基于3D ResNet-LSTM的人体行为识别模型构建研究
2024-07-23余胜
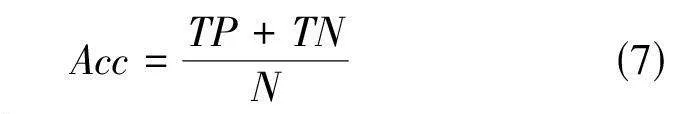

关键词:卷积神经网络;深度学习;人体行为识别;LSTM
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2024)18-0007-04
0引言
近年来,随着计算机视觉和深度学习技术的飞速发展,人体行为识别已经成为计算机科学领域的一个热门研究课题。人体行为识别是指通过分析视频或图像序列,自动识别和分类人体所执行的各种行为动作,如行走、跑步、跳跃、握手等。这种技术可以广泛应用于安全监控、智能交通、人机交互、体育分析等领域。然而,人体行为识别是一个具有挑战性的问题,因为它涉及多个因素,如人体姿态、动作变化、场景光照、遮挡等。为了解决这些问题,研究者们不断探索新的算法和模型,以实现准确、实时的人体行为识别。
当前人体行为识别方法主要可以分为两大类:基于人工设计特征的识别方法和基于深度学习的识别方法。基于人工设计特征的人体行为识别方法主要是通过人为设计特征因子,经过特征提取和分类器分类达到识别目的,主要包括基于时空体积的方法[1]、基于时空兴趣点(STIP)的方法[2]和基于轨迹的方法[3],这些特征都被很好地设计用于基于RGB视频的人体行为识别。近年来,随着深度学习技术的巨大进步,各种深度学习架构也被提出。由于基于深度学习的方法具有较强的表征能力和优越的性能,目前该领域的主流研究主要集中在设计不同类型的深度学习框架上。根据网络框架的组成不同,主要分为三类,即双支流卷积神经网络(CNN)、递归神经网络(RNN)和基于3D CNN的方法。
双支流CNN框架通常包含两个支流CNN,分别从RGB视频中提取不同的输入特征用于人体行为识别,通常通过融合策略获得最终结果。Simonyan和Zisser⁃man[4]提出了一种由空间网络和时间网络组成的双流CNN模型。首先,给定一个视频,每个单独的RGB帧和光流分别被输入空间流和时间流中,分别学习行为动作的表观特征和时序运动特征。然后,将这两个流的分类分数进行融合,生成最终的分类结果。Karpathy 等[5]将低分辨率RGB帧和高分辨率中心裁剪馈送到两个独立的流中以加快计算速度,并研究了不同的融合策略来模拟视频中的时序状态。