基于字段信息和覆盖率反馈的协议模糊测试方法
2025-02-15丁森阳徐向华

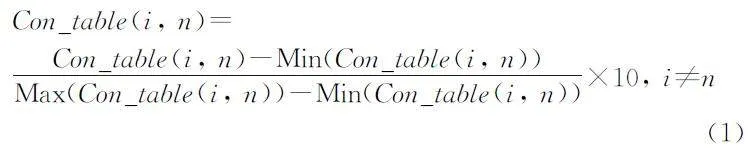

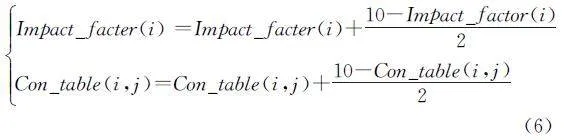
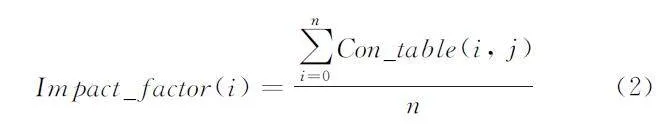
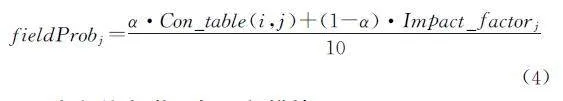
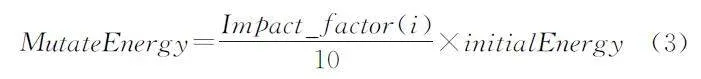

摘 要:模糊测试是目前比较流行的网络协议漏洞挖掘技术之一,但是存在现有网络协议模糊器对字段间的关联性探索不足的问题。为此,提出了一种基于字段信息和覆盖率反馈的模糊测试方法。该方法通过两个参数定量表示协议数据模型中不同字段的关系和每一个字段本身的影响力,并利用覆盖率信息持续学习更新,从而指导模糊测试向更高效的方向变异。基于该方法实现了基于字段信息和覆盖率反馈的模糊测试模糊器FMFuzzer(FieldMessagebasedFuzzer),并与模糊器Boofuzz和PAVFuzz进行了对比实验。实验结果显示,在3种网络协议上,FMFuzzer的代码覆盖率模糊器Boofuzz和PAVFuzz分别平均提升了10.97%和6.63%,证明了本方法的有效性。
关键词:网络协议漏洞挖掘;灰盒模糊测试;协议字段信息;代码覆盖率
中图分类号:TP393 文献标志码:A
0 引言(Introduction)
计算机网络支撑数字社会发展的基础,掌控着资源和信息的流通命脉,一旦网络通信出现故障,将给国家和社会的稳定发展带来极其严重的风险[1]。网络协议明确定义了不同实体之间进行网络通信的规范,而如何在我们所应用的网络协议实现中找到并修复安全缺陷,是每一位安全工作者都会面临的挑战[2]。
模糊测试[3]作为自动化漏洞发现领域中的佼佼者,凭借其易使用、效率高及误报率低等优势,在学术界和工业界都得到了广泛的应用和研究[4]。早期用于网络服务的模糊测试工具主要采用黑盒式模式[5],虽然黑盒模糊测试的适用性较强,但由于在测试过程中缺乏待测对象的内部反馈,其测试过程是相对盲目的,导致代码覆盖率和漏洞发现效率有限。近年来,结合代码覆盖率[6]反馈的灰盒模糊测试方法越来越流行[7],针对协议字段信息对模糊测试效率的影响,本文提出了一种结合代码覆盖率反馈的新型灰盒模糊测试方法,并通过实验验证了本方法的有效性。
1 相关工作与动机(Relatedworksandmotivation)
在网络协议模糊测试技术的发展初期[8],主要存在两种不同的基本测试思路[9]。采用这两种不同基本测试思路的方法,并各自采用不同的策略生成模糊测试用例,展现出各自独有的特点。
基于变异的灰盒模糊测试方法,如AFLNET[10] 和StateAFL[11],在测试过程中会依据代码覆盖率的反馈来指导测试用例的生成。这种方法旨在提高测试用例的效率,使其覆盖更多的运行代码。但早期的灰盒模糊测试方法都是基于AFL(AmericanFuzzyLop)工具进行的,而AFL在生成测试用例时采用的是随机突变的方式,这种方式在协议模糊测试领域存在一定的局限性,这是因为基于变异的方法很可能会破坏协议报文的结构,使其被待测程序直接抛弃而无法进入运行的流程。因此,这种方式产生的测试用例大多数都是无效的。
