融合ECA的多分支多损失行人重识别
2024-10-18王卫东徐金慧张志峰




摘" 要: 针对现有行人特征提取方法的不足,提出了一种融合ECA的多分支多损失行人重识别方法.首先,将轻量级ECA注意力模块嵌入到骨干网络ResNet50中,以增强显著特征,抑制无关特征.其次,设计了一个多分支网络结构分别提取行人的全局特征和局部特征,针对不同的特征采取不同的多池化特征提取方式,增强网络的特征提取能力.最后,联合三种损失函数对模型进行训练,并采用BNNeck进行优化,从而提高模型的鲁棒性.在Market1501和DukeMTMC-reID数据集上的实验表明,所提方法具有较好的效果,在识别精度上也优于较多的经典算法.
关键词: 行人重识别;ECA注意力模块;多分支特征;多损失联合
中图分类号:TP391.4""" 文献标志码:A""""" 文章编号:1673-4807(2024)01-082-07
DOI:10.20061/j.issn.1673-4807.2024.01.013
收稿日期: 2021-09-14""" 修回日期: 2021-04-29
基金项目: 国家自然科学基金项目(62076111)
作者简介: 王卫东(1968—),男,博士,副教授,研究方向为模式识别、智能信息系统.E-mail:78653221@qq.com
引文格式: 王卫东,徐金慧,张志峰.融合ECA的多分支多损失行人重识别[J].江苏科技大学学报(自然科学版),2024,38(1):82-88.DOI:10.20061/j.issn.1673-4807.2024.01.013.
Multi-branch and multi-loss person re-identification integratingefficient channel attention
WANG Weidong, XU Jinhui, ZHANG Zhifeng
(School of Computer, Jiangsu University of Science and Technology, Zhenjiang, 212100, China)
Abstract:Aiming at overcoming the shortcomings of the existing person feature extraction methods, we propose a multi-branch and multi-loss person re-identification method fused with ECA. Firstly, the lightweight ECA attention module is embedded in the backbone network ResNet50 to enhance salient features and suppress irrelevant features. Secondly, a multi-branch network structure is designed to extract the global and local features of person, and different multi-pool feature extraction methods are adopted for different features to enhance the feature extraction ability of the network. Finally, the three types of loss functions are combined to train the model, and BNNeck is used for optimization, so as to improve the robustness of the model. Experiments on Market1501 and DukeMTMC-reID datasets show that the method proposed in this paper has better results and is better than many classic algorithms in recognition accuracy.
Key words:person re-identification, ECA attention module, multi-branch feature, multi-loss combination
行人重识别(person re-identification, reID)广泛应用于智能安防、视频监控、目标跟踪等领域,但它仍然面临着遮挡、光照、低分辨率、姿势变化[1]、域自适应等诸多挑战.
近年来,随着深度学习的迅猛发展,基于深度学习的行人重识别已经基本取代了传统的行人重识别方法.文献[2]提出了IDE(ID-discriminative Embedding)模型,以ResNet-50作为主干网络,行人的ID类别作为训练标签,已成为很多现有行人重识别方法的基准网络.文献[3]通过引入行人属性标签,将ID损失和属性损失进行结合,提高了行人重识别的性能.
虽然全局特征包含了行人图片中最显著的外观信息,有助于判别不同身份的行人[4],但是也导致了局部细节信息(如帽子,腰带等)被忽略.当行人目标存在遮挡或视角问题时,仅凭全局特征很难准确地识别行人.为了解决这个问题,引入了局部特征,文献[5]提出了PCB(part-based convolutional baseline)分块模型,将特征图水平均匀划分为6块并分别预测ID,同时提出了RPP(refined part pooling)来解决行人图像不对齐问题.文献[6]使用人体关键点算法(global-local-alignment descriptor,GLAD)将图片分为头部、上身和下身3部分进行特征提取.文献[7]通过使用姿态估计模型估计出人体关键点,再通过仿射变换进行语义部件对齐,从而提取局部信息.文献[8]提出多粒度网络(multiple granularity network,MGN),通过结合全局特征和不同粒度的局部特征,进一步提升了网络的识别性能.
随着注意力机制地不断发展,使用注意力机制来优化行人重识别任务已经得到了学术界地广泛关注.文献[9]提出了注意力组成网络(attention-aware compositional network,AACN),利用注意力模块提取行人图像的姿态信息和局部信息,从而避免背景干扰.文献[10]提出双感知匹配网络(dual attention matching network,DuATM),去学习上下文感知特征序列,同步执行序列对比.文献[11]将通道注意力模块CAM和位置感知模块PAM融入到骨干网络中来提取通道和空间信息,同时引入正交正则化来增强隐藏激活和权重的多样性.文献[12]提出了混合高阶注意力网络(mixed high-order attention network,MHN),通过混合不同阶次的注意力模块学习更有区分性的特征,进一步增强注意信息的辨别力和丰富性.但上述注意力的方法由于复杂注意力模块的加入,使得网络结构复杂度更高,计算量更大.
为了解决行人重识别方法不能有效提取行人特征导致识别精度低且网络结构过于复杂的问题,文中提出了一种融合ECA的多分支多损失行人重识别网络模型,其创新之处是采用多特征方法,分别提取行人图像的全局特征和局部特征,并采用多损失函数进行网络参数优化.同时,算法还引入一个超轻量级的ECA注意力模块,来强化更具鉴别性的行人特征.
