基于图像处理和深度学习的答题卡评分算法
2024-09-04张志方少卿




关键词:答题卡识别;图像处理;深度学习;OCR识别;文本相似度计算
0 引言
随着教育信息化的发展,答题卡作为一种常见的考试方式,被广泛应用于各种教育场景,如学校的期中考试、期末考试、高考、托福、雅思等。然而,传统的答题卡评分方法需要人工扫描和阅卷,耗时耗力,且容易出错。因此,如何利用计算机技术实现对答题卡的自动识别和评分,是一个亟待解决的问题。
图像处理是一种利用计算机对数字图像进行分析和处理的技术,它可以实现对图像中信息的提取、变换和增强。图像处理技术在答题卡识别和评分中的主要作用是对答题卡图像进行预处理,如去噪、灰度化、二值化等,以便于后续的图像识别和分析。
深度学习是一种基于多层神经网络的机器学习方法,它可以从大量数据中自动学习特征和规律,实现对复杂问题的高效求解。深度学习技术在答题卡识别和评分中的主要作用是对答题卡中主观题答案的相似度计算、成绩统计等。
基于图像处理和深度学习的答题卡识别和评分算法是一种结合了图像处理技术和深度学习技术的答题卡评分方法,它可以实现对答题卡的自动识别和评分,提高评分的效率和准确性,减轻教师的工作负担,为教育改革和教学改进提供科学依据。
近年来,基于图像处理和深度学习的答题卡识别和评分算法受到了国内外学者的广泛关注,取得了一些研究进展。例如,高强[1] 等人提出了一种基于Hough和Canny的机器视觉方法对答题卡的客观题进行评分的处理方法,实现了对答题卡的客观题成绩分析。杜聪[2]提出了一种基于图像处理和卷积神经网络的技术,实现了对答题卡的客观题自动识别和评分。陈敏[3]提出了一种基于MATLAB的答题卡检测系统,利用数字图像处理的手段,实现了对答题卡图像的预处理、倾斜校正和识别判断。NV7VSbdvhpLL+wJkr6uJbll/670P+ANIYVxKvlCkdys=
尽管已有一些研究成果,但是基于图像处理和深度学习的答题卡识别和评分算法仍然存在一些问题和挑战,如答题卡图像的质量、光照、尺寸、倾斜等因素的影响,能否对主观题进行识别、主观题的手写风格、答案的语义理解等因素的影响,以及算法的通用性、鲁棒性、可扩展性等因素的影响。因此,本文旨在针对这些问题和挑战,提出一种更优化、更智能、更实用的基于图像处理和深度学习的答题卡识别和评分算法,为答题卡评分提供一种新的解决方案。本文的主要贡献如下:
1) 提出了一种图像处理方法,可以对答题卡图像进行预处理,如去噪、灰度化、二值化、校正等,以便于后续的图像识别和分析。
2) 提出了一种基于深度学习的方法,可以对经过OCR[4](Optical Character Recognition,光学字符识别)识别出的主观题答案与正确的主观题答案进行句子相似度计算,对结果进行分析与成绩统计。
3) 在真实的答题卡数据集上进行了实验,验证了本文算法的有效性和准确性,与人工评分的结果进行了对比,表明本文算法可以大大提高答题卡评分的效率和质量。
1 相关工作
答题卡识别评分通常包括两个部分的工作:客观题的识别与评分,以及主观题的识别与评分。因此,首先需要提取答题卡中客观题与主观题的区域。这可以通过图像预处理以及OCR技术来获取相应区域的轮廓。
对于客观题的处理,通常使用图像轮廓的相关方法进行答案的获取。当然,还可以使用透视变换等其他技术,不同的方法适用于不同的场景。
主观题的识别同样运用了OCR技术。在评分时,需要对两个句子的相似度进行计算。可采用的方法有多种,例如:1) 余弦相似度[5]:通过计算两个向量间的夹角余弦值来衡量它们的相似程度。2) Jaccard相似度[6]:通过计算两个集合的交集与并集的比值来衡量它们的相似度。3) 编辑距离[7]:通过计算将一个句子转换为另一个句子所需的最小插入、删除和替换操作步骤数。