为了能更好学习到行为动作的表观和运动特征,Wang等[6]将多尺度视频帧和光流输入到双流CNN以提取卷积特征映射,然后在提取到的轨迹为中心的时空管上对其进行采样。最后,使用Fisher向量表示[7]对结果特征进行聚合和使用SVM实现行为动作的分类识别。Wang等[8]将每个视频分成三个片段,并使用两流网络对每个片段进行处理。然后用平均池化的方法对三个片段的分类分数进行融合,得到视频级预测结果。针对当双支流卷积神经网络在融合视频时序信息方面的不足,导致对视频中人体行为动作理解得不充分问题,贾等[9]提出了一种改进的双流ResNet网络模型。针对普通的双支流CNN难以有效处理长时序运动特征、模型的泛化能力偏弱等问题,童等[10]提出了将支持向量机和双流卷积神经网络相融合的人体行为识别方法。
大量研究[11-13]已将二维CNN扩展到三维CNN结构,以同时对视频中的空间和时间上下文信息进行建模,这对于基于视频的人体行为识别任务来说至关重要。林等[11]将残差结构加入VGG16网中,并将其扩展到3D CNN模型。Ji等[13]利用人体检测器方法对视频中的人体进行分割,然后将分割的视频输入新设计的3D CNN 模型中,以从视频中提取时空特征。与文献[13]提出的3D CNN结构不同,Tran等[12]设计了C3D的3D CNN模型,在端到端网络框架中从原始视频中学习时空特征。然而,这些网络主要用于经过裁剪后的视频数据,而不是从完整视频中学习,因此忽略了视频中行为动作的长时空依赖性。Qiu等[14]将3D卷积分解为空间域的2D卷积和时间域的1D卷积,以经济有效地模拟3D卷积。Xie等[15]通过在 I3D 网络中结合使用 3D 和 2D 卷积滤波器,探索了 I3D的几种变体的性能,并引入了时间可分离卷积和时空特征门控来增强人体行为识别。戎[16]等将设计了多流3D卷积神经网络解决跨时间特征信息提取问题,实现了精确的人体行为识别。
