双视角数据下移动应用BUG报告识别方法研究
2024-10-18彭春雨郑尚邹海涛于化龙高尚


摘" 要: 为了快速而准确地识别其中的BUG报告将有助于开发人员对移动应用进行修复,通过调查移动应用运行的不同阶段,以用户反馈和问题报告两个视角为切入点,提出基于深度学习的移动应用BUG报告自动识别方法,即首先使用Word2Vec获取词向量,其次,构建Bi-LSTM网络获取高级文本特征,并通过注意力机制分配权重以捕获句子中对BUG报告识别起到关键作用的信息,最后获取问题报告的BUG标签.实验结果表明所提方法在准确率、召回率、F1-score和查准率上均有提高,有助于开发人员准确识别移动应用的BUG报告,提高BUG修复效率.
关键词: 移动应用;软件维护;问题报告;用户反馈;BUG标签
中图分类号:TP311""" 文献标志码:A""""" 文章编号:1673-4807(2024)01-068-07
DOI:10.20061/j.issn.1673-4807.2024.01.011
收稿日期: 2021-12-28""" 修回日期: 2021-04-29
基金项目: 国家自然科学基金项目(62176107)
作者简介: 彭春雨(1996—),女,硕士研究生
*通信作者: 郑尚(1983—),博士,副教授,研究方向为智能化软件工程. E-mail:szheng@just.edu.cn
引文格式: 彭春雨,郑尚,邹海涛,等.双视角数据下移动应用BUG报告识别方法研究[J].江苏科技大学学报(自然科学版),2024,38(1):68-74.DOI:10.20061/j.issn.1673-4807.2024.01.011.
Research on mobile APP BUG report recognitionmethod by dual-perspective data
PENG Chunyu,ZHENG Shang*,ZHOU Haitao,YU Hualong,GAO Shang
(School of Computer, Jiangsu University of Science and Technology, Zhenjiang 212100, China)
Abstract:Identifying the BUG reports quickly and accurately will help developers to repair mobile applications. Therefore, we propose an automatic identification method of mobile application bug reports based on deep learning by investigating the different stages of mobile application operation and taking user reviews and issue reports as the starting points. Firstly, Word2Vec is used to get word vectors; secondly, a Bi-LSTM network is constructed to obtain high-level text features. Furthermore, we assign the weight through the attention mechanism to capture the information in the sentence that plays a key role in the identification of the bug reports. Finally we get the bug label of the issue report. Our method is better than the methods proposed in previous works in terms of rate, and this study expounds the impact of datasets from different perspectives on mobile application BUG report identification, which helps developers to identify mobile application BUG reports accurately and improve the efficiency of BUG repair.
Key words:mobile application, software maintenance, issue report, user review, BUG label
随着移动终端的大范围普及,涌现了数以万计的移动应用,其维护显得尤为重要[1].在移动应用的维护过程中,BUG修复是重要任务之一,通过调查发现问题报告与软件维护有着紧密的联系.文献[2]通过分析三百多万个GitHub上的开源项目,发现问题报告可以帮助开发人员解决现存问题,其中,BUG报告所描述的BUG应该及时解决,以保证软件的质量[3].文献[4]提出基于N-gram的自动分类模型以识别BUG报告.
除问题报告之外,研究人员认为用户反馈中包含重要信息[5],其中与BUG相关的描述可用作移动应用问题报告的辅助信息.文献[6]使用包含BUG信息的用户反馈来辅助开发人员进行移动应用维护.文献[7]利用数据挖掘技术分析用户反馈,从而辅助开发人员进行软件维护.
随着移动应用的问题报告或用户反馈的增多,为了开发人员能够快速准确地识别出BUG报告,文献[8]采用TF·IDF, Word2Vec和MCG计算问题报告和BUG报告之间的相似度,进而识别未标记问题报告中的BUG报告.文献[9]设计了一种混合相似度用于计算未标记报告与BUG文本的相似性,根据经验阈值完成对未处理问题报告的标注工作.文献[10]设计了CaPBUG框架,该框架使用自然语言处理和机器学习算法,用以识别BUG报告及优先级排序.
文中以移动应用的用户反馈和问题报告两个视角为切入点,提出基于深度学习的BUG报告识别方法,即首先利用Word2Vec中的Skip-gram模型进行词向量表示,其次融合Bi-LSTM网络和注意力机制构建BUG报告识别模型.此模型不依赖传统文本挖掘方法,避免频繁的相似度计算,提高了识别的准确度,降低了时间消耗.通过开源数据集验证,在准确率(accuracy)、召回率(recall)、F1-score、查准率(precision)和时长方面均有较优表现.同时,对于移动应用的BUG报告识别,文中分析了问题报告和用户反馈的影响并给出适用性意见,即在移动应用运行不同阶段分析的重点,这将有助于移动应用的效能得到提高,并促进移动应用开发领域的技术迭代.
1" 基础知识
1.1" Word2Vec
Word2Vec算法[11]降低了词向量维度,避免了维数灾难.Word2Vec包含CBOW和Skip-Gram两种模型.鉴于问题报告和用户反馈的撰写方式不同,文本使用Skip-Gram模型进行词向量处理.
1.2" Bi-LSTM
传统的循环神经网络(recurrent neural network,RNN)在处理长序列模型时存在长期依赖问题,长短期记忆网络[12](long short-term memory,LSTM)通过改进神经元的内部结构,处理长序列时不会再出现梯度消失的情况.然而单向网络只能捕获前文信息,忽略了后文的信息.因此双向网络结构[13-14](Bi-directional network)通过构建两个独立且相同的神经网络来学习目标词汇与前后文的关系.文中使用双向LSTM[15](Bi-directional LSTM,Bi-LSTM)作为实现BUG报告识别任务的模型.
1.3" 注意力机制
注意力机制(attention mechanism)源于对人类视觉的研究,使得神经网络具备挑选重要特征的能力.带有注意力机制的神经网络具备直观性、通用性和可解释性.文中考虑Bi-LSTM模块后加入注意力层[16],使得模型选择性地关注序列中具有重要语义信息的权重向量,进一步提高模型的识别精度.
