基于内容和上下文的敏感个人信息实体识别方法
2025-02-15郭群张华熊王波王心怡
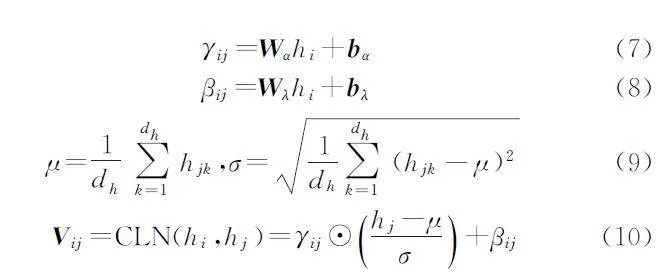
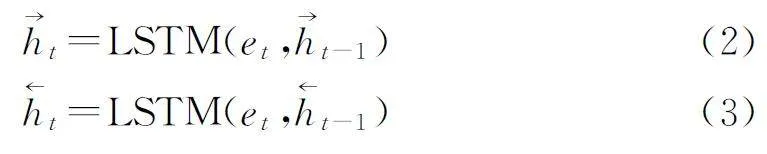

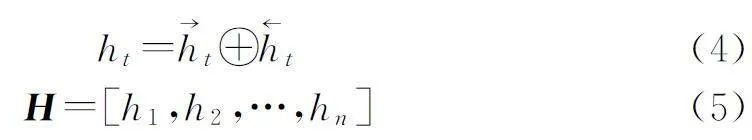
摘 要:针对现有方法对非结构文本中结构复杂的敏感个人信息实体无法有效识别的问题,提出一种基于内容和上下文的敏感个人信息实体识别方法。一方面,利用规则匹配检测具有可预测模式的敏感实体类型;另一方面,构建了一个基于词对关系分类架构(ELECTRA-W2NER,EW2NER)的实体关系分类识别模型,以检测模式复杂的敏感实体类型。EW2NER 使用最新的ELECTRA(Efficiently Learningan EncoderthatClassifies TokenReplacementsAccurately)模型实现词嵌入,并采取实体关系分类架构统一提取扁平型和重叠型的敏感个人信息实体。该模型在中文敏感数据集上取得了97.05% 的F1值,优于ExSense(Extractsensitiveinformationfromunstructureddata)模型。
关键词:敏感信息检测;命名实体识别;模式匹配;深度学习
中图分类号:TP391.1 文献标志码:A
0 引言(Introduction)
近年来,随着社交应用的迅猛发展,处理敏感个人信息的社交应用也呈现指数增长趋势。通过平台中的个人评论内容或生活分享信息(如博客文章、社交媒体动态等),可以直接或间接确认个人身份。个人身份信息泄漏问题会给用户和服务管理者带来法律纠纷与经济损失。事实上,近年来发生的数据泄露所带来的平均经济损失持续攀升[1],凸显出保护个人信息的重要性和紧迫性。
目前,敏感个人信息识别研究主要聚焦于两个核心领域:一是基于数据内容规则的识别方法,二是基于上下文语义的命名实体识别方法。然而,现有基于上下文的敏感实体识别方法对于重叠和非连续型实体无法有效统一识别。综合上述问题,本文根据OHM[2]归纳的敏感信息定义,将敏感个人信息实体类型分为复杂和可预测两种数据模式,并提出了基于内容和上下文的敏感个人信息实体识别方法(ContentandContextualSensitive PersonalInformation Entity Recognition Method,CCSPIER)进行敏感信息检测,具体表述如下:①基于数据内容的正则匹配方法检测具有可预测模式的敏感信息实体,例如身份证号码、手机号码等;②基于上下文语义特征提出一个名为ELECTRA-W2NER(EW2NER)的实体关系分类模型,统一识别扁平、重叠和非连续且模式复杂的敏感实体。
1 相关工作(Relatedwork)
对于敏感信息识别,早期使用基于数据内容特征的识别技术,主要使用关键词字典构造和规则模式匹配等方法对敏感信息进行识别。SHAPIRA等[3]提出了一种数据指纹识别方法,该方法从核心机密内容中提取指纹,同时忽略了文档的非相关部分,提高了机密内容改写的鲁棒性。SHU等[4]提出了一种序列比对技术用于检测复杂的数据泄漏模式,该算法旨在检测长而不准确的敏感数据模式。