在基于语法生成的黑盒模糊测试中,例如Sulley、BooFuzz和Peach等,采用了一种有效的策略解决了基于变异的方法中测试用例结构被破坏的问题。该方法只需测试人员在测试前定义协议报文的结构,并人工划分字段,就能针对特定字段进行变异。通过这种方法生成的测试用例在很大程度上不会破坏报文的整体结构。然而,黑盒模糊测试方法缺乏对覆盖率等待测对象内部信息的指导,导致对协议实体程序的覆盖率相对较低。
为了解决上述两种方式存在的不足,研究者们在基于语法生成的黑盒模糊测试工具的基础上进行了改进,通过引入覆盖信息反馈来指导模糊测试变异的过程。在该研究领域具有代表性的成果有基于经典黑盒工具Peach提出的Peach*[12]、PAVFuzz[13]与基于框架Fuzzowski提出的EPF(Evolutionary,Protocol-aware,andcoverage-guidednetworkFuzzer)[14]等,它们都致力于研究如何更有效地利用覆盖信息引导变异的方向。通过与Boofuzz、Peach等传统黑盒模糊工具进行对比实验,大部分结果均显示,引入覆盖率信息反馈的模糊测试工具取得了更优的表现,证明了利用覆盖信息指导模糊测试的有效性。
在对现有基于语法生成的灰盒协议模糊测试方法进行研究时发现,除了不同协议状态模型的两个字段之间具有关系(如PAVFuzz[13]的研究)之外;在同一协议状态模型中,某些字段之间也存在某种关系。这种关系表明,当多个字段组合变异时,可能会触发单个字段单独变异时所触发不到的分支。同时,LUO等[15]通过对代码的静态分析指出,对同一个协议中的不同功能码应该分配不同的变异策略来提高模糊测试效率,对重要性不同的字段也应该分配不同的变异能量,给一些重要的字段(如数据字段)更多的变异能量,以提高模糊测试的效率。
本文提出了基于字段信息和覆盖率反馈的模糊测试方法。具体来说,该方法用参数表定量表示一个数据模型中不同字段的关系和每一个字段本身的影响力,并通过覆盖率信息持续学习更新该参数表,以指导模糊测试向更高效的方向变异,从而实现更高的覆盖率。本文主要贡献总结如下:①提出了一种基于覆盖率反馈的字段信息学习机制,根据分支覆盖信息进行关系学习,动态地学习到同一数据模型中可变字段之间的关系和每个字段的影响力因子,并且以关系表的形式定量描述这种关系;②采用了字段组合选择策略,在关系表和影响因子的指导下,让关系比较密切的字段和重要性高的字段尽可能多地组合变异,并给影响因子更高的字段分配更多的变异能量;③实现了基于字段信息和覆盖率反馈的模糊测试方法FMFuzzer的原型系统,并在几个真实的协议上对其进行了简要的评估。初步结果表明,与现有网络模糊器相比,FMFuzzer能达到更高的代码覆盖率并获得更好的模糊测试效果。
2 详细设计(Detaileddesign)
2.1 总体概述
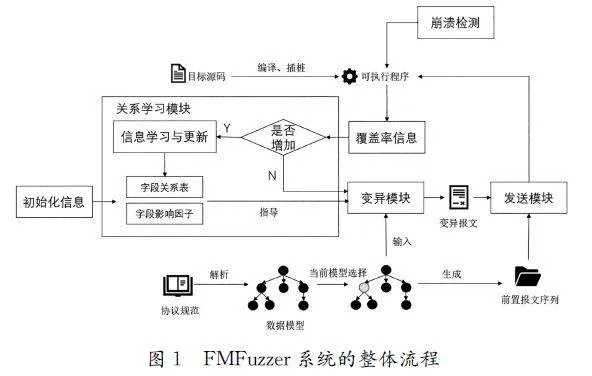
FMFuzzer系统的整体流程如图1所示。首先,系统获取当前所测试协议的协议规范,并捕获真实通信报文,将其解析为协议状态模型,其中每个协议状态的通信报文按照字段分块。定义好协议通信模型后,将目标源码通过AFL的LLVM(LowLevelVirtualMachine)编译器进行插桩、编译生成可执行程序。其次,初始化每个协议状态模型的字段关系表和字段影响因子。再次,遍历定义好的协议状态模型中的每一个状态,根据当前状态每个字段影响因子的不同,为该字段分配不同的变异能量;遍历协议当前状态的每一个字段,将其作为主字段,并根据字段关系表中各个字段与主字段的关系因子的大小与其本身的字段影响因子的大小,随机选取若干个字段作为组合变异字段一起进行变异,直至分配给该字段的变异能量耗尽。最后,在变异的过程中,如果覆盖率增加,则进入关系学习模块,将每一个被选取的组合变异字段单独与主字段进行变异,确定该字段是否对覆盖率的增加有贡献,并据此动态地调整该字段与主字段的关系因子与该字段本身的影响因子。
