基于深度学习的文旅内容命名实体识别研究
2024-12-04王晢宇李红

摘 要:实体是非结构化文本中的重要组成部分,是构成词汇短语的关键内容,每个研究领域通常都有其特定的实体集,因此好的实体识别研究可以帮助人工智能更准确地理解语料内容,对后续的关系抽取和更深层次的语义分析有重要作用。本文为了更准确地从景区文化内容相关文本中提取出具有研究意义和应用价值的命名实体内容,使用改进的RoBERTa预训练模型,结合BiLSTM-CRF模型,提出了一种景区文化内容实体识别的深度学习方法,并完成在该领域应用的模型训练。并将该模型与其他常见实体识别模型进行比较,证明了本方法在这项任务中的优越表现。
关键词:命名实体识别;深度学习;景区文化
中图分类号:TP 391" " " 文献标志码:A
旅游景区文化产业是现代产业体系的重要组成部分。2023年文化和旅游部印发的《国内旅游提升计划(2023—2025年)》提出了“加快智慧旅游发展,培育智慧旅游沉浸式体验新空间新场景”,标志景区文化内容数字化已成为现代化旅游产业下一个阶段发展的主要目标。将计算机技术应用于新型旅游文化体系的建设不仅具有现实价值,还具有创新意义。
1 研究现状
命名实体识别是从文本数据中抽取既定实体信息的技术。专家系统、基于规则和词典的技术是早期的实体识别的常用手段。一些学者基于机器学习提出了新方法。在此基础上,YU等结合KNN分类器和CRF模型构建了半监督的学习框架。与基于机器学习的方法相比,深度学习更有利于发现隐藏特征。
有学者(COLLOBERT R、CHO K和HUANG Z等)提出了长、短期记忆人工神经网络(LSTM)及其变种门控循环单元(GRU)。2018年,李莉双等[1]将BiLSTM模型应用于生物医学数据集上。2021年GHADDAR A[2]提出了一种基于晶格的长短期记忆网络(Lattice-LSTM)模型。可见,通用领域的命名实体识别效果较好,但是专门领域内的研究较少,尤其对旅游文化领域的命名实体识别研究略显不足,这也是本文研究的重点。
2 模型结构
