中文多字体古籍数据集多任务融合识别
2024-11-05薛德军师庆辉毕琰虹芦筱菲陈婧王海山吴晨




摘 要:针对中文古籍数字化处理中大规模高质量数据集匮乏的问题,本文提出了一种新颖的2级古籍数据集建设方法:一是构建了包含119.5万张图片、覆盖6 610个字符类别的多字体古籍单字数据集CACID;二是基于古籍文献内容合成了包含86 667列古籍文字图片的古籍篇章数据集CASID,这是目前报道的最大中文古籍合成数据集。本文设计了古籍多任务融合识别模型,并基于所建数据集进行了实验。结果表明,模型的识别准确率从35.62%显著提升至85.52%,验证了涵盖多字体多朝代的中文合成数据在古籍文字识别中的核心作用和良好泛化能力。
关键词:古籍;训练数据集;自动构建;深度学习模型;融合建模
中图分类号:TP391.43 DOI:10.16375/j.cnki.cn45-1395/t.2024.04.014
0 引言
随着国家对古籍数字化工作的日益重视[1],古籍文献的数字化不仅成为保护历史文化遗产的重要手段,更是推动文化传承与创新的关键一环。近年来,随着古籍研究的不断深入,人们对于古籍文献价值的认识愈发深刻,对古籍数字化的需求也日益迫切。同时,随着人工智能技术的快速发展,越来越多的AI技术被应用到古籍数字化工作中,为古籍的保护与传承注入了新的活力[2]。
尽管AI技术在古籍数字化中发挥了重要作用,但数字化性能的提升仍然受到高质量古籍数据集缺乏的制约。目前,古籍数字化数据集的建设主要依赖于传统的人工标注方法,这不仅耗时耗力,而且标注质量难以保证,导致数字化效果不佳。同时,由于古籍文献的特殊性,如文字表现形式丰富、纸张老化发黄、页面存在污渍等问题,使得古籍图像分析与识别成为一项非常具有挑战性的任务[3-4]。
针对上述问题,本文提出了一种新颖的2级古籍数据集建设方法:一是构建了包含119.5万张图片、覆盖6 610个字符类别的多字体古籍单字数据集CACID,为字符识别提供丰富资源;二是基于古籍文献内容合成了包含86 667列古籍文字图片的古籍篇章数据集CASID,进一步扩展数据集的规模和多样性。此外,在构建好的数据集基础上,本文设计了古籍多任务融合识别模型,并基于所建数据集进行了实验。结果表明模型的识别准确率得到大幅度提升,从而验证了高质量大规模古籍合成数据在古籍文字识别中的核心作用和良好泛化能力。
1 数据集构建
在古籍数字化进程中,数据集的构建至关重要[5]。古籍汉字形态丰富多样,包括象形图、书法字、刻板印刷、馆阁体及活字印刷等,其多样性和复杂性增加了识别难度,尤其是书法字,其书写风格的多样性和笔画的流动性更是识别的难点。
由于古籍资源稀缺且标注成本高昂,获取真实、高质量的标注数据变得异常困难。因此,合成数据成为主流的获取训练数据的手段,即通过模拟古籍文字图像并添加标签,构建古籍文字数据集。
鉴于此,本文提出2级古籍数据集建设方法。首先,构建古籍单字数据集(CACID),专注于收集古籍中的单个汉字图像,以支持精确的汉字识别研究。其次,构建古籍篇章数据集(CASID),通过合成方式模拟古籍排版和格式,呈现连续文本段落,以提供接近实际阅读场景的古籍图像数据。这2个数据集的结合,全面覆盖从单个汉字到连续文本段落的古籍内容,为古籍数字化中的文字识别、版面分析等任务提供丰富多样的数据资源。
