基于深度学习的量化索引调制语音信息隐藏检测方法
2024-07-23张豪杨洁



关键词:隐写分析;信息隐藏;压缩语音;深度学习
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2024)18-0073-03
0 引言
隐写术,是一种将秘密信息隐藏在网络传输介质中进行隐蔽通信的技术。随着网络流媒体的不断发展,网络压缩语音受到越来越多的青睐,已成为信息隐藏的极佳载体[1]。量化索引调制(QIM) 作为一种典型的网络压缩语音信息隐藏方法,由于其高隐蔽性,为一些不法分子提供了可乘之机。
网络压缩语音流中的QIM信息隐藏主要是运用语音信号在线性预测编码(LPC) 过程中嵌入秘密信息。Xiao等人[2]基于图论提出一种称为互补邻居节点QIM(CNV-QIM) 码本划分方法,不同的码本对应信息隐藏方法,该方法通过分割QIM码本,秘密信息则将会隐藏在线谱频谱系数码字中;Tian等人[3]提出了一种称作安全 QIM的信息隐藏方法,结合矩阵编码提高嵌入效率和抗检测能力;Liu等人[4]将 LPC 量化索引集合视为三维空间中的点,并基于最近邻投影点替换QIM方法进行信息嵌入。
为了检测网络压缩语音流中的QIM信息隐藏,Li 等人先后提出了基于矢量量化索引分布特征[5]和基于量化码字关联网络[6]两种特征提取方法,利用SVM训练隐写检测分类器实现QIM隐写分析;文献[7]提出了基于贝叶斯网络的压缩语音信息隐藏检测方法,通过构建码字贝叶斯网络,使用Dirichlet分布学习网络参数,实现对 QIM 信息隐藏的有效检测。
近年来,随着深度学习(DL) 的不断发展,出现了一些基于DL的QIM语音信息隐藏检测方法,其效果优于传统方法[8]。文献[9]提出了一种循环神经网络隐写分析模型(RNN-SM) ,首次将长短时记忆网络(LSTM) 结构用于构建码字关联模型。文献[10]基于DL构建了隐写特征融合网络(SFFN) ,该网络相较于RNN_SM在检测语音流中的QIM信息上有更好的提升效果。文献[11]提出了一种基于多通道卷积滑动窗口(CSW) 的隐写分析方法,通过CSW提取邻近语音帧之间的关联特性,取得了更好的检测效果。
现有的这些方法在长时长和高嵌入率时隐写分析性能能够达到比较满意的效果,但是在短时长和低嵌入率时隐写分析性能还有较大的提升空间。为此,本文提出了一种基于深度学习的QIM语音信息隐藏检测模型,通过时序特征提取、融合特征提取、特征分类实现更高效的隐写分析。
1 网络结构
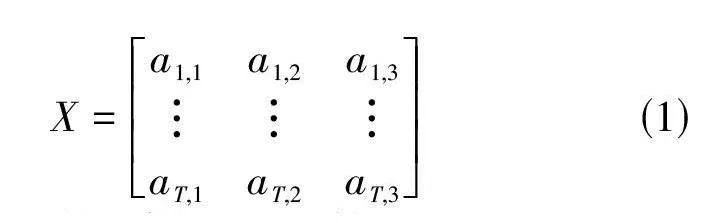
LPC利用线性预测实现对语音信号谱包络压缩表示,能够实现精确的语音参数预测。经LPC后,每帧包含3个矢量量化码字,经过QIM信息隐藏后,码字会发生改变。对于一个包含T 帧的语音样本,其维度则可表示为(T, 3) ,记网络输入样本数据为矩阵X,则X 可表示为:
本文所提出的基于深度学习的QIM信息隐藏检测模型如图1所示,由三个模块组成:时序特征提取模块(TFEM) 、融合特征提取模块(FFEM) 、特征分类模块(FCM) 。首先利用TFEM从输入数据中学习时序维度上的特征,然后利用FFEM学习通道维度和空间维度融合特征,最终使用FCM进行隐写分类。