2" 双视角数据下移动应用的BUG报告识别方法
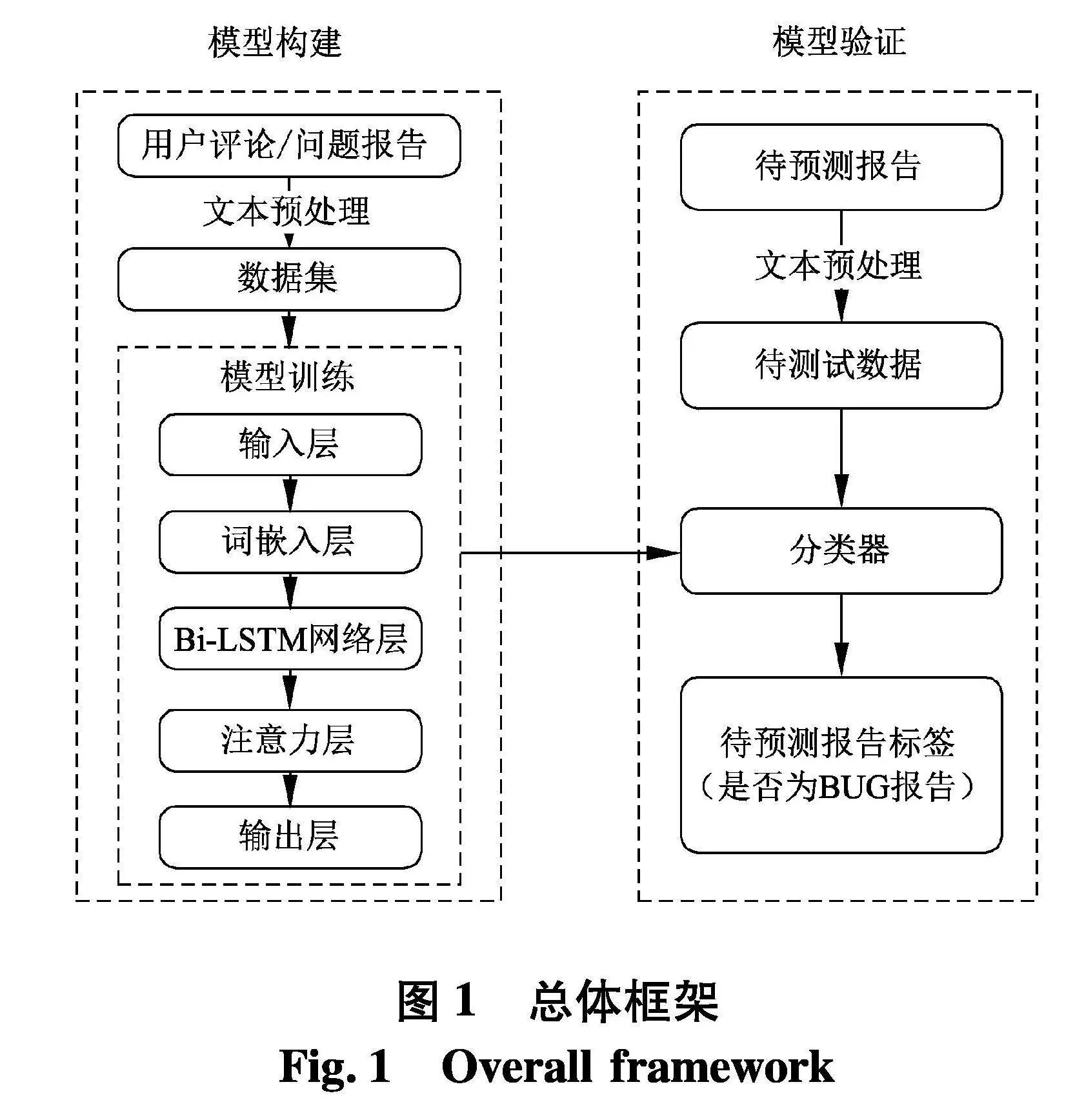
文中以用户反馈和问题报告两个视角为切入点,提出基于Bi-LSTM与注意力机制相融合的方法,框架图如图1.
2.1" 模型构建
2.1.1" 数据预处理
(1) 文本清洗:将用户反馈与问题报告中含有的对识别没有重要的作用的文本内容,通过清洗将其剔除.
(2) 令牌化:将用户反馈与问题报告根据空格符进行文本切割,并将所有英语单词小写化.
(3) 词根化:将单词的变体转为其词干,文中采用Stemmer2工具完成这项工作.
(4) 去除停用词:去除了常见的“the”“is”等停用词,同时保留了对语义信息有意义的单词.文中将长度小于2和大于20的单词也视为停用词.
2.1.2" 模型训练
如图2,识别模型网络结构包含5层:输入层、Embedding层、Bi-LSTM层、注意力层和输出层.
(1) 输入层
将预处理后的文本输入到Embedding层.
(2) Embedding层
首先接收输入层的文本,利用Skip-Gram模型为每个单词生成维度为M的词向量.将截取每个文本的前N个单词作为输入.当文本的长度低于N,则使用“空单词”填充至N.文中使用掩码在模型训练前阻止“空单词”进入模型.
(3) Bi-LSTM层
LSTM单元主要由输入门it(内含权重参数Wxi,Whi,Wci,bi),遗忘门ft(内含权重参数Wxf,Whf,Wcf,bf),输出门ot(内含权重参数Wxo,Who,Wco,bo)与数据组合gt(内含权重参数Wxc,Whc,Wcc,bc)组成.设当前神经元的单元状态、接收输入与单元输出分别为ct,xt,ht,上一单元的单元状态与单元输出分别为ct-1,ht-1,其工作流程为:
it=σ(Wxi·xt+Whi·ht-1+Wci·ct-1+bi)(1)
ft=σ(Wxf·xt+Whf·ht-1+Wcf·ct-1+bf)(2)
gt=tanh(Wxc·xt+Whc·ht-1+Wcc·ct-1+bc)(3)
ct=itgt+ftct-1(4)
ot=σ(Wxo·xt+Who·ht-1+Wco·ct-1+bo)(5)
ht=ottanh(ct)(6)
式中:σ为激活函数sigmoid.设双向网络的输出分别为h→i与h←i,则Bi-LSTM网络层的最终输出为两个向量拼接:
hi=[h→i,h←i](7)
(4) 注意力层
该层接收Bi-LSTM层的输出,生成特征权重并与特征进行加权求和后,输出句子特征.设Bi-LSTM层的输出为H=[h1,h2,...,hn],注意力权重参数为w,注意力层通过以下流程生成句特征hsen:
M=tanh(H)(8)
α=exp(wTM)∑exp(wTM)(9)
hsen=tanh(HαT)(10)
通过计算注意力概率分布,图3得到对移动应用BUG识别有影响的关键性词汇,不仅提高识别准确率,而且能够给予开发人员更直观的语义描述,同时有助于拓展相似的文本分析工作.
(5) 输出层
输出层由一个神经元组成,接收注意力层的句特征,输出当此判定结果:如果输出值y大于0.5,则判定其为BUG报告,反之则不是.该单元的激活函数为sigmoid,公式为:
σ(hsen)=11+exp(-hsen)(11)
为了减少模型出现过拟合的现象,引入Dropout算法保证模型的泛化能力.网络的损失函数为二分类交叉熵损失函数为:
Loss=-∑ni(yi×log(y^i)+(1-yi)×log(1-y^i))(12)
式中:yi为样本的真实标签;y^i为分类器的输出标签.
最后,训练上述Bi-LSTM和注意力机制模型的参数,当达到最大迭代次数得到分类器模型.为了提高模型性能,设置了Adam优化算法,该算法不同于传统的随机梯度下降优化算法,能够为不同的参数提供自适应学习率,保证网络的稳定性.
2.2" 模型验证
此阶段将预处理后的待预测问题报告通过Embedding层输入到训练好的分类器中得到其预测标签.具体的步骤描述如表1.
3" 实验设置
实验在Microsoft Windows 10的四核CPU(i5-7200U CPU @ 2.50 GHz)、8 GB内存和512 GB硬盘的PC上实现.