试验模型结构主要由3个部分构成。首先,将标注的语料输入RoBERTa模型中,通过预训练的方式得到高质量的词向量。其次,将训练好的词向量输入BiLSTM网络中进行训练,得到初步的词分类结果与标签。最后,将训练结果输入CRF模型中进行检查和纠错,根据对每个词汇上下文的识别结果和训练相似度修正识别结果,完成整个命名实体识别流程。
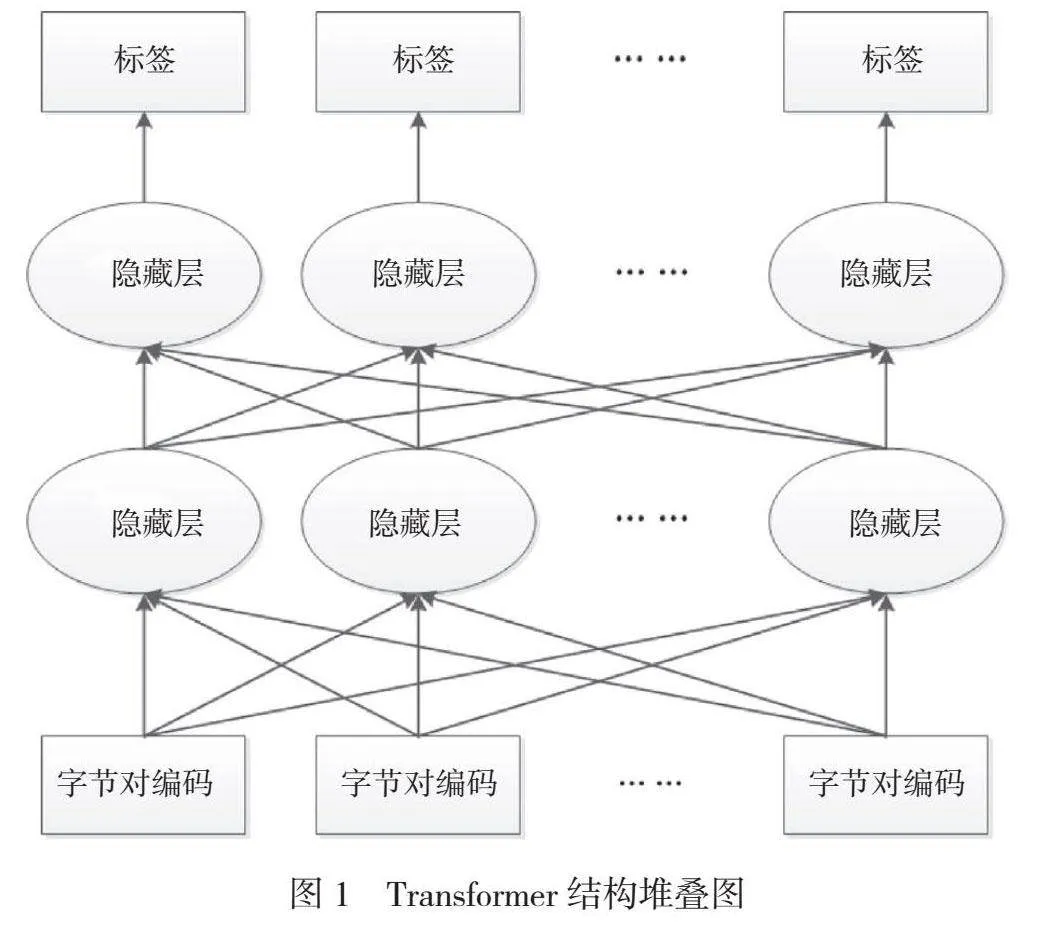
2.1 RoBERTa预训练模型
RoBERTa模型的主体结构由多层Transformer结构堆叠而成,该结构形成了更深层的神经网络模型,如图1所示。通常的预训练模型是单向计算的,该模型只能获取单个方向的上下文信息,并受模型结构的限制,词汇的表征能力不足。该模型最大的不同点是使用了双向的Transformer组件,并将Transformer层堆叠,可以同时得到前向和后向的Token,直接以P(wi|w1,...wi-1,wi+1,...,wn)为目标函数进行训练,进一步形成可以融合前向和后向文本信息的语言表征网络模型。
利用堆叠的Transformer结构,RoBERTa模型会将完整的前后文语段信息作为消息嵌入的一部分,这需要在嵌入层的同时输入字符的词信息、句子信息和位置信息,进而确保输入端获得了词汇的完整语法信息。
RoBERTa的训练过程让丰富的语义信息输入可以充分发挥价值。1)动态mask语言模型。模型在每次向内提供输入时动态地生成mask,用时刻变化的[mask]隐藏掉输入过程中15%的词汇Token。在训练过程中模型发现了随机词被隐藏,获取该位置词信息时必须参考前后文的信息来推断。因为Transformer具有全局可视的特点,同时统计学表明,由于15%的词汇隐藏对试验结果造成的负面影响可以忽略不计,使用这种方法可以提升词前后文的信息获取率。因此每次向模型输入一个序列时都会生成新的掩码模式。在大量数据输入的过程中模型将适应全部掩码策略,学习到最丰富的语言特征。2)字节对编码(BPE)的方式。字节对编码是混合使用了字符级别和单词级别编码的编码方式,目前自然语言处理任务中广泛采用了该编码方式。为了获取更细致的训练信息,模型采用byte BPE对词汇特征进行编码,即用byte级别的实现方式对文本输入进行标记。这一改变使词表长度扩充到了原先的1.6倍,增加了2000万参数量,虽然一定程度上造成了模型效率下降,但是模型的准确率有了可观的提升。