由于隐藏层中的循环连接,RNN 可用于分析时序数据。然而,传统的普通 RNN 存在梯度消失问题,使其无法有效地建模长期时间依赖性。因此,大多数现有方法都采用门控 RNN 架构,例如长短期记忆(LSTM) [17] ,来对视频序列中的长期时间动态进行建模。Donahue等[18]设计了长期循环卷积网络(LRCN),该网络由2D CNN提取帧级RGB特征,然后由LSTM生成单个动作标签组成。Ng等[19]从预训练的2D CNN中提取帧级RGB和光流图像特征,然后将这些特征输入到用于人体行为识别的堆叠LSTM框架中。在文献[20]的工作中,使用编码器LSTM将输入视频映射为固定长度的表示,然后通过解码器LSTM对其进行解码,以无监督的方式执行视频重建和预测任务。Wu等[21]利用了两个LSTM网络,这两个LSTM在粗尺度和细尺度CNN特征上协同运行,以实现高效的人体性格识别。
本文设计了一种改进的CNN-LSTM网络的人体行为识别模型,通过设计将CNN和LSTM相结合有效学习到行为动作的表观特征和时序动作特征,实现人体行为动作的识别。
1 人体行为识别方法与原理
1.1 残差网络
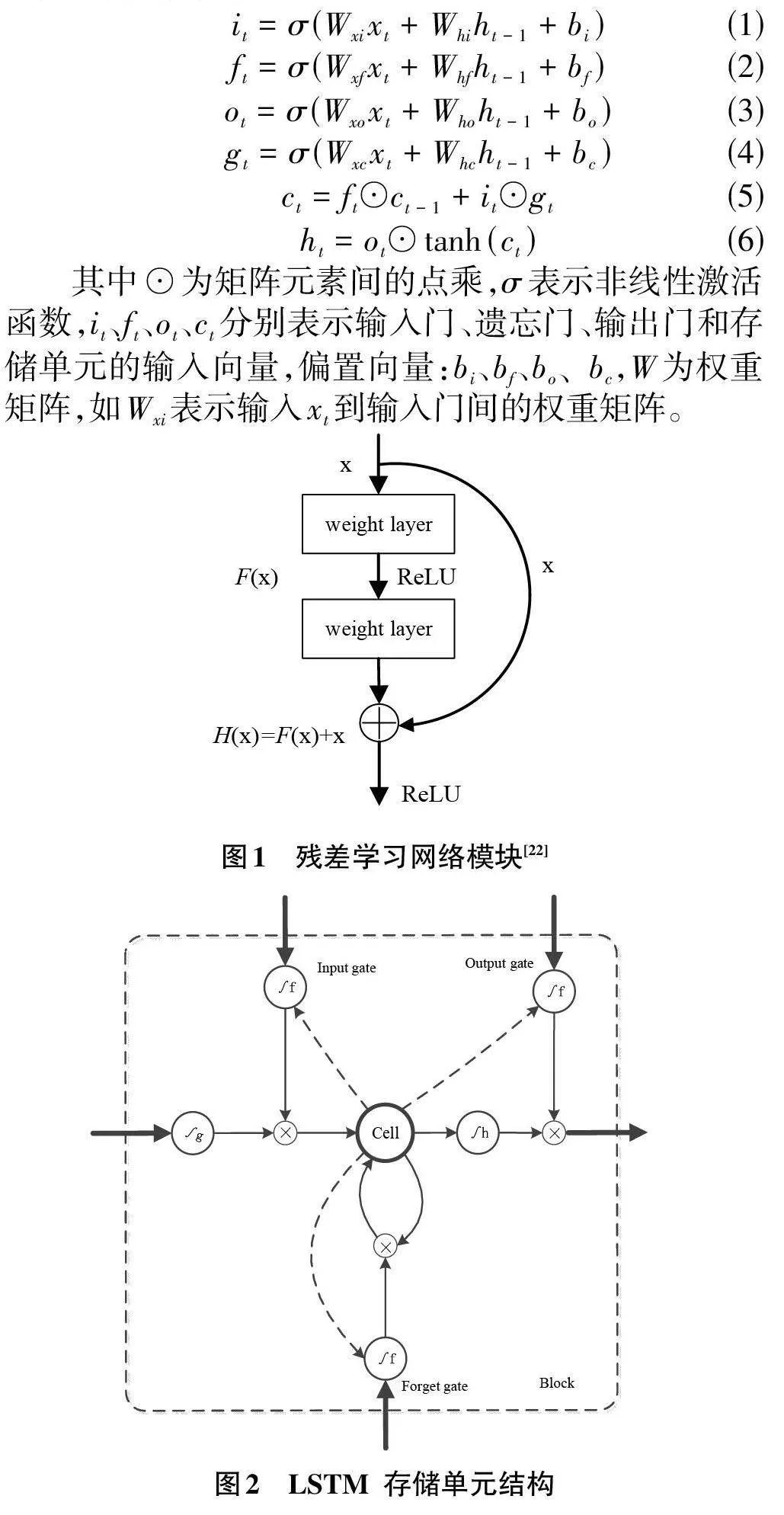
残差网络(Residual Network,简称ResNet) [22]是由微软亚洲研究院研究员提出的一种深度卷积神经网络结构,用于解决深度网络训练过程中的梯度消失和梯度爆炸问题。残差网络的核心思想是引入了“残差学习”(residual learning) 的概念。在传统的深度卷积神经网络中,每个层的输出都是通过非线性激活函数对输入进行变换得到的,而残差网络则通过将输入直接与输出相加,得到最终的输出。这样做的好处在于,当网络的输入和输出之间存在较大差异时,网络可以通过直接拟合差异部分,而不是完全重新学习输入和输出之间的映射关系。残差网络通过引入残差块和跳跃连接的方式,解决了深度卷积神经网络的梯度消失和模型退化问题,使得网络可以在很深的层次上仍然保持有效的学习能力。具体残差网络模块如图1所示,假设输入为x,卷积层的输出为F(x),则残差模块的输出可以表示为H(x)=F(x)+x。这里的F(x)是残差映射,x 是跳跃连接。
1.2 LSTM网络
LSTM(Long Short-Term Memory) 是一种特殊的循环神经网络(RNN) ,用于解决传统RNN在长序列数据处理中的梯度消失和梯度爆炸问题。LSTM通过引入门控机制来控制信息的流动,从而能够更好地捕捉长期依赖关系。LSTM的核心原理是通过三个门控单元来控制信息的流动:遗忘门(forget gate) 、输入门(inputgate) 和输出门(output gate) 。