在所有协议状态模型的每个字段都进行变异并耗尽当前变异能量后,本轮模糊测试结束,开启下一轮的变异。下一轮的变异将采用更新后字段影响因子为当前字段分配新的变异能量。
FMFuzzer主要由3个重要模块构成。①字段信息初始化模块。该模块负责初始化每个协议状态模型的字段关系表和字段影响因子,字段信息表通过当前模型中所有字段的两两组合变异,并依据变异后的覆盖率大小来进行初始化;字段影响因子由该字段与其他字段的关系因子综合定义。②字段选择变异模块。该模块负责变异报文,首先遍历所有的协议状态模型,根据字段影响因子为每个字段设置当前轮测试的变异能量;其次遍历所有字段,综合考虑当前协议状态模型下主字段和其他字段的关系因子与字段影响因子,随机选取若干个字段作为组合变异字段,并与主字段一同进行变异,生成变异后的测试用例。③字段信息学习与更新模块。该模块负责每轮测试结束后依据覆盖率反馈信息更新字段关系表和字段影响因子,达到启发式变异的效果。FMFuzzer会将字段间关系与字段本身的重要性定量表示出来,并在模糊测试开启前进行初始化,随着模糊测试的每一轮进行,字段关系表和字段影响因子会随着覆盖率信息不断学习和更新,从而指导整个模糊测试的流程不断向高覆盖率的方向变异,提高模糊测试的效率。
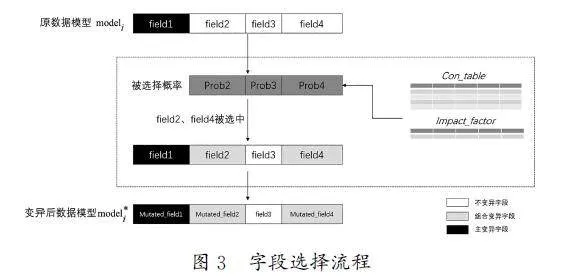
为了更清晰地展示字段关系表和字段影响因子,图2给出了每个协议状态模型的字段数据存储结构,对于每个协议状态模型modeli,在定义时会依据协议规范将其划分为若干字段,变异时也是以字段为单位进行的。每个协议状态模型,都对应一张Con_table表(表示字段之间的关系因子),以及一张Impact_factor表(表示字段本身的影响因子)。Con_table表会以三元组(fieldi,fieldj,CF)的数组格式存储,CF 代表两个字段间关系量化后的数据。Impact_factor表会以字典{fieldi:IF}的格式存储,IF 代表字段本身的影响因子。
2.2 字段信息初始化模块
在协议模型定义完成之后、模糊测试开始之前,系统会初始化协议每一个状态模型的字段关系表和字段影响因子,用于指导模糊测试的变异。
首先,遍历定义好的协议状态模型,对于每一个协议状态模型,取其中的两个字段(fieldi,fieldj),如果这两个字段的关系因子还没有被初始化,则仅将这两个字段作为可变异字段发送1000个变异报文,获取代码分支覆盖率,并根据覆盖率大小初始化这两个字段的关系因子CF。代码覆盖率越高,代表这两个字段的初始关系因子也越高。计算出关系因子后,以三元组(fieldi,fieldj,CF)的形式填入Con_table表。若当前协议状态模型有n 个字段,则字段的两两变异将进行C2n次,直至表格除了对角线都被初始化为止。
在初始化完成后,使用公式(1)将字段间关系因子进行调整,使其均匀分布在0~10,方便之后根据实时覆盖率信息进行更新和调整,其中Con_table(i,n)表示第i 个字段与其他n-1个字段间的关系因子。
在初始化字段影响因子时,遍历定义好的协议状态模型,对于每一个协议状态模型,遍历其所有字段fieldi,将其在Con_table表中所有相关项的平均值作为其初始影响因子,初始影响因子的计算方法如公式(2)所示:
