基于深度学习的人体姿态估计与追踪
2024-11-04张雪芹朱荟潼王宁






摘要:随着深度学习技术的发展,基于卷积神经网络的人体姿态估计和追踪的准确率得到大幅提高。但在面对遮挡问题时,还存在人体关键点检测困难、姿态追踪精度偏低和速度较慢等问题。本文针对这些问题,构建了一个ybasTrack 多人姿态估计和追踪模型;提出采用一种改进的YOLOv5s 网络进行目标检测;采用BCNet 分割网络区分遮挡与被遮挡人体,限定人体关键点定位区域;基于Alphapose 的SPPE(Single-Person Pose Estimator)进行改进,优化人体关键点检测结果;采用改进的Y-SeqNet 网络进行行人重识别,采用MSIM(Multi-Phase IdentityMatching)身份特征匹配算法对人体框、人体姿态和人体身份信息进行匹配,实现人体姿态追踪。实验表明,所提算法对遮挡场景下的人体姿态估计和姿态追踪具有较好的效果,模型运行具有较快速度。
关键词:人体姿态估计;AlphaPose;YOLOv5s;BCNet;SeqNet
中图分类号:TP391 文献标志码:A
基于机器视觉的人体姿态估计指的是从输入的图像或视频中定位出人体关键部位,如眼、肩、肘和膝等,并通过关键点之间的连接构建人体骨架,从而形成对人体姿态的表达。基于机器视觉的人体姿态估计和跟踪能够使计算机更好地理解人类行为,进而为许多应用场景提供支持,比如人机交互、运动捕捉和行为检测等。传统人体姿态估计和跟踪的方法使用人工设计的图像特征检测人体关键点,受限于提取特征的完备性和准确性,精度往往不高。近年来,随着深度学习技术的迅速发展,基于深度学习的人体姿态估计和跟踪算法成为研究热点。相较于传统方法,基于深度学习的人体姿态估计和跟踪方法具有较好的鲁棒性和更高的准确率。
在多人姿态估计方面, Papandreou 等[1] 提出了G-RMI 模型, 该方法使用Fater RCNN 进行人体检测,采用ResNet 对每个人体预测密集热图和偏移,通过融合两者的结果得到人体关键点的定位。Chen等[2] 基于GlobalNet 和RefineNet 提出了级联金字塔网络(Fcascaded Pyramid Networks,CPN),利用GlobalNet进行基本的人体关键点检测,利用RefineNet,通过卷积和下采样融合多分辨率的特征图,使得姿态估计模型对于复杂背景或遮挡关键点的估计准确率得到提高。