1" 融合ECA的多分支多损失行人重识别网络模型思想及步骤
(1) 构建ResNet50残差网为骨干网.
(2) 将注意力模块ECA注入到残差网ResNet50中.
(3) 在ResNet50之后,网络分为3个分支,包括两个全局和一个局部分支.
(4) 在两个全局分支的输入端,一个采用平均池化,另一个采用最大池化,提取行人的全局特征.
(5) 全局分支采用相同的网络结构,包括1×1卷积层,然后是三元组损失和中心损失组成的优化层,再采用BNNeck瓶颈结构得到归一化特征,最后经FC层用交叉熵损失函数进行优化.
(6) 局部分支将特征图水平均匀切分为3个部分.
(7) 对每个部分分别进行最大池化和平均池化,通过特征拼接将两种池化后的特征进行融合.
(8) 对于融合后的特征,再经过1×1卷积层、BN层和 ReLU 层得到局部特征向量.经FC层用交叉熵损失函数进行优化.
2" 网络模型结构
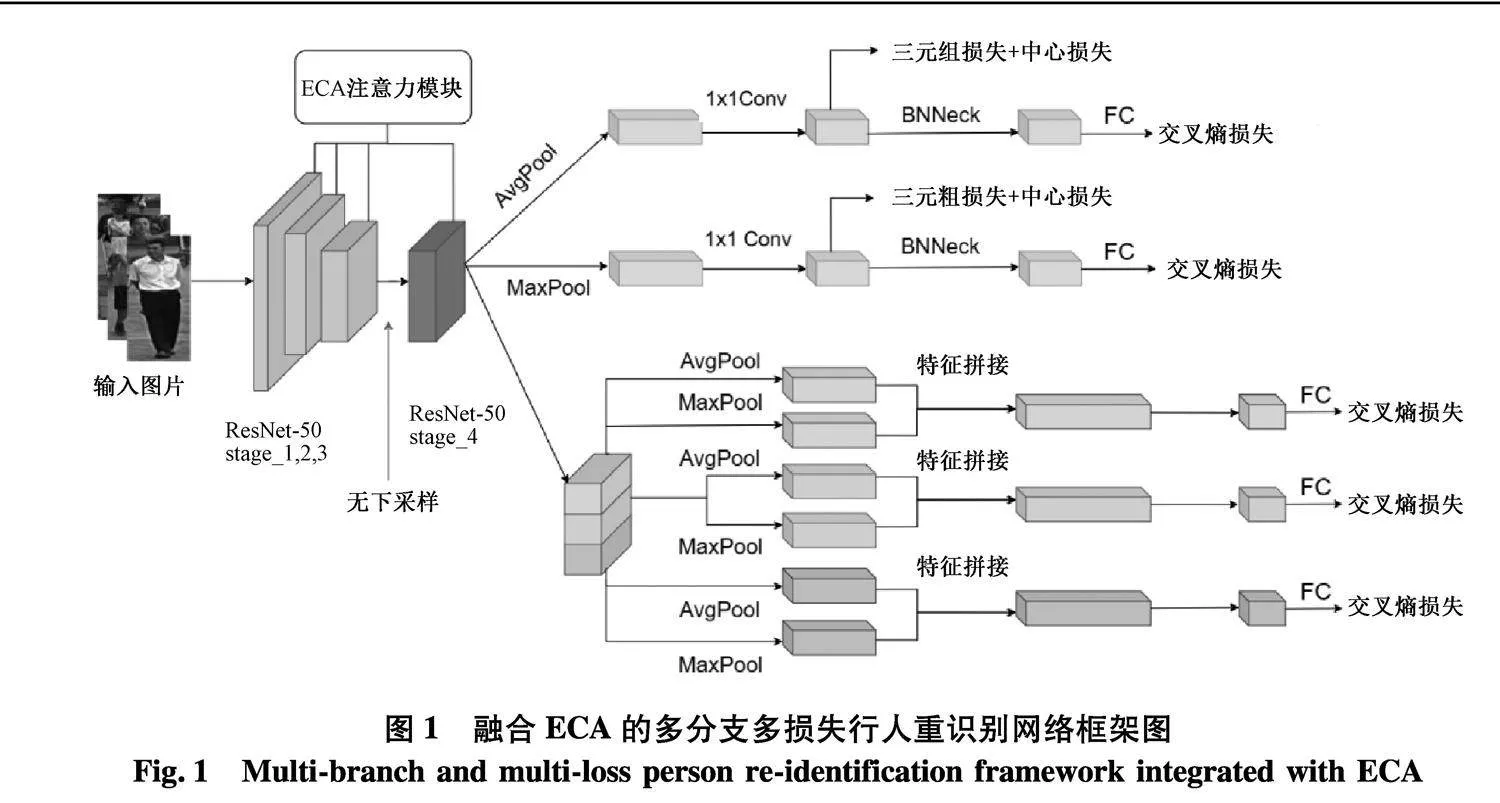
网络模型结构如图1,主要由骨干网络和3个分支构成.其中,骨干网络以ResNet-50为基础,在每个阶段中嵌入ECA注意力模块.同时对ResNet-50进行了轻微修改:移除网络最后的池化层和全连接层;为了使特征图拥有更加丰富的细节信息,取消了第四阶段中的下采样操作.引入ECA注意力模块的目的是在不增加网络复杂度的前提下使网络更加关注行人图像的有用信息,忽略无用信息,从而增强网络的特征提取能力.