这些门控单元使用Sig⁃moid函数作为激活函数,输出0到1之间的值,表示信息是否通过门控单元。LSTM存储单元结构如图2所示,其中⊗表示相乘,虚线箭头表示存储单元到各个门之间的权重值。输入层特征能否进入该隐含层节点由输入门控制,而遗忘门决定是否保留当前隐含层节点之前时刻的信息,输出门则决定当前节点的输出值是否传递到下一层。假设在t 时刻,对在同一层的神经元的输出值计算:
1.3 人体行为识别模型构建
在本文中,为了融合CNN在表观特征学习能力和LSTM能够处理复杂时序数据的优点,研究提出了3DResNet-LSTM网络的人体行为识别方法。
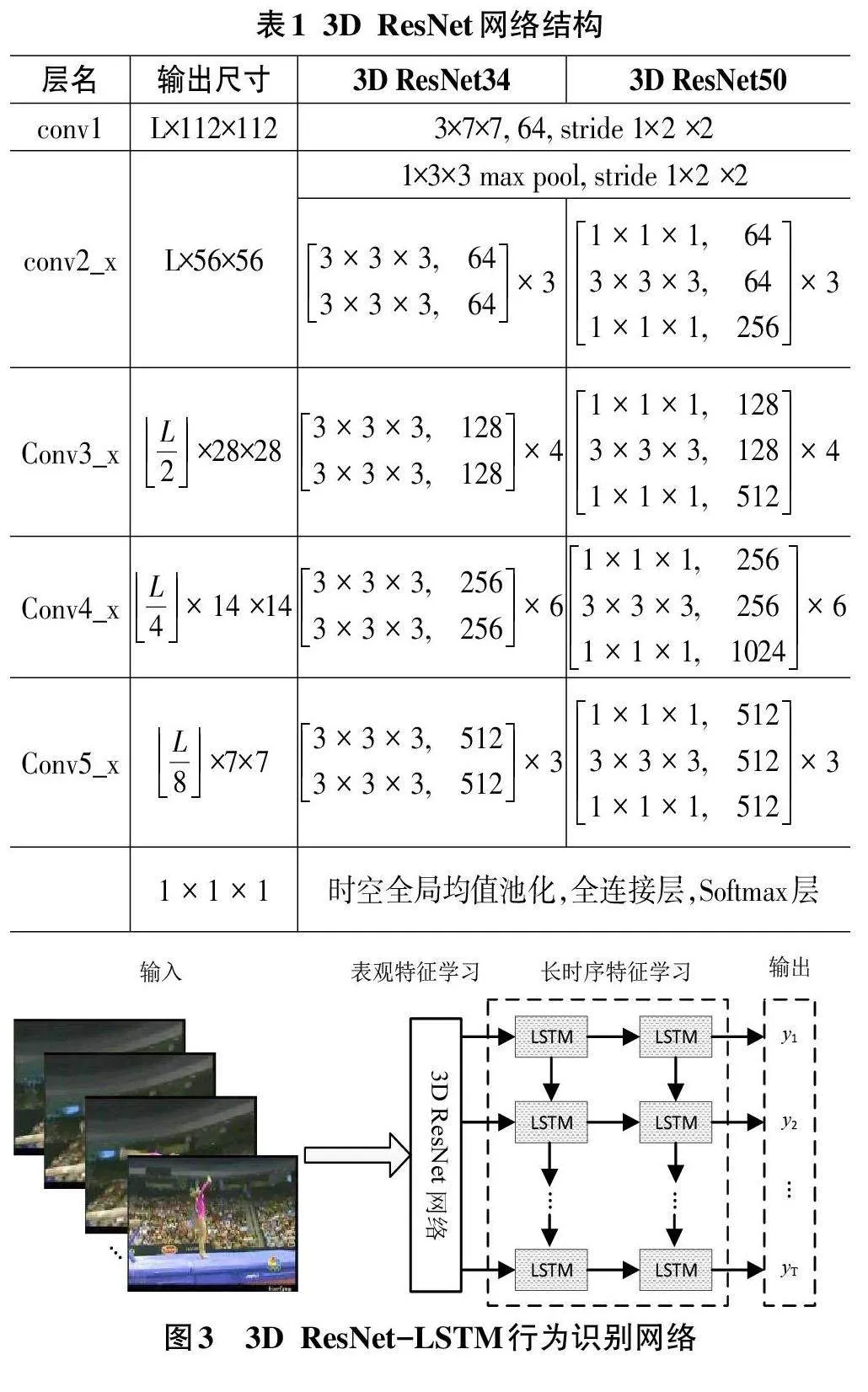
2) 3D ResNet-LSTM 网络。在传统基于CNN 结构提取的空间特征仅在最后通过一个Softmax层进行融合,缺少行为动作的长时序特征。因此,在将视频输入3D ResNet网络后得到的特征按视频时序先后输入到LSTM层中,然后将LSTM层的输出作为下一个LSTM 层的输入。Jeff 等[22] 在LRCN 中发现两层的LSTM网络效果最佳。因此,在本文中所设计的网络模型同样选择堆叠两层LSTM,具体网络结构如图3 所示。
2 实验及结果分析
2.1 实验环境
实验在Ubuntu20.4系统下进行,显卡为NVIDIAGTX Titan,内存32G,网络模型在深度学习平台Ten⁃sorflow和Keras上完成。
2.2 数据集及数据预处理
UCF101是一个现实人体行为动作识别数据集,从YouTube收集而来,包含了来自101个动作类别的13 320个视频。这些视频在动作方面具有最大的多样性,并在摄像机运动、物体外观和姿势、物体比例、视点、杂乱的背景、照明条件等方面存在很大的差异。UCF101中的动作类别主要可以分为以下五种类型:1) 人与物体的互动:这类动作涉及人与物体的交互,例如人们使用工具、操作机器等。2) 仅肢体运动:这类动作只涉及身体的运动,例如跑步、跳跃、游泳等。3) 人与人互动:这类动作涉及两个人或更多人的交互,例如握手、拥抱、打架等。4) 演奏乐器:这类动作涉及演奏乐器或进行音乐表演。5) 体育:这类动作涉及各种体育活动,例如足球、篮球、游泳等。UCF101 的每个动作类别都包含了多个视频,这些视频在内容上有所相似,但每个视频都有其独特的特点,例如背景、视角、光照条件等。
