基于改进FPN的小目标检测算法
2024-12-06金可艺陈惠妹曹斯茹




摘 要:本文针对目前小目标检测中语义信息缺失且识别困难的问题,对目标检测算法中的特征金字塔网络(FPN)进行了改进。首先,将顶层特征图融合上、下文信息,并与混合注意力机制串联,增强顶层特征,从而在进行自上而下融合过程中获得更好的特征。其次,针对小目标在FPN设计新的特征层。此层由深层语义信息和浅层细节信息融合而成,使得到的小目标层不仅是高分辨率的浅层,同时还有更丰富的语义信息。最后,将改进目标检测器在MS COCO数据集的一类上进行试验。结果表明,改进的Cascade RCNN小目标检测精度为54.2%,比原模型提高了11%。
关键词:小目标检测;FPN;特征融合;注意力机制
中图分类号:TP 751" " " " " 文献标志码:A
目标检测是计算机视觉领域的核心问题之一。基于深度学习的目标检测器主要有2种,即两阶段和一阶段[1]。前者检测结果更精确,后者检测速度更快。为更好地使用多尺度特征图,进而又提出了特征金字塔网络(FPN),以提高检测精度。目前通用目标检测器在精度上已取得较好效果[2],但是对小目标的检测效果仍然一般。小目标检测是一个备受关注的研究方向,在自动驾驶、遥感图像[3]等实际应用背景中,检测算法面临巨大挑战,很难准确识别出小目标。因此,研究一种用于小目标检测的目标检测算法具有重要的意义。
1 特征金字塔网络(FPN)
在目标检测的发展过程中,专家们对使用单、多尺度特征图进行了不断探索[4]。首先,为利用各个尺度的特征图,对输入图片进行多尺度缩放并制造图像金字塔。其次,对每个尺度的图片进行提取特征图和目标检测,但是这种方法训练时间过多,被很快弃用。再次,有专家选择使用卷积网络直接对输入图像进行多层卷积和池化,得到最终特征图并对其进行检测,但是这种方法仅对顶层特征图进行检测,导致特征过于单一,会忽略其他特征层。从次,有专家沿用之前对图片进行卷积网络的方法,对每一层卷积得到的特征图均进行检测,得到金字塔型特征层,虽然这种方法利用了每一层的特征图且训练时间不多,但是也没有充分利用各层的特征。