算法将输入图像大小调整为324×128,经过骨干网络后得到大小为24×8×2 048的特征图.随后将网络分为3个分支,其中两个为全局分支,一个为局部分支.对于两个全局分支,分别采取全局最大池化和全局平均池化,以提取更全面的高级语义信息.经过池化后得到特征大小为1×1×2 048.再通过1×1卷积层得到512维的全局判别特征,由三元组损失和中心损失进行优化.最后通过BNNeck瓶颈结构得到归一化特征,经过FC层后用交叉熵损失函数进行优化.
对于局部分支,将特征图水平均匀切分为3个部分,对每个部分分别进行最大池化和平均池化,通过特征拼接的方式将两种池化后的特征进行融合,从而得到增强的局部特征,局部特征的维数为4 096维.再经过1×1卷积层维数下降为512维,最后采用BN层和 ReLU 层将特征向量降至256维.加入BN层的目的是使得网络训练过程中的每一层输入保持相同分布.考虑到分块可能导致的不对齐问题,局部分支仅采用交叉熵损失函数进行优化.
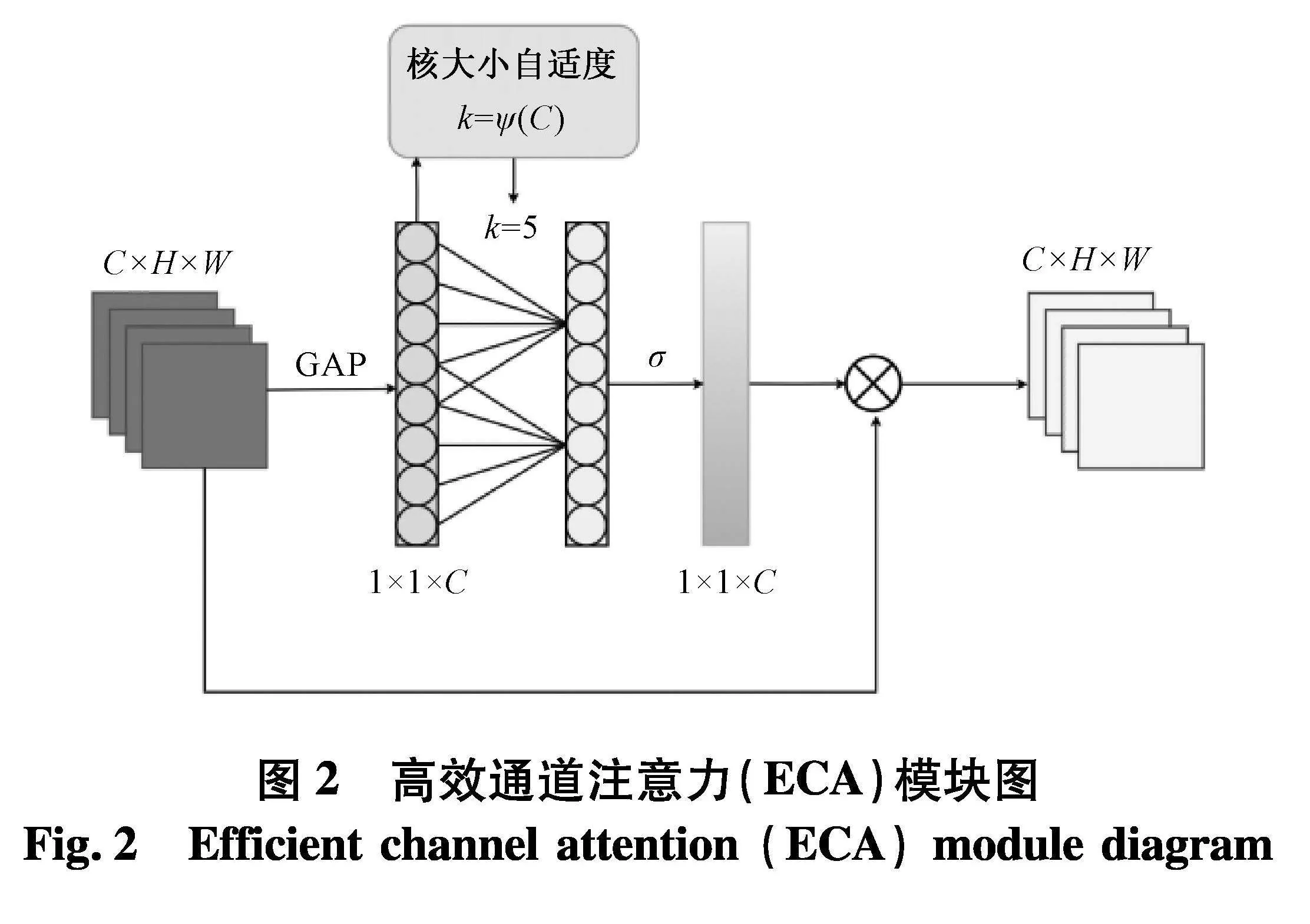
3" ECA注意力模块
为了克服性能和复杂性折衷之间的矛盾,引入了高效通道注意力模块[13](efficient channel attention,ECA),其主要作用是为每个通道生成相应的权重并学习其相关性.将行人图像的关键特征生成较大的权重,而无关的特征则生成较小的权重,从而提升网络对行人主要特征的敏感度.避免降维对学习通道注意力具有重要意义,而跨通道信息交互可以在降低模型复杂度的同时,提高模型的性能.