本研究采用BERT[8](Bidirectional Encoder Repre⁃sentations from Transformers,基于Transformer 的双向编码器)模型进行句子相似度的计算。
1.1 光学字符识别
OCR(Optical Character Recognition,光学字符识别)是指对文本材料的图像文件进行分析识别处理,以获取文字和版面信息的过程。简言之,就是将图像中的文字识别并转换为文本形式。OCR的基本流程可以简单分为以下几个步骤:
1) 预处理。对输入的图像进行预处理,包括图像去噪、二值化、灰度化、裁剪等操作,以提高后续字符识别的准确性。
2) 特征提取。提取图像中的特征,例如字符的边缘、形状、像素分布等信息,用于区分不同的字符。
3) 字符分类。使用机器学习或模式识别算法对提取的特征进行分类,将字符识别为对应的文本。
4) 后处理。对识别结果进行后处理,包括校正、校验、拼接等操作,以提高识别准确性和整体质量。
目前,有许多开源的OCR工具和框架,可用于不同的应用场景和语言。比如:PaddleOCR[9]:飞桨首次开源文字识别模型套件,旨在打造丰富、领先、实用的文本识别模型/工具库。CnOCR[10]:Python3下的文字识别工具包,支持简体中文、繁体中文(部分模型)、英文和数字的常见字符识别,支持竖排文字的识别。EasyOCR[11]:一种通用的OCR,可以读取自然场景文本和文档中的密集文本。TesseractOCR[12]:可在各种操作系统运行的OCR引擎,是比较常用的一种文本识别工具。Chineseocr[13]:常用于中文文本识别的工具。
1.2 BERT 模型
BERT (BidirectionalEncoder Representationsfrom Transformers) 是一种基于Transformer架构的预训练语言模型,由Google在2018年提出。它通过在大规模文本语料库上进行无监督的预训练,学习文本中的语义信息,并将学到的知识编码为词向量或句子向量。BERT可应用于多种自然语言处理任务,如文本分类、命名实体识别、问答系统等。
BERT模型的主要特点包括:
1) 双向性。BERT采用双向Transformer编码器,能够同时考虑文本中左右两个方向的上下文信息,从而更好地捕捉单词之间的关系。
2) 多层表示。BERT模型由多个Transformer编码器堆叠而成,每个编码器包含多个自注意力层和前馈神经网络层,可以学习不同层次的文本表示。
3) 预训练与微调。BERT模型首先在大规模文本语料上进行预训练,然后可以在特定任务上进行微调,以适应不同的应用场景。
在句子相似度计算中,BERT模型通常采用以下步骤:1) 输入表示。将两个句子分别进行分词,并添加特殊的开始和结束标记,然后将分词结果转换为词向量。
2) 编码器堆叠。将词向量输入BERT模型的多个编码器中,每个编码器会逐步提取句子的语义信息,生成多层次的表示。
3) 池化。从编码器的输出中选择一个特定的表示,通常选择CLS标记对应的向量作为整个句子的表示。
4) 相似度计算。通过计算两个句子的表示之间的余弦相似度或其他相似度度量方法,来评估两个句子之间的相似程度。
BERT模型在句子相似度计算中的应用原理主要是利用其在大规模语料上学习到的语义信息,将句子表示映射到高维空间中,然后计算它们之间的距离或相似度,从而判断句子之间的语义相似度。由于BERT模型能够考虑到句子中的上下文信息和词语之间的关系,因此在句子相似度计算任务中通常能够取得较好的性能。
2 算法具体实现
2.1 图像预处理
