面向金融新闻的命名实体识别方法
2024-07-23李淦


关键词:命名实体识别; ELMo; 条件随机场; BiLSTM; 金融新闻
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2024)18-0004-03
0 引言
命名实体识别(NER) 经历了从基于词典匹配和统计学方法到基于机器学习和深度学习方法的发展。其中,基于深度学习的方法减少了对人工特征工程的依赖,能让模型自动提取文本特征,提升了泛化能力,因此得到了广泛应用。然而,对于存在大量领域专有名词的金融新闻领域,常规的深度学习模型表现一般[1]。在金融领域,需要识别的实体具有特殊需求,例如产业名称、经营事件、资产关联和投资事件等。
在庞大的金融实体中,实体名称的多义性和实体边界的模糊性,增加了金融新闻领域的实体识别难度。例如,“苹果”既可以是一个企业名称,但常规的实体识别方法可能会将其识别为一般的水果名称。此外,长句中的实体嵌套和结合,在缺乏上下文关系的情况下,容易出现分割错误。为此,本文提出一种能够学习上下文信息的金融领域实体识别方法。
ELMo(Embeddings from Language Models) 模型[2]能够进行词向量的转换。与普通的word2vec方法相比,ELMo可以根据上下文场景动态调整单词的嵌入,捕捉单词在不同语境中的语义。通过两个阶段的训练,首先使用一个语料库进行词嵌入向量的学习,获得单词的上下文语境,之后模型可以对输入的单词进行动态调整,得到上下文相关的语义信息。
将得到的词嵌入向量输入到Attention-BiLSTMCRF模型中即可完成实体分类任务。该模型在开放领域命名实体识别任务中表现优异[3]。本文通过使用不同语料库对ELMo模型进行迁移训练,验证了此方法在金融新闻领域的命名实体识别任务中的效果提升。
1 数据集与数据预处理
本文使用网络上的金融新闻作为数据集,该数据集共包含20 000条新闻数据,以CSV文件格式存储,包含新闻的标题、内容和发布时间等3个部分。
1.1 数据清洗
首先,我们对这些文本数据进行清洗,具体步骤包括:1) 删除无法识别的特殊符号。2) 将繁体字符转换为简体字符。3) 删除字符之间无用的空格以及单行中单独的纯英文字符。
利用Python的正则表达式和字符串处理相关函数,设计了数据清洗流程。在清洗完成后,我们得到了干净的大段文字集合。
1.2 句子切分与分词