ECA模块在SE模块[14]的基础上,去除了原来SE模块中的FC层,通过增加局部跨通道交互和通道共享参数,降低了模型的复杂度,提高了学习注意力的效率.ECA模块结构如图2.
如图2,ECA模块首先对输入的特征图进行全局平均池化,将特征从二维矩阵压缩与提取到单个数值,然后执行大小为k的快速一维卷积来生成通道权重,获取各个通道之间的相关依赖关系.其中k是由通道维数C的函数自适应地确定.最后将生成的各个通道的权重通过乘法加权到原来的输入特征图上,将通过ECA模块提取的特征与原本的特征的加权完成在通道空间的特征再标定.通道权重为:
wi=σ∑kj=1αjyij" yij∈Ωki(1)
式中:Ωki为yi的k个邻域通道;yi为经过全局平均池化后的通道i的特征表示;αj为共享参数;σ为激活函数;wi为通道i的权重.
通道权重的计算需要通过核大小为k的一维卷积来实现,可以看出k是一个关键参数,因为k决定了局部跨通道交互的覆盖范围.由于通道维数C大小与k成正比,得到其指数函数对应关系:
C=φk=2γ·k-b(2)
已知通道维数C,一维卷积核大小k为:
k=ψC=log2Cγ+bγodd(3)
式中:todd表示与t最近的奇数.文中γ和b分别设为2和1.
4" 多池化与多损失函数
文中在模型中同时使用了平均池化和最大池化,从而获得既有全局信息又有代表性信息的行人特征.所提出的网络模型学习到更鲁棒的行人特征,文中使用交叉熵损失(cross-entropy loss)、难样本三元组损失(batch-hard triplet loss)、中心损失(center loss)3种损失函数联合训练,并利用BNNeck对其进行优化.
4.1" 交叉熵损失
交叉熵损失用于分类任务,交叉熵损失为:
Lc=-∑Ni=1qilogeeWTif∑Nk=1eWTkf" qi=0,y≠iqi=1,y=i(4)
式中:N为训练集中的行人类别总数,y为行人的真实标签;W是全连接层对应i类别的权重向量.
但是交叉熵损失函数过度依赖正确的行人标签,容易造成训练过拟合(overfitting)的现象.为了防止模型过拟合并且提高模型的泛化能力,采用了标签平滑(label smoothing)[15]思想,对行人标签进行了平滑处理,将式(4)中的q改为:
qi=εNy≠i1-N-1Nεy=i(5)
式中:ε是错误率,用于降低模型在训练集上的置信度,将其设置为0.1.
4.2" 难样本三元组损失
难样本三元组损失是三元组损失的改进版本.公式为:
Ltriplet=α+maxp=1…K‖fia-fip‖2-""" minp=1…Kj=1…Pj≠i‖fia-fjn‖2+(6)
式中:fia为锚点特征向量;fip为正样本特征向量;fjn为负样本特征向量;P是每个批次中的行人ID数;K是每个批次中同一ID的图片数;φ+表示maxφ,0;α为三元组损失的margin参数,将其设置为1.2.
4.3" 中心损失
若仅使用三元组损失函数作为度量损失,可能会出现类间距离小于类内距离的情况.所以引入了中心损失(center loss),中心损失可以学习到每一类深度特征图的中心.当深度特征图与其对应的类中心之间的距离较大时,中心损失会对其进行惩罚,从而弥补了三元组损失的缺点.center loss 函数定义为:
Lcenter=12∑Bj=1‖ftj-cyj‖22(7)
式中:yj为第j个图像的标签;cyj为第yj个类别的特征中心;B为最小批次的图片数量.
4.4" 联合损失函数
针对全局特征和局部特征,分别采用了不同的损失函数.对于全局特征,使用三元组损失、中心损失和交叉熵损失3种损失函数.而对于局部特征,考虑到分块导致的不对齐问题,仅使用交叉熵损失.这样整个网络模型的损失函数为:
Ltotal=12∑2iLtripletGi+ε×∑2iLcenterGi+
15∑5iLCfi(8)
式中:Gi为全局特征;Ltriplet为三元组损失;Lcenter为中心损失;LC为交叉熵损失;fi为两个全局特征和3个局部特征;ε为center loss的权重,文中设为 0.000 5.
虽然联合三种损失函数可以提高模型的鲁棒性.但是由于分类损失和度量损失优化特征目标所在的特征空间是不一致的.交叉熵损失通过构建超平面来将不同类别的特征分配到不同的子空间里面,更适合在余弦空间优化特征.而三元组损失和中心损失更适合在欧几里得空间中约束特征.
