基于深度学习的高铁旅客出行选择行为分析
2024-12-04刘睿






摘 要:在高铁大数据时代,基于海量出行数据对旅客选择行为进行精准建模与预测,不仅可为产品设计提供支持,还可进行差异化运力调整,意义重大。本文融合前沿深度学习技术,聚焦北京沪线的工作日OD票务数据,考量旅客进行选择决策时各类属性(到达-出发站,到达-出发时间等)的综合影响,构建用户偏好模型,通过挖掘属性间的复杂关联模式,对乘客选择行为进行准确归纳与模拟。研究表明,与传统模型相比,该方法可以显著提升选择预测精度。
关键词:出行选择行为分析;深度学习;客票数据;京沪高铁
中图分类号:U 293" " " " " " 文献标志码:A
分析高铁旅客出行选择行为对高铁产品设计和运输组织至关重要。相关研究主要有2类,即基于调查(RP/SP)数据的分解模型和基于客票大数据的聚合模型[1]。张航等[2]利用京沪高铁旅客出行RP调查数据构建了旅客出行计划的MNL模型。陈凯[3]建立高铁公司收入最大化的分时定价模型,并利用遗传算法进行求解,增加了高铁运营企业的客运收益。罗钧韶[4]利用空间匹配算法挖掘车辆出行轨迹,分析乘客出行分布特征等,并将其应用于城市交通规划。随着大数据处理技术发展,马书红等[5]将旅客属性、心理感知和选择行为进行了融合,构建了基于出行链的混合选择模型。黄欣等[6]提出旅客行程服务记录(PSR)概念,设计了铁路电子客票技术方案。强丽霞等[7]基于离散选择框架,建立描述旅客选择行为的模型,阐明了出行分析的回归方法。崔愿等[8]发挥不同数据源的比较优势,构建覆盖多运输方式、旅客流总量和过境比例分析模型。
本文以京沪虹桥高铁平时的车票数据为基础,将车票数据的属性作为深度学习模型的映射特征,研究旅客对不同类型列车的偏好,为运用大数据支撑智能决策奠定基础。
1 高铁旅客选择的影响因素分析
旅客出行选择的影响因素主要有2个方面,即旅客社会经济特征和列车特征。有学者将影响因素分为旅客主因素、列车特性和随机因素,研究了铁路旅客的选择行为,包括到发站、到发站的GDP(万亿元/年)、到发时间、车票票价、乘车时间和座次。此外,列车运力约束和铁路售票策略也会对旅客的实际选择行为产生一定影响。从车票数据中可以反映出许多信息。1)OD里程。2)座位容量。座位容量与票务销售策略有关,列车运力越大,选择乘客的可能性就越大。3)负载系数。负载系数反映了列车张力和列车运力,列车的载客率越高,列车运力越紧张,乘客可选择的自由度越小。4)原点站系数。起源站的车票较多,车票较容易购买,旅客也有较充裕的上车时间和较好的列车环境。5)服务频率。服务频率是一天内相同OD可服务的列车数量,服务频率越高,乘客的选择性自由度越高。6)总人次。总人次反映了旅客对车票的竞争程度。乘客总数越大,竞争越激烈,乘客选择的自由度就越小。
2 基于深度学习的模型概述
2.1 模型概述
深度学习是一种从数据中学习表示的新方法,强调从连续层学习,这些连续层对应越来越有意义的表示。深度学习模型的基础是感知器,感知器接收来自n个其他感知器Xn的输入信号。这些输入信号通过加权连接Wn传输。将感知器接收到的输入值与感知器的偏置bn进行比较,再通过激活函数σ(z)输出感知器结果。它一般有3层或3层以上的神经网络,包括一层输入、一层输出和几个中间层。神经网络各层的输出为σ(WnXn+bn)。
目前,深度学习网络模型主要分为密集前馈网络模型、卷积网络模型和递归网络模型。由于本文中的数据没有考虑时间,并且数据间没有序列关系,因此采用前馈网络模型。深度学习的前馈网络模型可以通过一系列简单的数据转换(层)并由一系列输入特征映射到目标。