基于深度学习的方法是当前敏感信息识别领域的主要方法。李姝等[5]提出一个融合敏感关键词特征的分层BERT(BidirectionalEncoderRepresentationsfromTransformers)模型,通过将敏感关键词特征融合到BERT的输入中,在互联网新闻数据集上取得非常好的效果。GUO等[6]提出了ExSense框架,该框架使用正则匹配和BERT-BiLSTM-Attention模型来识别英文数据中的敏感信息实体。该模型引入了注意力机制,使得LSTM输出的词表示向量更好地结合了上下文语义。郑旭如[7]针对英文数据集i2b2提出charCNN-BERT-CRF模型,通过加入charCNN(Character-levelConvolutionalNeuralNetwork)抽取英文缩写单词形态特征,再与单词上下文语义特征向量拼接作为词最终语义特征,经实验表明,该方法有效缓解了因英文单词构词法而引起的问题。许成[8]提出的基于ELMo(Embeddingsfrom Language Models)与FLAT(Flat-LatticeTransformer)的BiGRU-Flat命名实体识别模型在网络敏感信息主题检测任务中效果突出。
2 敏感信息识别方法(Sensitiveinformationidentificationmethods)
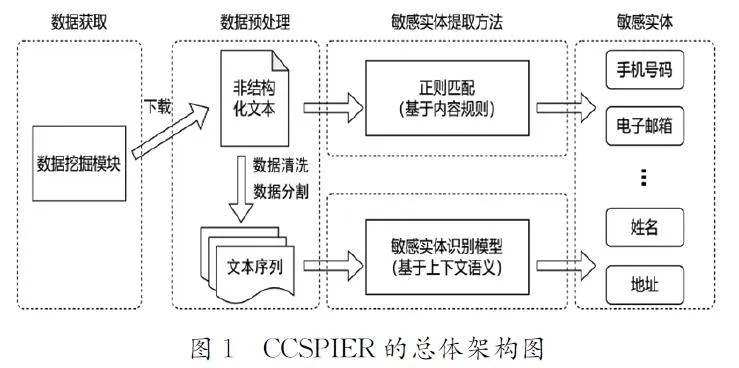
本文提出的基于内容和上下文的敏感个人信息实体识别方法(CCSPIER)的总体架构如图1所示。
CCSPIER方法的敏感实体识别功能由两个部分组成:基于数据内容的正则匹配方法,用于检测具有可预测模式的敏感信息实体;基于上下文语义的敏感实体关系分类识别模型,用于检测模式复杂的敏感信息实体。
2.1 基于数据内容的正则匹配方法
对于具有可预测模式的敏感个人数据,本文采用基于规则匹配的方法进行识别,实体类型与正则表达式如表1所示。
2.2 基于上下文语义的EW2NER模型识别方法
对于模式复杂的敏感实体类型,根据实体内部数据的连续情况可分为扁平实体、重叠实体与非连续实体3种实体类型[9]。例如,“健康状况”类型的“症状”子类型中可能会出现重叠实体和非连续实体,例句如“我的颈椎和腰很痛”中“颈椎痛”和“腰痛”两个非连续的命名实体出现重叠情况。
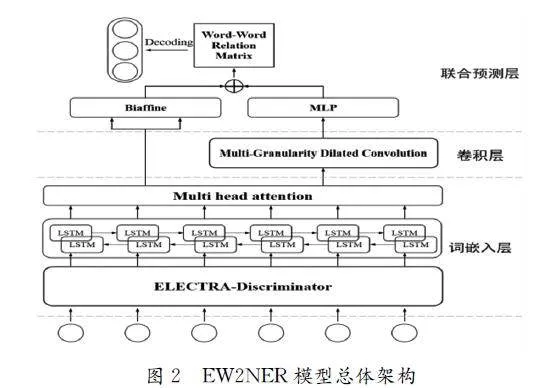
为对上述复杂命名实体类型进行统一识别,本文采用一种名为W2NER[10]的关系分类架构,将命名实体识别看作单词之间的关系分类问题,设计并实现了一个基于实体关系分类的敏感实体识别模型,命名为ELECTRA-W2NER(EW2NER),其模型总体架构如图2所示。
2.2.1 词嵌入层
输入序列为X={x1,x2,…,xn},经过ELECTRA模型学习后,得到包含上下文语义特征的词嵌入表示向量,具体如公式(1)所示:
E=ELECTRA(X)=[e1,e2,…,en] (1)
其中:E∈Rn×d 为ELECTRA模型输出的词嵌入表示向量,n为token长度,d 为ELECTRA模型输出的隐藏向量维度。
词嵌入表示向量E 经过BiLSTM 编码后,分别由前向LSTM与后向LSTM输出拼接得到特征向量H,分别如公式(2)至公式(5)所示:
其中:→ht与←ht为前向LSTM 和后向LSTM 的输出向量,et为向量E 中第t个词向量,⊕为向量拼接操作。
