基于多尺度偏移感知网络的结肠息肉目标检测
2025-01-25池晓鑫杜晓刚王营博雷涛









摘 要:一些息肉目标检测方法难以充分提取全局及长距离语义信息,导致在具有环境噪声的情况下对尺寸差异较大的息肉目标检测精度低.为了解决该问题,提出了一种基于多尺度偏移感知的息肉检测网络.首先,设计了多尺度偏移感知注意力模块,通过在不同尺度上对图像特征进行注意力加权和偏移感知,提高了图像特征的提取和融合能力.其次,设计了渐近特征融合模块,对不同尺度的特征图进行自适应空间加权融合,从而捕捉了更丰富的上下文信息.通过大量实验证明,该方法在三个不同类型的息肉数据集上分别达到了94.8%、94.6%和95.8%的检测精度,相比于当前主流的目标检测方法取得了更好的检测结果.
关键词:医学图像; 息肉检测; 注意力机制; 多尺度特征; 特征融合
中图分类号:TP391.41
文献标志码: A
Multi-scale offset-aware network for colon polyp detection
CHI Xiao-xin, DU Xiao-gang*, WANG Ying-bo, LEI Tao
(School of Electronic Information and Artificial Intelligence, Shaanxi Joint Laboratory of Artificial Intelligence, Shaanxi University of Science amp; Technology, Xi′an 710021, China
)
Abstract:Some polyp detection methods struggle to adequately extract global and long-range semantic information,leading to lower detection accuracy of polyp targets with significant size variations in the presence of environmental noise.In order to address this issue,a polyp detection network based on multi-scale offset awareness is proposed.Firstly,a multi-scale offset-aware attention module is designed to enhance the extraction and fusion capability of image features by applying attention weighting and offset awareness to features at different scales.Secondly,an asymptotic feature fusion module is designed to adaptively spatially weight and fuse feature maps of different scales,thereby capturing richer contextual information.Extensive experiments demonstrate that this method achieves detection accuracies of 94.8%,94.6%,and 95.8% on three different polyp datasets,outperforming current mainstream object detection methods.
Key words:medical imaging; polyp detection; attention mechanism; multi-scale feature; feature fusion
0 引言
息肉检测是胃肠道疾病早期诊断和治疗的关键步骤之一.然而,由于胃肠道内部结构复杂且息肉形态多样,使得传统的人工检测方法效率低下且存在主观性,因此研究一种自动化的、高效的息肉检测方法具有重要意义.
当前,在复杂环境噪声影响下对大尺度差异息肉的高精度检测仍面临很大挑战.该领域研究主要集中在两个方面:(1)基于卷积神经网络(Convolutional Neural Network,CNN)的检测方法;(2)基于Transformer架构的检测方法.
基于CNN的检测方法主要分为两类:一阶段方法和两阶段方法.一阶段方法通过单个神经网络同时完成目标定位和分类.例如,王博等[1]提出一种改进的M2det息肉检测方法,使用FFMs模块融合主干网络特征,同时增加scSENET注意保留有效特征,但对于一些对比度较低且形状不规则息肉依然存在误检.Pacal等[2]采用改进的YOLO系列网络对息肉进行目标检测,在公开数据集ETIS-Larib[3]中获得了91.62%的精度,仍有待提升.Ohrenstein等[4]提出了一种SSD联合GAN的检测方法,GAN用于提升数据集中小目标的分辨率,在保证SSD检测的速度上,提升了检测小目标息肉的精确度,但依旧有可提升的空间.一阶段方法结构简单,运行速度快,但检测精度偏低.
两阶段方法则是先生成候选框(Region Proposal),然后对这些候选框进行分类和回归.例如:Mo等[5]使用Faster R-CNN在内窥镜息肉数据集上检测并获得了较高精度,但实验结果对于尺度较小及对比度不高和含有镜面反光区域的息肉检测效果不佳.Chen等[6]提出将Faster R-CNN整合自注意模块用于对数据增强后的息肉图像检测,对于隐蔽型息肉检测效果不理想.Qadir等[7]针对传统卷积网络提出整合区域候选网络(Region Proposal Network,RPN)和减少假阳性(False Positive,FP)单元来提升息肉检测整体性能并分别在Faster R-CNN和SSD上测试,虽然精度有所提升,但参数量较大,且需要一定的计算资源.两阶段方法准确性高、泛化能力强,但速度慢、网络复杂,对训练数据要求高.