3.1" 数据集
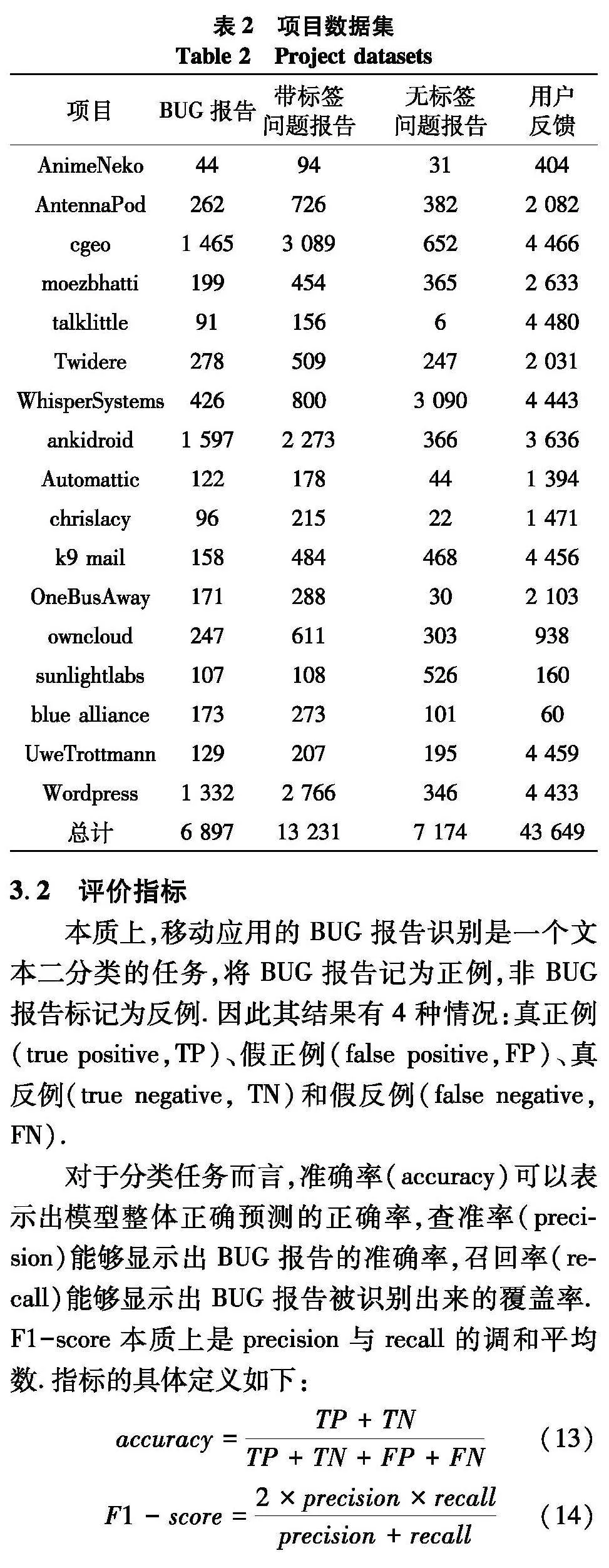
数据集来自于文献[8-9],其具体描述如表2.
3.2" 评价指标
本质上,移动应用的BUG报告识别是一个文本二分类的任务,将BUG报告记为正例,非BUG报告标记为反例.因此其结果有4种情况:真正例(true positive,TP)、假正例(1 positive,FP)、真反例(true negative, TN)和假反例(1 negative,FN).
对于分类任务而言,准确率(accuracy)可以表示出模型整体正确预测的正确率,查准率(precision)能够显示出BUG报告的准确率,召回率(recall)能够显示出BUG报告被识别出来的覆盖率.F1-score本质上是precision与recall的调和平均数.指标的具体定义如下:
accuracy=TP+TNTP+TN+FP+FN(13)
F1-score=2×precision×recallprecision+recall(14)
precision=TPTP+FP(15)
recall=TPTP+FN(16)
3.3" 实验参数设置
文中参数的设定为:Dropout丢弃概率P=0.5;Adam算法学习率η=0.000 1;批量大小batch size=32;输入序列长度Nreview=110,Nreport=180;词向量长度Wreview=Wreport=10.
4" 实验结果及分析
4.1" 实验结果
分别使用全用户反馈与问题报告作为训练数据集,即使用用户反馈数据集训练时,则问题报告作为测试集;而使用问题报告训练时,随机选取90%的问题报告作为训练集,10%作为测试集,且由于选取具有随机性,最终结果为运行20次的平均结果.为了验证方法的性能,文中选择了BUG报告识别的多种方法进行对比.
(1) 混合相似度[9]:首先分别计算待预测问题报告与历史问题报告和用户反馈之间文本相似度,然后将两种相似度相结合,通过事先设置好的阈值进行标记.
(2) N-gram IDF based线性回归[4]:将文本划分为n元的词组,使用逆文档频率去除低频词组,进行特征挑选后构建线性回归分类器.
(3) N-gram IDF based随机森林[4]:应用上述方法后构建随机森林分类器.
(4) N-gram IDF based朴素贝叶斯[4]:应用上述方法后构建贝叶斯分类器.
(5) 线性回归[17]:利用回归分析,构建分类器.
(6) 随机森林:利用多棵决策树构建分类器.
(7) 朴素贝叶斯[18]:基于贝叶斯原理构建分类器.
(8) CaPBUG[10]:利用TF-IDF进行特征提取,并使用SMOTE对问题报告进行过采样后,构建随机森林分类器.
(9) Transformer:使用Transformer对问题报告进行分类.
(10) CNN:使用基于卷积神经网络(CNN)的模型来预测问题报告的标签.
(11) GRU:通过门控神经单元(GRU)识别问题报告中的BUG信息.
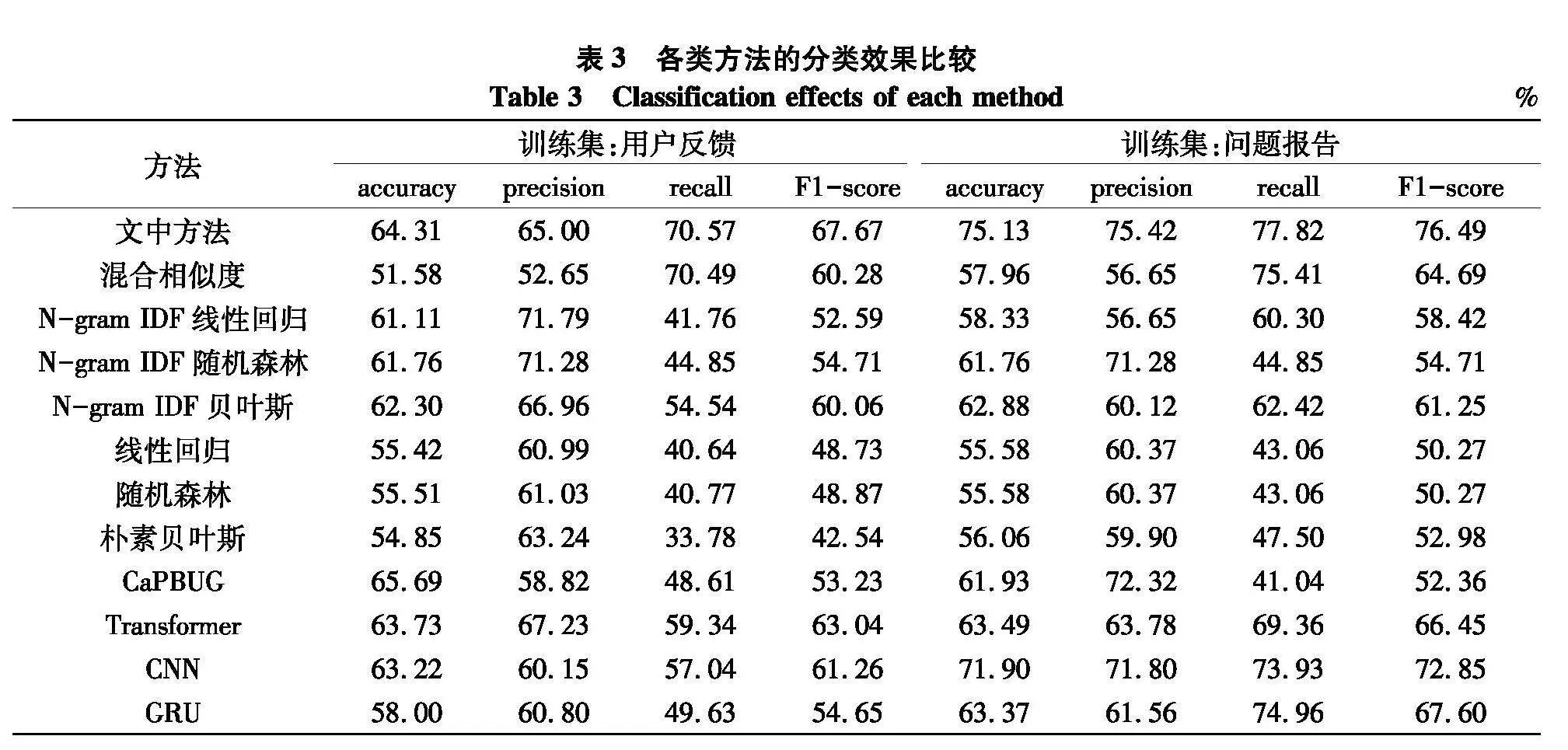
由表3结果可知,文中在用户反馈作为训练集时,accuracy略低于CaPBUG,但其他指标则优于此方法. 而precision略低于N-gram IDF based 线性回归、随机森林、贝叶斯和Transformer,但其他指标均有不错的表现.综合4个指标,文中方法整体表现较优. 其次,通过分析结果发现,移动应用问题报告作为训练集的BUG识别效果更佳.