4.5" BNNeck瓶颈结构
如果对同一特征向量同时使用这两种损失函数,它们的特征空间目标将会不一致,从而出现在训练过程中一种损失在减少,而另一种损失在振荡甚至增加的可能.为了解决这一问题,引入BNNeck瓶颈结构.BNNeck的核心思想是在全连接(FC)层前添加批量归一化(BN)层,如图3.BN层前的特征为ft,ft经过BN层得到的归一化特征为fi.在训练过程中,ft用于计算三元组损失和中心损失,fi用于计算交叉熵损失.在测试阶段,文中将fi用于最终的判别特征.
5" 实验与分析
5.1" 数据集与评价指标
实验采用行人重识别领域两个大型公开数据集,Marker-1501和DukeMTMC-reID.Marker-1501数据集是在清华大学中采集,包含在6个摄像头(5个高清摄像头和1个普清摄像头)下1 501个行人的32 668张图像,其中训练集有751人,共12 936张图像.测试集有750人,共19 732张图像,包含3 368张查询图像.DukeMTMC-reID 数据集在杜克大学中采集,是从DukeMTMC视频数据集的视频中每120帧采样一张图像而得到的.包含8个摄像头下1 812个行人的36 411张图像.其中训练集有702人,共16 522张图像.测试集有702人,共19 889张图像,包含2 228张查询图像.该数据集中不同行人的图像相似度较高,具有较强的挑战性.
文中采用累积匹配特性(cumulative matching characteristics,CMC)曲线中的首位命中率(Rank-1)和平均精度均值(mean average precision,MAP)作为评估模型性能的指标.Rank-1是检索结果中第一张图像即为目标行人图像的概率.MAP是计算所有查询图像在准确率-召回率曲线下方的面积平均值.反应了检索结果中所有正确图像排名的靠前程度,能更全面地衡量 ReID 算法的性能.
5.2" 实验设置
在深度学习框架PyTorch实现相关算法.网络的基础架构采用ResNet-50,并使用在ImageNet数据集上预训练的ResNet-50模型参数来初始化网络权重.在训练和测试过程中,将输入图像大小均调整为384×128,训练阶段采用水平翻转、随机擦除(Random Erasing)和归一化进行数据预处理,测试阶段仅使用归一化处理.