获取完整的答题卡图像后,须对图像进行去噪处理,以获得可识别的答题卡图像。本实验采用以下步骤进行去噪。
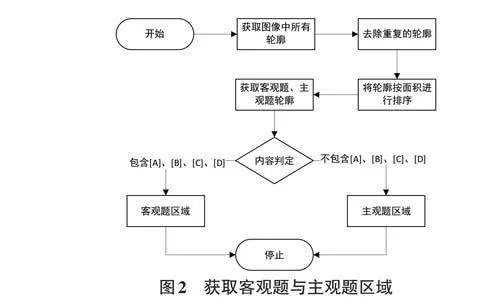
去除图像噪点后,开始对图像中的客观题与主观题区域进行截取。此过程主要通过分析答题卡各轮廓的面积来实现。
通过上述步骤,可以从答题卡图像中提取出评分所需的客观题和主观题答题区域。
2.2 客观题识别及评分
客观题的识别主要通过计算两种轮廓来确定学生的选择题答案:一种是所有答案的轮廓,另一种是学生填涂的答案轮廓。通过计算这两种轮廓的重叠面积,可以确定学生所选择的答案。获得客观题区域截图后,按照以下步骤处理即可得出学生客观题的最终得分。
在上述流程中,对轮廓进行排序时,首先获得180 个轮廓,然后通过轮廓计算其中心点。将这些中心点按照题号及四个选项的顺序进行排序,从而得到排序后的180个坐标点。根据这180个坐标点分别被包含在哪个轮廓区域内,可以对180个轮廓进行排序。
随后,通过计算学生填涂区域与排序后的180个轮廓的重合面积,可以判定学生客观题填涂的具体答案。重合面积判定标准设定为70%,即重合部分面积小于轮廓面积的1.3倍时,判定两个轮廓重合。将最终获得的正确答案数量乘以对应题目的分值,即可得到客观题的最终得分。
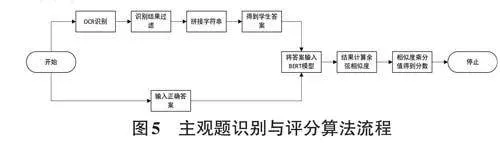
2.3 主观题识别与评分
主观题的识别主要依靠OCR技术和BERT大模型进行答案提取与相似度计算。具体实现步骤如图5 所示。
本研究使用的OCR技术为PaddleOCR技术,从主观题的答题区域识别学生的手写答案。将识别出的字符串进行拼接,得到完整的学生答案。随后,将手动输入的正确答案与学生答案作为模型输入,通过BERT模型转换为两个句子向量。利用余弦相似度计算这两个向量的相似度,得到一个0到1之间的数值,其中0表示两个句子的意思完全不同,1表示两个句子的意思完全一致。将相似度结果与该题目的分值相乘,即可得到最终的主观题得分。
2.4 结果分析
根据上述算法步骤,本实验采用了一种通用的答题卡进行识别及评分。具体实现结果如图6所示。
从图6可以看出,学生填涂的45个题目答案均被正确检测。与正确答案比对后发现,学生正确回答了45道选择题,每题2分,因此选择题最终得分为90分。在主观题部分,学生手写答案与OCR识别后的答案几乎一致,仅有部分标点符号存在微小差异,但这并不影响语句的整体含义。经BERT模型计算,两个答案的相似度为90%。该题目满分为10分,因此学生在这部分获得9分。将两部分得分相加,得到学生的最终得分99分。
图6中答题卡的科目区域显示“90+10”,代表教师手动改卷的得分,其中90为选择题分数,10为主观题分数,最终总分为100分。这表明,基于图像处理和深度学习的答题卡识别和评分算法与人工评分方法的结果几乎一致。此外,该算法在处理速度上有显著提升,同时可以避免人为主观影响和人工误差等问题。
3 总结与展望
本研究提出了一种结合图像处理、OCR技术及深度学习模型的算法,用于识别和评分学生答题卡。该方法首先将答题卡中的客观题与主观题分开处理。对于客观题,通过图像轮廓筛选、排序以及重合面积计算,能够快速获取学生的答案并计算得分。主观题部分则采用OCR 技术获取学生手写答案,并利用BERT模型对学生答案与标准答案进行相似度计算,将结果乘以分值得到主观题得分。最后,将客观题和主观题得分相加,得出学生的最终成绩。
尽管本研究已取得一定成果,仍有改进空间。例如,可以扩展答题卡的题目类型,并考虑光照条件和答题卡印刷质量对图像处理的影响。因此,后续研究可探讨如何避免图像受到此类问题的干扰。总体而言,该算法在当前答题卡视觉识别与评分领域展现出一定的创新性,并取得了较好的效果。