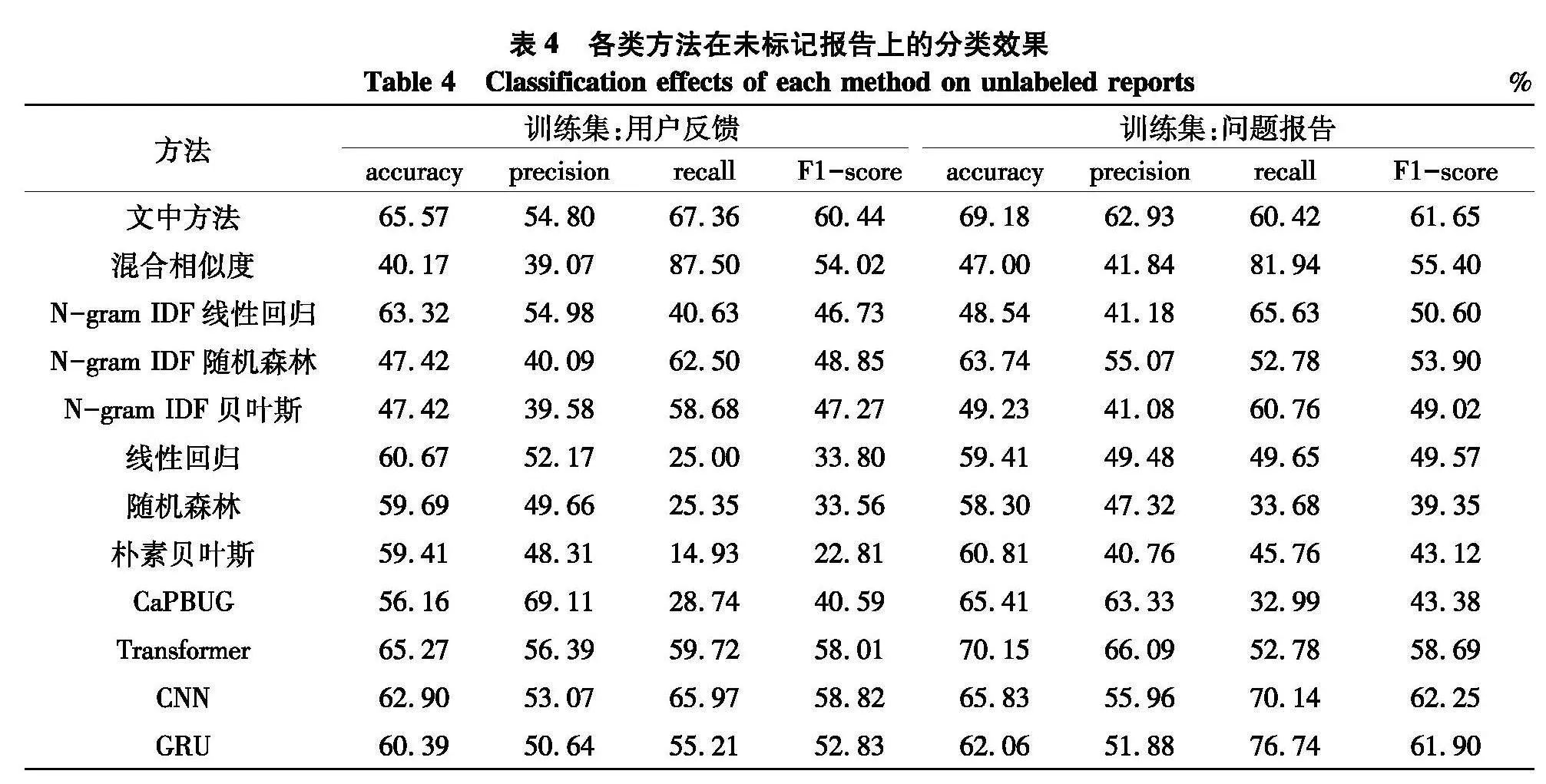
为进一步验证所提方法的可靠性,在手工标注的7 174个问题报告中重复20次随机选取10%问题报告进行验证.对于以上未标记问题报告的标签,借鉴文献[8-9],实验结果如表4,无论是用户反馈还是问题报告作为训练数据集,文中方法都具有一定的优越性.然而,混合相似度的recall大幅高于文中及其他的方法,其原因在于其设定的阈值,当相似度高于该值便认定其为BUG报告,当其设定较低时,则多被预测为为BUG报告,从而TP与FP的数量增多,导致recall会增加,然而其他性能却相对降低.此外,Transformer在以问题报告作为训练集的accuracy与precision略高于文中方法,原因在于Transformer完全基于自注意力机制,对于问题报告词语间的位置信息会有一定的丢失.而CaPBUG追求较高precision,导致其他指标较低.