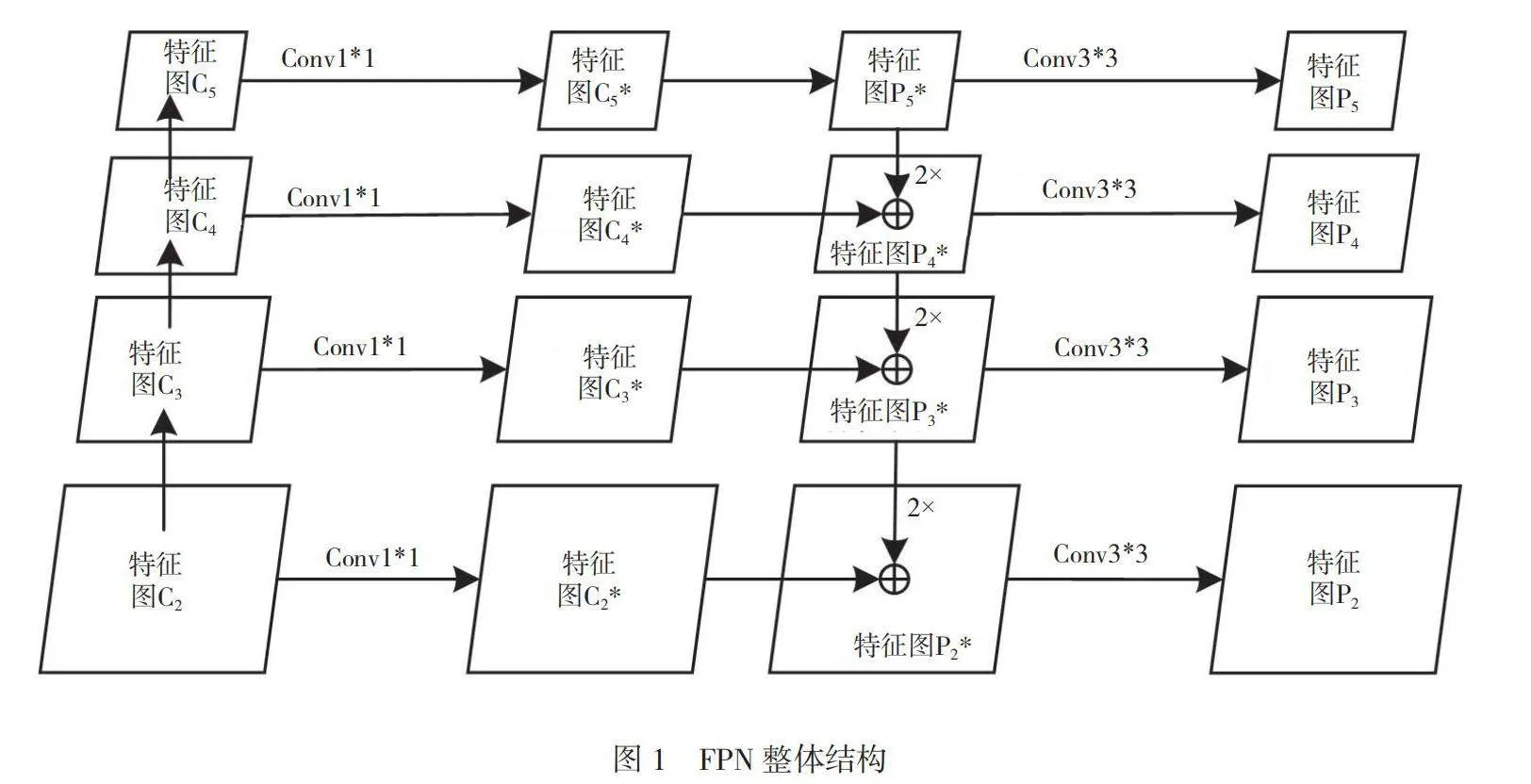
为了更好地处理不同尺度的目标、充分利用各层特征,本文提出多尺度融合算法,以进一步提升检测效果,即特征金字塔网络(FPN)。FPN不仅利用了不同尺度的特征图,还在自上而下融合过程后大幅度改进了浅层特征;在提高整体检测效果的同时,小目标精度也有了明显提升。FPN由自底向上、自顶向上和横向连接3个部分组成。FPN整体结构如图1所示。
1.1 自底向上
此部分为主干卷积网络的输出(以ResNet50为例),将每个阶级最后的残差块结果作为FPN的输入,记为{C2,C3,C4,C5}。
1.2 自顶向下
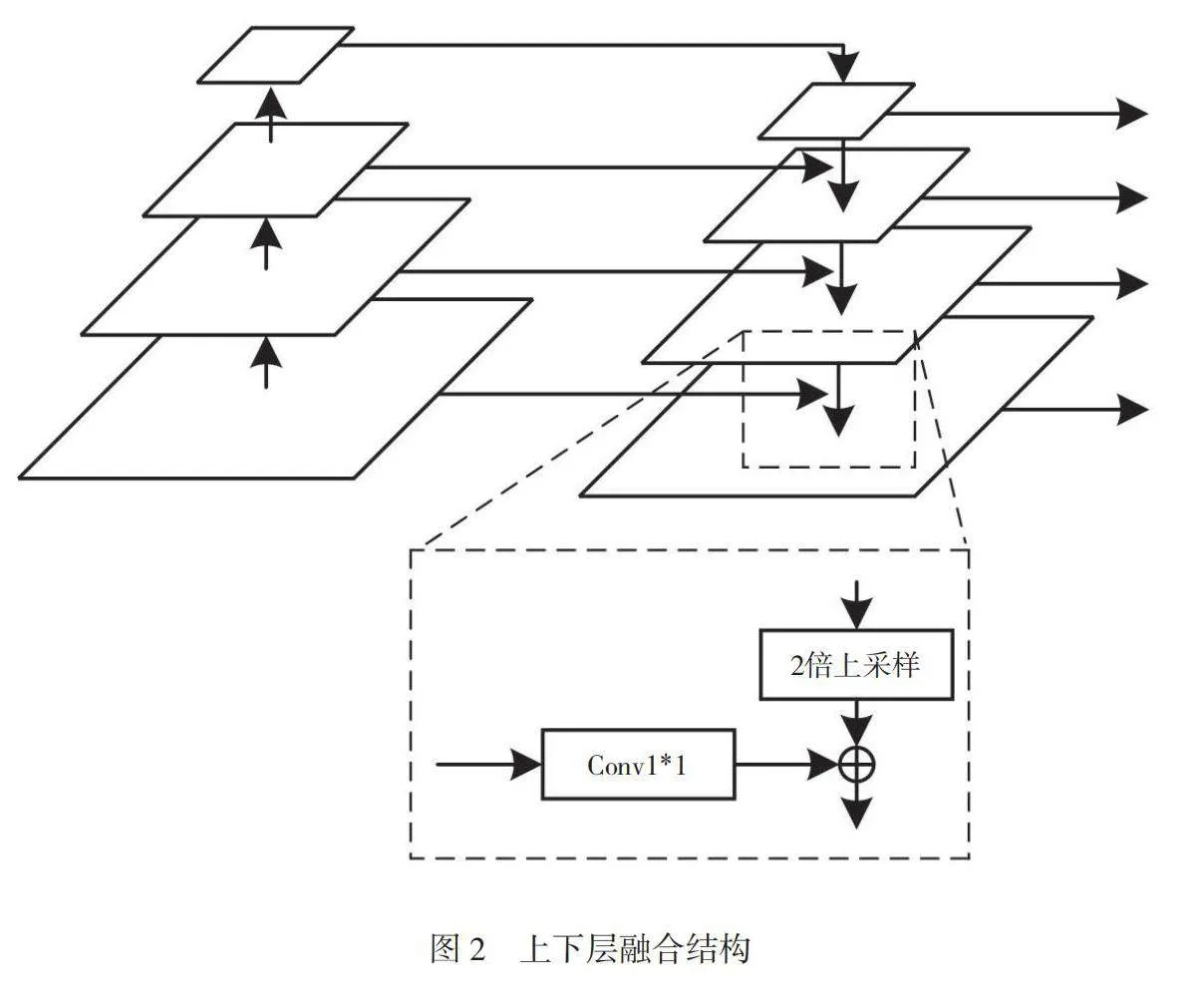
此部分是将上一层进行二倍上采样的特征图与此层的特征图相融合得到此层特征图。具体过程如下:将经过1*1卷积的P5*(等同于C5*)进行2倍上采样,再将其与下一层的C4*相加得到P4*。同理,C2*、C3*经过自顶向下融合后分别得到P3*、P2*。上、下层融合结构如图2所示。
1.3 横向连接
此部分包括2个部分。第一是对输入特征图{C2,C3,C4,C5}分别进行1*1卷积,得到{C2*,C3*,C4*,C5*}。第二是在自上而下特征融合后,对{P2*,P3*,P4*,P5*}进行3*3卷积,得到特征金字塔的最终输出{P2,P3,P4,P5}。
2 改进的FPN