2 实验与讨论
2.1 数据集与评估方法
本文使用文献[9]中所提出的72小时英文和41小时中文PCM格式语音数据集,使用CNV-QIM隐写术进行信息隐藏,形成隐写语音数据集。嵌入率定义为将秘密信息嵌入语音帧的概率。数据集按3:1:1比例划分训练、测试和验证集。以100%嵌入率中文语音集为例,训练集包含9242 个文件,测试集包含3082 个,验证集包含3080个文件。本文选取准确率为评价指标,模型准确率越高,表明检测性能越优异。
2.2 消融实验
消融实验是评估深度学习模型各个模块贡献的常用方法,通过移除或替换模型的某些部分,可以量化这些部分对整体性能的影响程度。本节将针对检测压缩语音流中QIM隐写术的任务,开展消融实验探究不同模块的作用,结果如表1所示。
移除本文提出的TFEM模块后,在中英文数据集上的检测精度分别为72.27%和78.36%,相较于本文所提出的模型下降了13.91和9.65个百分点。类似地,移去FFEM模块时,模型的检测精度在中英文数据集上的检测精度分别为70.32%和74.48%,相较于本文所提出的模型下降了15.86和13.53个百分点。这说明本文设计的模型是本研究的最佳模型,下面将在此基础上开展其他实验分析。
2.3 在不同低嵌入率下的模型性能分析
评估模型在低嵌入率场景下的检测性能很有必要,因为不法分子通常会选择较低的嵌入率,从而减小对载体语音质量的影响,降低被发现的风险。如表2所示,给出了在10秒语音帧条件下,本文方法与其他三种对比方法在不同嵌入率下的对比结果。
可以看出,在5种嵌入率下本文方法的检测精度均高于RNN_SM,SFFN和CSW三种对比方法。尤其在30%嵌入率下,本文方法在中英文数据集上的检测精度分别高达99.12%和99.07%显著高于其他三种方法。即使在10%嵌入率时,本文方法依旧能够取得86%以上的准确率,比CSW提高超过7个百分点。总的来说,各种嵌入率条件下,本文方法相较于其他方法均表现出了优异的性能。
2.4 不同短时长语音的模型性能分析
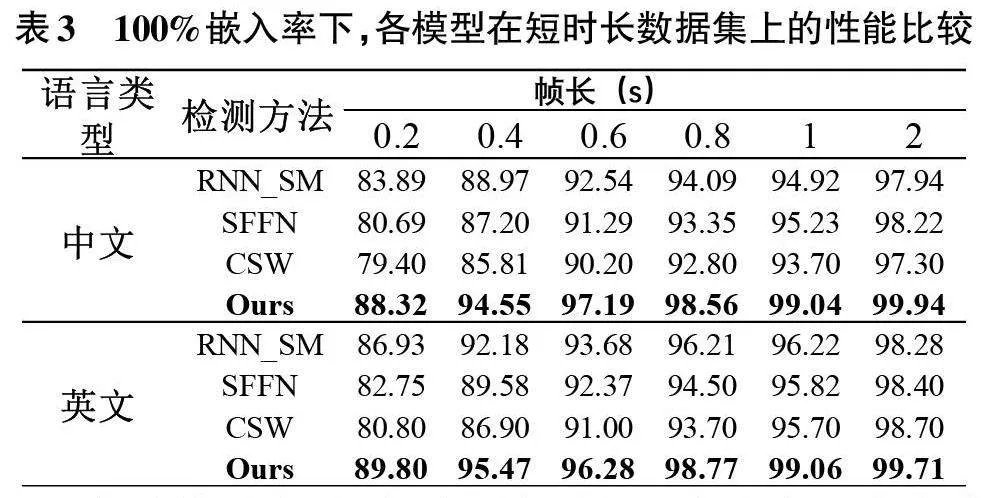
检测隐藏在短时长压缩语音流中的隐写术是一个极具挑战的问题。不法分子往往会选择嵌入较短的语音片段,以降低被发现的风险,达到嵌入秘密信息的目的。因此,评估隐写分析方法在处理短时长语音时的性能至关重要。为此,本文将语音分割成0.2 秒,0.4 秒,0.6 秒,0.8 秒,1 秒和2秒不同时长,并在100%嵌入率下评估了各方法的检测表现,结果如表3所示。
实验结果表明,各种语音时长下本文方法在中英文两种数据集上均能保持较高的检测精度,并全面优于RNN_SM,SFFN和CSW三种对比方法。尤其在较短的0.2秒语音时长上,本文方法在中英文数据集条件下分别取得了88.32%和89.80%的高准确率,相比其他方法提高超过8个百分点,这也验证了本文方法在检测短时语音流中QIM信息隐藏的有效性。
3结论
考虑到现存的隐写分析方法在检测压缩语音流中的QIM存在一定挑战,本文提出了一种基于深度学习的语音隐藏检测方法来解决此问题。实验结果表明,该方法能够有效提取QIM隐写分析的特征,并且相较于其他隐写分析方法,在短时长和低嵌入率条件下具有更佳的检测性能。