4.2" 移动应用中不同应用阶段数据集的影响
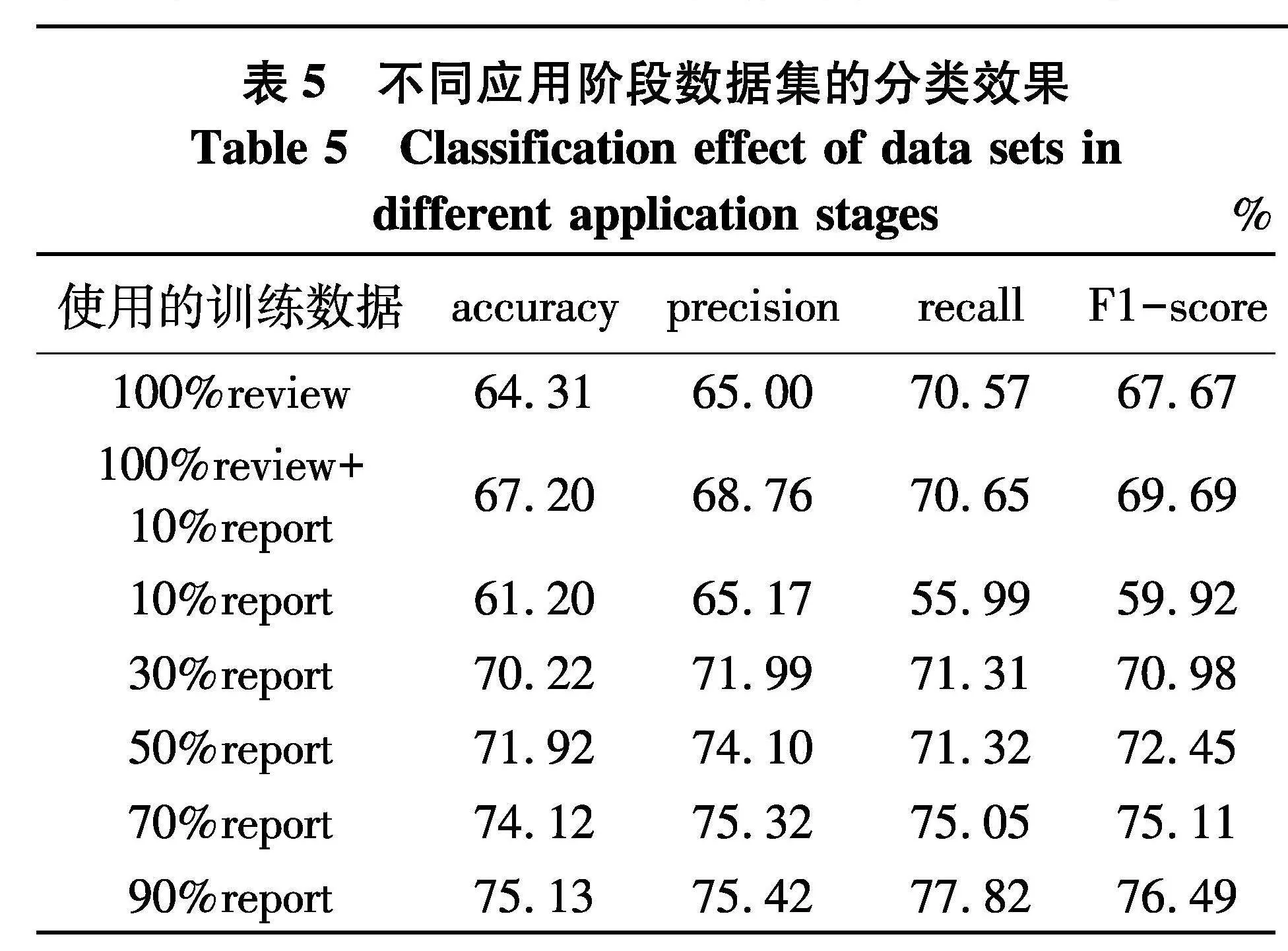
文中探究了融合100%用户反馈(review)与10%问题报告(report)的数据,以及10%、30%、50%、70%、90%问题报告作为训练数据集的情况,并给出运行20次的平均结果,如表5.
由表5可知,在移动应用开发初期,通过用户反馈的数据构建的模型性能优于仅使用少量的带标签的问题报告;随着移动应用问题报告数量的增加,向训练数据中添加少量的问题报告可有效地提升模型的性能,这表明问题报告中包含有不同于用户反馈的对分类有效的特征信息;当移动应用的带标签问题报告数据充足时,模型的性能大幅优于仅使用用户反馈的情况,并且训练使用的问题报告数据越多,模型的性能越佳,这表明在带标签问题报告数据充足的情况下,使用问题报告的效果优于用户反馈的训练结果.
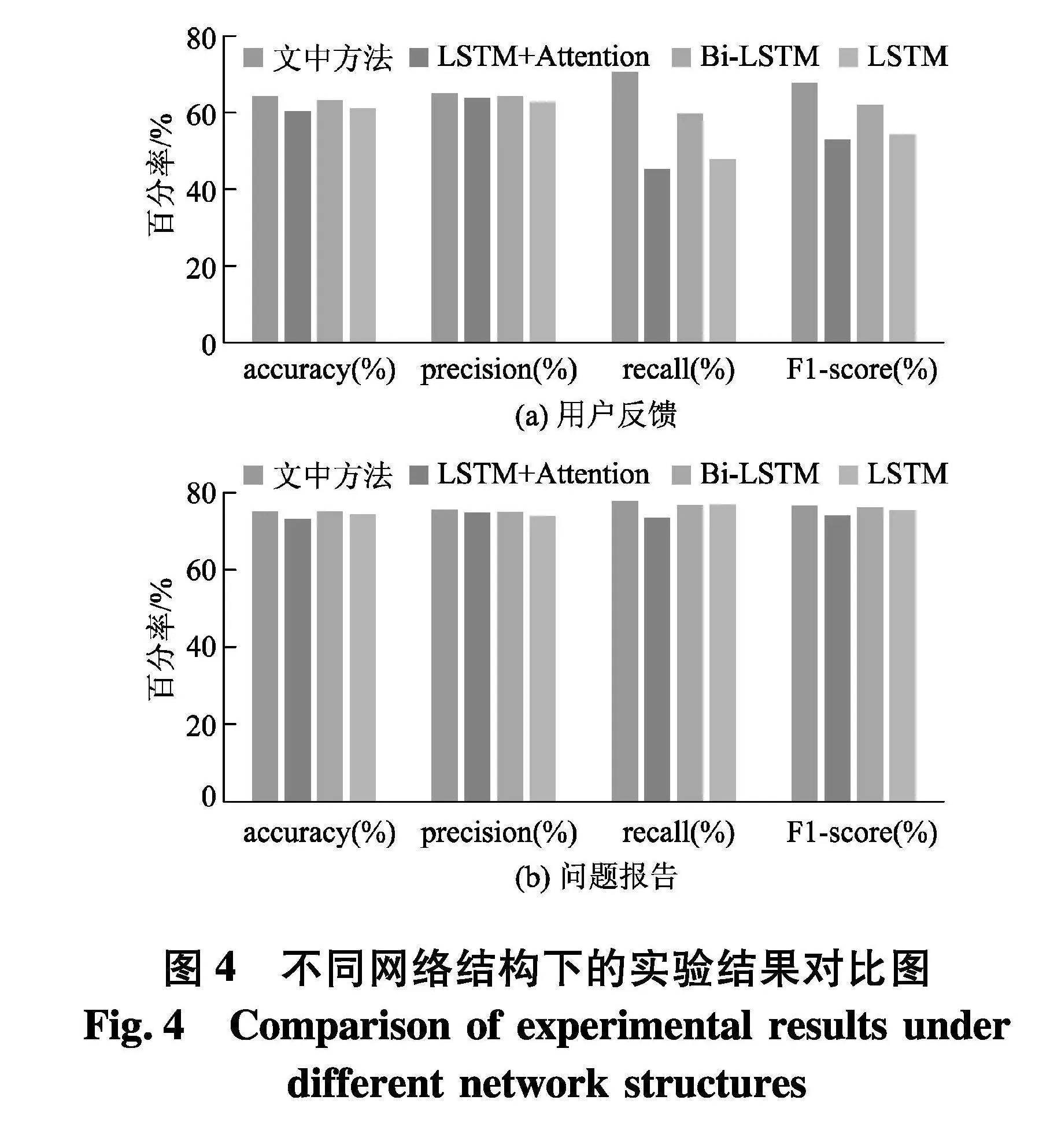
4.3" 不同网络结构下的性能分析
为了验证网络结构的优越性,分别选取了LSTM融合注意力机制、Bi-LSTM和LSTM进行了对比实验.由图4的结果可知,Skip-gram向量模型、Bi-LSTM网络和注意力机制对于文中网络结构的重要性.