目前已有一些对小目标特性进行改进的算法[5]。有的专家采用过采样含有小目标的图像并重复粘贴复制小目标的方法,对小目标检测进行数据增强。有的专家采用对FPN添加融合因子并控制自上向下传递的特征量的方法,得到使每层融合到更适合特征的带有S-α的检测器。有的专家设计新的特征级超分辨率,将其作为训练时的监督信号,并匹配相对感受野,更精准地对小目标进行监督。还有的专家采用分配多尺度特征融合权重并加入约束大目标的抑制块的方式,使小目标保留更多的细节和特征。
本文针对小目标的特性,对FPN进行改进。虽然FPN进行了特征图的多尺度融合,并已经利用较低层的特征来提高对小目标的检测精度,但是其还存在一些问题,例如顶层特征图缺少上、下文信息融合、小目标特征不够丰富等。本文以顶层特征增强和添加小目标层的方式对FPN进行改进,以期取得更好的小目标检测效果。
2.1 顶部特征增强模块
2.1.1 混合注意力机制(CBAM)
注意力机制一直是目标检测中被广泛使用的方法。2018年,有专家提出了一种新的注意力机制,即CBAM。这是一种混合注意力机制,它从通道和空间2个方面出发,顺序使用通道注意力和空间注意力,使输入特征图在通道维度和空间维度上均获得更好的处理。CBAM由2个部分组成,即通道注意力模块CAM和空间注意力模块SAM。CBAM结构如图3所示。
CAM对输入的形状为(B,C,H,W)的特征图分别进行最大池化和平均池化,得到2个形状为(B,C,1,1)的特征图。再将两者送入共享感知机(MLP)进行处理,将得到的结果相加。最后利用Sigmoid函数得到每个通道的权重系数,并将权重与输入特征图相乘,得到通道注意力特征图F。
SAM将经过CAM模块调整的特征图F沿通道轴分别进行最大池化和平均池化,得到形状为(B,1,H,W)的2个特征图。再对2个特征图进行通道拼接,由卷积降维,得到通道数为1的特征图。最后利用Sigmoid函数得到每个空间位置上的权重系数,并与特征图F相乘,得到最终的新特征图,将其作为输出。
2.1.2 顶部特征增强