接下来,使用字符串分割函数对文本进行句子切分,根据中文标点符号确定句子边界,生成句子列表。然后,借助Python的jieba分词工具对文本数据进行分词和词元标注等操作。为了提高分词准确性,我们使用了jieba分词的搜索引擎模式,并加入自定义的金融领域词典,进一步细分长单词[4]。
1.3 序列标注
对上述文本语料,采用BIOES标注体系进行序列标注:B(Beginning) 表示实体的开始。I(Inside) 表示实体的中间部分。O(Outside) 表示不是实体的单元。 E(End) 表示实体的结束。S(Single) 表示含有一个单词的命名实体。
完成以上数据预处理后,我们得到了带有标签的单词集合,作为模型的训练输入。
1.4 ELMo 模型预训练
我们利用网易新闻语料库、人民日报语料库和维基百科语料库对ELMo模型进行预训练。这3个语料库的规模由大到小分别是维基百科、人民日报和网易新闻,与金融新闻领域的相关度则相反。通过对不同规模和相关度的语料库进行训练,旨在验证迁移训练方法在金融新闻领域命名实体识别任务中的效果。
2 ELMo-BiLSTM-CRF 模型
ELMo模型是双向LSTM网络架构,包含前向和后向两部分,目的在于最大化这两个局部语言模型的似然性。ELMo采用两段式流程:第一阶段是利用语料库对模型进行预训练,第二阶段是在下游任务中从预训练网络中提取出词嵌入向量,作为新的特征补充模型。首先使用一个语言模型学习一个单词的词嵌入向量,然后在使用该词嵌入向量时,根据单词的特定上下文语义对该单词的词嵌入向量进行调整,从而获得上下文相关的语义信息。通过这种动态调整的思想,可以解决传统词向量表示中多义词对应同一向量的问题[5]。
Bi-LSTM着眼于整合前后层神经元间的信息交互,以期解决传统单向循环神经网络中常见的梯度消失问题[6]。它由两层LSTM组成。长短时记忆神经网络旨在解决传统循环神经网络中的梯度爆炸和梯度消失问题,对长期信息进行更加全面的学习。单个LSTM的结构如图1所示。通过前向LSTM和后向LSTM中的控制门和遗忘门,丢弃负面信息并保存正面信息。由于是双向的网络结构,因此可以得到过去对现在的影响和未来对现在的影响两个方向的加权信息。