Zhang 等[3] 提出了一种名为DARKPose 的方法,该方法采用分布感知解码技术,通过改进标准坐标编码过程,降低了编解码过程中关键点坐标变换产生的误差。Fang 等[4] 提出一种名为AlphaPose 的多人姿态估计模型,使用YOLOv3 作为人体检测器,并在单人姿态估计SPPE(Single-Person Pose Estimator)部分提出一种对称变换空间网络(Symmetric SpatialTransformer Network,SSTN),可以从不准确的边界框中提取高质量的单人区域。
在多人姿态跟踪方面,Zhang 等[5] 提出了一种实时目标跟踪网络Ocean,使用无锚点目标网络与特征对齐模块相结合,直接预测人体的位置和比例,该方法可以纠正不精确的边界盒预测,学习对象感知特征以提高匹配精度。Yan 等[6] 提出了一种多人姿态估计和跟踪框架LightTrack,使用YOLOv3 作为目标检测器, 基于结构化图卷积网络( Structured GraphConvolutional Networks, SGCN)进行人体姿态匹配,相比于其孪生网络跟踪算法Ocean,LightTrack 的结果在达到了与之相似精度的同时,计算量和参数量分别下降了97.4% 和92.3%。Fang 等[7] 在AlphaPose的基础上附加一个行人重识别分支,使得该网络可以同时估计人体姿态和重识别特征,设计了一种姿势引导注意机制( Pose-Guided Attention Mechanism,PGA)来增强人体的身份特征,并使用多阶段身份匹配算法(Multi-Phase Identity Matching,MSIM)集成人体的检测框、人体的姿态以及身份信息,实现了多人姿态估计和跟踪。Wang 等[8] 提出了一种基于Transform 的姿态引导特征分离方法( Pose-guidedFeature Disentangling,PFD),利用姿态信息对人体关节部分进行拆分,选择性地匹配非遮挡部分,强调可见身体部位的特征。Bazarevsky 等[9] 提出BlazePose姿态追踪框架,由于人脸相对于全身而言不容易被遮挡,而且在神经网络中该部分的响应值通常是较高的,因此使用面部检测器代替人体检测器解决密集人群中遮挡严重的问题。Chen 等[10] 提出了遮挡感知掩模网络(Occlusion-Aware Mask Network,OAMN),可以使模型有效关注人体区域而非背景区域,让现有的注意力机制能够不受遮挡物体的影响,从而精确地捕捉身体部位。