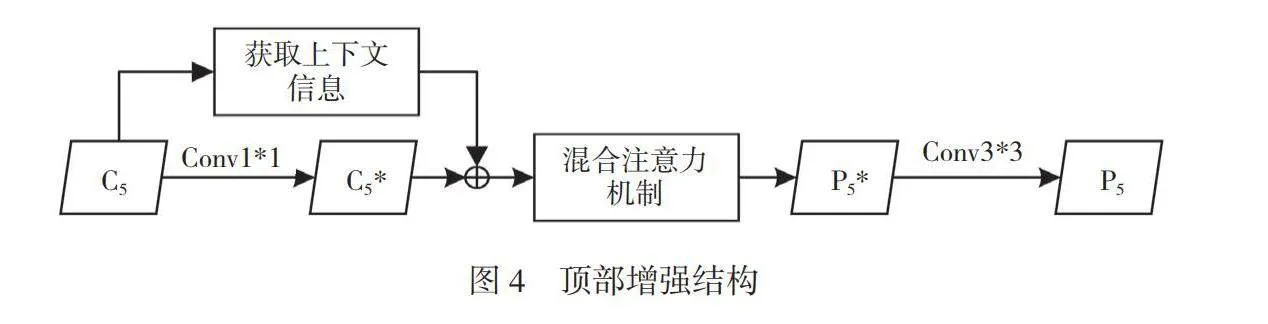
在传统FPN的自上而下融合过程中,最顶层C5*是由获取主干卷积网络的最高层C5并对其进行1*1卷积后得到的特征图,而其他层则是由对上一层特征图进行上采样,再与本层对应的主干网络进行卷积后的特征图相融合得到的,因此只有最顶层特征图的信息是单一的,缺少上、下文特征融合的部分。本文针对此问题,添加了顶部特征增强模块。顶部增强结构如图4所示。
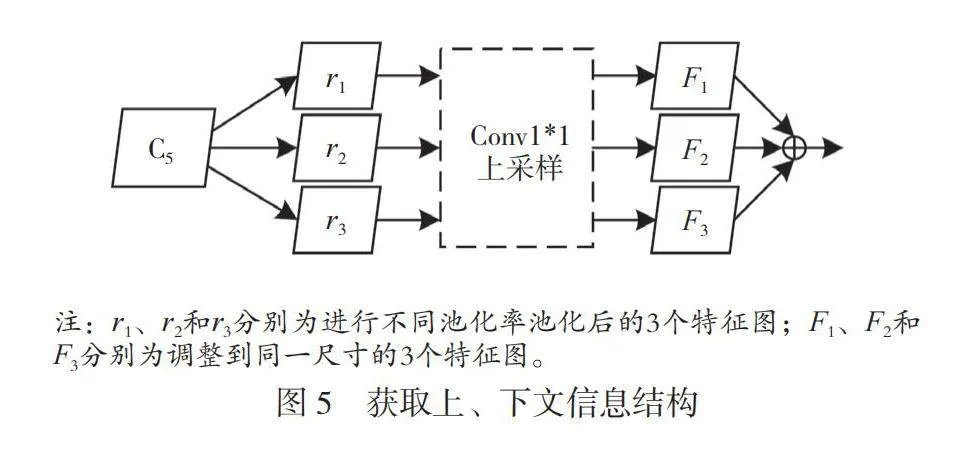
首先,对主干卷积网络的C5层进行比例不变的自适应池化,分别使用0.1、0.2和0.3这3个池化率获取不同空间的上、下文信息,得到3个不同尺寸的特征图r1、r2和r3。其次,将得到的特征图分别进行卷积,对通道进行降维操作。再次,将特征图上采样到同一尺寸,得到3个与C5尺寸相同的特征图F1、F2和F3。将3个特征图进行通道拼接,得到含有上、下文信息的新特征图。获取上、下文信息结构如图5所示。从次,对新特征图与经过卷积降维的C5*进行求和,得到一个融合上、下文信息的顶层特征图。最后,在新得到的顶层特征图中加入混合注意力机制,进一步增强顶层特征,得到P5*。增强特征图P5*会为下一层提供更好的特征,将其进行3*3卷积得到P5,将P5送入下一步的区域生成网络(RPN)后,可提高后续的检测效果。
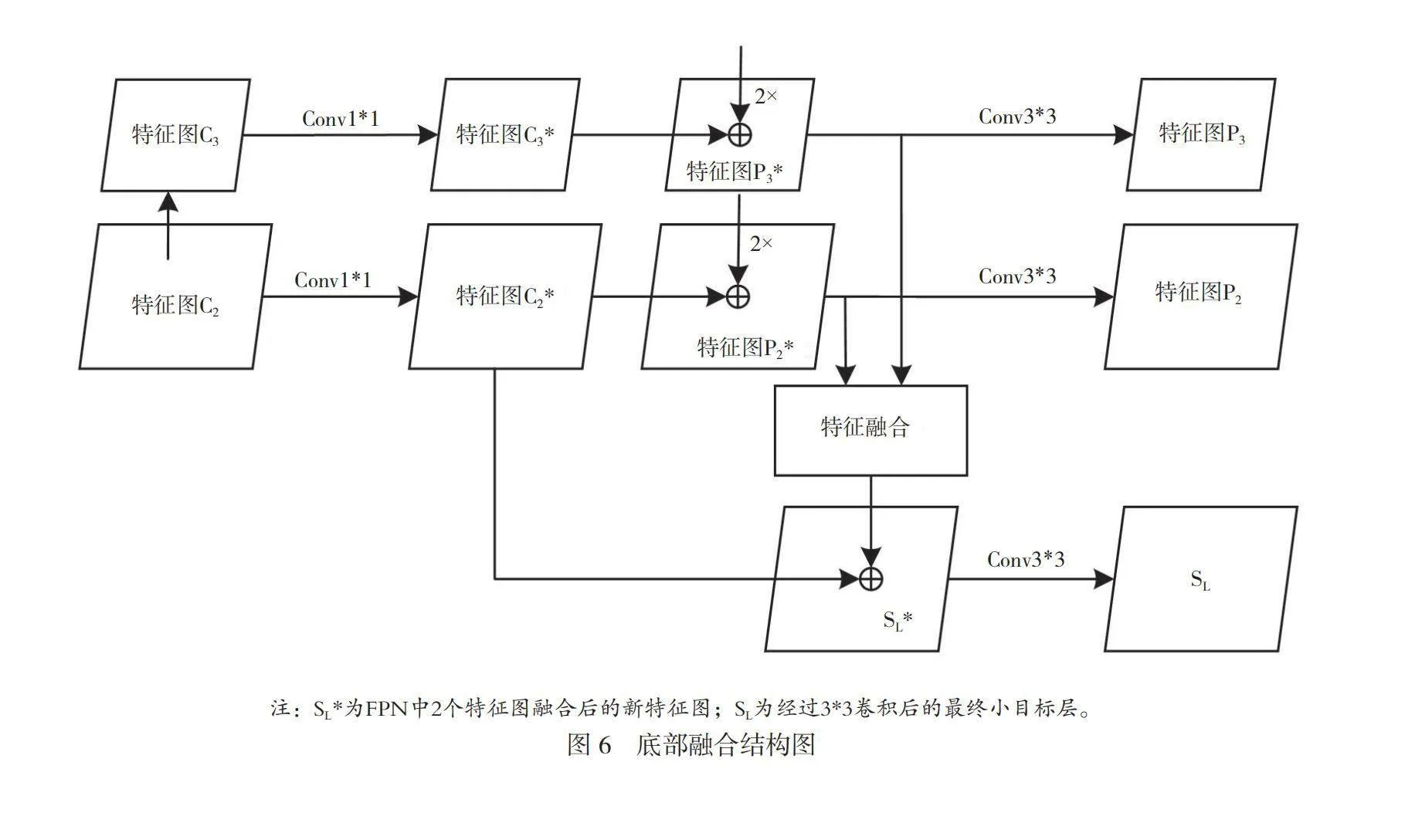
2.2 底部特征融合模块
在图像目标检测任务中,小目标占整幅图像的面积比例较小,很难捕捉到它们的细节信息。并且随着神经网络主干模型越来越深,特征图的分辨率也越来越低,使小目标检测面临挑战。一般深层网络提取到的特征含有更丰富的语义信息,但是小目标相关的特征更多集中在浅层。虽然深层特征具有更强的语义表达能力,但是对小目标来说,它们可能并不是最相关的特征。本文针对小目标语义信息较少的问题设计了底部特征融合模块,选择FPN中的C2层和C3层,将低分辨率特征图的深层语义与高分辨率特征图的浅层区域细节相融合,得到更适合小目标的特征金字塔层SL。底部融合结构如图6所示。