在基于Transformer的检测方法中,Yoo等[8]提出将Transformer集成到YOLO体系结构中,专注于调整负责特征融合的部分,但是,所构建的轻量化息肉检测模型在精度和召回率上仍有一定提升空间.针对Transformer注意力模块在处理图像特征图时收敛速度慢且特征空间分辨率有限的问题,Zhu等[9]通过引入可变形注意力机制并结合可变形卷积的稀疏空间采样以及Transformer的关系建模能力,提出了Deformable-DETR.Dai等[10]提出了Dynamic-DETR方法,通过在DETR的编码器和解码器阶段引入动态注意力来突破其对小特征分辨率和训练收敛速度的两个限制.Wang等[11]基于Transformer提出Anchor-DETR方法,其提出的目标检测查询设计和一种新的注意力变体可以在实现与DETR中标准注意力相似或更好的性能的同时减少内存开销.Cao等[12]通过优化粗糙特征和预测位置,即提出了一个由粗糙层和精细层构成的新型粗到细(CF)解码器层来解决DETR在小目标检测性能较低的问题.Peng等[13]指出卷积和级联的自注意模块在特征提取中存在一定缺陷,并提出一种称为Conformer的混合结构,在检测任务中充分利用卷积操作和自注意力机制增强表示学习.
综上,基于CNN的检测方法对局部信息敏感,对全局语义信息的理解能力较弱,不能充分提取全局及长距离有效信息.基于Transformer的检测方法虽然有较好的全局理解能力和长距离依赖处理能力,但其本身计算复杂度过高,对一些环境噪声较大且密集的小目标检测效果不佳.
针对上述问题,本文提出一种基于多尺度偏移感知的息肉检测网络来实现自动准确的息肉目标检测.采用多尺度偏移感知注意力引导特征提取的方式来解决传统方法难以处理长距离依赖及全局信息提取不充分的问题.通过渐近自适应空间特征融合策略来有效分离噪声并充分融合有效特征,从而提升模型对小目标息肉的特征学习能力.通过大量实验证明,该方法在不同噪声环境下,能够有效提升不同形态息肉的检测准确性.
1 本文方法
1.1 总体架构
图1是本文提出的多尺度偏移感知息肉检测网络整体模型,由多尺度偏移感知模块(Multi-Scale Offset-aware Attention Module,MOA)、渐近特征融合模块(Asymptotic Feature Fusion Module,AFFM)和分类回归模块三部分组成.首先,输入图像经过MOA进行特征偏移对齐并提取多尺度特征;其次,这些特征图通过AFFM逐次从低级到高级进行渐近特征融合.本文采用渐近自适应空间融合结构,避免了非相邻层特征融合时可能出现由于语义差距过大导致融合不充分的问题.同时,为了避免出现过拟合现象,本文在AFFM的最浅层和最深层分别引入类残差结构,进一步补充局部及全局语义信息.最后,融合后的特征进入分类回归模块.在分类回归模块,本文采用基于卷积操作的预测器而非传统基于感兴趣区域的池化操作,其具有更高的效率、更丰富的空间信息、更好的泛化能力和更简单的训练过程.该预测器分为两个分支,分别用于预测每个Anchor的所属类别和回归目标边界框参数,最终输出预测结果.这种结构设计能够更好地捕获目标的语义信息和空间关系,提高模型的准确性和鲁棒性.
1.2 多尺度偏移感知模块
特征提取网络中,单一尺度特征所包含的语义信息是有限的,多尺度特征提取则能更全面地捕捉到图像中的有效信息,且不同尺度下提取的特征能更好地适应不同尺度下的环境变化和噪声,但由于物体形变以及尺度选择的不确定性往往会造成一定程度的特征偏移.