使用多头自注意力机制对特征向量H 根据任务情况进行自适应调整,增强敏感信息相关语义特征的关注度,提高向量的语义表征能力,具体如公式(6)所示:
Eatt=Multihead(H,H,H) (6)
其中,Eatt∈Rn×dh 为词嵌入层最终输出的词嵌入表示向量,dh为向量的隐藏维度。
2.2.2 卷积层
本研究使用的卷积层包含3种模块:条件层归一化模块用于生成词嵌入表示的词对关系网格表示;BERT嵌入样式网格表示构建模块用于丰富词对关系网格表示的隐含特征信息;多粒度膨胀卷积模块用于提取不同距离词对之间的交互表示。
(1)条件层归一化
根据W2NER关于词对关系网格的定义,词对关系网格表示向量为三维矩阵V∈Rn×n×dh ,Vij=(xi,xj)∈Rdh 是关于网格行中词xi隐藏表示hi与网格列中词xj 隐藏表示hj 的词对向量。通过条件层归一化公式(7)至公式(10)计算词对关系表示Vij:
其中:hi作为条件用于条件层归一化中用于生成增益γij和偏置βij,μ 和σ 分别是hi的平均值和标准差,hjk 表示hj的第k 维,☉表示逐位相乘操作,W 与b 为可训练参数矩阵。
(2)BERT嵌入样式网格表示构建
为使模型更全面地捕获序列中的语义信息以及理解任务需求,本模块采用类似BERT模型的3种嵌入向量丰富词对关系网格表示:表示词对关系信息的WordEmbedding、表示每对词之间的相对位置信息的DistanceEmbedding及表示用于区分网格中下三角区域和上三角区域的区域划分信息的RegionEmbedding。将3种嵌入向量进行向量拼接,并使用多层感知机进行特征降维,得到最终带有相对位置信息与区域信息的词对关系网格表示向量C,具体如公式(11)所示:
C=MLP([V;Ed ;Et]) (11)
其中:C∈Rn×n×dC ,dC =dh +dd +dt为复合嵌入表示向量的隐藏维度。
(3)多粒度膨胀卷积
本模块采用多个不同膨胀率(dilated)的二维卷积核在词对关系网格表示向量中进行卷积操作,用于捕获不同距离词对之间的交互表示,具体如公式(12)所示:
Ql=σ(DConvi(C)) (12)
其中:Convi代表膨胀率为l 的膨胀卷积操作,Ql∈Rn×n×dC 表示膨胀率为l 的膨胀卷积输出,σ 是GELU激活函数。经过多粒度膨胀卷积模块可以得到最终的词对关系网格表示Q =[Q1;Q2;Q3]∈Rn×n×3dl,为卷积输出向量的隐藏维度。
2.2.3 联合预测层
文献[10]的研究表明,MLP(MultilayerPerceptron)预测器与双仿射预测器配合使用,可以增强关系分类效果。因此,在小节分别单独使两种预测器计算词对的关系分布,之后将两个关系分布结果相加作为最终的预测结果。
(1)双仿射预测器
在得到词嵌入层输出的词表示向量H 后,将两个E 看作实体关系分类中的头部信息xi与尾部信息xj,分别使用两个多层感知机计算得到头部隐藏向量,分别表示si 与ej;之后使用一个Biaffine公式计算词对(xi,xj)的实体关系分类预测结果y'ij,具体如公式(13)至公式(15)所示:
si=MLP(hi) (13)
ej=MLP(hj) (14)
y'ij=siTUej+W[si;ej]+b (15)
其中:siT为si的转置,U、W 和b都是模型中的训练参数,[;]为拼接操作。
(2)多层感知机