首先,对FPN的P3*层进行卷积,使通道数扩大为原来的4倍,提高特征图的表达能力。其次,使用由1*1卷积和ReLU激活函数组成的卷积块进行多次迭代,提取P3*的特征,获取其主要语义信息。再次,利用像素重排,将其通道数变为原来的1/4、空间维度扩大2倍,以此来提高特征图的分辨率。再将提高分辨率的特征图P3*与P2*进行通道拼接,得到1张新的特征图。从次,将得到的特征图使用1*1卷积和ReLU激活函数组成的卷积块进行多次迭代,提取浅层特征图中的可靠细节信息。最后,将高分辨率的特征图P3*与具有浅层特征信息的特征图进行像素叠加结合,得到新的用于小目标的FPN层,该层不仅包括浅层特征中的细节信息,还包括从深层中获得的更丰富的语义信息。特征融合结构如图7所示。
将底部融合模块得到的小目标层与C2*相加得到SL*,再将SL*进行3*3卷积得到最终的小目标层SL,由此得到了一个融合深层语义信息与浅层细节信息且包括更多小目标特征的特征层。
2.3 在目标检测器中的应用
以经典两阶段检测器Faster RCNN为例。首先,在原有模型的基础上,将本文改进的FPN连接到主干卷积网络上,得到多层特征图。其次,将其送入下一阶段的区域生成网络(RPN),得到候选框。再次,将候选框和多层特征图一同送入感兴趣区域池化(ROI Pooling),得到相应的特征表示。最后,经过全连接层后,对特征表示进行目标分类和边界框回归,获得最终检测框。改进模型整体结构如图8所示。同理,可将本文改进的FPN应用到其他两阶段目标检测器模型中,以提升小目标检测的效果,成为针对小目标改进的检测器模型。
3 试验结果
3.1 试验环境和参数设置