4.4" 运行时间对比分析
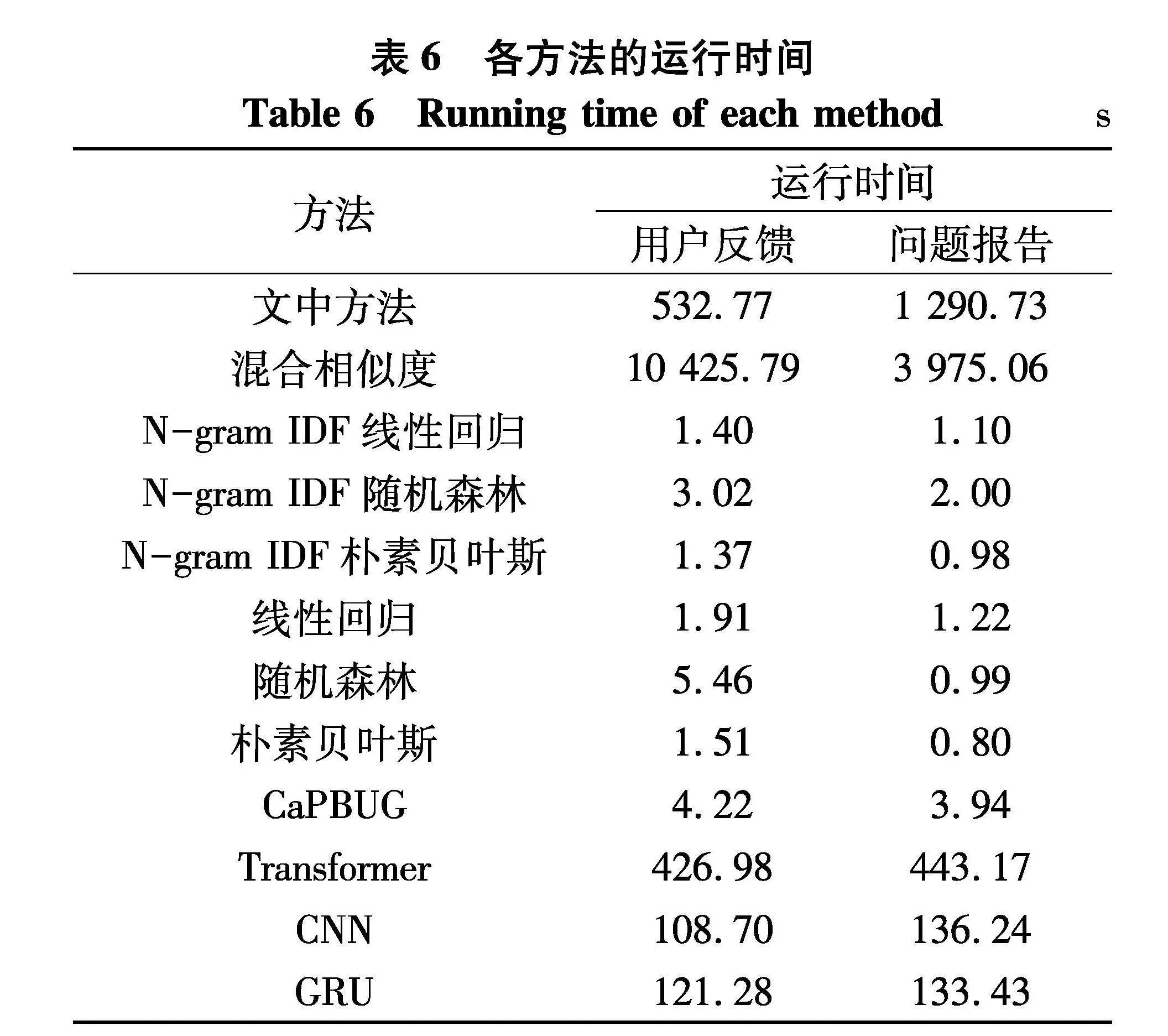
如表6为文中方法和其他对比方法的运行时间.与混合相似度方法相比,文中方法的运行时长有大幅度降低.相较于N-gram IDF based结合线性回归、随机森林、朴素贝叶斯、CaPBUG等方法,文中方法的运行时间不占优势,但以运行时间换取了更高的识别率,且运行时间仍在可接受的范围内.
4.5" 参数讨论
4.5.1" 输入序列长度
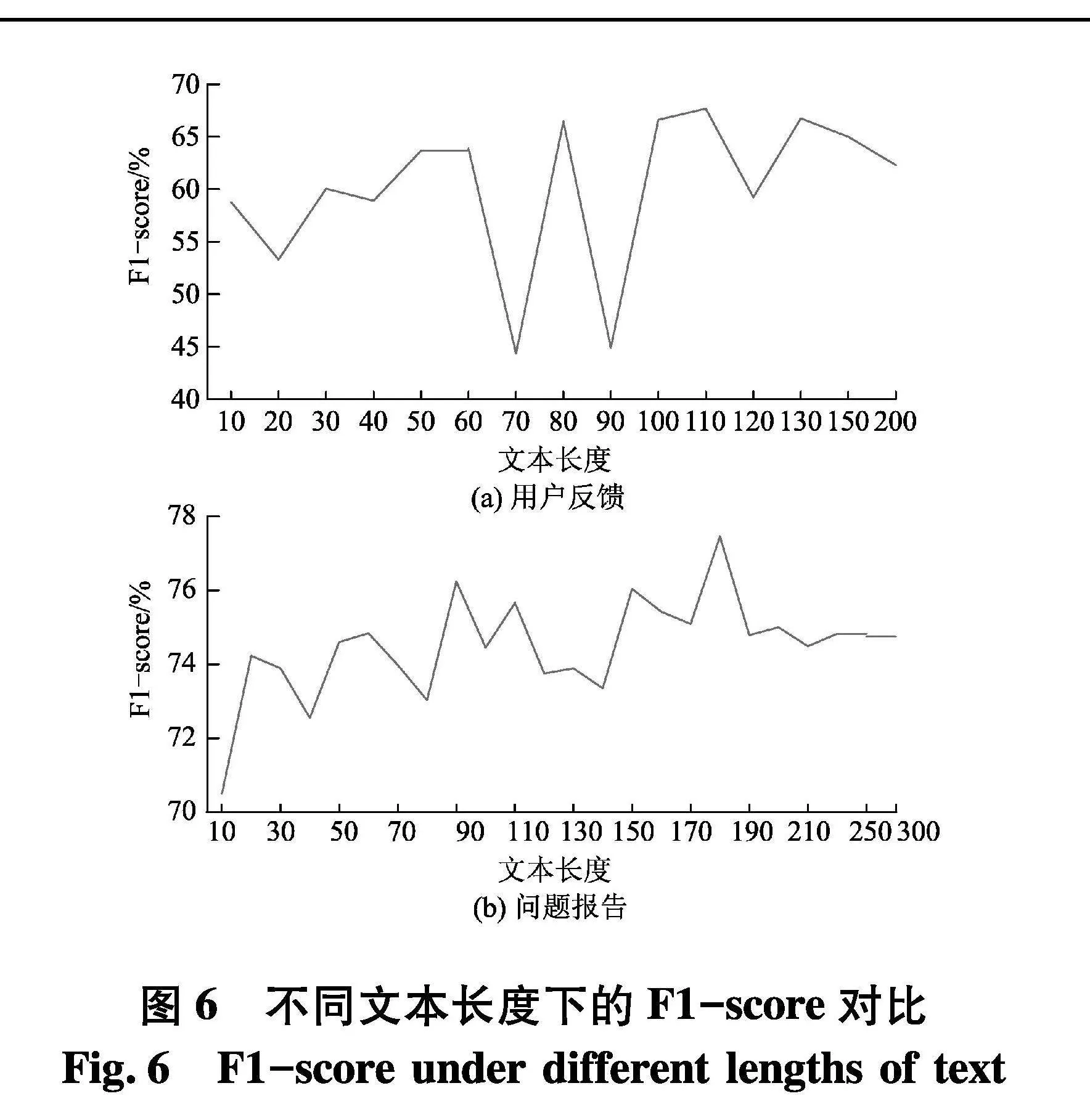
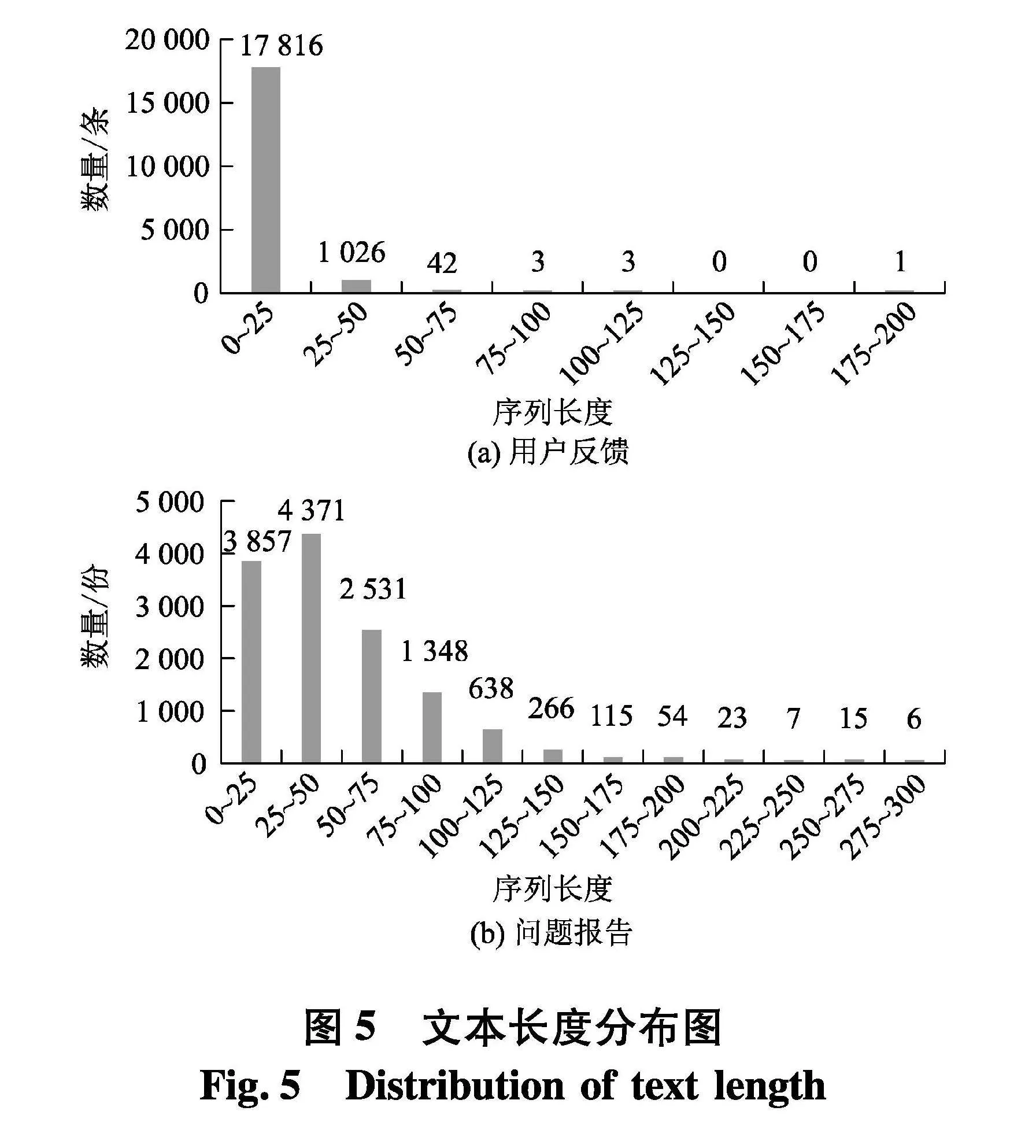