1.1 单字数据集构建
中国书法的字体丰富多样,包括甲骨体、大篆、小篆、隶书、草书、楷书、行书等。在构建古籍单字数据集时,首先对单字图像进行预处理,去除背景、增强文字部分,并转换成黑白二值图像;其次,按命名规则对预处理后的图像进行标注,将同标签、同字体的图像进行整合;最终形成多字体CACID数据集。
该数据集包含119.5万张图片,涵盖6 610个文字类别,每个文字类别包含多种书法字体。CACID数据集的采样实例图如图1所示(示例为“书”的楷书、行书、草书、隶书、篆书字体)。
1.2 篇章数据集构建
篇幅图像生成是基于古籍文本生成含有单字标注的篇幅级古籍文字图像。其中,针对每一份古籍文本,可生成多份篇幅级古籍文字图像与之对应,以楷书体、行书体、草书体、隶书体、篆书体等多种形式呈现。
本文整理了中文重要古籍文本300余篇,包括《晋书》《宋书》《南齐书》《梁书》《陈书》《魏书》《北齐书》《周书》《隋书》《南史》《北史》等,用作生成篇幅级古籍文字图像的真实文字标签。构建古籍篇章数据集CASID是一个复杂且精细的过程,涉及多个步骤以确保数据的准确性和多样性。以下是该构建流程的详细步骤。
Step 1 字符提取与识别
在构建数据集的开始阶段,首先从文字版古籍内容中提取每一个拟使用的字符。随后,在古籍单字数据集CACID中查找这些字符的对应图像。为了保证合成数据的丰富性和多样性,根据字体等标签随机选择字符图像。如果在CACID数据集中找不到某个字符的图像,记录下这个缺失的字符,并继续寻找下一个字符。
Step 2 字符图像二值化
经过提取和识别后,对每一个字符图像进行二值化处理。这一步骤的目的是将字符图像转换为只包含黑白像素点的形式,以便于后续的合成和处理。在二值化过程中,设定一个阈值(如200),图像中灰度高于此值的部分会转换为白色,低于此值的部分则转换为黑色。
Step 3 调整字符尺寸
为了确保所有字符在视觉上保持一致和协调,需要对每个字符图像进行尺寸调整。具体来说,调整字符图像的宽度或高度,使其不超过设定的像素值(如80像素)。此外,根据字符中黑色文字的像素个数进一步缩放调整,比如根据黑色占比的不同,将字符缩小到适当的比例。
Step 4 背景图与文字定位
为了模拟真实环境,准备多个与古籍背景相似的图像作为合成背景。这些背景图像经过调整,达到统一的像素大小(如1 110×2 110像素)。然后,在这些背景图像上定位出文字的排列位置。按照古籍的阅读顺序(右上至左下),确定每个文字的中心点位置,并设置适当的间距,以确保文字的整齐排列。
Step 5 文字与背景融合
文字与背景定位完成后,将每个字符图像的中心点与背景图像上的文字中心点对齐。通过二值与“bitwise_and”操作将字符图像融合到背景图像中。因此,每个字符都会准确地出现在预定的位置上,形成一幅完整的古籍篇章图像。
Step 6 记录字符位置
最后,为了便于后续的数据分析和处理,记录每个字符在最终合成图像中的位置信息。这通常包括字符的左上角和右下角坐标等数据。这些位置信息有助于快速定位和分析字符在图像中的分布情况。
通过以上6个步骤,本文构建出一个古籍文字图片与文本标签对应的古籍篇章数据集CASID,共86 667列古籍文字图片数据和对应的列文本标签,涵盖字符类别6 610个,总计包含104.1万字,这是目前公开报道的最大规模的中文合成古籍篇章数据集。生成的篇幅古籍图像实例如图2所示(示例为三皇本纪 小司马氏撰并注的篇幅图像)。