针对该问题,本文设计了MOA模块.该模块通过结合多尺度注意力和特征偏移感知,有效提取不同尺度、姿态和噪声下的特征并避免了特征在图像中位置偏移的问题.MOA的整体结构如图2所示.基于传统的ResNet50[14]网络结构,本文在Conv2-4_x卷积层加入由EMA模块和Offset Map组成的残差分支所构成的多尺度偏移感知注意力模块(MOA模块).MOA模块通过结合高效多尺度注意模块(Efficient Multi-Scale Attention Module,EMA)[15]与Offset Map对齐模块,能够在捕捉不同尺度下关键信息的同时,运用偏移感知,实现对不同尺度下特征的定位与调整,从而更精确地把握特征间的空间关联,实现多尺度信息的有效融合.
多尺度注意力能在进行多尺度特征提取时,选择合适的尺度范围和间隔.不同的图像可能需要不同的尺度范围来捕捉其特征.本文采用EMA模块如图2所示.EMA通过对图像特征进行多尺度的注意力加权,提高模型在多尺度信息融合和特征提取方面的效率和性能.EMA采用三分支并行处理,对输入图像特征进行特征分组,并编码了跨通道信息以调整不同通道的重要性.同时,精确的空间结构信息也被保留在通道中.EMA通过建立通道位置之间的相互依赖关系,实现了跨空间信息聚合,从不同的空间维度方向进行了更丰富的特征聚合.并且,采用3*3和1*1卷积可以在中间特征之间利用更多的上下文信息,进一步提高了特征提取的效果.
针对多尺度特征提取时存在的特征偏移,本文采用Offset Map对齐模块结合EMA精确调整多尺度特征.如图2所示,输入特征图经过RoI池化生成池化特征图,经过全连接层生成归一化的偏移量,这里的全连接层是通过反向传播进行学习的,所生成偏移量的归一化是必要的,以使得偏移量的学习对感兴趣区域(RoI)的大小具有不变性.然后将偏移量与可变形卷积映射后的特征图相结合,经过特征偏移对齐得到最终的输出特征图.
1.3 渐近特征融合模块
特征融合网络中,与许多基于特征金字塔网络的目标检测方法一样,首先通过多层卷积神经网络提取图像不同尺度的特征,这些特征包括低级的边缘和纹理信息,以及高级的语义信息.然后,不同尺度的特征被送入一个渐近特征融合模块,该模块能够将不同尺度和语义层次的特征进行有效地融合,从而得到更加全面和丰富的特征表示.最后,将融合后的特征输出并用于分类和回归任务,如图1所示.
在进行特征融合之前,输入图像经过多尺度偏移感知模块得到一组不同尺度的特征,将其表示为{C2,C3,C4,C5}.为了进行渐近特征融合,低级特征C2和C3首先输入到特征金字塔网络中,然后依次添加C4和C5.因为所有层次特征均参与了特征融合,可能会遗失底层原始信息和抽象的高级特征而导致过拟合.为了解决该问题,本文用类残差结构分别将低级和高级特征补充到渐近特征融合网络的输出端,最终形成一组多尺度特征{P2,P3,P4,P5}输出到分类回归模块.
通过观察渐近特征融合网络的体系结构,在主干网络的自下而上的特征提取过程中,本文采用渐近集成低级、高级和顶级的特征,有效避免了特征融合不充分问题.具体来说,渐近特征融合网络最初融合了低级特征,然后是深层特征,最后整合最抽象的特征.非相邻层次特征之间的语义差距大于相邻层次特征之间的语义差距,特别是对于底部和顶部特征.这直接导致了非相邻层次特征的融合效果较差.因此,直接使用C2,C3,C4和C5融合是不合理的.由于该体系结构是渐近的,这将使不同层次特征的语义信息在渐近融合过程中更接近,从而缓解上述问题.