以上方法证明了深度学习方法在人体姿态估计和跟踪中的有效性,但是,在实际应用中,对复杂场景中的多目标、小目标和遮挡问题,姿态估计和跟踪的准确率和速度仍有待提高。针对上述问题,本文提出了一个基于人体姿态估计框架AlphaPose、YOLOv5s 目标检测网络、YoloBCNet 分割网络与SeqNet 行人重识别网络的人体姿态估计和追踪框架ybasTrack。针对多人姿态估计,在人体检测中,在YOLOv5s 的Neck 部分添加小目标检测模块,改进模型因下采样倍数较大、丢失小目标特征信息的缺点;在关键点检测中,使用三重注意力(TAM)改进关键点空间信息丢失问题,采用AdaPool 池化改进模型参数量较大问题以及下采样造成的特征信息丢失问题。针对多人姿态追踪,在行人重识别模块,提出基于改进的SeqNet 网络构建行人重识别分支,采用弱监督预训练框架(PNL) 预训练SeqNet 网络,得到更准确的re-ID 特征表达。
1 多人姿态估计与追踪框架
针对遮挡场景下的人体姿态估计和姿态追踪任务,本文构建了一个基于目标检测、关键点检测、图像分割和行人重识别的多人姿态估计与追踪框架ybasTrack,如图1 所示。
本文所提出的多人姿态估计与追踪框架ybasTrack的基本原理如下: ( 1)人体检测( Human detection)。使用改进的YOLOv5s 网络检测画面中所有的人体区域位置,得到的人体区域框作为后续人体分割网络与行人重识别网络的输入。(2)人体分割(Humansegmentation)。根据人体检测阶段得到的人体区域,使用BCNet 分割网络对多人体实例进行像素级分割,分别得到遮挡人体的分割区域和被遮挡人体的分割区域。(3)姿态估计(Pose estimation)。使用改进的Alphapose 姿态估计模型,对于人体分割阶段得到的遮挡人体进行关键点检测;对于被遮挡人体,利用人体分割阶段得到的分割区域约束检测到的候选关键点的位置。(4)行人重识别(Pedestrain recognition)。提出基于改进的SeqNet 网络构建行人重识别分支,采用弱监督预训练框架( Pre-training frameworkutilizing Noisy Labels,PNL) 预训练SeqNet 网络,得到更准确的re-ID 特征表达。(5)身份特征匹配(Identityfeature matching)。对于人体检测阶段得到的人体区域框、姿态估计阶段得到的人体姿态和行人重识别分支得到的行人重识别特征,使用身份特征匹配算法MSIM 进行匹配,最终输出姿态追踪结果。