2 文字识别模型
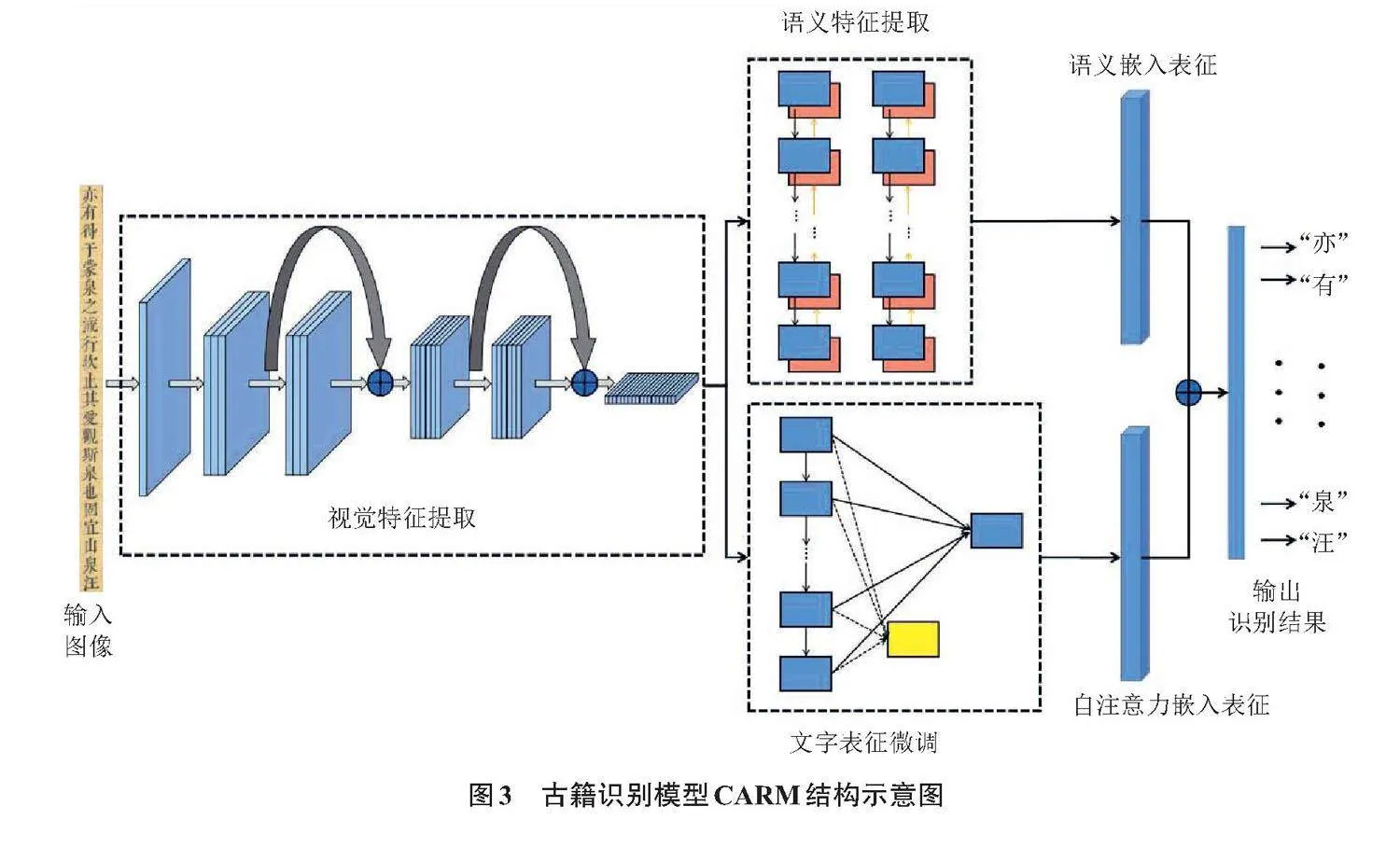
本文设计了古籍多任务融合识别模型CARM,模型结构示意图如图3所示。
2.1 视觉特征提取
在经典残差模型[6]的基础上,本文引入了通道混淆、分组卷积以及深度可分离卷积技术,旨在保障模型深度的同时拓展其宽度,进而增强通道间的信息交互与依赖关系学习。网络结构采用模块化设计,通过5种不同模块与卷积的组合堆叠,构建了一个18层的模型。此外,在模块单元间实现了多尺度特征融合[7],将模型的计算复杂度控制在2.3 G FLOPs(floating point operations per second)以内,以确保在不显著增加计算负担的前提下,实现模型性能的优化。
2.2 语义特征提取
在传统序列识别结构[8]的基础上融入语义信息,结合双向多门循环网络[9]与双向自注意力模型[10-11],通过联合调节网络内所有神经层的前后神经元,对卷积网络提取的图像特征进行深度双向表达学习。如此,不仅实现了对图像特征的降维语义编码,并在不同层级上进行了多轮迭代学习,从而使模型深入挖掘图像特征中的语义表征信息与关联信息。
2.3 多阶段多任务训练策略
为提升模型在形近字、繁体字、异体字识别上的精度及复杂背景的应对能力,本文设计了多阶段、多任务训练策略。
初始阶段,混合使用合成与真实数据训练模型,以纠正合成样本带来的特征偏差。随后,利用模型识别文字类别的核心表征,并用真实数据进行文字表征微调,确保学习到的文字表征与对应类别的核心表征尽可能接近,而与其他类别的核心表征保持较远距离[12],以此确保文字表征的准确性和区分度。最后,根据专业人员的反馈优化系统,并据此扩充和筛选数据再次训练,以进一步提升模型性能。
3 实验结果
3.1 实验设置与数据集
本实验中的训练数据由两部分组成:真实古籍数据集CARD和合成古籍篇章数据集CASID。CARD数据集来源于传统的古籍文献资源,共399万字符,包括来自《四库全书》约10万列文字图像,约189万字符,以及来自刻版印刷书籍(包括《晋书》《宋书》等多部史书)约10万列文字图像,约210万字符。两类数据共4 285个字符类别,样本实例图如图4所示。基于这些数据构建相应的训练集和验证集,训练得到CARM-Base模型。
本文基于不同的数据集训练了2个识别模型:一是基于CARD数据集构建相应的训练集和验证集,训练得到CARM-Base模型;二是在CARD数据集中加入CASID数据集共同作为训练数据,构建相应的训练集和验证集,训练得到CARM-Large模型。
在测试阶段,选用100张真实的古籍图像作为模型测试集,共计1 345列。其中,随机抽取520列进行标注,包含8 865字。测试集数据未参与上述训练集的构建,因此可以客观评估模型的泛化性能。测试集数据实例图如图5所示。
3.2 评估指标
本文采用的评估指标为[Wc](字正确率)和[Wa](字准确率)。[Wc]的计算如式(1)所示,
[Wc=Nc/Nr+Nd+Nc×100%], (1)
式中:[Nc]为模型正确识别并保留的字符数;[Nr]为模型错误将一个字符替换为另一个字符的数量;[Nd]为模型错误删除的字符数量。