字段信息初始化完成后,每个协议状态模型都获得了一张字段关系表和字段影响因子,这使得在模糊测试初始,变异就能有比较好的引导。虽然初始化阶段需要额外的时间开销,但是对于一种协议,只需要初始化一次,就能记录下每个字段的信息且可以重复使用,在测试不同的协议实现时沿用这些信息,对于总体的模糊测试效率的提升具有积极的作用。
2.3 字段选择变异模块
该模块负责生成变异报文,其核心功能为选定当前模糊测试阶段的协议状态模型后,遍历模型的所有可变字段,依据其字段影响因子分配本轮的变异能量,并且利用该字段对应的关系表,计算其他可变字段与其组合变异的概率,然后从中选择若干个字段一同变异,并与主字段进行有利于覆盖率增长的组合变异,从而提高模糊测试的效率。
字段选择变异模块的输入为当前正在变异的协议状态模型mi。首先,遍历该状态的所有字段,将当前字段作为主字段,根据当前字段的影响因子分配变异能量,能量分配如公式(3)所示,由于字段影响因子CF 服从(0~10)上的均匀分布,所以使用均匀分布的概率公式,其中initialEnergy 为初始能量,一般由测试人员根据实际测试环境决定。
根据主字段的字段关系表和字段影响因子,计算出其他每个字段被一起组合变异的概率,将变异后的测试用例发送给目标,如果当前的报文触发了新的分支覆盖,主字段的字段关系表和字段影响因子会进行学习更新,使得下一轮的模糊测试能朝着覆盖率更高的方向进行,并且重置当前的变异能量为初始值,使得当前主字段能进行更充分的变异测试。在当前字段的变异能量耗尽后,对当前协议状态模型的所有字段都进行相同的操作,在遍历完所有协议状态模型后,将使用新的字段关系表和字段影响因子开始下一轮的模糊测试。
字段选择变异模块的核心流程在于组合变异字段的选择。在选择组合变异字段时,系统会综合考虑当前主字段的字段关系表和其他字段的字段影响因子,据此计算出每个字段被选择的概率。值得注意的是,对于组合变异的字段数量不做限制,这一设计旨在能最大限度地扩展变异范围,使模糊测试能尽可能地覆盖到更多的代码。字段选择流程如图3所示。
组合变异字段的选择会基于当前状态模型mi 对应的字段关系表Con_tablei 与字段影响因子Impact_factori 计算出每个字段被选择的概率,并储存在概率数组fieldProb[]中,若当前主字段为fieldi,第j 个字段被选择的概率如公式(4)所示。由于Con_tablei 与Impact_factori 都属于在0~10上的均匀分布,所以计算出的概率值一定在0~1,其中α 为两个参数的权重,代表本次模糊测试分别对Con_tablei 和Impact_factori的重视程度,其值默认为0.5,表示字段间关系和字段影响因子拥有相同的权重。
2.4 字段信息学习与更新模块
字段信息学习与更新模块负责动态更新当前协议状态模型的字段关系表和字段影响因子,使得模糊测试朝着高覆盖率的方向进行。字段信息学习与更新算法如表1所示。
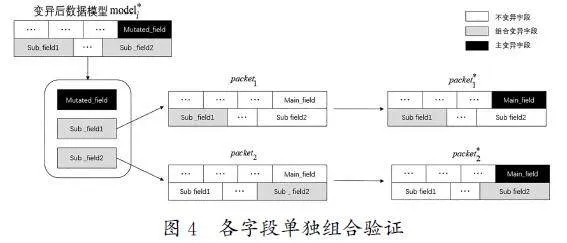
算法1给出了字段信息学习与更新模块的算法流程。如果当前变异的报文有新的分支覆盖,则会进入字段信息学习与更新模块。首先,获取当前变异报文的主字段和组合变异字段(算法1中的第1行);其次,对于每一个组合变异字段,都会单独与主字段进行测试,各字段单独组合验证如图4所示。通过单独组合验证,系统判断该组合变异字段是否与主字段有关联性,并评估其字段影响力,据此对字段关系表和字段影响因子进行相应的调整。
