多实例弱监督语义分割在癌症病理图像分割的应用
2024-09-04杨晗




关键词:病理图像;弱监督;实例;语义分割;像素级标签
0 引言
组织病理学的图像分析已经逐渐成为癌症病情分析的重要辅助手段[1]。近年来,深度神经网络在癌症病理图片的自动分类与分割方面已经取得了许多突破性成效[2]。这些方法通常需要大量的人工与时间成本。目前主流的癌症病理图像分割中,每一张病理图像都需要对应的像素级标签[3],为了减少对像素级标签的需求以及减少成本,许多研究人员提出了弱监督语义分割用于癌症病理图像分割,只需要图像级标签即可[4]。在弱监督语义分割中,用于分割的伪标签也是决定准确度的关键,伪标签越接近真实的专家标注的标签,则分割的精度越高[5]。
本文提出了一个弱监督学习框架用于组织病理学图像分割。主要有三个步骤:首先,使用组合多实例学习(cMIL)方法从原始图像级数据集中使用实例级标签构建高质量的实例级数据集。其次,提高伪标签精度,利用卷积神经网络对实例数据集中癌症病理图片进行特征提取,提取癌症区域并且将其制作成像素级的伪标签。最后,再训练一个完全监督语义分割模型,将伪标签直接用于图像分割。为了验证方法的正确性,在BRACS[6]数据集上进行实验,BRACS是专攻于乳腺癌病理切片的数据集,实验取得了不错的成果。
1 相关工作
1.1 组织病理学图像分割中的弱监督学习
目前来说,运用到病理图像分割的弱监督学习主要归为两类:基于超像素的分割方法以及基于分类网络先验信息的方法[7]。基于超像素的分割方法使用相似像素所合成的超像素训练分类模型,也就是将病理图片中外观相似的区域合并为超像素,训练分类模型之后可以知道所属区域是否为癌症区域。基于分类网络先验信息的方法使用类激活映射图[7]定位图像中的显著区域,一般先使用图像级标签训练分类网络,即在病理图像中选择有癌症区域的以及正常的两个集合一起训练分类网络,然后根据像素点的响应值确定图像中各个区域的类别,最后将训练好的图片作为伪标签作为完全监督语义分割的输入。
1.2 多实例学习在弱监督语义分割中的应用
多实例学习在弱监督方法中广泛应用[8]。然而,尽管多实例学习在弱监督方法中取得了优秀的成果,但许多解决方案需要预先指定的特征,这需要特定于数据的先验知识,这限制了应用的一般性。而在组合多实例学习中,训练过程是端到端的,没有刻意的特征提取和特征学习,使得训练过程非常简单。
1.3 多实例弱监督学习在病理图像分割中的应用
多实例学习中的训练数据是有标记的,一般情况下标记只有两个类别:正和负。多实例学习的目标是学习得到一个分类器,使得对新输入的样本可以给出它的正负标记、目前,多实例学习在病理图像中的应用是将病理图像切割成小图作为实例,经过训练过的分类器得到小图的标记,将小图的正负标记(即癌变的小图以及正常的小图)用不同的颜色区分拼接后得到大图作为伪标签。但在这项工作中,切割成的小图的分辨率不可以太小(太小会使结果误差较大)。弱监督语义分割中还有一种常用方法,利用图像特征提取热力图做伪标签,图像特征提取可以简单地理解为是图像中信息对于预测结果的贡献排名,分数越高(颜色越热)的地方表示,在输入图片中这块区域对网络的响应越高、贡献越大,一般用于弱监督语义分割的预测工作。目前只使用图像特征提取的弱监督语义分割效果并不算理想,但将其作为多实例学习弱监督的补充却已足够,在多实例学习中分割出来的小图恰好可以进行特征提取,但因为特征提取本身的效果一般而多实例学习的效果却很不错,因此本文将多实例学习后标记出的癌症图像进行特征提取,进一步细化伪标签使伪标签精度更高。
2 方法
2.1 多实例分类模型
本文首先构建两个不同的图像的集合,包含癌症区域的图像的集合以及正常的图像的集合。然后将图像切割成了大小一样的N×N小图。使用两个基于实例学习的分类器对图像进行筛选,它们具有不同的标准(Max-Max和Max-Min) 。
Max-Max策略用于选择每个图像切割后的小图中癌变(CA) 概率最高的小图,然后将其加入癌症区域的合集中。而Max-Min策略则是在图像级标签为癌症的图片中选择含癌症区域概率最高的小图,并在图像级标签为非癌症(NA) 的图片中选择正常区域概率最4EXZpuvRO02s3AaVSHAeMpo8R+LBulw5YDSoSByjhJk=高的小图。在组合多实例学习中,将这两个标准结合起来,以减少分布偏差问题,并获得一个更平衡的数据集。
如果图像的图像级标签表示其为癌变(CA) 图像,那么切割后的小图中至少有一个包含癌变区域;如果图像的图像级标签表示其为非癌变(NA) 图像,那么切割后的小图中都不包含癌变区域。Max-Max策略旨在选取每个癌变图像中癌变概率最高的小图,以构建癌症区域的合集。而Max-Min策略则进一步考虑了非癌变图像,从中选取正常区域概率最高的小图。在组合多实例学习中,结合这两种策略可以有效地减少数据分布偏差,从而得到一个更加平衡的数据集。
