基于Storm的可扩展的分布式网络爬虫系统设计研究
2024-09-04池国俊
关键词:Storm;可扩展;分布式;网络爬虫;系统设计
0 引言
在互联网时代背景下,大量新型商业模式被广泛应用于互联网领域中,造成互联网上所创建的站点数量急剧增加,导致互联网上的信息资源呈现出指数型爆炸式增长。在海量互联网信息资源中,人们若想快速检索和查阅自己感兴趣的网络资源,必须加强对网络爬虫技术的应用[1]。然而,传统单机网络爬虫技术过于落后,难以满足现代化日益增长的数据抓取使用需求。分布式网络爬虫系统的设计和应用可以解决上述问题,该系统主要应用Storm云平台,确保多台机器在运行期间能够高效地分工合作,使得网络爬虫速率和性能不断提升。因此,在Storm云平台的应用背景下,强化对新型分布式网络爬虫系统设计和实现的研究显得尤为重要。
1 提出问题
传统单机网络爬虫技术因过于落后,难以满足现代化日益增长的数据抓取使用需求。而分布式网络爬虫系统的设计和应用可以解决以上问题,该系统主要应用Storm云平台,确保多台机器在运行期间,能够高效地分工合作,使得网络爬虫速率和性能不断提升。
2 具体设计方案
2.1 系统设计原则与关键技术
2.1.1 系统设计原则
该系统设计目的是提高分布式网络爬虫的速度和性能,为用户打造安全可靠的网络环境。因此,系统设计应遵循以下几个原则:1) 效率性原则。通过提升系统效率,避免因系统运行过慢而降低用户体验。为满足系统效率性需求,应将系统内部网络带宽设置在万兆以上,避免因网络运行缓慢而降低系统整体运行效率。2) 可靠性原则。系统可靠性主要是指系统正常执行一段时间所对应的概率,系统实际运行过程中,如果出现非法输入数据行为,或者某硬件部分出现异常问题,此时,系统仍然继续稳定执行相关功能的概率,通过提高系统可靠性,可以确保系统能够正常、稳定、安全地运行。3) 安全性原则。系统安全性需求主要涉及数据预防丢失、禁止网络病毒入侵系统等,通过对系统进行安全化设计,可以实现对系统数据访问流程的保护,避免系统数据出现丢失、泄露等风险,同时,还要加强对系统权限安全化管理,避免因出现非法人员登录和访问该系统造成重要系统数据丢失。
2.1.2 Storm 云平台
Storm的出现填补了这一空白。Storm云平台由Nathan Marz开发,后被Twitter收购。收购后,Twitter 将Storm开源,随后社区越来活跃,使用者越来越多,名声大噪,被很多企业采纳使用,甚至很多被用于二次开发,催生了许多优秀产品。Storm主打计算实时流数据,使得对源源不断的流数据处理起来变得更加方便,弥补了Hadoop批处理在实时数据的低效性[2]。
2.2 系统总体设计
2.2.1 系统框架设计
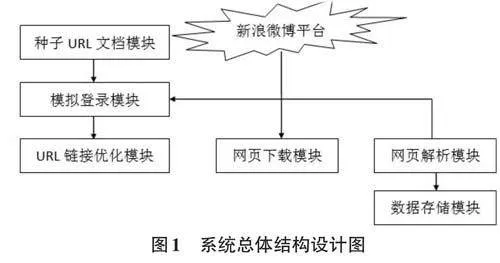
应用本文系统抓取新浪微博平台数据时,首先,利用Storm云平台对网络爬虫相关数据进行抓取,随后,将抓取好的数据安全传输并存储至分布式数据库中,为后期的聚类、分类等业务处理提供依据。与传统单机网络爬虫技术相比,本文系统具有数据处理速度快、容错性高等优势。本文系统总体框架如图1所示,从图1中可以看出,本文系统主要包含种子URL 文档、模拟登录、URL优化链接、网页下载等模块,这些模块既相互独立又相互联系,在实际运行期间分工明确[3]。
2.2.2 系统数据库设计
当网络数据被成功抓取后,需将抓取的数据存储到数据库中,以便后期相关人员查看和调用。因此,在进行本文系统设计期间,要重视对系统数据库的设计。系统数据库中包含多种数据表,为保证数据库设计质量,本文重点设计了搜索结果表、用户信息表、微博评论信息表、微博转发信息表等数据表[4]。其中,搜索结果表包含微博发表时间、微博发表设备、微博地址、微博内容等属性;用户信息表包含用户姓名、用户昵称、用户地址、用户粉丝数、用户微博数、用户关注数等属性;微博评论信息表主要包含微博评论内容、评论时间、被点赞次数等属性;微博转发信息表主要包含微博转发时间、微博转发次数、微博点赞次数、微博URL地址等属性。
另外,为确保所设计的数据库能更好地满足数据的增删改查操作,现将数据库操作封装类的主要代码编写如下:
2.3 系统模块设计
2.3.1 种子URL 文档模块
首先初始化种子URL文档。Storm集群在Topol⁃ogy的Spout中将该种子URL读入集群中,作为网络爬虫的入口。在该Topology中,Spout为系统消息读入的接口,因此种子URL在该Spout中的nextTuple()函数中发送给下一个Bolt来处理。Storm的Topology在初始化的时候会先初始化open()函数,因此种子URL可以在该函数中直接获取[5]。
2.3.2 模拟登录模块设计
模拟登录模块是使用程序模拟真实新浪微博用户来登录新浪微博平台,目的是获取Cookie。其中,需要跟新浪微博身份认证平台进行一系列的交互。