具体来说,首先,取原始协议状态模型,仅对主字段进行变异并发送给待测设备,获得其分支覆盖率Cov0(算法1第2~3 行);其次,遍历每一个被选择的组合变异字段,分别将其单独变异以及与主字段组合变异,得到对应的报文Packeti 与Packeti*;最后,将其发送给待测设备,获得单独变异的覆盖率Covi 与组合变异的覆盖率Covi*(算法1第5~8行)。
根据覆盖率的差异,算法会更新字段关系表和字段影响因子,若Cov0≠Covi*,则证明字段的组合变异能产生不同代码覆盖分支,组合变异字段对测试用例存在一定的影响;此时,算法会相应地更新字段影响因子,若有组合变异字段的测试用例达到的覆盖率更大,则增大该字段的影响因子,反之则减小(算法1第9~11行)。影响因子的更新学习方法如公式(5)所示,并确保更新后影响因子的值依旧保持在0~10。
若Cov0∪Covi≠Covi*,则证明组合变异达到了单独变异所达不到的分支,主字段与组合变异字段存在一定的联系且有益于覆盖率的增加,更新字段关系表,可以提高这两个字段的关系因子,并同时提高这两个字段的影响因子,使其在下一轮模糊变异中能分配到更多的能量(算法1第12~14行),字段关系表和影响因子更新方法如公式(6)所示:
3 实验验证(Experimentalverification)
为了验证本方法的有效性,我们在RTSP、DNS和FTP协议上进行了对比实验。具体而言,本方法在基于语法生成的黑盒协议模糊器BooFuzz上引入了字段间关系表、字段影响因子及分支覆盖信息反馈,使用并扩展了BooFuzz的变异引擎进行字段变异,实现了FMFuzzer的原型系统。在实验中,选择了两个指标衡量本方法的性能,分别是分支覆盖数和触发新分支的测试用例数量。为确保实验结果的可靠性,我们对每组实验均重复进行了三次,并取平均值作为最终结果,以消除随机因素的影响。
3.1 实验设计
实验环境设置如下:FMFuzzer运行环境为IntelCorei5-4750CPU @3.20GHz ×4,内存7.6 GB,操作系统为Ubuntu18.04。
本实验以基于本方法实现的模糊器FMFuzzer作为实验组。由于FMFuzzer 是基于BooFuzz 实现的,所以选择BooFuzz与PAVFuzz作为对照组。其中,开源的PAVFuzz只能在Windows操作系统上运行,因此我们在Ubuntu系统上复现了PAVFuzz 的核心思想作为对照组。FMFuzzer 与BooFuzz、PAVFuzz一样,都是基于语法生成的模糊测试工具,其不同之处在于FMFuzzer引入了字段组合变异和覆盖率信息反馈,以BooFuzz和PAVFuzz作为对照组进行对比可以检验使用本方法引导模糊测试的有效性。
本文选择了RTSP协议、DNS协议和FTP协议进行实验,并分别使用了Live555、Dnsmasq、LightFTP作为这些协议的实体程序。这些协议实体程序都是网络上使用范围比较广的协议实现,经常被作为各个工作的实验对象,具有实际的测试价值。
为了评估本方法的实际效果,本文采用了以下2个实验评测指标:①总分支覆盖数量,是指模糊器在实验运行的时间内能覆盖的总代码分支数量,也是本方法实现的基础,用于引导模糊测试的进行,也可以反映模糊器对待测协议实现代码的探索程度,是在协议模糊测试领域获得广泛认可的通用指标,能覆盖更多的程序分支,代表模糊器的探索能力较强,有更大的概率能挖掘出潜在漏洞;②触发新分支覆盖的测试用例数量是指模糊器在实验运行期间所产生的测试用例中触发程序新覆盖分支的测试用例个数,能反映模糊器运行期间产生的测试用例的质量。
3.2 实验结果
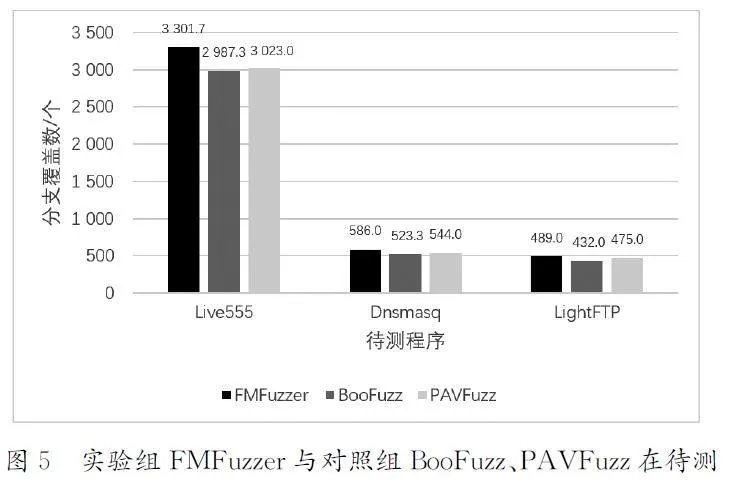
