基于大模型知识追踪的多模态教育知识图谱构建与应用
2024-09-04王磊时亚文刘晓丹张耀民韩泉叶
关键词:大模型;知识追踪;多模态;教育;知识图谱
0 引言
知识图谱是自然语言处理领域用来存储和表示知识的一种可视化新技术,具有强大的知识查询和语义推理能力。它可以为数字化互联网平台提供丰富的信息处理方式,成为目前互联网计算平台上知识模型和知识图形可视化的重要理论模型。教育知识图谱是智慧教育的重要表现形式,可以提供教育信息检索、个性化学习推荐、学生画像、智能问答、教学预警、精准教学决策分析等智能服务。教育知识图谱通过将分散碎片式的教育资源与相关实体搭建成一个联通的语义化网络,根据语义网络表示实现教育相关的知识点和资源的关联,具体包括知识点之间关联、知识点与学习资源之间关联、知识点与学生行为之间关联等[1]。教育知识图谱是实现多模态教学、自适应学习等智能化教育信息服务的基础,最终为教学决策提供优化建议。
大语言模型提供了强大的数据处理能力和新数据挖掘潜力。基于大模型构建的知识图谱具备了更丰富的专业知识背景和可解释性,可以为应用领域提供一个强大可靠的决策辅助工具。本文基于百度智能云千帆大模型平台,结合知识追踪机制,构建了基于大模型知识追踪的多模态教育知识图谱,并进行了教育知识下游应用。
1 研究现状
教育知识图谱和多模态知识图谱在国内外得到了广泛关注。陈囿任等人[2]在多模态知识图谱中融合了视觉文本等多种源信息,对多模态知识图谱价值及类别进行了分析讨论,从多源异构数据文本生成、表示学习、实体对齐、实体链接等方面进行对比分析,同时对跨模态知识图谱融合技术进行了详细介绍。最后,他们对多模态知识图谱的发展前景进行了分析,提出了目前多模态知识图谱的技术局限性,并给出了自己的见解。叶新东等人[3]针对教育环境的实际问题设计了基于多模态大模型的精准教学支持平台和面向个性化教育的云边协同平台架构,两者之间互补,协同工作。王文广等人[4]总结了多模态知识图谱以及知识图谱在各垂直领域的最新应用,综述了GPT大模型在知识图谱构建过程中的应用现状,并分析了大模型、多模态与知识图谱之间的关系。罗江华等人[5]分析了多模态、大模型与领域知识图谱三者之间的关联,探索了多模态学科知识图谱关键技术与构建流程,设计了多模态领域知识图谱的教育应用案例。车万翔等人[6]调研分析了大模型对自然语言处理的影响,分析了大模型对自然语言处理领域下游任务带来的机遇和挑战,最后讨论了大模型和NLP的前沿技术。余胜泉等人[7]通过增强大模型构建通用人工智能教师架构,介绍了“大模型+精调”技术路线,分析了通用大模型时代教师所面临的机遇与挑战以及应对措施。
多模态知识图谱的构建是一个复杂烦琐的任务,涉及人工智能领域的关键技术,需要数据处理、自然语言处理、计算机视觉、知识图谱等方面的专业知识和技术支持。本文在以上学者的研究基础上,提出了基于大模型知识追踪的多模态教育知识图谱流程,旨在更精准地进行学情分析,对学习者进行学习路径规划,推荐学习资源。
2 大模型
大模型是一种包含大量训练参数和复杂网络结构的深度学习模型,它可以处理海量数据、辅助完成复杂任务,包括图像识别、计算机视觉、语音识别、自然语言处理等。大模型通过海量语料进行长时间训练,从而生成亿级参数的大模型。其本质是通过自监督学习,有效利用了大量没有标签的数据进行预训练。训练过程可以有效地从海量标记和未标记的数据中获取知识并对特定任务进行参数精调,扩展了模型的泛化能力。大模型是未来人工智能各个领域发展的重要方向和关键技术。伴随着深度学习技术的不断发展和应用场景的不断拓展,大模型将会在更多领域展现其巨大的前景,更好地推动人工智能发展。
3 多模态特征融合
多模态特征融合可以将多个模态表示进行融合,每一种不同来源的特征信息都可以被看作一种新模态[8]。不同来源的模态信息可以交叉互补,模态之间可能还存在多样化的信息交互方式,多模态融合能够产生更为丰富的特征信息。目前,大部分研究学者主要是把图像、文本和语音这三种模态进行融合[1]。本研究的特征融合方式采用交互式融合,通过引入交互项来构建不同模态之间的关系。例如,在知识点关系抽取任务中,可以使用交互式神经网络来学习学生发帖/教师回帖和视频观看记录之间的交互信息,从而提高模型性能。
4 基于大模型知识追踪构建多模态教育知识图谱