但由于LSTM在处理长句子序列时需要较长的训练时间才能捕捉到远距离的依赖特征,这导致了对输入序列中单独元素的细节信息丢失的问题,具体表现为其提取长期依赖特征的能力较弱。在经典Bi-LSTM模型的基础上,通过引入自注意力机制来缩短距离,并通过关注度的权重,可以提升长期依赖特征的效果[7]。注意力机制与视觉聚焦机制在理论层面相似,旨在从繁杂信息中挑出与任务目标更为紧密相关的部分。在计算资源有限的情况下,使用注意力机制可以有效解决信息超载的问题。网络模型的参数越多,代表其表达能力越强,但这也会导致训练时间的增加。引入注意力机制可以聚焦更为关键的信息,降低其他信息的权重,从而有效提高任务处理的效率。依据序列信息和键值计算相似度,运用softmax函数处理原分数并获取权重信息,然后对键值和权重实施加权操作以获得注意力值。
Bi-LSTM输出每个字符在各类实体中的得分,输出最高的得分项作为标签预测的结果。但这种输出缺乏规则的约束,因此可以使用条件随机场(CRF) 定义模板对标签分类的结果进行约束。
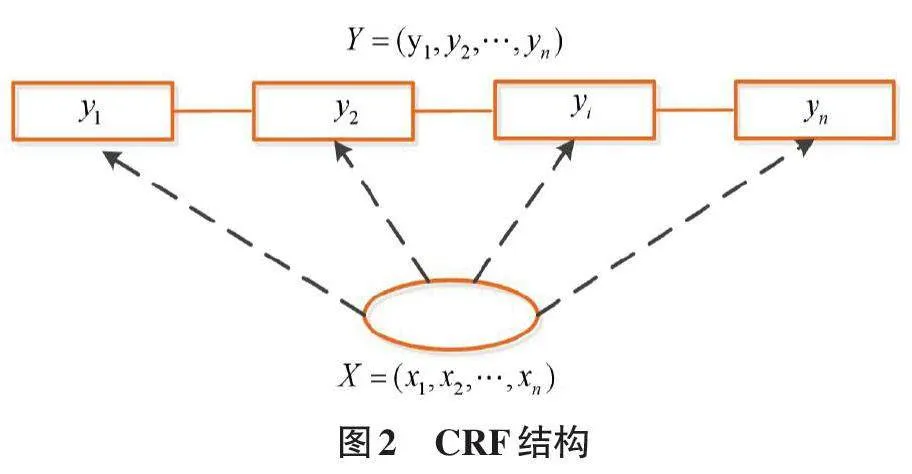
条件随机场(CRF) 是一种无向图模型[8],通过定义丰富的特征模板,展示出超越隐马尔可夫模型(HMM) 和最大熵马尔可夫模型(MEMM) 的优越性能。CRF模型负责将Bi-LSTM模型输出的特征信息进行标注,解决句子中有依赖关系的标签分类问题。CRF的输入是观测序列X,输出是标注序列Y。通过最大似然估计计算损失函数,由Bi-LSTM模型的输出作为预测的标注序列,使得条件概率P(Y | X)最大化,实现实体的特征提取。其结构如图2所示。
只使用Bi-LSTM模型是将序列标注问题视为分类问题,将每一个需要标注的位置都作为一个单独的样本进行分类,这样就缺少了序列不同位置之间的相互关系信息。而CRF模型则能够提供包含完整序列关系的信息。
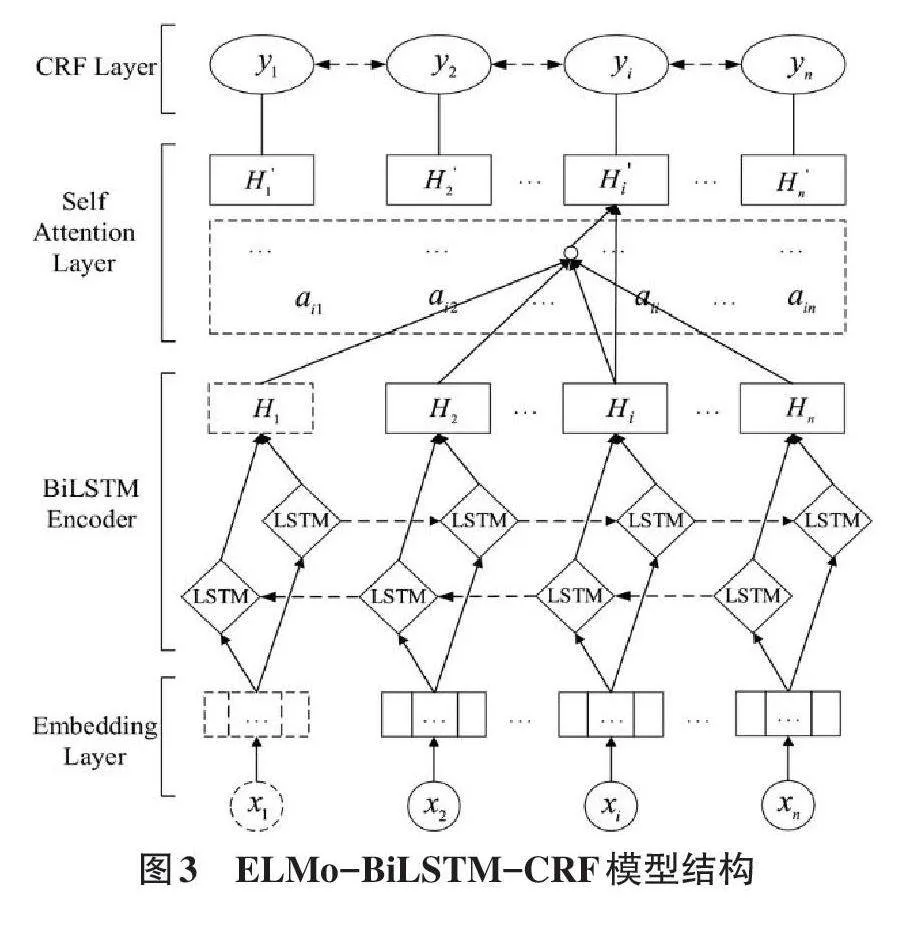
综合以上模型的分析,实验采用的模型总体架构如图3所示。其中,Embedding层通过ELMo模型进行词嵌入向量的转换,形成词向量序列,并将其输入到双向LSTM中。双向LSTM将正向和反向的LSTM的输出向量进行归一化和加权求和,得到正反两个方向语义的融合表示。CRF层以初始的实体序列为参照物,计算标记输出序列的损失值,并以损失值最小化为训练目标,对模型参数进行调整。
3 实验
3.1 实验环境与评估标准
本实验的硬件环境为:处理器:Intel Xeon Gold6138;内存:32GB;操作系统:Ubuntu 22.04。选择的编程语言为Python 3.9.13,深度学习框架为PyTorch 1.13.1。