(1)分支覆盖数对比。实验组FMFuzzer 与对照组BooFuzz、PAVFuzz在待测程序Live555、Dnsmasq与LightFTP上的分支覆盖数对比结果如图5所示。由图5可知,实验组FMFuzzer在3个待测程序上覆盖的分支数量都高于对照组BooFuzz与PAVFuzz。在目标程序Live555上,相较于BooFuzz,FMFuzzer在分支覆盖数量指标上提升了10.52%,相较于PAVFuzz提升了9.22%;在目标程序Dnsmasq上,相较于BooFuzz,FMFuzzer在分支覆盖数量指标上提升了11.98%,相较于PAVFuzz提升了7.72%;在目标程序LightFTP上,相较于BooFuzz,FMFuzze在分支覆盖数量指标上提升了10.42%,相较于对照组PAVFuzz提升了2.95%。
总分支覆盖数指标的提升证明了本方法的有效性。分支覆盖数量的提升得益于本方法利用反馈的代码覆盖信息持续更新和学习字段关系表和字段影响因子,使变异时字段之间能进行有针对性的组合变异,进而提升了测试用例触发目标程序新分支的能力。
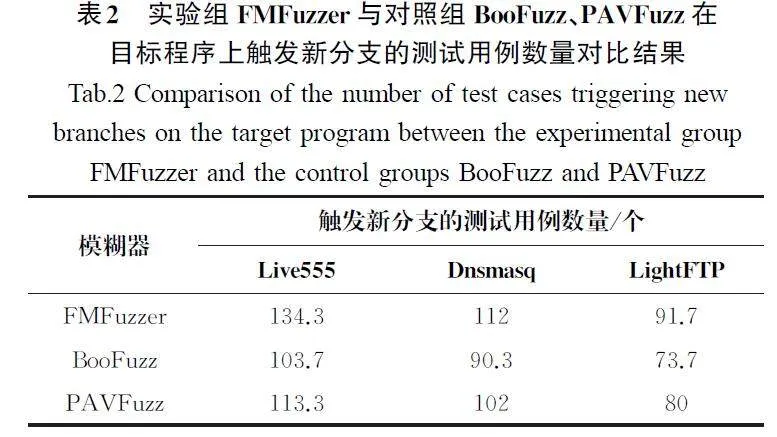
(2)触发新分支覆盖的测试用例数量对比。实验组FMFuzzer与对照组BooFuzz、PAVFuzz在目标程序上触发新分支的测试用例数量对比结果如表2所示。在目标程序Live555上,相较于BooFuzz,FMFuzzer在触发新分支覆盖的测试用例数量指标上提升了29.51%,相较于PAVFuzz提升了18.53%;在目标程序Dnsmasq上,相较于BooFuzz,FMFuzzer提升了24.03%,相较于PAVFuzz提升了9.80%;在目标程序LightFTP上,相较于BooFuzz,FMFuzzer提升了24.42%,相较于PAVFuzz提升了7.51%。
在相同的测试时间里,FMFuzzer触发新分支的测试用例数量均多于对照组的BooFuzz与PAVFuzz的数量。此效果得益于FMFuzzer在每一轮模糊测试中根据字段影响因子对每个主字段赋予了动态变化的变异能量,当FMFuzzer认为某个字段的影响因子过小,已经不具备触发新覆盖分支的能力时,便快速跳过这个字段,进行其他字段的变异工作,避免了在无用字段上浪费过多的测试时间。且FMFuzzer在模糊测试过程中使用启发式的思想学习到字段间的关系表和字段影响因子,指导字段朝着覆盖率增长的方向进行组合变异,提高模糊测试的效率。
4 结论(Conclusion)
针对基于语法生成的灰盒协议模糊测试方法PAVFuzz和Polar在协议字段关系和影响力处理方面的不足,本文提出了一种基于字段信息和覆盖率反馈的模糊测试方法。该方法用两个参数定量表示一个数据模型中不同字段的关系和每一个字段本身的影响力,并通过覆盖率信息不断学习更新,用于指导模糊测试往更高效的方向变异,达到更高的覆盖率。基于该方法实现了模糊器FMFuzzer,并进行了实验评估,对3种应用广泛的网络协议进行了测试,并与模糊器BooFuzz和PAVFuzz进行了对比。对比结果显示,本方法在分支覆盖数与触发新分支的测试用例数量指标上都有一定程度的提升,证明了本方法的有效性。
参考文献(References)
[1]VOLKOVA A,NIEDERMEIER M,BASMADJIAN R,etal.Securitychallengesincontrolnetworkprotocols:asurvey[J].IEEEcommunicationssurveys amp; tutorials,2019,21(1):619-639.