1.1 多人姿态估计
本文提出的多人姿态估计方法(命名为ybaPose),包括人体检测、人体分割和姿态估计3 个模块。
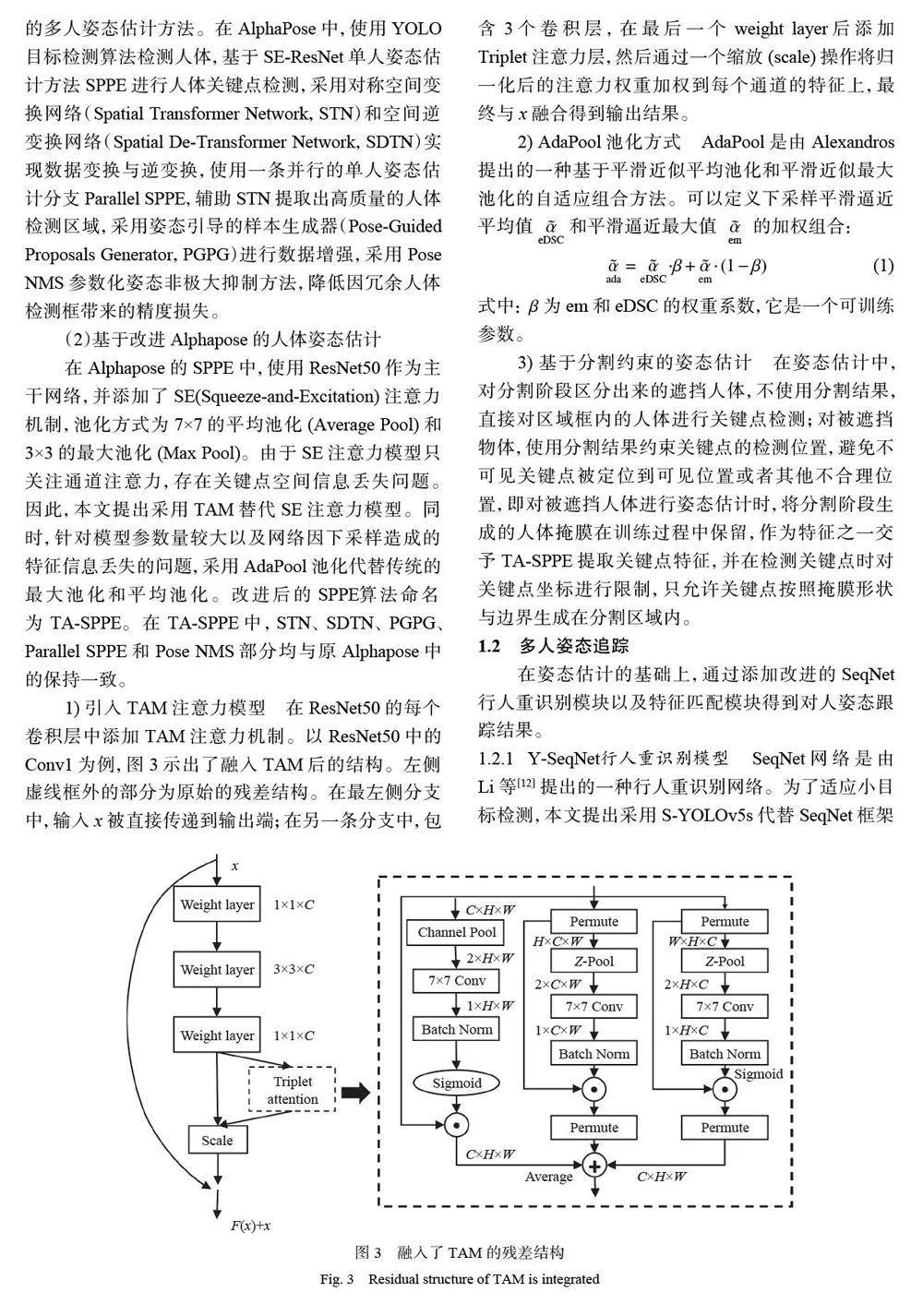
1.1.1 基于改进的YOLov5s的人体检测算法 YOLOv5s是YOLOv5 系列中复杂度最小、速度最快的模型,本文提出采用YOLOv5s 作为多人姿态估计模型中的人体检测器,使模型在维持较低复杂度的同时还能保持较高的检测精度。考虑到实际多人姿态估计中许多目标人体尺寸很小,而YOLOv5s 的下采样倍数比较大,较深的特征图难以有效学习到小目标的特征信息, 因此本文提出在YOLOv5s 的Neck部分添加小目标检测模块,使较浅层特征图与深层特征图融合后再进行检测。改进后的YOLOv5s 命名为S-YOLOv5s,结构如图2 所示,其中CBL 模块由卷积层、批归一化层和激活函数LeakyReLu 组成,CSP1_X 模块由卷积层和X 个残差单元组成,CSP2_X 模块由CBL 模块、残差单元以及卷积层组成,SPP 模块采用1×1、5×5、9×9 和13×13 的最大池化方式,进行多尺度特征融合。
图2 中红色虚线框内为新增加的小目标检测模块,该模块在YOLOv5s 中的Neck 部分的最后一次上采样后,继续对特征图进行CSP2_1、CBL 和上采样操作,然后将上采样后的特征图与Backbone 中第2 层特征图进行融合,以此来获得更大的特征图。改进后的YOLOv5s 最终输出的特征图大小有152×152、76×76、38×38 和19×19 这4 种尺寸,分别对应检测4×4以上、8×8 以上、16×16 以上和32×32 以上尺寸的目标。
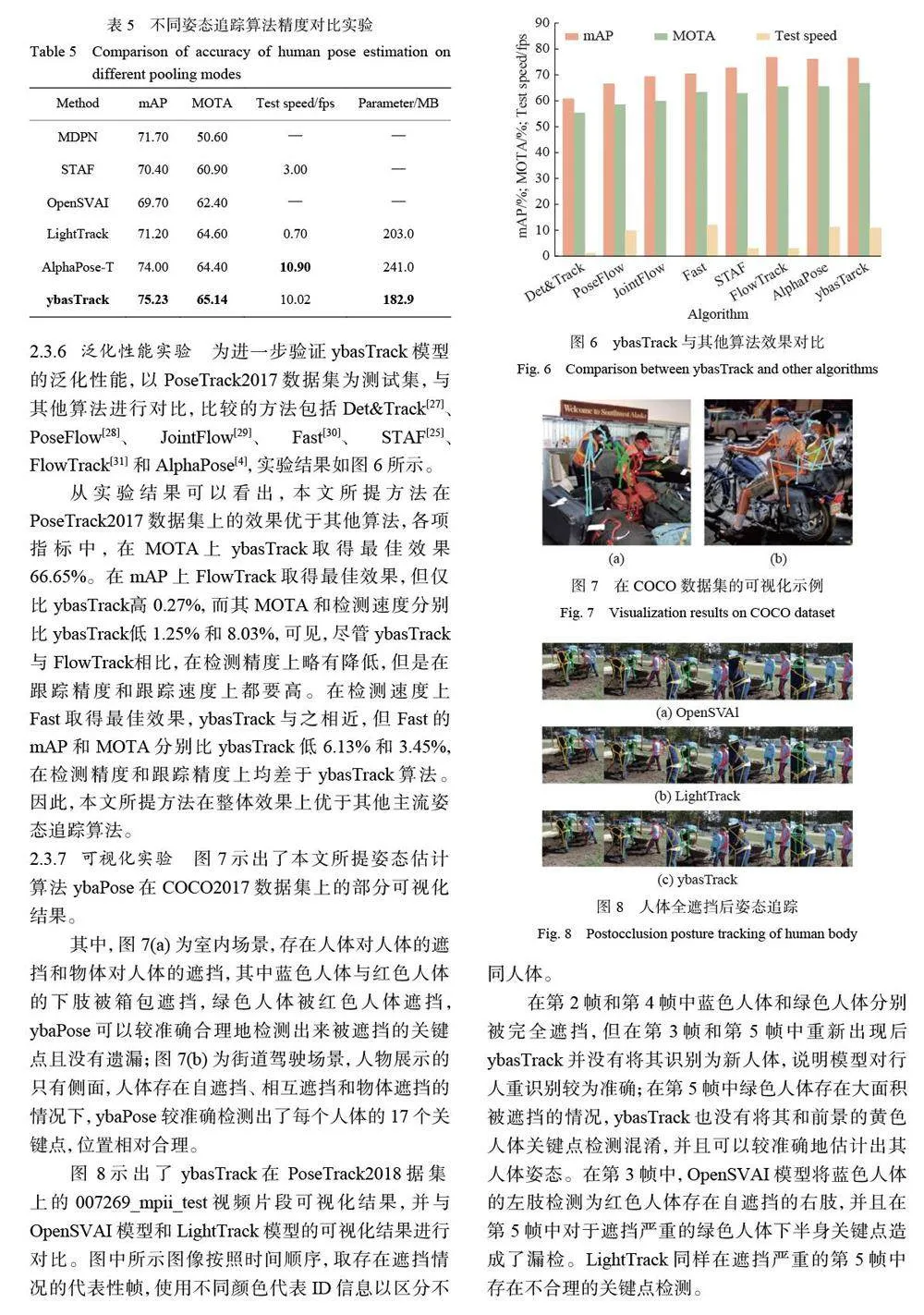
1.1.2 基于BCNet的人体分割 BCNet 是Ke 等[11] 提出的一种应用于遮挡场景下的轻量级双图层实例分割网络,具有较好的分割精度,本文采用BCNet 进行遮挡目标人体分割。BCNet 将图像中感兴趣区域建模为上、下两个重叠的图层,其中上方图层检测遮挡目标,下方图层检测被遮挡的对象。这种显式建模方式可以将遮挡与被遮挡目标的边界进行解耦,并在掩膜和边界预测的同时考虑遮挡与被遮挡关系之间的干扰,使得现有图像实例分割模型在复杂遮挡场景中的处理效果得到了显著提升。