在多层次特征融合过程中,本文利用自适应空间特征融合(Adaptive Spatial Feature Fusion,ASFF)为不同层次的特征分配不同的空间权重,增强关键层次的重要性,减轻来自不同对象的差异信息的影响.融合了三个层次特征的ASFF模块如图3所示.设xn→lij表示从第n层到l层(i,j)处的特征向量,特征向量ylij经过多层次特征的自适应空间融合得到.这里定义为三个尺度特征向量x1→lij、x2→lij和x3→lij的线性组合,如公式(1)所示:
ylij=αlij·x1→lij+βlij·x2→lij+γlij·x3→lij
(1)
式(1)中:α1ij,β1ij和γ1ij表示第1层三个层次的空间权重,且αlij+βlij+γlij=1.考虑到渐近特征融合网络各阶段融合特征数量的差异,实现了阶段特定数量的自适应空间融合模块.
2 实验结果与分析
2.1 实验数据集
本文采用三个不同类型的息肉数据集,包含胃肠镜息肉图像集、视频帧以及息肉CT图像集.三个数据集中涵盖了不同尺度以及不同模态的息肉,这有助于验证模型性能,检验其泛化能力和鲁棒性.
2.1.1 AI_2020_VOC数据集
AI_2020_VOC是一个用于息肉检测和分割任务的数据集.该数据集由中国医学科学院和清华大学合作收集和标注.数据集包含来自结肠镜检查的息肉图像,涵盖了不同类型和大小的息肉.每个图像都经过专业医生标注,标注信息包括息肉的位置和形状.该数据集包含7 804张息肉CT图.
2.1.2 PolypGen2021_MultiCenterData_v3数据集
PolypGen2021_MultiCenterData_v3[16]数据集(简称PolypGen)起源于Endocv2021挑战的一部分,旨在解决息肉检测和分割的通用性.该数据集包含3 446个带注释的息肉标签,由6名高级胃肠病学家验证了息肉边界的精确划定.该数据集共计3 762帧的阳性样本,包含了小、中、大息肉的像素级标注.
2.1.3 Dataset-acess-for-PLOS-ONE数据集
本数据集是提交给PLOS One的论文数据集(简称DfPlos One)[17].该数据集包括404张胃息肉图像,这些图像来自中国浙江省邵逸夫医院215名接受内镜检查的患者.所有图像均包含至少一个息肉,并由经验丰富的内窥镜医师进行了标记.为了构建测试数据集,对图像进行重排并随机选择了50张图像.鉴于剩下的354张图像对于训练而言过少,对354张带标签的图像进行180度旋转以增强数据.经增强后共得到708张图像用于训练.
2.2 实验设置
实验硬件环境为Intel Core i9-12900k处理器与一块NVIDIA A30显卡.操作系统使用Linux Ubuntu20.04,深度学习框架选用Pytorch1.7.1,开发语言版本是Python 3.7.
在训练过程中,模型进行有监督迭代训练,设置模型学习率为0.001,动量为0.9,批数量为16,训练迭代轮数为150,测试过程对于全部目标域图像进行分类验证,批处理数量设置为4.所有图像经过预处理调整为300×300像素.对于DfPlos One数据集,在模型训练前对输入图像进行上、下、左、右、左上、右上、左下、右下和中心共9个方位的裁剪,以及随机图像旋转和翻转进行数据扩充,确保每幅输入图像的息肉区域的语义表达.
2.3 评价指标
为了客观全面地评价网络性能,并与其他算法进行公平比较,模型在训练和测试过程中均采取目标检测评价指标中常用的COCO指标,并从中选用精确率(Precision)、召回率(Recall)、平均精度(Average Precision,AP)和均值平均精度(mean Average Precision,mAP)作为模型的性能评估指标.
精度衡量正确预测的目标所占百分比,定义为:
Precision=TPTP+FP
(2)
式(2)中:TP代表真阳性,FP代表伪阳性.
召回率是指能够被正确检测的患者在所有患者中所占的百分比,计算公式(3)为:
Recall=TPTP+FN
(3)
式(3)中:TP代表真阳性,FN代表伪阴性.
AP是在不同置信度阈值下计算出的精度的平均值,通过计算P-R曲线下的面积来衡量算法在不同置信度阈值下的性能表现,如式(4)所示:
AP=∫10P(R)dR
(4)
式(4)中:P和R分别代表精度和召回率.
mAP反映了在所有类别中的精度表现,如式(5)所示:
mAP=1N∑Ni=1∫10P(R)dR
(5)
式(5)中:N代表类别个数,P和R分别代表精度和召回率.