批次大小N=P×K设置为16,每个训练批次随机挑选P为4个行人,每个行人随机选取K为4张图片.三元组损失margin参数设置为1.2,中心损失权重参数设为5×10-4.训练共经过500个周期(epoch),初始学习率为2×10-4,在第320周期和第380周期分别衰减为2×10-5和2×10-6.采用自适应梯度优化器(Adam)对网络模型参数进行优化,初始学习率为2×10-4,权重衰减因子为5×10-4的L2正则化.
5.3" 与传统方法的对比实验
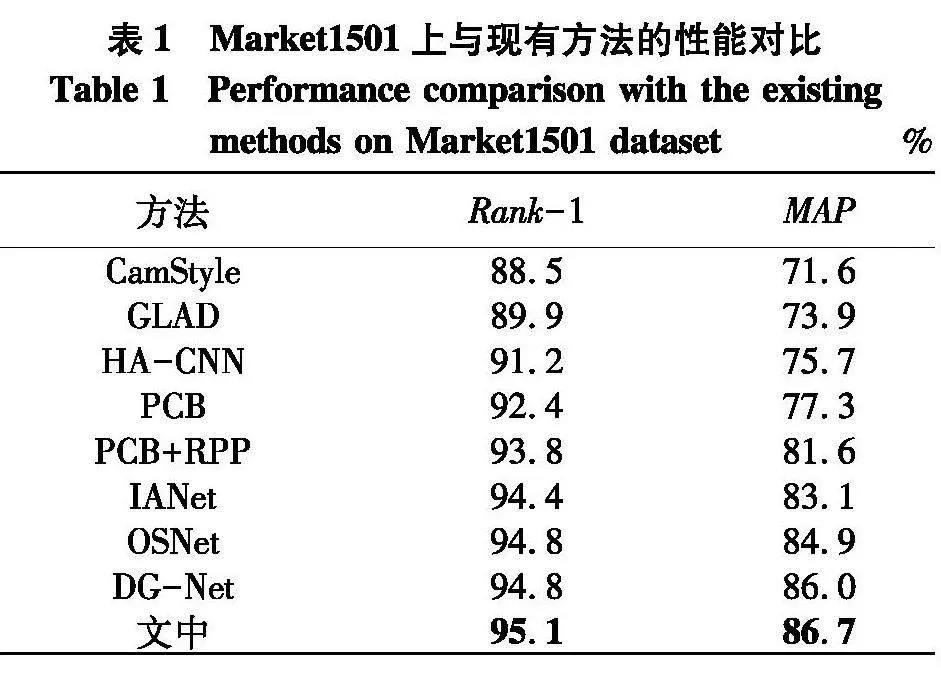
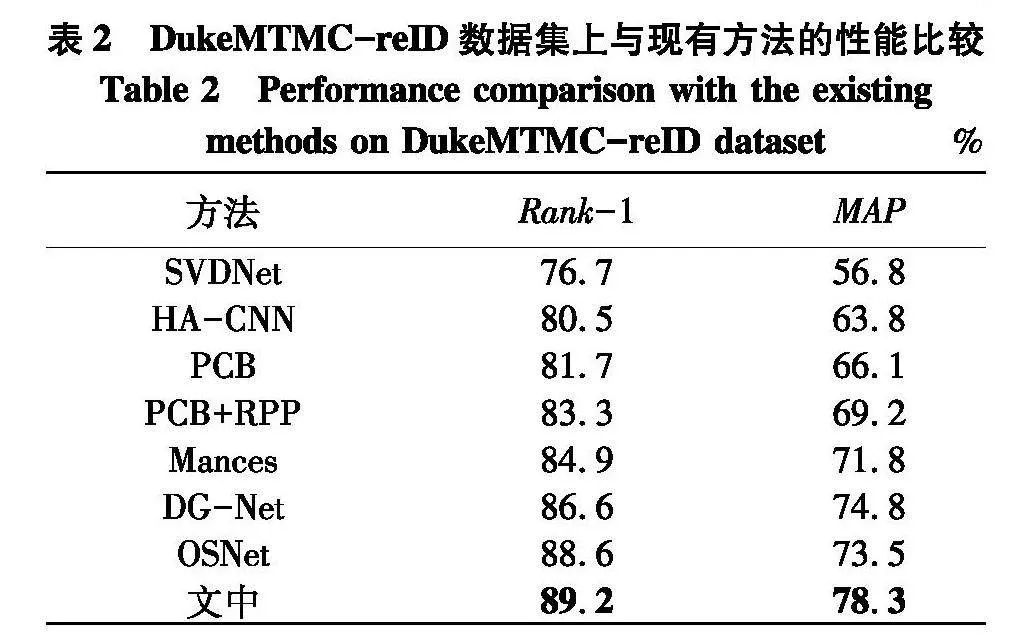
将文中算法与近年主流算法在Market1501和DukeMTMC-reID两个数据集上进行比较,结果如表1、2.
由表1可以看出,文中算法在Market1501数据集上Rank-1和MAP精度分别达到了95.1%和86.7%,与目前较优的DG-Net相比,Rank-1和MAP分别提高了0.3%和0.7%.
由表2可以看出,在DukeMTMC-reID数据集上,文中方法Rank-1和MAP精度分别达到了89.2%和78.3%,较于OSNet算法精度分别提高了0.6%和4.8%.结果表明,所提模型能够有效提升行人重识别的准确率.
5.4" 消融研究
为评估所采用的各方法对网络模型的影响,在Market1501 数据集上设计了一系列消融实验.
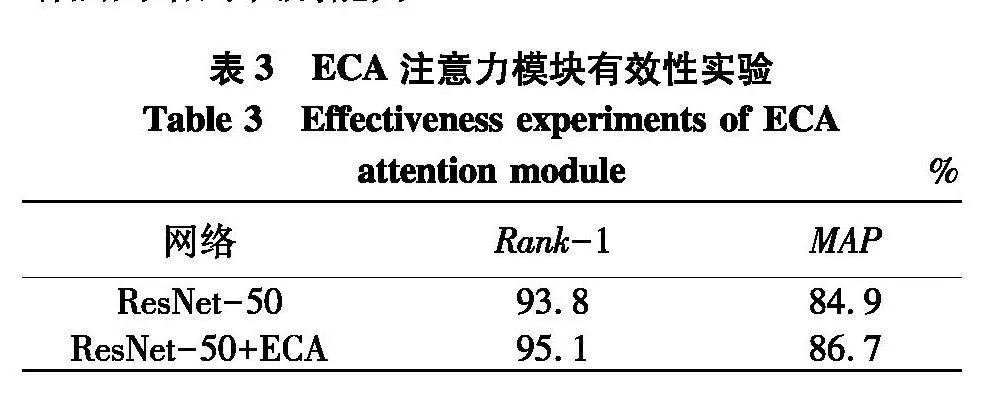
5.4.1" ECA注意力模块有效性分析
为验证ECA注意力模块的有效性,对比了仅采用ResNet-50为骨干网络和采用嵌入ECA注意力模块的ResNet-50为骨干网络两者的实验结果,如表3.可以看出,添加了ECA注意力模块后,网络模型在Market1501 数据集上的Rank-1提升了1.3%,MAP提升了1.8%.实验结果表明,添加ECA注意力模块有助于网络对有效特征的提取,增强网络的识别能力.