本文采用的深度学习前馈网络与上层、下层完全连接,产生的信号向前传输,反馈误差信号向后传输。将计算出的损失函数的输出值作为反馈信号,并对权重和偏置进行微调以减小损失值,直到达到最小损失,从而得到训练好的网络。此调整由优化器完成。
2.2 模型构建
数据处理完成后,将京沪高铁客票数据的属性作为深度学习全连网络的输入特征。通过一系列图层变换,最终映射到选择不同列车的人数,得出不同列车的乘客选择概率。建立深度学习网络模型的步骤如下。
2.2.1 数据处理
数值和文本数据被处理为适合模型输入的张量类型。将列车到达时间-出发时间作为0~1440的分钟数进行处理,并将距离系数扩大100倍,以方便处理,文本数据通过one-hot编码进行处理。在本文中,到达和出发站、座位类型以及是否为始发站均通过one-hot编码进行处理。最后,对每个特征进行标准化处理,即减去输入数据的每个特征(输入矩阵的列)的平均值,将其除以标准偏差,并使特征的平均值为0,标准差为1。
2.2.2 损失函数
在本文中,损失函数为MAE(平均绝对误差),计算过程如公式(1)所示。
(1)
式中:yi为预测选定列车旅客数;xi为实际选定列车旅客数;n为样本数据的大小。
2.2.3 模型超参数调整
模型超参数包括网络层数、每个中间层的节点数以及优化器。深度学习网络模型包括输入层、输出层和若干中间层。为了获得最适合模型数据的网络层,选择相对较少的层(3层)。在本文中,数据经过一次one-hot编码处理后具有64维。因此,选择的中间点必须>64,以更好地表示数据形成的三维空间,并根据平均损耗逐步调整具有不同节点数的网络层中间层,直至平均损耗无明显变化,最终实现中间节点数的最优组合为256-128-64-1。不同网络层的平均最小预测损耗值如图1所示。
从图1可以看出,随着中间网络层数逐渐增加,模型预测的平均最小损耗值逐渐变小,而模型的中间网络层数>7,预测结果没有明显改善,因此模型最终选择了7个中间层的组合。目前,Adam优化器、随机梯度下降(SGD)和RMSprop算法是深度学习模型中的常用算法。根据不同优化器下的损失,选择最合适的模型数据的优化器。通常,RMSprop比SGD具有更好的优化效果,而Adam获得的损失值较小,因此本文将Adam作为该模型的优化器。本文共有5617个训练样本。为了尽快获得最佳质量和偏差并加快训练效率,批量大小选择128。
调试后选择的深度学习模型的超参数结构如下:一层输入,7个中间层,一层输出;每一层的节点分别为输入层-256-128-64-1(输出层);优化器是Adam;激活函数选择通常用于机器学习的Relu函数。深度学习开发环境为TensorFlow 2.0 PyCharm。
2.3 参数设置
本文模型中共有5个参数,包括输入序列的时间步长T、预测序列的时间步长T'、高铁站附近的距离阈值D、空间子网的多头注意机制数量K以及时间子网的隐藏状态维数M。设T=18,T'=6,即利用过去3h内多个车站的客流量来预测一个高铁站未来1h内的客流量。将一个高铁站的距离阈值设定为1000m,即预测某一地点的车站未来客流量时,考虑1000m内的高铁站客流对该车站未来客流量的影响。多头注意机制的数量K和时间子网的隐藏状态维数M均设置为16。
3 案例分析