2.4 MOA模块实验对比
表1展示了在PolypGen数据集上添加不同注意力模块后的对比结果.
值得注意的是,当添加MOA模块时,网络的参数数量最少,仅为37.85M,模型的计算能力表现最优,同时mAP(0.5)达到了最高的94.1%,mAP(0.5∶0.95)也达到了最佳的76.0%.相较于添加CBAM、SE、ECA、SA等注意力模块,MOA模块能够在捕捉不同尺度下关键信息的同时,利用偏移感知实现对各尺度下的特征定位与调整,从而更精确地把握特征间的空间关联.此外,MOA具有高效的设计结构,减少了计算负担,提高了模型的计算效率.
2.5 对比实验
为了体现本文模型在不同尺度息肉检测上的准确性和鲁棒性,在三个不同规格数据集总计上万张息肉图像上进行了对比实验.实验结果如表2所示.从表2可以看出,与YOLOv7相比,本文方法在三个数据集上的精度提升了分别为3.5%、6.7%、9.0%,mAP指标提升了分别为5.6%、6.4%、2.2%.与目标检测中无锚框方法FCOS相比,本文方法精度提升了分别为1.0%、3.0%、15.1%,mAP指标提升了分别为0.9%、3.0%、0.5%.与最新的基于信道重参数卷积YOLO体系结构RCS-YOLO相比,本文模型在AI_2020_VOC数据集和PolypGen数据集上的精度分别提升了3.1%和3.0%,在DfPlos One数据集上相差1.0%,但是在mAP指标上分别提升了8.1%、14.4%、0.2%.综上,本文模型在三个数据集上的精度和平均准确率上具有很大的优势,但在召回率上与当前一些主流方法相比仍有一定的差距.这些结果充分展现了本文方法在不同尺度息肉检测上的准确性和鲁棒性.
图4展示了本文模型在三个不同息肉数据集上的检测结果.
左图是真实息肉位置,右图是模型输出的预测结果.通过对比可以发现,尽管许多息肉存在微小、对比度低、不规则形状、残渣以及胃液等噪声,检测难度较大,但本文模型仍然能够准确地检测出息肉位置.此外,本文模型在处理息肉CT图时同样能够精确地预测其位置.这表明本文模型在处理不同类型的息肉数据集时具有很好的泛化能力和抗干扰能力,进一步验证了本文模型在息肉检测上的鲁棒性.
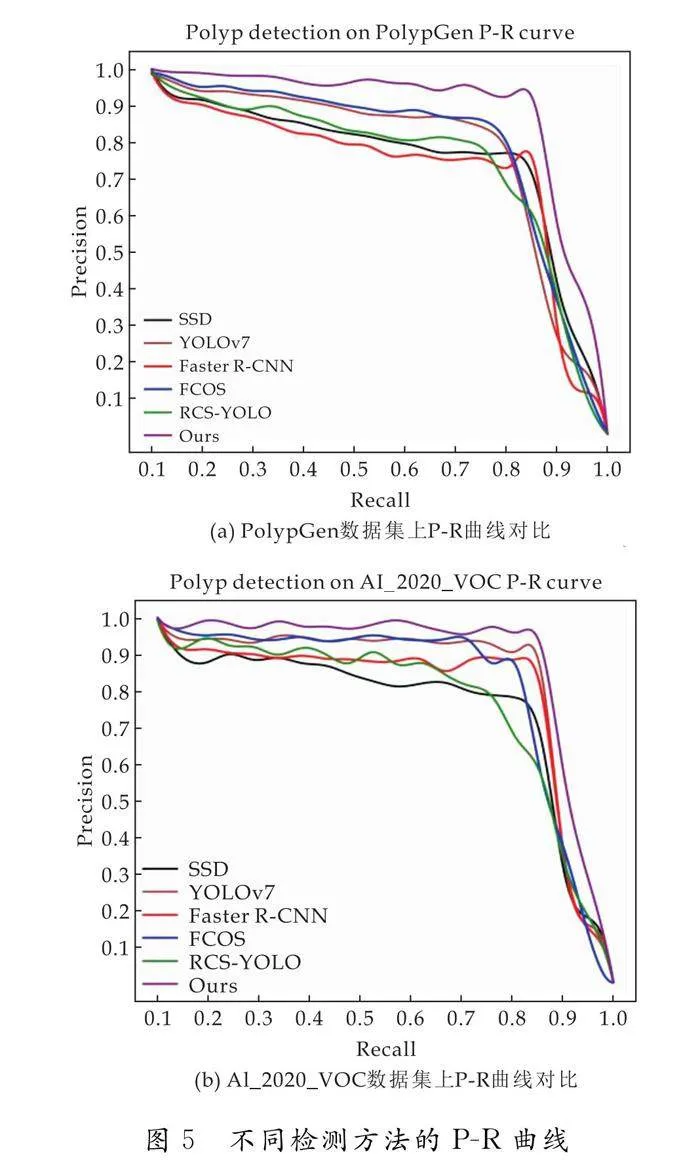
图5为基于精确率与召回率绘制的不同检测方法在不同数据集上的P-R曲线.图5(a)所示为胃肠镜息肉数据集PolypGen,图5(b)所示为胃部息肉CT数据集AI_2020_VOC.与目标检测领域最新的方法相比,本文方法在传统胃肠镜息肉以及息肉CT图上的P-R曲线均表现出优异的性能,进一步验证了本文方法的有效性和可行性.
2.6 消融实验
为了验证各模块在息肉数据集上的有效性,比较了单独加入MOA模块、AFFM模块以及同时加入二者的性能,实验结果如表3所示.与基线结果相比,在ResNet50主干中融入MOA模块后,三个数据集上的mAP分别增加了1.4%、0.7%和0.4%;用AFFM模块替换原FPN网络后,三个数据集上的mAP分别提升了3.6%、4.0%和1.2%;而当同时加入MOA模块和AFFM模块时,与基线网络RetinaNet相比,mAP分别提升了7.5%、6.2%和3.7%.综上,实验结果表明了MOA模块和AFFM模块的有效性.
3 结论