本文使用Ubuntu 18.04操作系统。硬件采用Intel(R) Xeon(R) Platinum 8352V CPU和显存为24 GB的NVIDIA RTX 4090 GPU;软件选择Python 3.8.0、Cuda11.1。基于Pytorch 1.8.1框架搭建实验平台,并使用开源的目标检测框架MMDetection(v3.2.0)进行模型训练和评估。在训练过程中,选择随机梯度下降(SGD)优化器,动量因子和权重衰减因子分别设置为0.9和0.000 1,初始学习率为0.02,训练迭代12个epoch,每个批量(batch_size)包括2个样本。
3.2 数据集与评估指标
MS COCO数据集是目标检测中使用最广泛的通用数据集之一,将数据集中分辨率小于(32×32)ppi的目标定义为小目标。该数据集包括80个目标类别,并具有大量小目标物体数(标注约有41%的目标面积小于32×32)。目前驾驶安全和自动驾驶技术得到越来越多的关注,因此本文选用COCO 2017数据集中的停车标志类(stop_sign)进行试验。此类共包括1 803张图片,其中训练集为1 734张,验证集为69张。
本文试验使用的评估指标包括平均精度(mAP)、平均召回率(mAR)以及针对小目标的平均精度(mAPs)和平均召回率(mARs)。
3.3 试验结果分析
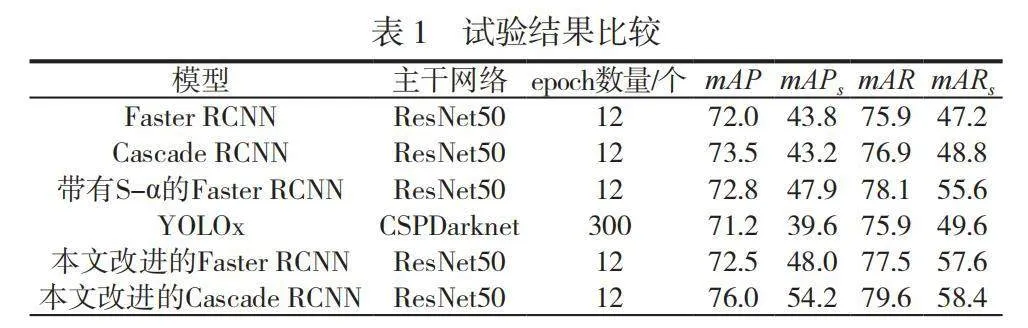
在试验中,将本文改进的FPN分别应用到两阶段检测器Faster RCNN和Cascade RCNN中,评估结果见表1。由表1可知,本文的改进目标检测模型的精度均有所提升,对小目标的检测效果更显著。改进的Cascade RCNN模型的检测精度提升明显,虽然总精度只提高了2.5%,但是对小目标的检测精度却提高了11%。