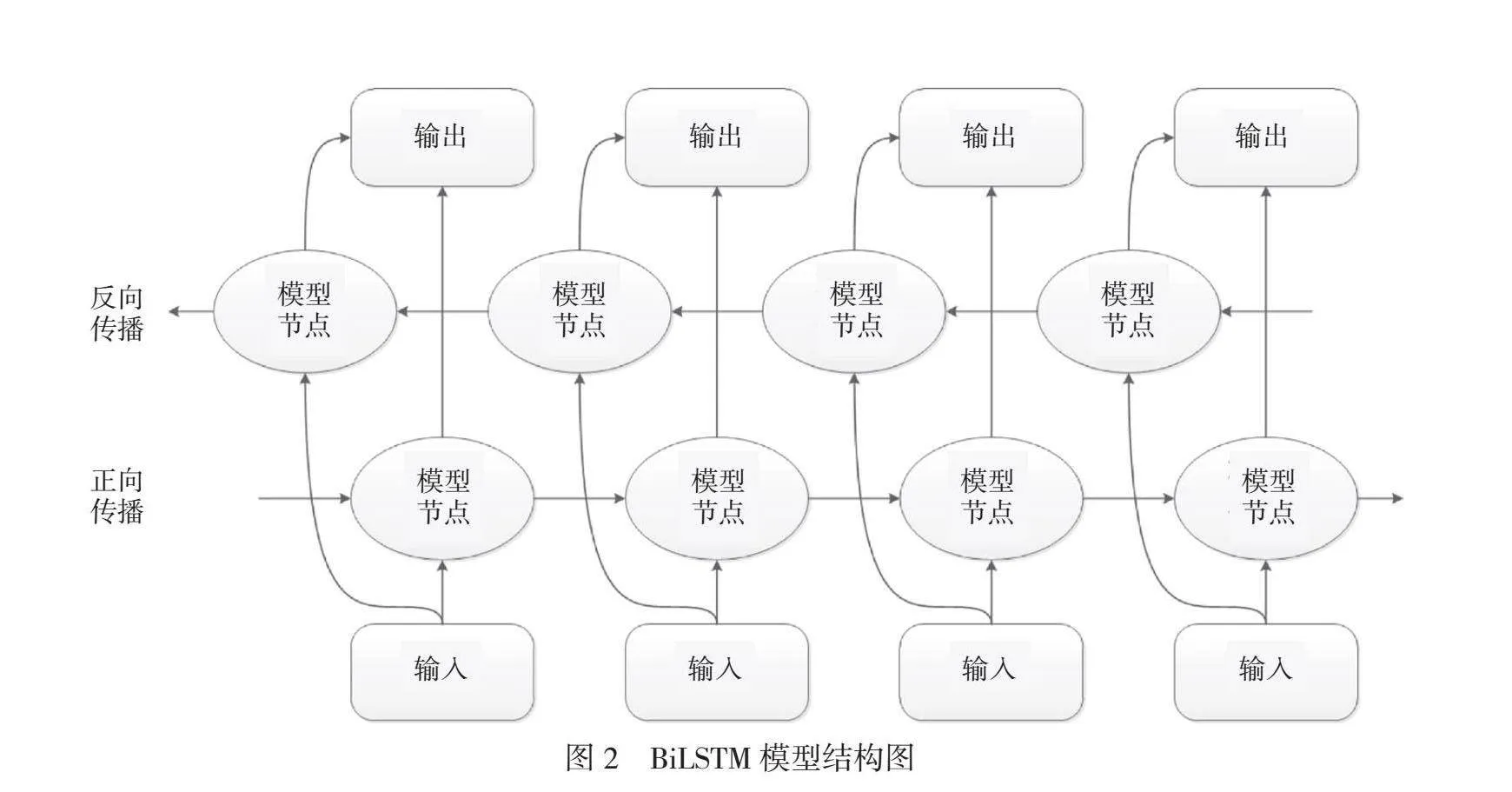
2.2 BiLSTM层
BiLSTM(Bi-directional Long Short-Term Memory)是由2个方向相反的LSTM模型构成的,分别从正向和反向传递模型参数。由于经典的LSTM模型只能获取单向文本信息,而在语言学中一个词语的含义通常受上下文内容的影响,BiLSTM模型的提出巧妙地解决了这个问题。模型最终的输出向量是由正向和反向的模型训练结果拼接而成的,因此该模型具有同时获得词汇前后文信息的能力。
BiLSTM模型结构图如图2所示。BiLSTM由2个反向的LSTM模型组合而成。输入信息是从RoBERTa模型训练得到的特征向量,模型中一部分从前向后处理输入序列,另一部分反向处理输入序列,2个LSTM模型分别互不干扰,计算出各自的训练结果,两者的计算结果只有在各自计算结束后才会进行拼接,进而得到最终输出结果。
对于景区文化领域的命名实体识别的任务,BiLSTM层计算特征向量对应标签的主要模型层。一些传统的试验方法通过Word2Vec或者其他特征向量计算方法获取输入词汇的特征向量,并将其输入BiLSTM模型中进行训练,直接得到分类结果。为了提高试验正确率,本文将RoBERTa作为预训练模型生成输入特征向量,将CRF模型作为下一步试验的模型,既发挥了BiLSTM本身的优势,又规避了模型本身的不足。
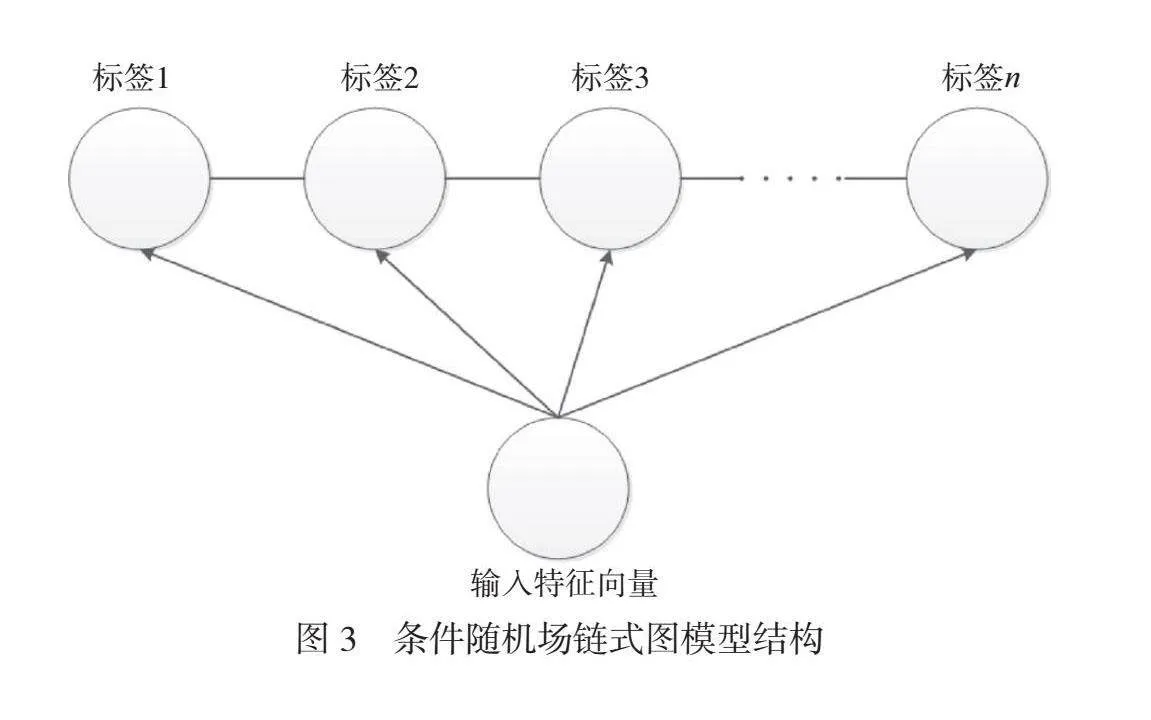
2.3 条件随机场
条件随机场链式图模型结构如图3所示。条件随机场(CRF)本质上是一种用判别式构成的无向图模型。模型根据对概率情况的条件分布进行建模,而不是直接对联合分布进行建模,因此条件随机场可以看作基于条件概率衍生出的一种图结构模型。模型的输入是以组为单位的随机变量,通过模型的计算输出得到另一组随机变量,可用于不同场景下的预测问题。条件随机场的输入和输出的表达式如下:设x={x1,x2,…,xn}为观测序列,对应的标记序列y={y1,y2,…,yn},则条件随机场的目标函数可以记作P(y|x)。