针对息肉检测任务中息肉尺度差异大、环境噪声复杂等问题,本文提出了一种多尺度偏移感知息肉检测网络.通过多尺度偏移感知注意力提取并对齐不同尺度有效特征,有效解决了传统目标检测方法在环境噪声影响下难以充分提取全局及长距离有效信息的问题.同时,采用渐近的自适应空间融合结构有效解决了不同尺度特征融合过程中由于非相邻层特征语义差距大导致融合不充分的问题,进一步提升了模型在息肉检测上的准确性和可靠性.经过大量实验证明,本文方法在三个息肉数据集上的检测精度均优于当前主流方法.
参考文献
[1] 王 博,张丽媛,师为礼,等.改进的M2det内窥镜息肉检测方法[J].计算机工程与应用,2022,58(2):193-200.
[2] Pacal I,Karaboga D.A robust real-time deep learning based automatic polyp detection system[J].Computers in Biology and Medicine,2021,134:104 519.
[3] Silva J,Histace A,Romain O,et al.Toward embedded detection of polyps in wce images for early diagnosis of colorectal cancer[J].International Journal of Computer Assisted Radiology and Surgery,2014,9:283-293.
[4] Ohrenstein D C,Brandao P,Toth D,et al.Detecting small polyps using a Dynamic SSD-GAN[J].ArXiv Preprint ArXiv,2020,2010:15 937.
[5] Mo X,Tao K,Wang Q,et al.An efficient approach for polyps detection in endoscopic videos based on faster R-CNN[C]// Proceedings of the 24th International Conference on Pattern Recognition (ICPR).Beijing,China:IEEE,2018:3 929-3 934.
[6] Chen B L,Wan J J,Chen T Y,et al.A self-attention based faster R-CNN for polyp detection from colonoscopy images[J].Biomedical Signal Processing and Control,2021,70:103 019.
[7] Qadir,Hemin Ali,Ilangko Balasingham,et al.Improving automatic polyp detection using CNN by exploiting temporal dependency in colonoscopy video[J].IEEE Journal of Biomedical and Health Informatics,2019,24(1):180-193.