对网格表示Q 直接使用多层感知机计算词对(xi,xj)的实体关系分类预测结果y″ij,具体如公式(16)所示:
y″ij=MLP(Qij) (16)
其中,Qij表示词对(xi,xj)特征向量。
将双仿射预测器得到的y'ij和多层感知机预测器得到的y″ij相加,得到最终实体关系分类预测结果yij,具体如公式(17)所示:
yij=Softmax(y'ij+y″ij) (17)
3 实验(Experiment)
3.1 数据集
为评估本文提出的EW2NER模型在识别扁平敏感个人信息实体方面的性能,本小节使用公开数据集Resume[11]进行测试。Resume数据集是从中国股市上市公司的高级管理人员简历中收集得到的,共包含了1027份简历样本。其中,实体内容均属于模式复杂的敏感个人信息实体类型,与本文的研究目标高度契合。Resume数据集的标注实体共有人名、国籍、地名、民族、专业、教育背景、组织名和职称8种类别。在实体数量的分布上,训练集包含了13438个实体,验证集则包含了1497个实体,而测试集则包含了1630个实体。
同时,为了评估本文提出的EW2NER模型对重叠型实体的识别效果,本小节使用CMeEE-v2(ChineseMedicalEntityExtractionEvaluationDatasetversion2)[12]数据集,该数据集由临床病例、入院记录、检验报告等医学非结构化文本构成,命名实体共划分为九大类,包括疾病、临床表现、药物、医疗设备、医疗程序、身体、医学检验项目、微生物类及科室。其中,任一类实体中都有可能嵌套其他类型的实体。其中,疾病、临床表现、药物等实体类型隶属于“健康状况”敏感个人信息实体类型。CMeEE-v2数据集的语句量分布如下:训练集包含了14965条语句,验证集包含了2493条语句,测试集包含了2493条语句。
3.2 实验评价指标
实验的评价指标包括查准率(P)、召回率(R)和F1值(F1)3个。这些指标用于衡量分类模型的性能。具体定义如下:真正例(TP)是指将正例预测为正例,假反例(FN)是指将正例预测为反例,假正例(FP)是指将反例预测为正例,真反例(TN)是指将反例预测为反例。查准率、召回率及F1值的计算公式如公式(18)至公式(20)所示:
P=TP/(TP+FP) (18)
R=TP/(TP+FN) (19)
F1=(2×P×R)/(P+R) (20)
3.3 实验参数设置
实验使用到的ELECTRA模型和BERT模型均为哈工大讯飞联合实验室(HFL)提供的中文预训练模型,分别为chinese-electra-180g-base-discriminator与chinese_wwm_L-12_H-768_A-12预训练模型,两种模型的网络结构均为12层、隐藏维度均为768。
3.4 实验结果与分析
3.4.1 扁平型实体识别性能对比实验
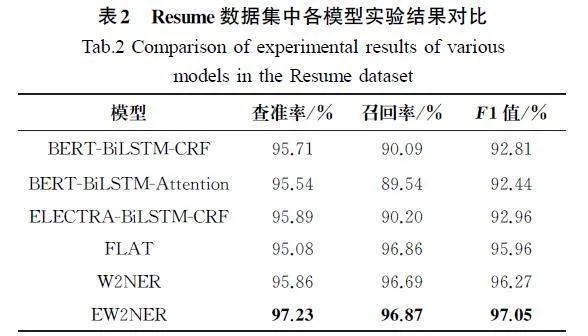
为了评估EW2NER模型对扁平型敏感个人信息实体的识别性能,本文选择BERT-Biaffine、BERT-BiLSTM-Attention、ELECTRA-BiLSTM-CRF、FLAT 以及W2NER 对照模型与EW2NER模型在Resume数据集上进行对比实验。Resume数据集中各模型实验结果对比如表2所示。
