全文检索的原理与实现探讨
2009-10-13满鹏
满 鹏
〔摘 要〕本文主要在介绍全文检索的概念和原理的基础上,论述了全文检索的几种主要技术,并给出了逆向最大分词法的具体实现。
〔关键词〕全文检索;搜索引擎;中文分词
〔中图分类号〕TP31 〔文献标识码〕A 〔文章编号〕1008-0821(2009)07-0138-03
Discussion on Principle and Implementation of Full Text SearchMan Peng
(Computer Center,Changchun University,Changchun 130022,China)
〔Abstract〕Based on the introduction of concept and theory of full text search,in this paper,it expounded a few primary technologies in full text search,proposed an implementation of reverse direction maximum word-dividing.
〔Key words〕full text search;search engine;chinese division
全文检索是对大数据文本进行索引,在建立的索引中对要查找的单词进行搜索,定位哪些文本数据包括要搜索的单词。因此,全文检索的全部工作就是建立索引和在索引中搜索定位,所有的工作都是围绕这两方面展开的。下面本文就对它的原理、技术和实现,一一加以分析与探讨。
1 原 理
全文搜索的典型代表是网络蜘蛛程序(网络机器人),可以通过对它的工作过程分析,分析出全文搜索的技术原理。网络蜘蛛程序是一个自动搜索程序,可自动在互联网上搜索信息。并且查看页面的内容,然后从中找到相关的信息,最后再从该页面的所有链接出发,继续寻找其它相关的信息。网络蜘蛛不断的重复这个过程,并把经过的所有网页收集到搜索引擎所在的服务器中,这个过程一般采用的是广度优先算法。当网络蜘蛛收集到信息后,接下来要进行以下几个方面的工作:
1.1 建立索引数据库
当网络蜘蛛存储网页后,再由自定义程序对服务器中保存的网页进行分析,提取相关网页的URL、编码类型、关键词位置、生成时间、大小和与其他网页的链接关系等。根据网站自定义的相关度算法进行运算,最后得到相关度信息,然后用这些相关信息建立网页索引数据库。
1.2 在索引数据库中搜索
当用户输入搜索内容,单击搜索按钮后,系统自定义程序开始根据相关技术,分析用户的搜索内容,然后从网页索引数据库中,找到包含用户搜索内容的所有相关网页。
1.3 对搜索结果进行排序
在网站自己的索引库中,对网页的每个关键词都有记载,根据关键词的搜索次数以及在网页中出现的次数等分析要素,对搜索到的结果进行排序,也可以自己定义排序处理程序。最后将处理好的结果展现出来。
2 技 术
下面对于全文搜索中的主要几种技术,加以分析探讨,以便为全文搜索的技术实现提供某种思路。
2.1 中文分词技术
英文是以词为单位的,词与词之间上靠空格隔开,而中文是以字为单位,句子中所有的字连起来才能描述一个意思。例如,英文句子I am Chinese,翻译成“我是中国人”。计算机可以很简单的通过空格知道Chinese是一个单词,但是不能很明白“中”、“国”两个字合起来才表示一个词。把中文的汉字序列切分成有意义的词,就是中文分词。现有的分词算法有3种:基于字符串匹配的分词算法、基于理解的分词算法和基于统计的分词算法。本文不对此一一分析,请读者自行查阅相关文献。
2.2 排序技术
排序技术类似于曝光率,谁出现的次数最多,谁排在前面。在互联网上,链接就相当于“曝光”,在B网页中链接了A,相当于在谈话中提到了A,如果在C、D、E、F中都链接了A,那么说明A网页是最重要的,A便会排在最前面。另外还有HillTop算法等。
2.3 网络蜘蛛
网络蜘蛛即Web Spider,是一种很形象的网页搜索技术。把互联网比喻成一个蜘蛛网,那么Spider就是网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其他链接地址,然后通过这些链接地址寻找下一个网页,这样一直循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当成一个网站,那么网络蜘蛛就可以用这个原理把互联网上所有的网页都抓取下来。在抓取网页的时候,网络蜘蛛一般有两种算法:广度优先和深度优先。广度优先是指网络蜘蛛会先抓取起始网页中链接的所有的网页,然后再选择其中的一个链接网页,继续抓取在此网页中链接的所有网页。这是最常用的方式,因为这个方法可以让网络蜘蛛并行处理,提高其抓取速度。深度优先是指网络蜘蛛会从起始页开始,一个链接一个链接跟踪下去,处理完这条线路之后再转入下一个起始页,继续跟踪链接。这个方法的优点是比较容易设计。
3 实 现
建立全文索引中有两项非常重要:一个是如何对文本进行分词;一个是建立索引的数据结构。
3.1 如何分词