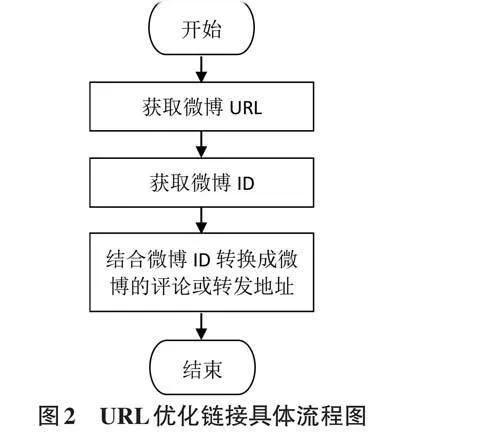
2.3.3 URL 优化链接模块
URL优化链接的具体流程如图2所示。从图2中可以看出,首先获取微博URL,通过应用Chrome浏览器开发工具快速查找和获取微博URL地址(如:http://weibo. com/aj/v6/comment/big? id=3817652743101226&page=2) 。其次,获取微博ID。结合所获取的微博URL,不难发现微博的唯一ID为“3817652743101226”。最后,对获取的微博URL地址进行转化,使其转化为某条微博评论或者转发期间可以翻页的地址,该地址可被新浪微博平台快速识别和获取[6]。
2.3.4 网页下载模块设计
在设计网页下载模块时,为提高网页下载速度,须运用多线程思想。具体操作包括:使用线程连接池对线程进行统一管理,减少线程的创建或者销毁,从而达到提高系统程序执行性能的目的。在进行网页信息抓取时,要运用get请求,当get请求发送结束后,从新浪微博平台中抓取和查找HTTP状态响应值。针对所获取的状态响应值进行个性化操作和处理。当响应码显示为“200”,说明本文系统服务器成功接收和发送get请求,并成功返回相应的响应数据,此时网页下载成功[7]。
2.3.5 网页解析模块设计
运用网页下载模块,所下载的网页通常含有冗余、无利用价值的数据,此时,需要将所下载好的原始网页数据传输和发送至网页解析模块,由网页解析模块对这些数据进行筛选解析处理。在设计网页解析模块时,通常会用到HTML文档解析器。该解析模块所解析内容主要包含以下两个部分:1) 从网页中,解析出所需要的URL链接,然后,将该链接发送和传输至URL链接优化模块中,由URL链接优化模块对该链接进行优化处理,并将最终优化处理结果发送和存储至数据库中[8]。2) 从网页中解析出微博评论等所需数据。总之,网页解析模块用于对微博数据、微博用户数据、微博转发数据等多种数据的统一解析处理。
2.3.6 数据存储模块设计
在设计数据存储模块时,需要使用Java来操作分布式数据库,需要在工程中添加mongojavadriver2.9.3.jar依赖,而后可以通过程序来对分布式数据库进行增删改查等操作。在操作整个集群的时候,由于仲裁节点不存储数据,只负责投票,因此前端不需要连接到仲裁节点。在分布式数据库中建立一个名为“的数据库,然后连接到数据库中具体的集合。
3 设计方案执行效果
3.1 Storm 集群环境搭建
在Storm集群中,含有三个节点,这些节点主要运行于Nimbus、Supervisor后台程序中。在搭建Storm集群环境时,需要在下载和安装Zookeeper集群的基础上,做好对Storm相关参数的配置,然后,启动所创建好的Storm集群。
3.2 系统功能测试
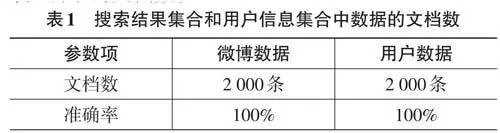
为测试系统功能实现效果,本文以“新浪微博”为应用场景,通过对“地震”“伤亡”关键字眼进行主题搜索,从微博数据、用户数据两个角度分析,测试系统所抓取信息数据情况。通过搜索以上关键字眼,系统会自动呈现出2 000条微博数据,即2 000个用户发表了2 000条微博数据。通过查看分布式数据库,获得如表1所示的文档数。
从表1中的数据可以看出,本文系统抓取准确率达到百分之百,这说明新浪微博中“地震”“伤亡”不同主题下的各项数据均成功抓取。因此,本文系统所含有的模拟登录、网页下载、数据存储等功能模块可以正常、稳定地运行。
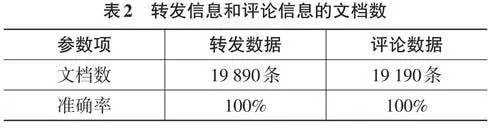
为测试和验证本文系统在抓取微博评论信息、微博转发信息方面的性能,以“某一条微博”为案例,该条微博含有19 890条微博转发量和19 190条微博评论量,通过调用分布式数据库查看转发信息和评论信息所对应的文档数,获得如表2所示的查看结果。
从表2中的数据可以看出,本文系统抓取准确率达到百分之百,这说明本文系统全部下载所有评论数、转发数。因此,本文系统通过利用微博的UR地址,可以成功抓取和获得所有微博的评论数和转发数,具有稳定可靠、数据处理能力强等特点。
4 结束语
综上所述,本文所设计的分布式网络爬虫系统主要运用Storm云平台,该云平台具有强大的在功能拓展性和并行处理能力等特性,通过运用Storm云平台这些特性,可以最大限度地提高分布式网络爬虫速度和性能。本文系统在具体设计时,选用“新浪微博”这一应用场景,通过抓取新浪微博平台相关数据,并将所抓取好的数据安全、可靠地存储到指定的数据库中,方便其他人员查看和调用。总之,本文提出的基于Storm可扩展的分布式网络爬虫系统设计方案具有较高的有效性和可靠性;实现对系统种子URL文档、模拟登录、URL优化链接、网页下载等多个模块的成功设计和开发,保证系统各功能模块运行安全性和可靠性,符合预期设计标准和要求,值得被进一步推广和应用。