选择VIT[9]作为分类器。两个基于多实例学习的分类器在相同的配置下分别进行训练,训练结束后,本文将相同的训练数据输入两个训练好的分类器中,在相应的标准下筛选出癌变图片与正常图片,作为预测的结果。图1为组合多实例学习的示意图。
2.2 提取图像特征制作伪标签
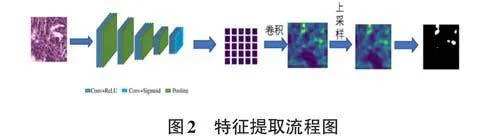
经过预测小图癌变概率,将概率大于0.5的图片视为具有癌变区域的图片,概率小于0.5的视为正常的图片,然后将小图拼接回大图,直接将癌变区域与正常区域用颜色区分作为伪标签。为了使伪标签更加精确,再对图片进行训练,如图2所示,本文借鉴了ResNet-MIL[10]对VGGNET16神经网络进行了一些改进。VGGNet16原本最后输出的是多维的并且分辨率显著降低的图片,这样的结果并不能作为病理图像的伪标签使用。经过改进,可以使输出的多维特征图融合到一张上,并且分辨率恢复到输入图片大小。主干网络使用了VGGNet16,用来提取癌变特征。Vgg⁃Net16在整体上可以划分为8个部分(8段),前5段为卷积网络,后3段为全连网络。前5段的卷积网络都是由卷积层、RELU激活函数与最大池化层组成。卷积层提取特征,最大池化层用于降低模型计算量和扩大网络感受野。由于VGGNet16最后一层卷积输出的特征图是多维的,而实验需要输出的特征图是二维的,因此对最后的特征图进行了1×1的卷积操作,将特征图降低到二维。使用sigmoid激活函数让输出热图上每个点的值处于0~1,从而能够反映概率。为了获得和原始输入图像分辨率大小相同的热图,对输出热图采用了双线性插值上采样的办法,而没有使用反卷积。因为考虑使用反卷积会引入更多的参数,从而导致网络过拟合。经过训练最后将概率高于0.5的像素视为癌变像素点,低于0.5的视为正常像素点,将二者用两种不同的颜色代替,作为伪标签。
2.3 图像分割
得到图像的伪标签之后,就可以使用完全监督的方式训练分割模型。选择医学影像分析中常用的Unet模型来进行分割。U-net整体是编码器-解码器结构,如图3所示。网络的整体结构形似一个大写的英文字母U。编码器主要由卷积层与池化层组成,用于提取特征,由两个3×3的卷积层再加上一个2×2的最大池化层组成一个下采样的模块,一共经过4次这样的操作。解码器由一层反卷积+特征拼接+两个3×3 的卷积层反复构成,一共经过4次这样的操作,最后接一层1×1卷积,降维处理,即将通道数降低至特定的数量,得到预测图。
3 实验
3.1 实验实现
本文利用BRACS 数据集进行了实验,随机从BRACS中抽取500张作为训练集,47张作为测试集验证实验的有效性。实验中考虑到显卡内存空间的限制,同时保留图片更多的空间信息,切割出来的小图均调整到512×512像素大小。
组合多实例学习中的实例分类器和再训练步骤都使用Adam优化器进行训练,固定学习率为0.000 1。在多实例学习中,batch size设置为8。在重新训练步骤中,batch size设置为16。在分割阶段, U-Net使用Adam 优化器进行训练,固定学习率为0.001,batchsize为8。
3.2 制作伪标签
利用组合多实例学习分类模型筛选出小图中癌变区域与正常区域后,将癌变图片输入改进的VGG16 模型,得到特征图,再对特征图进行卷积、上采样等操作后,将特征图进一步转化为伪标签,最后将小图拼接回原图大小的伪标签图。在CAMEL模型[11]中在使用组合多实例学习筛选出正常区域与癌变区域后,直接将得到的区别后的小图拼接回大图作为伪标签。以医生的标注作为标准,测试伪标签的精度,在训练集数据上使用组合多实例学习方法得到CAMEL的伪标签后,再进行特征提取得到本文需要的伪标签。从表2可以看出,特征提取后的伪标签精确度要高于没有进行特征提取的伪标签。
3.3 利用伪标签进行完全监督分割
得到伪标签之后,就可以对病理图像进行分割,将伪标签作为训练集标签进行完全监督语义分割,分割模型采用U-net结构。将本文模型(VGG-MIL) 与当下弱监督语义分割常用的模型进行比较,很明显,本文的模型VGG-MIL效果最为优秀。
4 结束语
计算机辅助诊断组织病理图像能够减轻病理医师的负担。在本项研究中,本文提出了一个弱监督学习框架,用于仅使用图像级标签的组织病理学图像分割。该框架能够利用图像级标签生成像素级伪标签,并取得了相当不错的分割结果。更重要的是,这种弱监督学习语义分割的方法可以推广到其他组织病理学图像分析研究中。在本项研究中,利用图像级标签获取的种子区域在训练过程中是固定不变的,且种子区域对训练结果起着决定性作用。若种子区域质量不佳,也会对训练结果产生负面影响。在未来的工作中,可以考虑利用区域生长法使这些种子区域不断变化,而变化的准则则由相邻点之间卷积神经网络学习到的特征相似性决定。这样做可以增加网络对种子区域生成质量的容错率,有利于最终分割效果的提升。