从表2中的实验结果可知,EW2NER模型相较于其他对照模型,在查准率、召回率和F1值上均为最好且F1值达到了97.05%,说明EW2NER模型能够有效捕获并理解非结构化文本中的敏感个人信息相关语义特征,并且经过ELECTRA模型得到的词嵌入表示内含更丰富的语义特征,有效提高了模型对复杂实体类型的识别性能。同时,可以看出命名实体关系抽取识别模型(W2NER和EW2NER)的各项性能指标均优于序列标注识别模型(表2中的前4种模型)的相关指示,说明与序列标注式模型相比,实体关系抽取式命名实体识别模型更适用于本文研究的敏感个人实体识别任务。
3.4.2 重叠型实体识别性能对比实验
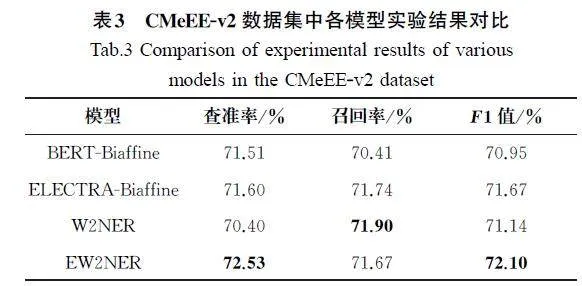
为评估EW2NER模型对于重叠型实体的识别性能,与目前主流的3种可识别重叠型实体的模型进行对比实验。CMeEE-v2数据集中各模型实验结果对比如表3所示。
分析表3中的实验结果可知,在CMeEE-v2数据集中,本文提出的EW2NER模型的召回率略低于W2NER模型的召回率,但查准率与F1值均高于其他对照模型的对应指标,说明文本提出的EW2NER模型能有效地识别出非结构化文本中的重叠型敏感个人信息实体。
3.4.3 单一方法与混合方法性能对比实验
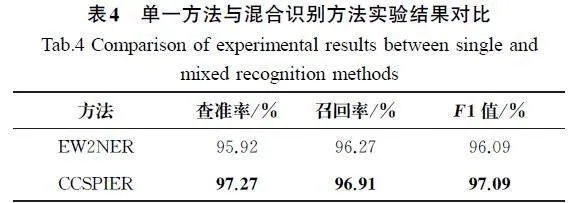
本实验的主要目的是评估CCSPIER混合识别方法(结合正则匹配和EW2NER的识别方法)相较于单独使用EW2NER的识别方法,在敏感实体识别任务上是否具有优势。本文基于Resume数据集,根据表1中整理的正则表达式,为每一种模式可预测的敏感个人信息实体各生成400个符合规则与不符合规则的伪数据,共计4800个新实体数据,在不破坏原数据集语义的情况下分散插入语句中。对于单独使用EW2NER的识别方法,所有实体都统一标记为敏感实体(包括基于规则匹配的敏感个人信息实体)用于模型训练学习。表4为单一方法与混合识别方法实验结果对比。
根据表4中的实验结果可以看出,CCSPIER混合识别方法的各项性能评估指标均高于单独使用EW2NER的识别方法的相关指标。相较于单独使用EW2NER的识别方法,本文提出的CCSPIER混合识别方法能更有效地识别非结构化文本中的敏感信息实体。
4 结论(Conclusion)
本文深入探索了敏感个人信息实体的识别问题,根据数据模式特征将其精细划分为可预测模式与复杂模式两大类,并提出了一种基于内容和上下文的敏感实体混合识别方法(CCSPIER)。CCSPIER结合基于内容的正则匹配方法,实现对具有可预测模式的敏感实体类型的检测;利用基于上下文特征的EW2NER实体关系分类模型检测实体结构复杂的敏感实体类型。为了验证EW2NER模型的有效性,分别进行了扁平型与重叠型敏感实体的识别比较实验,结果显示该模型能有效统一识别各种结构的敏感实体。此外,对敏感实体数据集的实验表明,CCSPIER混合识别方法相较于单独使用EW2NER的识别方法更有效,达到了97.09%的F1值。综上所述,本文提出的CCSPIER混合识别方法可以从非结构化数据中有效提取敏感信息实体。
参考文献(References)
[1]IBM.2023年数据泄露成本报告[EB/OL].(2023-12-29)[2024-04-09].https:∥www.ibm.com/cn-zh/reports/databreach.