3 试验过程
3.1 数据集和数据预处理
本文使用的训练语料来源于网络公开数据,包括中国旅游网、文旅部政务门户以及各大景区官网等平台。借助信息提取技术从网页中获取10124篇文章,经过筛选,剔除掉重复、低质量文章后,剩余5000篇文章。将这些文章顺序打乱,防止相近内容过于集中,使用分词技术将文章以词短语为单位分开,最后使用开源的命名实体标注工具标注全部内容。人工审核标注的准确性后,将标注好的数据集按照7∶2∶1的比例划分为训练集、验证集和测试集。
本文进行标注时选用经典的BIO体系,其优点是简洁高效,识别结果可以更直接地转化为关系抽取任务需要的数据格式。BIO是B(Beginning)、I(Intermediate)和O(Other)的缩写,其中“B”表示一个实体开头位置上的字符,“I”表示实体从中间到结尾的字符,“O”表示非实体的部分字符。文化数据与其他领域不同,其实体是描述景区要素的特定实体类型。
根据对景区语料特征的研究,本文将命名实体分为5类:名称(Name)、时间(Time)、行为(Denoter)、位置(Location)和对象(Object)。根据上述5类实体构造BIO标签,得到11个预定义标签类型,见表1。
3.2 评价指标
命名实体识别任务主要包括实体边界划分和实体类型标注2个部分。预测结果正确的标准是预测得到的实体结果边界、实体类型与实际标签的实体边界、类型完全一致。评价指标采用NER常用的评价指标,即Accuracy(精确率)、Precision(准确率)、Recall(召回率)和F1值,分别如公式(1)~公式(4)所示。
(1)
(2)
(3)
(4)
式中:Accuracy为分类器或者模型对整体样本判断正确的能力;Precision为分类器或者模型正确预测正样本精度的能力;Recall为分类器或者模型正确预测正样本全度的能力;F1值为Precision和Recall的加权调和平均;TP为真正类,表示实体标注正确且被预测为正确结果的数量;TN为真负类,表示实体标注错误且被预测为错误结果的数量;FP为假正类,表示实体标签本身是错误的,但是被预测为正确结果的数量;FN为假负类,表示实体本身标注正确,但是被预测为错误结果的数量。