在数据预处理过程中,首先,将视频数据按7:3的比例随机划分为训练集和测试集。然后,将视频按时间轴平均分成三段,在每段视频中随机抽取L × 256 ×256的视频子段,其中L 为视频字段的帧数,256 × 256 为视频帧分辨率。最后是样本数据扩充,将视频子段按随机裁剪、翻转、旋转等方法,最终得到L × 224 ×224的视频子段作为3D-ResNet网络的输入。
2.3 网络参数设置
3D ResNet网络模型训练时,采用随机梯度下降优化方法,视频字段长度L=10,初始学习率为lr=0.001,每200 个epoch 后学习率调整为原学习率的0.1,最大训练epoch 为1 000,动量值m=0.9,批量值batch size = 64。
2.4 评价指标
在人体行为识别中,准确率是用于衡量模型在分类识别任务中准确性的评价指标,表示模型预测正确的样本占总样本数的比例。计算如式(7) 所示:
其中,TP 是正确分类为正样本的个数,TN 是正确分类为负样本的个数,N 为整个样本个数。
2.5 实验结果
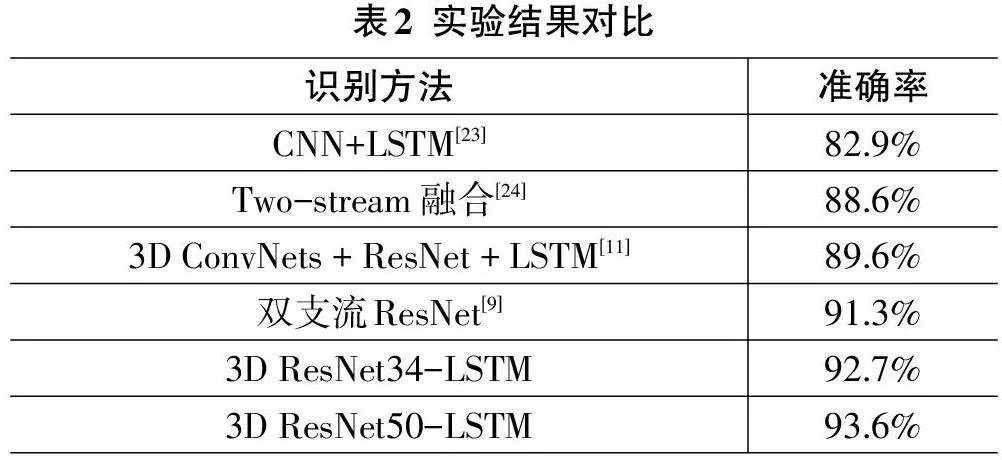
实验的方法与其它经典的人体行为识别方法进行对比,实验结果如表2 所示。从实验结果看,3DResNet网络模型的识别准确率要明显优于对比识别方法的准确率,获得了最高识别准确率93.6%。比较与传统基于CNN的识别方法,3D ResNet得益于3D卷积神经网络在学习到行为动作表观特征后,经过LSTM网络有效地学习到了长时序特征。对比于普通CNN-LSTM网络,前期的3D ResNet网络不仅可以学习到表观特征,而且还能有效处理短时序特征,最终的识别准确率高于CNN-LSTM类网络模型。
3 结论
提出了一种3D ResNet-LSTM的视频人体行为识别方法。网络首先对视频进行按时间轴平均分段、随机抽取视频样本子段、进行视频样本扩充等数据预处理方法;然后用处理后的数据对设计的网络模型进行训练,达到完成行为动作表观和时序特征学习的目标。在UCF101数据集上的实验结果表明设计的3DResNet-LSTM的有效性。