图5为预处理后用户反馈与问题报告的文本长度分布.文中设置了用户反馈的输入序列长度的范围为[0,200],问题报告的输入序列长度的范围为[0,300].
由图6可知,当用户反馈的长度在110,F1-score达到最优值,在长度超过110之后,其呈现下降的趋势,因此选择110作为用户反馈单条文本的长度.同理,问题报告的序列长度设置为180.
4.5.2" 词向量长度
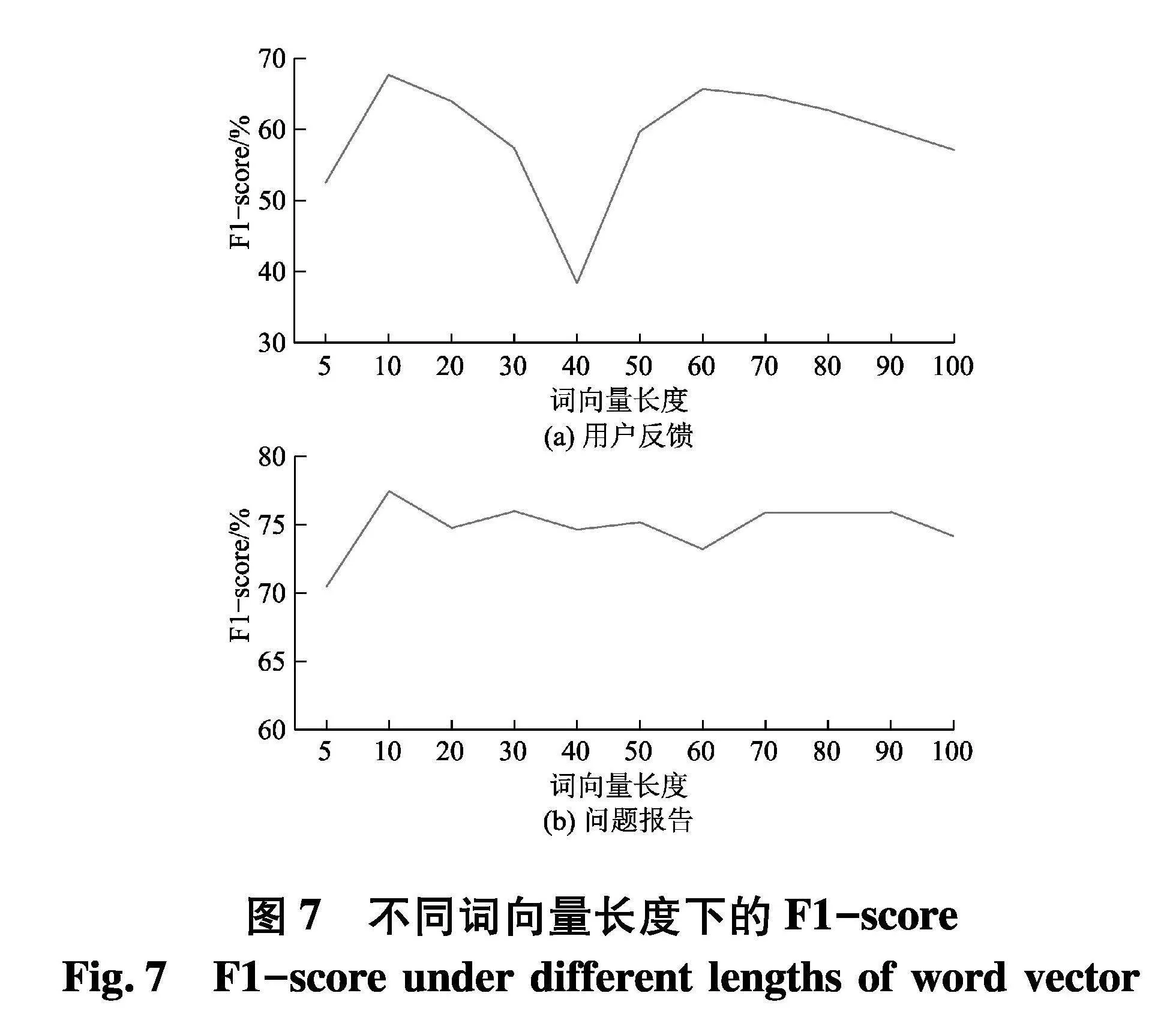
当用户反馈和问题报告分别固定了最佳的输入序列长度后,仍需对词向量的长度进行讨论.根据文献[19],寻求空间设置为[5,100].