检测结果比较如图9所示,图9(a)~图9(c)分别为原Cascade RCNN模型的检测结果,图9(d)~图9(f)分别为本文的改进模型检测结果。比较图9(c)、图9(f)可知,原模型并未检测出小停车标志,而本文改进模型不仅能检测出,还具有良好的检测值。
4 结语
针对小目标所在的浅层语义信息不够丰富和FPN顶层缺少上、下文信息的问题,本文提出了改进小目标检测的目标检测器模型算法。该算法对顶层补充上、下文信息并添加注意力机制增强特征,使整个网络的特征进一步增强。并在底层进行深层与浅层特征融合,针对小目标得到了一个语义信息更丰富的浅层特征层。最后与原目标检测器进行对比试验,结果表明,改进模型在一定程度上提升了总精度,大幅提高了小目标的检测精度。
参考文献
[1]ZOU Z,CHEN K,SHI Z,et al.Object detection in 20 years:A Survey[J].Proceedings of the IEEE,2023,111(3):257-276.
[2]张阳婷,黄德启,王东伟,等.基于深度学习的目标检测算法研究与应用综述[J].计算机工程与应用,2023,59(18):1-13.
[3]CHENG G,YUAN X,YAO X,et al.Towards large-Scale small"object detection:Survey and benchmarks[J].IEEE Transactions on pattern analysis and machine intelligence,2023,45(11):13467-13488.
[4]陈科圻,朱志亮,邓小明,等.多尺度目标检测的深度学习研究综述[J].软件学报,2021,32(4):1201-1227.
[5]潘晓英,贾凝心,穆元震,等.小目标检测研究综述[J].中国图象图形学报,2023,28(9):2587-2615.