[2]YUGHAR,CHITHRAS.Asurveyontechnologiesandsecurityprotocols:referenceforfuturegenerationIoT[J].Journalofnetwork and computerapplications,2020,169:102763.
[3]LIANGHL,PEIXX,JIAXD,etal.Fuzzing:stateoftheart [J].IEEEtransactionsonreliability,2018,67(3):1199-1218.
[4]任泽众,郑晗,张嘉元,等.模糊测试技术综述[J].计算机研究与发展,2021,58(5):944-963.
[5]ALSAEDIA,ALHUZALIA,BAMASAG O.Black-boxfuzzingapproachestosecurewebapplications:survey[J].Internationaljournalofadvancedcomputerscienceandapplications,2021,12(5):849-855.
[6]HEMMATIH.Howeffectivearecodecoveragecriteria?[C]∥IEEE.ProceedingsoftheIEEE:2015IEEEInternationalConferenceonSoftwareQuality,ReliabilityandSecurity.Piscataway:IEEE,2015:151-156.
[7]MANÈSVJM,HANH,HANC,etal.Theart,science,andengineeringoffuzzing:asurvey[J].IEEEtransactionsonsoftwareengineering,2021,47(11):2312-2331.
[8]ZHANGZW,ZHANGHZ,ZHAOJJ,etal.Asurveyonthedevelopmentofnetworkprotocolfuzzingtechniques[J].Electronics,2023,12(13):2904.
[9]LIJ,ZHAOB,ZHANGC.Fuzzing:asurvey[J].Cybersecurity,2018,1:1-13.
[10]PHAM V T,BÖHME M,ROYCHOUDHURY A.Aflnet:agreyboxfuzzerfornetworkprotocols[C]∥IEEE.ProceedingsoftheIEEE:2020IEEE13thInternationalConferenceonSoftwareTesting,ValidationandVerification(ICST).Piscataway:IEEE,2020:460-465.
[11]NATELLA R.StateAFL:Greyboxfuzzingforstatefulnetworkservers[J].Empiricalsoftwareengineering,2022,27(7):191.
[12]LUOZX,ZUOFL,SHENYH,etal.ICSprotocolfuzzing:coverageguidedpacketcrackandgeneration[C]∥IEEE.ProceedingsoftheIEEE:202057thACM/IEEEDesign Automation Conference (DAC).Piscataway:IEEE,2020:1-6.
[13]ZUOFL,LUOZX,YUJZ,etal.Pavfuzz:state-sensitivefuzztestingofprotocolsinautonomousvehicles[C]∥IEEE.ProceedingsoftheIEEE:202158thACM/IEEEDesignAutomationConference(DAC).Piscataway:IEEE,2021:823-828.
[14]HELMKER,WINTERE,RADEMACHERM.EPF:anevolutionary,protocol-aware,and coverage-guided networkfuzzingframework[C]∥IEEE.ProceedingsoftheIEEE:202118thInternationalConferenceonPrivacy,SecurityandTrust(PST).Piscataway:IEEE,2021:1-7.
[15]LUOZX,ZUOFL,JIANGY,etal.Polar:functioncodeawarefuzztestingofICSprotocol[J].ACMtransactionsonembeddedcomputingsystems,2019,18(5s):1-22.
作者简介:
丁森阳(1997-),男(汉族),湖州,硕士生。研究领域:计算机网络,漏洞挖掘。
徐向华(1965-),男(汉族),杭州,教授,博士。研究领域:计算机网络,机器学习,物联网技术。本文通信作者。