[Wa]的计算如式(2)所示,
[Wa=Nc-Ni/Ni+Nd+Nc×100%], (2)
式中:[Ni]为模型错误插入到文本中的字符数量。
[Wc]只关注模型保留正确字符的能力,不看其是否插入额外字符;[Wa]既考虑保留正确字符,又考虑是否插入不必要字符。因此,模型若插入过多额外字符,即使正确识别许多字符,其准确率也会受影响。
3.3 结果分析
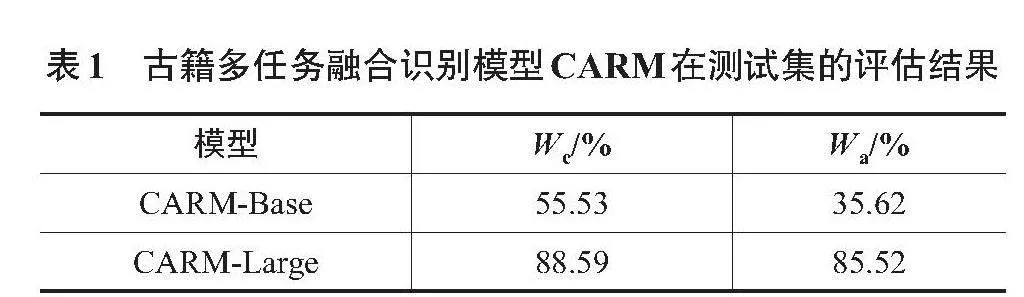
在测试集上,本文对CARM-Base和CARM-Large这2个模型进行了评估。测试集的识别结果实例图见图6,模型的性能评估结果见表1。
从实验结果可以看出,CARM-Large在测试集上的表现显著优于CARM-Base。CARM-Large的字正确率达到了88.59%,比CARM-Base的55.53%提升了59.53%;CARM-Large的字准确率为85.52%,比CARM-Base的35.62%提升了140.09%。2个指标的大幅度提升意味着CARM-Large在识别古籍文字时能够更好地处理各种复杂的字符特征,更准确地还原古籍文本的内容。
CARM-Large性能显著提升主要归功于在训练过程中充分利用了多书法字体古籍数据集CASID。CASID的引入不仅丰富了训练样本的多样性,还使得模型能够更好地适应不同字体和风格的古籍文字。实验结果充分验证了使用合成数据可以大幅提升古籍识别模型的识别能力和泛化性能,可以解决古籍文字识别中训练数据缺乏的问题。
此外,本文分析了构建古籍单字数据集CACID后,数据集中单字分布的变化情况。原数据集包含4 285个单字类别,样本数量分布不均,存在明显的长尾现象。经过扩充,字符类别的总数增长至6 610个,增长了近55%,显著丰富了数据集字符的多样性。
具体到字符来看,一些原来样本较少的字符在扩充后得到了显著增加。例如,“商”字的样本数量从1 102个增加至3 191个,增长了近2倍;“簡”字从695个增加至4 075个;“趺”字从2个增加至48个等。这些字符样本数量的提升有助于模型在训练过程中学习到其字体特征,从而提高识别性能。
但是,一些罕见字符的样本数量增长并不明显。例如,“旈”字从1个增为2个,这说明对于这些罕见字符,现有的扩充策略还不够有效。这些发现为后续改进和优化古籍文字识别模型提供了重要的指导方向。
4 结论
本文针对中文古籍数字化处理中大规模高质量数据集匮乏的瓶颈问题,提出了一种新颖的2级古籍数据集建设方法,并成功构建了CACID和CASID 2个数据集。古籍单字数据集CACID的构建丰富了古籍字符的种类和样本数量,为模型训练提供全面和多样的数据支持;古籍篇章数据集CASID的合成则基于实际古籍文献中的文字布局和排列方式,有助于模型在实际应用中适应复杂多变的古籍识别场景。
本文设计的古籍多任务融合识别模型在构建数据集上的实验结果表明,模型的识别准确率从35.62%显著提升至85.52%,验证了涵盖多字体多朝代的文字合成数据在实际应用中具有优异的识别能力和泛化能力。
本文通过对数据集中单字分布变化的分析,发现模型在识别罕见字符和复杂布局时的性能仍有待提升,这是本文后续需要重点改进的方向。
参考文献
[1] 全国古籍整理出版规划领导小组. 2021—2035年国家古籍工作规划[R]. 2022.