知识追踪机制根据学生做题历史行为序列数据,以及学生与题目的交互结果,来推算学生对于新知识状态可能会出现的表现行为,从而可以对学生在新题目上的结果进行预测。知识图谱以其构建语义关联、智能聚合的自动化能力,为机器学习模型理解复杂的学习资源和构建知识语义网络提供了新的方法。知识图谱构建的目标是从大量的结构化和非结构化数据中进行实体识别、关系抽取、事件抽取的过程,通过实体对齐、指代消歧等解决多种类型的数据不一致问题,并完成知识融合,将知识表示存储到知识库中,最后进行下游知识图谱推理和应用。知识追踪机制是进行教育资源组织,实现教育资源整合的关键技术。
多模态知识图谱与传统知识图谱的区别在于:前者主要研究文本和数据库的实体和关系,而后者则在传统知识图谱的基础上构建多种模态下的实体,以及多种模态实体间的多模态范式。多模态数据为人们认知世界提供了多样化的信息化支撑。多模态知识图谱的构建是在知识图谱的基础上,融合多种模态知识,如视频、文本、图像等,构建一个功能强大的领域知识图谱。多模态教学利用多种渠道以及不同教学手段,借助于教师、学生肢体语言、语言交流等多种符号资源进行互补,旨在更好地促进学习者自适应能力。
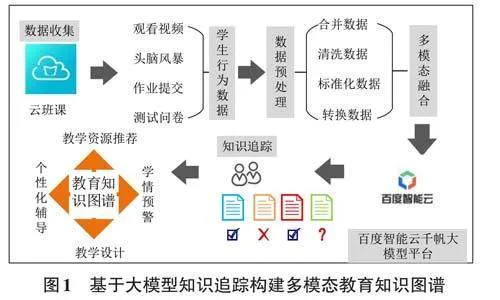
基于大模型知识追踪构建多模态教育知识图谱的步骤如图1所示:
Step 1:数据采集
利用云班课平台导出多种模态的数据,如文本(教案、课件)、图像(教学过程截图)、视频(教学视频)等,并对数据进行整理存储。
Step 2:数据预处理
通过云班课导出的数据存在缺失异常数值,需要对数据的缺失值进行检测并用删除法或插值法等方法进行填充。对于异常值,需要对其进行替换或者删除处理。对于重复值,需要进行删除。通过数据预处理环节,可以使得数据变得更加干净,同时还需要利用数值化、标准化、归一化、离散化等操作将数据转化为建模的输入。
Step 3:多模态融合
多模态融合技术的关键是将来自不同模态的数据进行统一。利用云班课导出多模态数据,包括学生签到、资源浏览、头脑风暴、视频观看、教学互动、作业提交等学生行为数据,通过CNN以及LSTM进行特征提取,为学生行为数据分配权重,将加权求和后的特征向量作为最终的融合结果。
Step 4:多模态命名实体与关系抽取
该步骤可以从文本数据中提取实体之间的关系,并建立实体链接。在命名实体识别和抽取之前,采用后端平均值方法将不同模态数据进行融合作为分类器的输入。在命名实体识别过程中,可以利用文本、图像、音频等多种模态的特征进行融合,再利用文本和图像之间的关联性进行学习[9]。首先对教学资源(教材、课件、试题库)进行分类、标注和整理,利用BiLSTM+CRF深度学习方法从教材、课程大纲等文本资料中提取教学过程中的基础概念、知识重难点。关系抽取首先需要判断一个实体对之间是否有关系,然后判断抽取的关系属于哪个种类。在这个环节仍然采用BiLSTM神经网络进行关系抽取,再通过多模态关系抽取出知识之间的关联和依赖关系[10]。
教育知识图谱知识点OWL描述语言:
<EquivalentClasses>
<Class abbreviatedIRI=":数据框切片"/>
<ObjectUnionOf>
<Class IRI="#连续"/>
<Class IRI="#不连续"/>
</ObjectUnionOf>
</EquivalentClasses>
Step 5:大模型下多模态知识图谱构建
该步骤根据知识点实体和关系构建教育知识图谱,把教育类实体看作图中的节点,关系作为节点之间的边,再将节点连接起来。根据融合后的多模态语义信息以及知识追踪结果,构建多模态教育知识图谱,最后利用图数据库进行知识存储和查询。大模型可以提供更准确、更稳定的预测性能,从而在各种应用场景中发挥重要作用。国内大语言模型中文训练语料数据量丰富,本文使用百度智能云千帆大模型平台对模型进行精调,部署域内知识检索功能,通过输入关键词或问题,从包含大量专业领域知识的数据源中检索相关答案,并生成准确的回答和信息。
Step 6:知识推理与应用
基于构建好的多模态教育知识图谱,进行知识推理和下游应用。多模态教育知识图谱的构建是一个系统工程,涉及跨领域的专业技术。使用图数据库查询语言进行复杂的图查询操作,从图谱中获取相关的知识。依据学生的学习行为记录,通过教育知识图谱规划个性化学习路径和推荐学习资源。基于教育知识图谱产生的学生学习过程和学情分析,也可以为教师提供有效的教学支持和辅助决策。
5 结束语
本文基于大模型知识追踪构建了多模态教育知识图谱,介绍了多模态实体识别、关系抽取,以及多模态融合核心技术。利用融合后的多模态数据和语义信息构建多模态教育知识图谱,采用图数据库来存储和查询多模态知识图谱。基于构建好的多模态知识图谱,可以进行教育知识推理和下游任务,如知识点检索、教学决策和教学预警,最终实现个性化教学资源推荐与精准教学决策。