5.4.2" 多分支多池化架构有效性分析
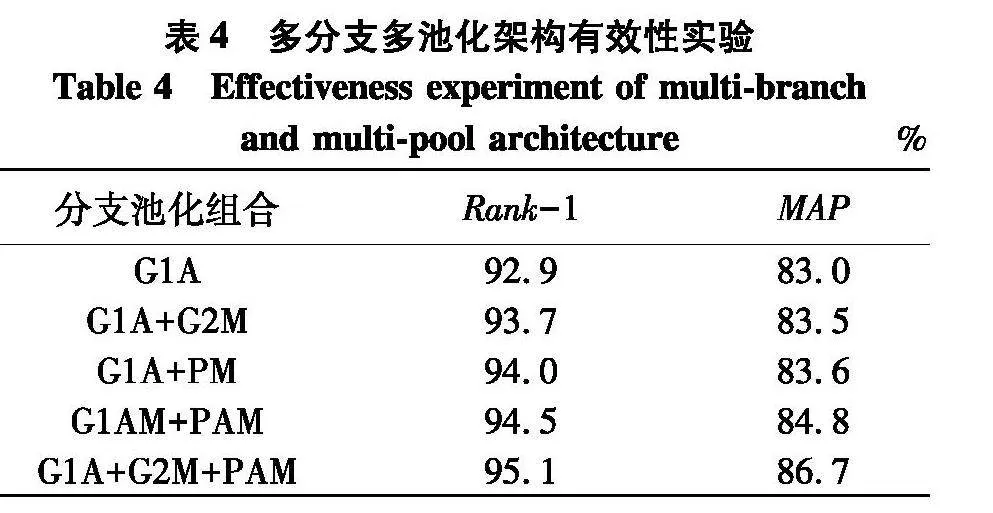
为研究多分支结构和多池化特征提取对网络模型的影响,选择不同分支和不同池化的组合进行了一系列对比实验.结果如表4.
表4中G1、G2和P分别代表全局分支1、全局分支2和局部分支.A代表全局平均池化,M代表全局最大池化.因此,G1A表示采用全局平均池化的全局分支1,G1M表示采用全局最大池化的全局分支2,PAM表示采用多池化(全局平均池化和全局最大池化)特征提取的局部分支.
在多分支方面,可以看出,当只有全局分支G1A时,识别精度最低,Rank-1与MAP分别为92.9%和83.0%.而每增加一个分支,Rank-1和MAP精度都会提高,这体现了多分支模型的有效性.
在池化方面,当采用G1A + PM方法时,Rank-1与MAP精度仅达到了94.0%和83.6%.而采用G1AM + PAM方法时,Rank-1与MAP精度分别达到了94.5%和84.8%,相比于单池化分别增加了0.5%和1.2%.这体现了多池化模型的有效性.因此,结合两者的优势,最终选用三分支多池化方法(G1A + G2M + PAM),获得了最好的实验结果.
5.4.3" 多损失函数和BNNeck有效性分析
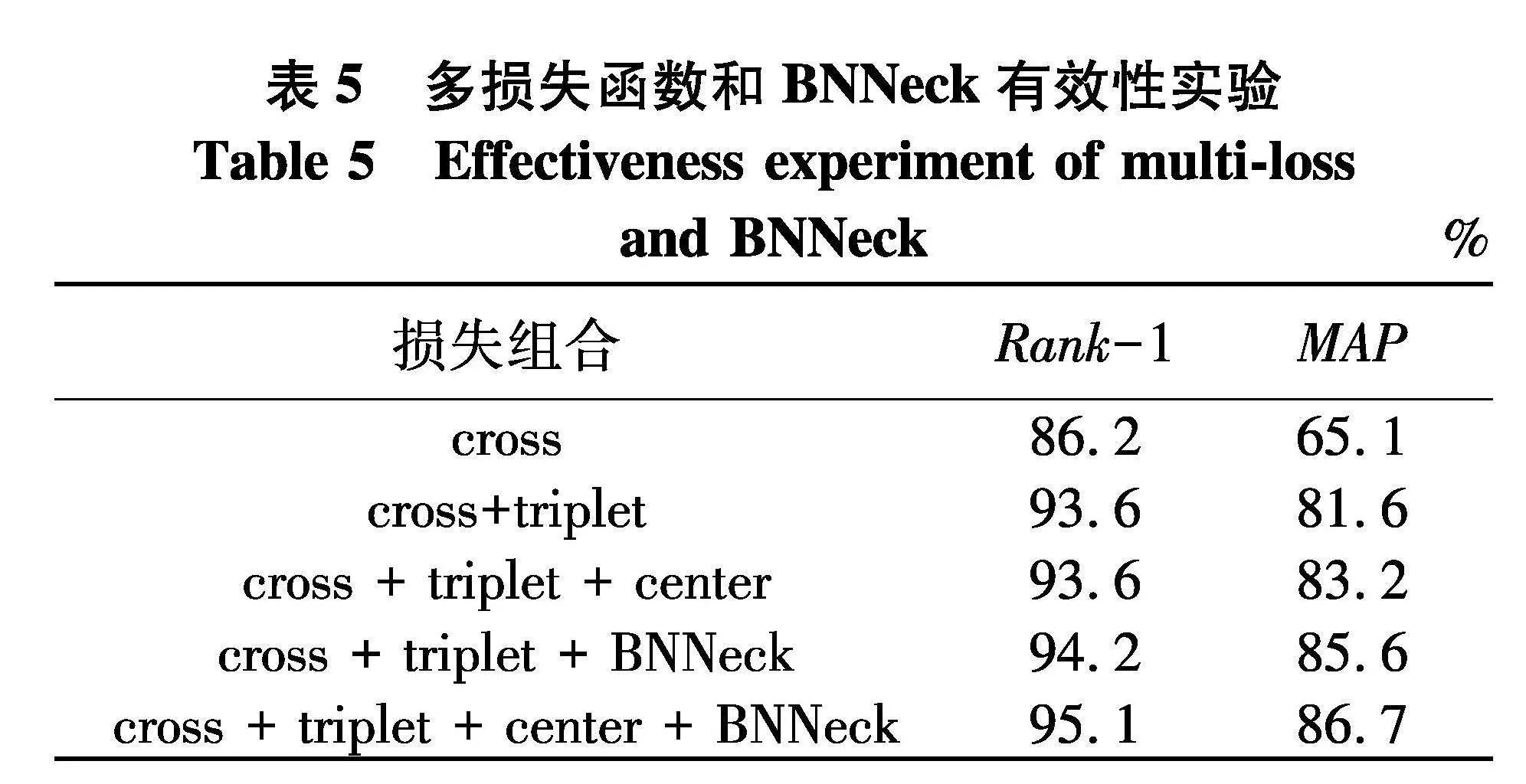
为证明多损失函数联合学习以及BNNeck对损失进一步优化的有效性,进行了一系列定量分析(表5).