[2] 王秋云.我国古籍数字化的研究现状及发展趋势分析[J].图书馆学研究,2021(24):9-14.
[3] 李国新.中国古籍资源数字化的进展与任务[J].大学图书馆学报,2002(1):21-26.
[4] 周迪,宋登汉.中文古籍数字化开发研究综述[J].图书情报知识,2010(6):40-49.
[5] 李春桃,张骞,徐昊,等.基于人工智能技术的古文字研究[J].吉林大学社会科学学报,2023,63(2):164-173.
[6] HE K M,ZHANG X Y,REN S Q,et al.Deep residual learning for image recognition[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition,2016:770-778. DOI:10.1109/CVPR.2016.90.
[7] MA N N,ZHANG X Y,ZHENG H T,et al.ShuffleNet V2:practical guidelines for efficient CNN architecture design[C]//15th European Conference on Computer Vision(ECCV),Munich,Germany,September 8-14,2018. Proceedings,Part XIV,2018,11218:122-138.
[8] SHI B G,BAI X,YAO C.An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(11):2298-2304.
[9] SCHUSTER M,PALIWAL K K.Bidirectional recurrent neural network[J].IEEE Transactions on Signal Processing,1997,45(11):2673-2681.
[10] MINJOON S,ANIRUDDHA K,ALI F,et al.Bidirectional attention flow for machine comprehension[C]//International Conference on Learning Representations,2016.
[11] CUI Y M,CHEN Z P,WEI S,et al.Attention-over-attention neural networks for reading comprehension[C]//55th Annual Meeting of the Association-for-Computational-Linguistics(ACL),2017. DOI:10.18653/v1/P17-1055.
[12] SCHROFF F,KALENICHENKO D,PHILBIN J.FaceNet:a unified embedding for face recognition and clustering[C]//IEEE Conference on Computer Vision and Pattern Recognition(CVPR),2015,Boston,MA,USA. DOI:10.1109/cvpr.2015.7298682.
Multi-task fusion recognition of Chinese multi-font ancient literature dataset
XUE Dejun, SHI Qinghui, BI Yanhong, LU Xiaofei, CHEN Jing, WANG Haishan, WU Chen
(Tongfang Knowledge Network Digital Publishing Technology Co., Ltd., Beijing 100192, China)
Abstract: To address the scarcity of large-scale, high-quality datasets for digitizing Chinese ancient literature, this paper introduces a novel two-tiered approach for dataset construction. Firstly, we establish a multi-font Chinese ancient character image dataset(CACID), containing 1.195 million images across 6 610 character categories. Secondly, we synthesize the Chinese ancient synthetic image dataset(CASID)which consists of 86 667 columns of ancient text images, based on authentic ancient literature content. This is currently the largest synthetic dataset for Chinese ancient literature reported. Then, we design a multi-task recognition model tailored for ancient literature and experimentally verify its effectiveness using our constructed datasets. The experimental results show a remarkable enhancement in recognition accuracy, with the model,s recognition rate soaring from 35.62% to 85.52%. This significant improvement verifies the excellent generalization capability of the synthetic data, encompassing diverse fonts and dynasties, in practical applications.
Keywords: ancient literature; training dataset; automatic construction; deep learning model; fusion modeling
(责任编辑:黎 娅)
收稿日期:2024-04-10;修回日期:2024-04-24
基金项目:国家重点研发计划(2020YFC0833003);国家卓越行动计划(WKZB1911BJM501173/02)资助
第一作者:薛德军,博士,高级工程师,研究方向:自然语言处理、深度学习、大模型,E-mail:xuedejun@cnki.net