[8] Yoo,Youngbeom,Jae Young Lee,et al.Real-time polyp detection in colonoscopy using lightweight transformer[C]// Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision.Waikoloa,Hawaii:IEEE,2024:7 809-7 819.
[9] Zhu X,Su W,Lu L,et al.Deformabledetr:Deformable transformers for end-to-end object detection[J].ArXiv Preprint ArXiv,2020,2010:04 159.
[10] Dai X,Chen Y,Yang J,et al.Dynamicdetr:End-to-end object detection with dynamic attention[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Montreal,QC,Canada:IEEE,2021:2 988-2 997.
[11] Wang Y,Zhang X,Yang T,et al.Anchordetr:Query design for transformer-based detector[C]// Proceedings of the AAAI Conference on Artificial Intelligence.California,USA:AAAI,2022:2 567-2 575.
[12] Cao X,Yuan P,Feng B,et al.Cf-detr:Coarse-to-fine transformers for end-to-end object detection[C]// Proceedings of the AAAI Conference on Artificial Intelligence.California,USA:AAAI,2022:185-193.
[13] Peng Z,Guo Z,Huang W,et al.Conformer:Local features coupling global representations for recognition and detection[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2023,45(8):9 454-9 468.
[14] He K,Zhang X,Ren S,et al.Deep residual learning for image recognition[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas,NV,USA:IEEE,2016:770-778.
[15] Ouyang D,He S,Zhang G,et al.Efficient multi-scale attention module with cross-spatial learning[C]// ICASSP 2023-2023 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Acoustics,Speech:IEEE,2023:1-5.
[16] Ali S,Jha D,Ghatwary N,et al.PolypGen:A multi-center polyp detection and segmentation dataset for generalisability assessment[J].ArXiv Preprint ArXiv,2021,2106:04 463.
[17] Zhang X,Chen F,Yu T,et al.Real-time gastric polyp detection using convolutional neural networks[J].PloS One,2019,14(3):e0 214 133.
[18] Woo S,Park J,Lee J Y,et al.Cbam:Convolutional block attention module[C]// Proceedings of the European Conference on Computer Vision (ECCV).Munich,Germany:Springer International Publishing,2018:3-19.
[19] Hu J,Shen L,Sun G.Squeeze-and-excitation networks[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT,USA:IEEE,2018:7 132-7 141.
[20] Lin T Y,Goyal P,Girshick R,et al.Focal loss for dense object detection[C]// Proceedings of the IEEE International Conference on Computer Vision.Venice,Italy:IEEE,2017:2 980-2 988.
[21] Wang Q,Wu B,Zhu P,et al.ECA-Net:Efficient channel attention for deep convolutional neural networks[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Seattle,WA,USA:IEEE,2020:11 534-11 542.
[22] Zhang Q L,Yang Y B.Sa-net:Shuffle attention for deep convolutional neural networks[C]// IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP).Toronto,Canada:IEEE,2021:2 235-2 239.
[23] Liu W,Anguelov D,Erhan D,et al.Ssd:Single shot multibox detector[C]//Proceedings of the Computer Vision-ECCV 2016:14th European Conference.Amsterdam,The Netherlands:Springer International Publishing,2016:21-37.
[24] Wang C Y,Bochkovskiy A,Liao H Y M.YOLOv7:Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Vancouver,BC,Canada:IEEE,2023:7 464-7 475.
[25] Ren S,He K,Girshick R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis amp; Machine Intelligence,2017,39(6):1 137-1 149.
[26] Tian Z,Shen C,Chen H,et al.Fcos:Fully convolutional one-stage object detection[C]// Proceedings of the IEEE/CVF International Conference on Computer Vision.Seoul,Korea (South):IEEE,2019:9 627-9 636.
[27] Kang M,Ting C M,Ting F F,et al.RCS-YOLO:A fast and high-accuracy object detector for brain tumor detection[C]// International Conference on Medical Image Computing and Computer-Assisted Intervention.Cham,Switzerland:Springer Nature,2023:600-610.
【责任编辑:陈 佳】