分词的好坏关系到查询的准确程度和生成索引的大小。在中文分词发展中,早期经常使用分词方式是二元分词法,该方法的基本原理是将包含中文的句子进行二元分割,不考虑单词含义,只对二元单词进行索引。因此该方法所分出的单词数量较多,从而产生的索引数量巨大,查询中会将无用的数据检索出来,好处是算法简单不会漏掉检索的数据。之后又发展出最大匹配分词方法,该方法又分为正向最大分词和逆向最大分词。其原理和查字典类似,对常用单词生成一个词典,分析句子的过程中最大的匹配字典中的单词,从而将句子拆分为有意义的单词链。最大匹配法中正向分词方法对偏正式词语的分辨容易产生错误,比如“首饰和服装”会将“和服”作为单词分出。本文实现的是逆向最大分词方法,该分词方法较正向正确率有所提高。最为复杂的是通过统计方式进行分词的方法。该方法采用隐式马尔科夫链,也就是后一个单词出现的概率依靠于前一个单词出现的概率,最后统计所有单词出现的概率的最大为分词的依据。这个方法对新名词和地名的识别要远远高于最大匹配法,准确度随着取样文本的数量的增大而提高。二元分词方法和统计方法是不依赖于词典的,而最大匹配法分词方法是依赖于词典的,词典的内容决定分词结构的好坏。
3.2 索引的结构
索引的数据结构基本上采用倒排索引的结构。全文检索的索引被称为倒排索引,之所以称为倒排索引,是因为将每一个单词作为索引项,根据该索引项查找包含该单词的文本。因此,索引都是单词和惟一记录文本的标识是一对多的关系。将索引单词排序,根据排序后的单词定位包含该单词的文本。
3.3 逆向最大分词算法
逆向最大分词的实现算法说明:
(1)读取一整条句子到变量str中,转到(2);
(2)从句子的尾端读取1个字到变量word中,转到(3);
(3)在字典查找word中保存的单词。如果存在则保存word,转到(4),否则转到(5);
(4)如果是字典中最大单词或者超过最大单词数(认定为新词),从句尾去掉该单词,返回(2);
(5)读取前一个字到word中,构成新单词,转到(3)。
假设字典中有如下的单词:
中国
中华民国
国家
人民
民主
在内存中按照如下方式按层排列:其中每一个方块代表一个字,箭头所指向为该单词的前一个字。
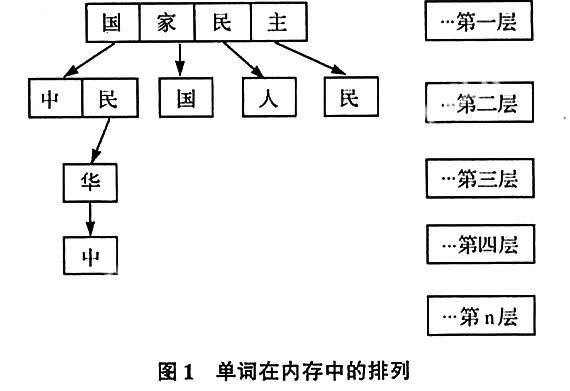
那么,如查找单词“中华民国”:(1)首先在第一层中使用二分法找到“国”字,获得“国”下层的数组“中民”;(2)在该层使用二分法查找“民”,获得“民”下层的数组“华”;(3)在该层使用二分法查找“华”,获得“华”下层的数组“中”;(4)最后在该层找到“中”,至此匹配完毕。
3.4 索引的格式
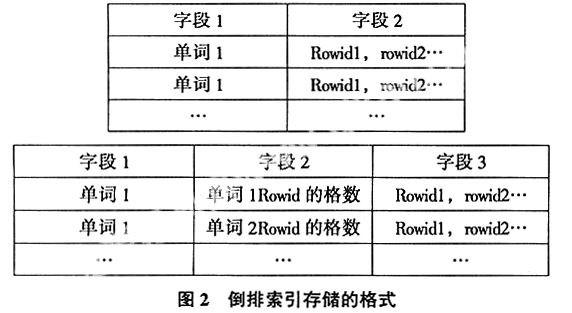
索引的格式是倒排索引的格式,也就是一个单词对应若干个文本表示。比如,建立全文索引的对象是rec中的字段,生成倒排索引使用数据库中的b树进行存储。在数据库是对某个字符字段进行全文索引,因此,rec的rowid作为该rec上该field的标示是必须要被记录的。因此倒排索引存储的格式如下:
字段1字段2单词1Rowid1,rowid2…单词1 Rowid1,rowid2………字段1字段2字段3单词1单词1Rowid的格数Rowid1,rowid2…单词1单词2Rowid的格数Rowid1,rowid2…………
3.5 全文索引的查询
全文的索引查询首先将对要查询的单词进行分词,然后在存储倒排索引的b树中将包含这些单词的rowid全部查找出来,并根据这些rowid在存储实际数据的b树中,将包含这些数据的行过滤出来。
4 结 论
本文简单地介绍了全文检索技术的基本概念、原理和相关技术,并给出了逆向最大分词技术的具体实现。随着搜索引擎市场空间越来越大,搜索引擎也分得越来越细,搜索需求不可能都一样,搜索引擎会不断细化,各具特色的搜索引擎也陆续出现。本文中的所实现的技术,在这些不同的应用领域中,都将会有一定的使用价值。
参考文献
[1]李盛韬.基于主题的Web信息采集技术研究[D].中国科学院计算技术研究所硕士毕业论文,2002.
[2]许洪波.大规模信息过滤技术研究及其在Web问答系统中的应用[D].中国科学院计算技术研究所博士毕业论文,2003.
[3]谭建龙.串匹配算法及其在网络内容分析中的应用[D].中国科学院计算技术研究所博士毕业论文,2003.
[4]Winter.中文搜索引擎技术揭密:系统架构[EB].中文全文检索网,2004.
[5]Lawrence S,Giles C L.Searching the world wide web[J].Science,1998,280(4).
[6]http:∥www.bhasha.com[EB].2007.5.
[7]Hendler J.Agents and the Semantic Web.IEEE Intelligent Systems,2001-03-04.
[8]T Berners Lee.J Handler.O Lassila,The Semantic Web.Scientific America,May 2001:219.
[9]Cardie C.Empirical methods in information extraction.AI Magazine,1997,18(4).
[10]HSUC N,DUNG M.Generating finite-state transducers for semi-structured data extraction from the Web[J].Information System,1998,23(8):521-538.