表5中,cross代表交叉熵损失,triplet代表三元组损失,center代表中心损失.可以看出,当联合三种损失函数共同训练时,Rank-1和MAP精度分别达到93.6%和83.2%.相比于只有两种损失函数联合学习的模型,虽然Rank-1精度没有提高,但是MAP精度提高了1.6%.而对于只有交叉熵损失函数的模型,Rank-1和MAP精度分别提高了7.4%和18.1%.此外,当联合三种损失函数的模型加上BNNeck进行优化后,Rank-1精度提高了1.5%,MAP精度提高了3.5%.实验结果证明了多损失函数的有效性以及BNNeck对损失的优化作用.
5.5" 实验结果可视化
图4展示了文中实验的部分可视化结果.图中左侧query是待查询图像,右侧1~10是查询结果图像.其中,无边框的图像为正确检索结果,有边框的图像为错误检索结果.不难看出,文中方法具有较高的识别效果,从而显示了模型较强的鲁棒性.
6" 结论
针对行人特征提取方法问题的不足,提出了一种融合ECA的多分支多损失行人特征提取模型.得出如下结论:
(1) ECA注意力模块的嵌入增强了行人的显著特征,抑制了不相关特征.
(2) 多分支网络能够同时提取行人的全局特征和局部特征,并采取不同的池化方来充分进行特征提取.
(3) 为了进一步提高模型的鲁棒性,结合了三种损失函数对模型进行训练,并采用BNNeck进行优化.
在Market1501和DukeMTMC-reID两个数据集上的实验结果表明,文中模型具有较好的鲁棒性,同时在识别精度上也有所提升.未来的工作是进一步优化模型,在不增加网络复杂度的前提下提高行人重识别的准确率.
参考文献(References)
[1]" 李永顺,李垣江,张尤赛,等. 应用HOG-CHT组合特征的行人检测[J].江苏科技大学学报(自然科学版),2017,31(1):66-27.
[2]" ZHENG L, YANG Y, HAUPTMANN A G. Person re-identification: Past, present and future[J]. Journal of Class Files,2015,14(8):1610.02984.
[3]" LIN Y, ZHENG L, ZHENG Z, et al. Improving person re-identification by attribute and identity learning[J]. Pattern Recognition, 2019, 95: 151-161.
[4]" LIAO S, HU Y, ZHU X, et al. Person re-identification by local maximal occurrence representation and metric learning[C]∥Proceedings of the IEEE Conference On Computervision and Pattern Recognition.USA:IEEE,2015: 2197-2206.
[5]" SUN Y, ZHENG L, YANG Y, et al. Beyond part models: Person retrieval with refined part pooling [C]∥Proceedings of the European Conference on Computer Vision.USA:ECCV,2018: 480-496.
[6]" WEI L, ZHANG S, YAO H, et al. Glad: Global-local-alignment descriptor for pedestrian retrieval[C]∥Proceedings of the 25th ACM International Conference on Multimedia.USA:ACM,2017: 420-428.
[7]" ZHENG L, HUANG Y, LU H, et al. Pose-invariant embedding for deep person re-identification[J]. IEEE Transactions on Image Processing, 2019, 28(9): 4500-4509.
[8]" WANG G, YUAN Y, CHEN X, et al. Learning discriminative features with multiple granularities for person re-identification[C]∥Proceedings of the 26th ACM International Conference on Multimedia.USA:ACM,2018: 274-282.
[9]" XU J, ZHAO R, ZHU F, et al. Attention-aware compositional network for person re-identification[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.USA:IEEE,2018: 2119-2128.
[10]" SI J, ZHANG H, LI C G, et al. Dual attention matching network for context-aware feature sequence based person re-identification[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.USA:IEEE, 2018: 5363-5372.
[11]" CHEN T, DING S, XIE J, et al. Abd-net: Attentive but diverse personre-identification[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision. USA:IEEE,2019: 8351-8361.
[12]" CHEN B, DENG W, HU J. Mixed high-order attention network for person re-identification[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision.USA:IEEE,2019: 371-381.
[13]" WANG Q, WU B, ZHU P," et al. ECA-Net: Efficient channelattention for deep convolutional neural networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.USA:IEEE,2020:11534-11542.
[14]" HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. USA:IEEE,2018: 7132-7141.
[15]" SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. USA:IEEE,2016: 2818-2826.
(责任编辑:曹莉)