[2]OHMP.Sensitiveinformation[J].Southerncalifornialawreview,2015,88(5):1125-1196.
[3]SHAPIRAY,SHAPIRAB,SHABTAIA.Content-baseddataleakagedetectionusingextendedfingerprinting[DB/OL].(2013-02-08)[2024-04-14].https:∥arxiv.org/abs/1302.2028.
[4]SHUXK,ZHANGJ,YAODD,etal.Fastdetectionoftransformeddataleaks[J].IEEEtransactionsoninformationforensicsandsecurity,2016,11(3):528-542.
[5]李姝,张祥祥,于碧辉,等.互联网新闻敏感信息识别方法的研究[J].小型微型计算机系统,2021,42(4):685-689.
[6]GUOYY,LIUJY,TANG W W,etal.Exsense:extractsensitiveinformationfromunstructureddata[J].Computersamp;security,2021,102:102156.
[7]郑旭如.基于深度学习的数据脱敏研究[D].哈尔滨:哈尔滨工业大学,2020.
[8]许成.面向网络敏感信息的主题检测和情感分析研究与实现[D].上海:东华大学,2021.
[9]HUZT,HOU W,LIU X X.Deeplearningfornamedentityrecognition:asurvey[J].Neuralcomputingandapplications,2024,36(16):8995-9022.
[10]LIJY,FEIH,LIUJ,etal.Unifiednamedentityrecognitionasword-wordrelationclassification[J/OL].(2021-12-19)[2024-04-14].https:∥arxiv.org/abs/2112.10070.
[11]ZHANGY,YANGJ.ChineseNERusinglatticeLSTM[J/OL].(2018-05-05)[2024-04-14].https:∥arxiv.org/abs/1805.02023.
[12]ZANHY,LIWX,ZHANGKL,etal.Buildingapediatricmedicalcorpus:wordsegmentationandnamedentityannotation[M]∥ Lecture Notesin Computer Science.Cham:SpringerInternationalPublishing,2021:652-664.
作者简介:
郭 群(1998-),男(汉族),临沂,硕士生。研究领域:智能信息处理。
张华熊(1971-),男(汉族),金华,教授,博士。研究领域:智能信息处理。
王 波(1982-),男(汉族),钟祥,高级工程师,学士。研究领域:大数据和行业人工智能,软件工程。
王心怡(1990-),女(汉族),威海,学士。研究领域:大数据,信息研究。
基金项目:浙江省科技厅“尖兵”“领雁”研发攻关计划项目(2024C01019,2022C01220)