3.3 试验结果
根据本节叙述的实体识别要求与评估原则,对5次重复试验各项结果取平均值后,本文使用的RoBERTa-BiLSTM-CRF模型在增强的CEC数据集命名实体识别任务中的整体标注精确率为94.47%,准确率为92.36%,召回率为90.87%,F1值为91.61%。5种命名实体分别的识别结果见表2。
3.4 对比试验
为了验证本模型在领域实体识别任务上的优势,本文在同一数据集与命名实体类型的基础上分别用CRF、BiLSTM、BiLSTM-CRF和BERT-BiLSTM-CRF这4种模型进行对比试验。详细的对比试验结果见表3。
可以看出,简单的CRF和BiLSTM模型取得的结果并不理想。相比较下,BiLSTM-CRF增加了BERT预训练模型后使模型性能得到了明显的提高,F1值提高了8.07%,足以证明预训练模型的引入和优化对自然语言的命名实体识别效果有很大的提升。相比较BERT-BiLSTM-CRF,优化后的RoBERTa模型对试验的四个指标均有一定提升,可以证明RoBERTa比BERT模型效果更好。从结果可以看出本文采用的RoBERTa-BiLSTM-CRF方法取得了最佳的试验效果。
4 结语
本研究描述了景区文化数据领域命名实体识别任务的试验过程。构建了融合预训练模型的RoBERTa-BiLSTM-CRF试验框架,确定了试验模型的参数设定。与当前普遍采用的其他模型相比,本研究的方案更能够获取细颗粒度的实体信息,通过大量的对比试验,从理论和实践的角度验证了本方法的有效性,为景区数据数字化事业供了技术支持。
参考文献
[1]李丽双,郭元凯.基于CNN-BLSTM-CRF模型的生物医学命名实体识别[J].中文信息学报,2018,32(1):116-122.
[2]GHADDAR A,LANGLAIS P,RASHID A,et al.Context-aware"adversarial training for name regularity bias in named entity recognition[J].2021,9:586-604.