由图7针对两种视角下的数据集,当词向量长度为10,F1-socre值均达到最优.
5" 结论
以用户反馈与问题报告两个视角的数据集为切入点,围绕移动应用的BUG报告识别展开研究,通过构建融合注意力机制的Bi-LSTM网络,自动识别问题报告的标签,得出结论如下:
(1) 在计算开销方面,文中方法在问题报告和用户反馈两个数据集视角下均有大幅降低,有效降低了计算开销;在识别效果方面,文中通过Word2Vec获取特征的语义信息,同时通过注意力机制捕获更为关键的特征.文中方法在问题报告和用户反馈数据集视角下,将F1-score分别提升至76.49%、67.67%,使得BUG报告识别更加精准;
(2) 文中通过分析在问题报告和用户反馈两个视角下的数据集表现,明确了移动应用不同运行阶段下问题报告和用户反馈对BUG报告识别的影响及适用情况:当带标签问题报告数据不足时,使用用户反馈用于移动应用BUG报告识别;当标签数据充足时,通过问题报告训练的模型性能更佳.因此,在移动应用不同阶段下,对数据角度进行分析将有助于开发人员更高效地识别BUG报告.
参考文献(References)
[1]" ZHANG Tao, CHEN Jiachi, LUO Xiapu, et al. Bug reports for desktop software and mobile apps in Github:what is the difference? [J]. IEEE Software, 2019, 36(1):63-71.
[2]" CABOT J, IZQIERDO J L C, COSENTINO V, et al. Exploring the use of labels to categorize issues in open-source software projects[C]∥ 2015 IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering (SANER).Canada:IEEE, 2015:550-554.
[3]" ZAIDI S F A, LEE C G. Learning graph representation of bug report stotriage bugs using graph convolution network[C]∥ 2021 International Conference on Information Networking.Korea: ICOIN, 2021: 504-507.
[4]" TERRDCHANAKUL P, HATA H, PHANNACHIT-TA P, et al. Bug or not? bug report classification using N-Gram IDF[C]∥2017 IEEE International Conference on Software Maintenance and Evolution.China:ICSME ,2017: 534-538.
[5]" 於跃成,谷雨,左华煜,等. 基于用户反馈信息可信传播的社会推荐方法[J]. 江苏科技大学学报(自然科学版), 2021, 35(4):58-65.
[6]" CIURUMELEA A, SCHAUFELBUHL A, PANICHEL-LA S, et al. Analyzing reviews and code of mobile apps for better release planning[C]∥ 2017 IEEE 24th International Conference on Software Analysis, Evolution and Reengineering. Austria :SANER, 2017: 91-102.
[7]" GENC-NAYEBI N, ABRAN A. A Systematic literature review: opinion mining studies from mobile app store user reviews[J]. Journal of Systems amp; Software, 2017, 125:207-219.
[8]" LI Haoming, ZHANG Tao, WANG Ziyuan. Bug or not bug? labeling issue reports via user reviews for mobile apps[C]∥The 30th International Conference on Software Engineering and Knowledge Engineering.USA:SEKE, 2018:59-65.
[9]" ZHANG Tao, LI Haoming, XU Zhou, et al. Labeling issue reports in mobile apps [J]. IET Software, 2019, 13(1):528-542.
[10]" AHMED H A, BAWANY N Z, SHAMSI J A.CaPBug a framework for automatic bug categorization and prioritization using NLP and machine learning algorithms[J]. IEEE Access, 2021, 99:1-1.
[11]" MIKOLOV T, CHEN K, CORRADO G, et al. Efficientestimation of word representations in vector space [J]. Computer Science, 2013,1301:3781.
[12]" DAOUD N, ELAHAN M, ELHENNAWI A. Aerosoloptical depth forecast over global dust belt based on LSTM, CNN-LSTM, CONV-LSTM and FFT algorithms[C]∥ IEEE EUROCON 2021-19th International Conference on Smart Technologies. Ukraine:IEEE, 2021:186-191.
[13]" MOHARM K, ELAHAN M, ELHENNAWI E. Windspeed forecast using LSTM and Bi-LSTM algorithms over gabal El-Zayt wind farm[C]∥ 2020 International Conference on Smart Grids and Energy Systems. Australia: SGES, 2020:922-927.
[14]" WANG Shaokang, CHEN Yihao, MING Hongjun, et al. Improved danmaku emotion analysis and its application based on Bi-LSTM model[J]. IEEE Access, 2020, 99:1-1.
[15]" ZHOU Peng, SHI Wei, TIAN Jun, et al. Attention-based bidirectional long short-term memory networks for relation classification[C]∥Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Germany: ACL,2016:207-212.
[16]" HUANG Q, EMAD S, XIA X, et al. Identifying self-admitted technical debt in open source projects using text mining[J]. Empirical Software Engineering, 2018,23(1):418-451.
[17]" MENDOZA R, MARTINEZ J, HIDALGO M C, et al. Estimation of the Pb content in a tailings dam using a linear regression model based on the chargeability and resistivity values of the wastes (La Carolina Mining District, Spain) [J]. Minerals, 2022, 12(1):7.
[18]" 黄城, 徐克辉, 郑尚,等. 基于交叉过采样的软件自承认技术债识别方法[J]. 江苏科技大学学报(自然科学版), 2020, 34(5):51-56.
[19]" YU Liangjun, GAN Shengfeng, CHEN Yu, et al. Correlation-based weight adjusted naive bayes[C]∥ 2018 IEEE 30th International Conference on Tools with Artificial Intelligence. Greece:ICTAI, 2020: 825-831.
(责任编辑:曹莉)