将2019年4月某周二京沪高铁线路的OD客票数据作为训练数据。原因是这段时间列车运力充裕,对乘客限制较少,因此可以尽可能选择自己满意的列车。样本数为5617。将2019年5月的周二作为预测数据,样本总数为5373。为了减少个人主观选择的偶然性带来的误差,对于4月3个周二(20190410、20190417和20190424),以选择不同列车的平均乘客数作为训练数据的目标;对于五一假期后的3个周二(20190508、20190515和20190522),选取平均人数作为预测目标,剔除人数较少(一般<10)的OD,以减少随机误差。部分原始票证数据见表1,数据包括日期、列车、始发站、始发时间到达站、到达时间、里数、座位类型、旅客和票价等。为了更好地分析旅客出行行为,对数据进行扩充和优化,增加服务频次、始发站以及达站GDP等数据,处理后的数据见表2。
由于同一地区的旅客具有相似的选择特征,为了更好地进行分类,利用模糊聚类分析方法,根据到发交通流量、车站节点的位置、经济水平以及人口水平,将京沪高铁线路的站级划分为4个等级。分类结果见表3。
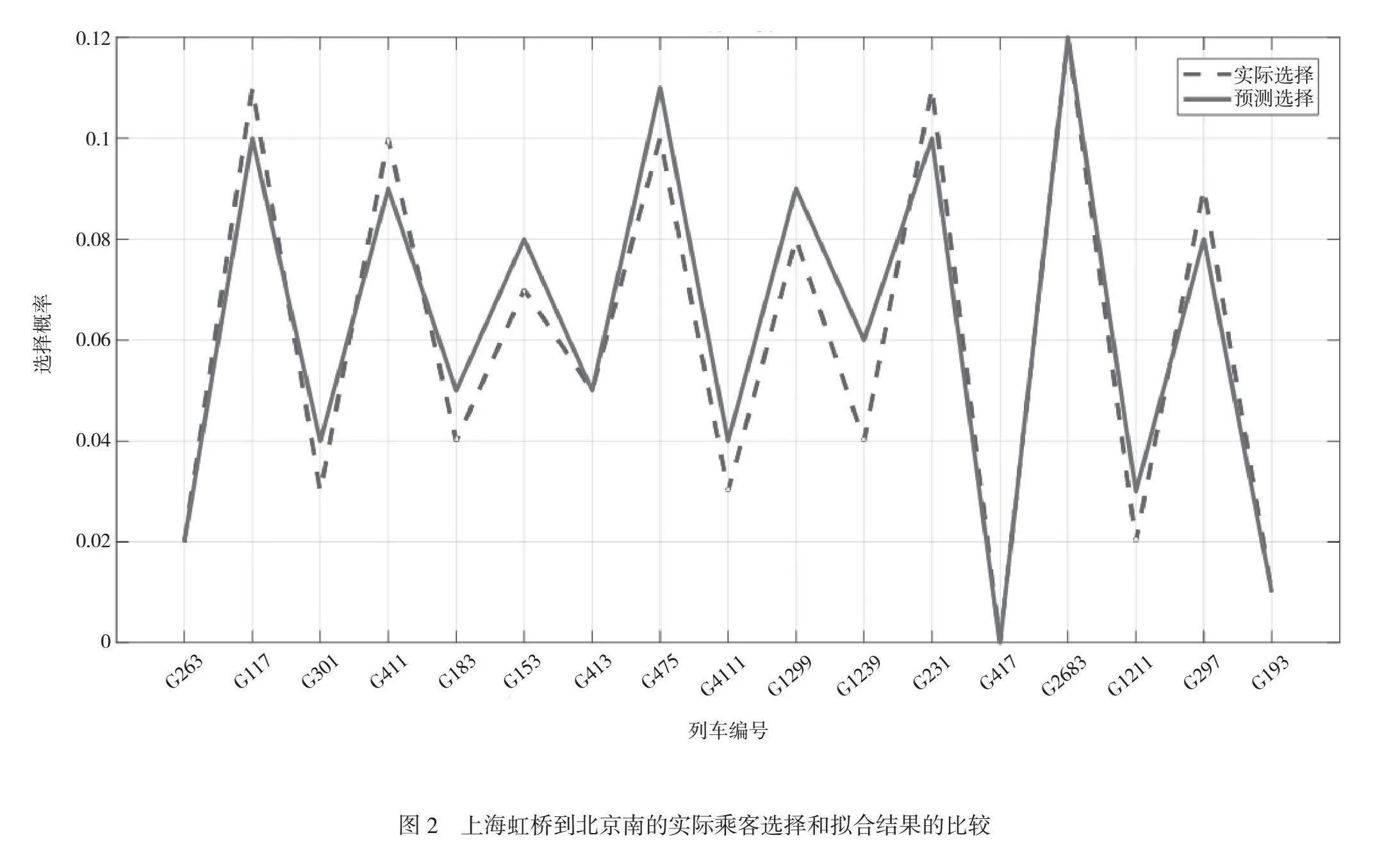
根据客票数据,可以从深度学习网络模型中获得京沪高铁不同ODs不同列车的实际选择概率,并与拟合结果进行比较,总体拟合效果良好。以北京南-上海虹桥为例,实际乘客选择与拟合结果的比较如图2所示。可以看出,深度学习模型在预测上海虹桥到北京南的乘客选择概率方面具有很好的拟合精度。不同节点的不同OD的选择精度数据见表4。
由于头等舱节点通常是相对较大的综合枢纽节点,客流量较多,乘客的出行选择行为非常复杂,并涉及大量影响因素。因此,第一级节点的OD与其他节点间的拟合效果不理想。对于这种类型的OD,在后续的研究中将进一步增加映射特征维度,并增加票数据量,以提高拟合精确度。
4 结论
鉴于独特的模式识别能力和数据规则提取能力,深度学习模型在大量数据的支持下不需要领域知识,越来越多的非参数机器被用于新兴的行为选择研究。本文采用深度学习网络模型对京沪高铁市场进行了分析,将车票数据的属性作为深度学习模型的特征向量,映射出不同类型列车的高铁旅客选择概率。结果表明,深度学习模型可以较好地预测设计指标。本文仅对周二的门票数据进行分析,数据量有限。后续研究可以通过增加特征向量来提高预测精度,并增加数据训练量。
参考文献
[1]曹堉,王成,王鑫,等.基于时空节点选择和深度学习的城市道路短时交通流预测[J].计算机应用,2020,40(5):1488-1493.
[2]张航,赵鹏,乔珂,等.高速铁路旅客出行时间选择Logit模型与分析[J].铁道运输与经济,2017,39(1):55-60.
[3]陈凯.基于旅客出行方式选择的高速铁路客运分时定价方案研究[J].铁路计算机应用,2022,31(9):57-62.
[4]罗钧韶,潘嘉杰.基于GPS数据挖掘的出租车出行特征分析[J].交通与运输,2020,33(增刊2):49-54.
[5]马书红,李阳,岳敏.考虑出行链的城际旅客换乘选择行为研究[J].北京交通大学学报,2020,44(6):74-81.
[6]黄欣,张志强,单杏花,等.基于电子客票的铁路旅客智能出行研究[J].中国铁路,2019(11):1-6.
[7]强丽霞.基于客票数据的高速铁路旅客出行选择行为研究[J].铁道运输与经济,2018,40(4):52-57.
[8]崔愿,陈璟,李可等.基于多源数据的区域综合运输通道旅客出行特征研究[J].公路交通科技,2023,40(1):252-260.
通信作者:刘睿(1993-),甘肃兰州人,工程师,研究方向为电力能源、城市轨道交通运输工程。
电子邮箱:3382300395@qq.com。