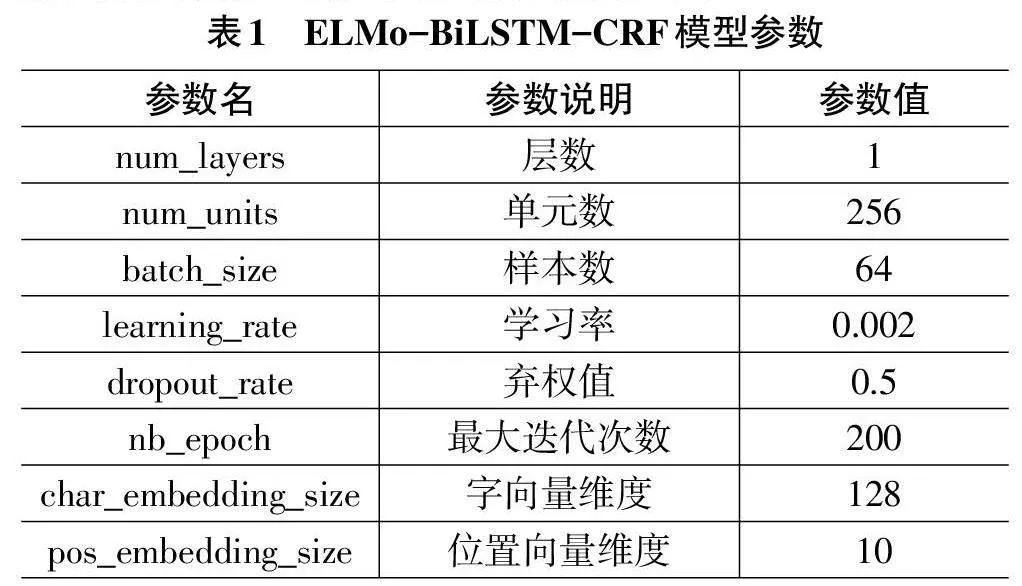
将数据集按照8∶2的比例分为训练集和测试集。为了防止过拟合,在模型中加入了Dropout。经过参数调整,将模型的主要参数设置如下:
采用精确度、召回率及F1值评估模型性能。其中,精确度表示全部正确识别实体占识别总数的比率;召回率指的是在所有实际存在的实体中被正确识别出的比率;F1值为精确度与召回率的调和均值,表示一种综合的考量指标。其定义如下:
式中:TP为正确预测的实例数,TN为正确识别的不属于此类的实例数,FP为被错误划分为此类的实例数, FNi为此类中实例但被误分为其他类的实例数,C为所有类别的总数。
3.2 实验结果与分析
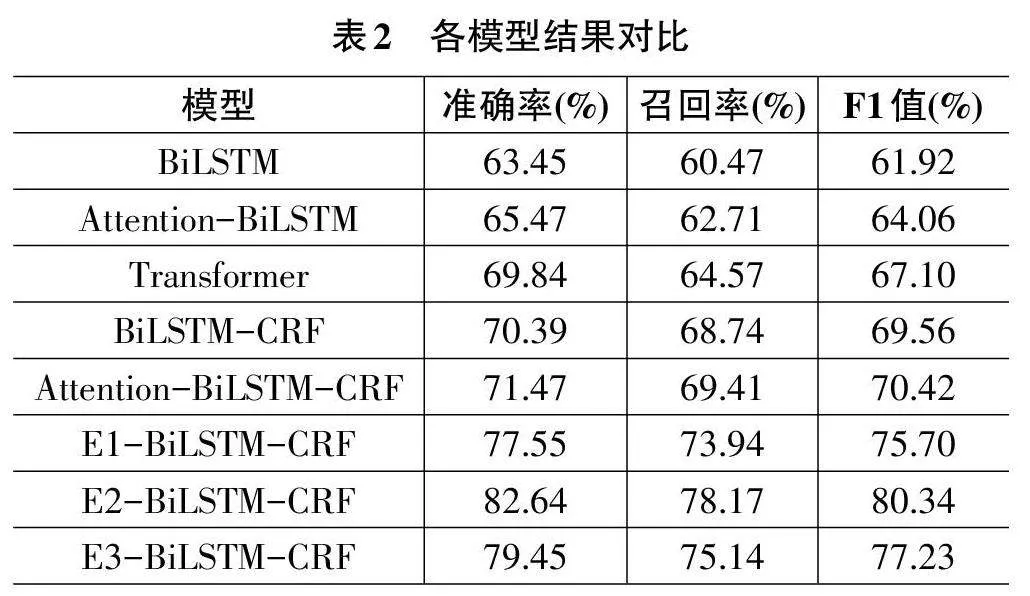
选取BiLSTM、Attention-BiLSTM、Transformer、BiLSTMCRF和Attention-BiLSTM-CRF5种模型作为对比。使用网易新闻、人民日报和维基百科语料库进行训练的ELMo模型分别称为E1、E2、E3。其精确度、召回率和F1值如表2所示。
通过实验结果对比,在Bi-LSTM中引入注意力机制能够小幅提升评价指标,而在Bi-LSTM之后引入CRF用于分类的输出能得到较为明显的提升。由于Transformer模型对上下文信息的获取能力较强,也能得到不错的效果,并且由于它在处理序列数据时经过单层即可获取全局信息,在训练时间上也有所提升。
相比于不使用ELMo 模型作为Embedding 层的Attention-BiLSTM-CRF,使用预训练的ELMo 模型在准确率上最多提升了11%,在召回率上最多提升了9%。其中,E1使用的网易新闻语料库包括4000条新闻数据,而E3使用的维基百科语料库有104万条数据,它通过更大量的训练数据得到了更好的效果。因为兼顾了数据量和领域相关性,使用人民日报语料库训练的E2表现是最好的。
4 结束语
本文使用三种语料库对ELMo模型进行训练,结合Attention-BiLSTM-CRF进行金融新闻数据的命名实体识别任务。通过对比BiLSTM、Transformer 等多种模型,证明了引入ELMo模型可以在金融新闻命名实体识别任务中得到显著的提升。并且,通过分析三种语料库的数据量和领域相关性,得出了使用大数据量和领域相关性强的语料库进行模型训练能够得到更好效果的结论。
