,Nagelkerke和McFadden决定系数,其取值范围为0~1,常用来比较几个不同的模型对同一数据的拟合情况,某一模型的伪-R2值越大就表明该模型对数据拟合得越好。此处的三种伪-R2值都大于0,可以接受。
3.模型的参数估计结果
在输出的结果中有参数估计表(Parameter Estimates),该表中的“Threshold”是关于回归方程中的常数项αj的一些指标,该表中的“Location”是关于回归方程中的自变量的一些指标。模型的参数估计结果见表1所示。
从显著性水平看,婚姻、同比报酬水平、上司关系、精神压力、工作自主权对工作满意度的作用在统计上都达到显著水平。
表1中分类预测变量前的负号“-”表明该变量的该类与工作满意度的较小的分值相联系。若计算e-β,即exp(-β),也即OR(Ratio of the Odds),能显示变量的该类与参照类相比选择工作满意度较小分值的几率。对婚姻状况而言,“婚姻=1.00”的系数为“0.592”,其符号为正,说明“未婚”的员工比“已婚”的员工更倾向于选择“不满意或非常不满意”,而exp(-0.592)= e-0.592=0.55,则表明当其他变量保持恒定时,“未婚”的员工选择“非常满意或满意”的几率是“已婚”员工的0.55倍。同样的,从表1的结果能看出:当其他的变量保持恒定时,“同比报酬水平”偏低的员工对工作感到非常满意或比较满意的几率是“同比报酬水平”偏高的员工的0.4倍;“上司关系”为良的员工对工作感到非常满意或比较满意的几率是“上司关系”为差的员工的4.64倍;“精神压力”高的员工对工作感到非常满意或比较满意的几率是“精神压力”低的员工的0.44倍;“工作自主权”高的员工对工作感到非常满意或比较满意的几率是“工作自主权”低的员工的2.42倍。

表1 回归模型的参数估计结果
4.回归模型及应用
根据以上参数估计结果,可以写出以下回归方程:
Logit1= -0.011-(0.592*Marriage1+ 0.927*Pay1-0.132*Pay2-1.535*RSupervisor1- 0.844*RSupervisor2 + 0.818*PMental1 + 0.667*PMental2 - 0.884*Autonomy1 -0.178*Autonomy2)
Logit2 =2.509 - (0.592*Marriage1 + 0.927*Pay1-0.132*Pay2-1.535*RSupervisor1- 0.844*RSupervisor2 + 0.818*PMental1 + 0.667*PMental2 - 0.884*Autonomy1 -0.178*Autonomy2)
对于每一个自变量或说每一个记录case,因变量的累积预测概率的计算公式为③:
prob(j)=1/(1+e-(aj-(β1X1+β2X2+…+βkXk)))= 1/(1+e-logit(j))
那么对于任何一个没有参与调查的员工,我们可以通过上式预测其工作满意度的状态。例如,假定某个员工具有以下特征:Marriage=2,Pay=2,RSupervisor=2,PMental=2,Autonomy=3,把这些自变量的取值代入Logit1方程中得:Logit1=-0.011-(-0.132-0.844+0.667)=0.298,则第一等级的累积概率 Prob(1)=1/(1+ e-0.298)=0.57;类似的,可以计算出第二等级的累积概率Prob(2)=0.94。
那么从上面的累积概率中可以轻易地计算出每一等级的独立概率。第一等级的独立概率就等于prob(1)=0.57;第二等级的独立概率等于prob(2)-prob(1)=0.37;第三等级的独立概率等于1-prob(2)=0.06。由于在工作满意度的三个类别中第一类的预期概率值最大,故该员工的预测分类为第一类,也就是说可以预测该员工对工作感到非常满意或比较满意。
四、结 语
从以上调查结果的分析来看,只有少数电子企业员工(9.7%)对工作感到非常不满意或比较不满意,近一半员工(51.6%)对工作非常满意或比较满意。约一半(55.6%)电子企业员工认为自己与类似学历或工作经验的朋友相比月平均工资偏低。对大部分员工而言,拥有良好或中等状况的同事关系和上司关系,并且其同事关系好于上司关系。有45.0%的员工觉得工作的时间压力过大,有37.9%的员工觉得工作的精神压力过大,有38.4%的员工觉得工作的自主权太低。从显著性水平看,婚姻、同比报酬水平、上司关系、精神压力、工作自主权都是工作满意度的有力预测指标,以上建立的回归方程预测模型可对每个员工的工作满意度做较好的预测。
另外,在利用SPSS进行顺序逻辑回归分析时,注意的是在运行该程序之前,我们需要先考察是否有数据单元格为空或极端小的情况。若有,则模型的运行就可能存在困难。而当自变量为连续变量时,有关空单元格的警告则可置之不理⑤。在该研究中,我们对分类自变量与因变量做了交叉分析来考察数据单元格,单元格为空或极端小值的情况占极小比率,没有影响模型的运行。
在利用顺序逻辑回归分析管理问题中的因变量时还需要注意的是:对参数估计结果的解释不像直线回归那么直接,需要格外谨慎。对于SPSS输出的参数估计表来说,若是连续自变量,回归系数前的“+”号(“-”号)表示自变量与结果变量之间呈正相关(负相关),其值的增加预示着因变量进入更高累积等级的概率的增加。对于分类自变量而言,某一水平的系数越大,表示因变量进入更高累积等级的概率越大,分类自变量某水平前回归系数的符号的“正”“负”取决于该水平与参照水平相比对因变量的影响。例如对于一个二分类自变量,若系数为正,则表明因变量较大的分值与自变量第一类相联系;若系数为负,表明因变量较小的分值与自变量第一类相联系。与较大分值相联系,意味着因变量取较小分值的累积概率较小。
总而言之,顺序逻辑回归是对顺序因变量的一种深入分析,不仅可以分析预测变量对因变量的影响是否显著,还可以建立量化的预测模型,对人力资源管理来说是一种十分有用的方法。拙文应用该方法研究了人力资源管理中的一个重要变量“工作满意度”,借此推动该方法的正确使用。此外,由于样本是本课题组在天津市电子企业中采取方便抽样的方式抽取的,该模型的外部效度尚有待验证,在利用时需谨慎。
注释:
①黄春生.工作满意度、组织承诺与离职倾向相关研究[D].厦门:厦门大学博士学位论文,2004.
②王黎明,陈 颖,杨 楠.应用回归分析[M].上海:复旦大学出版社,2008.
③Norusˇis,J Marija.Chapter 4 ordinal regression in SPSS 17.0 Advanced Statistical Procedures Companion[M]. Prentice Hall,2008.
④P McCullagh.Regression Models for Ordinal Data[J].Journal of the Royal Statistical Society,1980,(42):109-142.
⑤SPSS,Inc.Ordinal Regression Analysis,SPSS Advanced Models 10.0[M].Chicago,IL.,2002.
