基于自适应注意力机制的表格结构识别模型
2024-06-07郑剑锋张广涛刘英莉
郑剑锋 张广涛 刘英莉

基金项目:国家自然科学基金(批准号:52061020)资助的课题;云南计算机技术应用重点实验室开放基金(批准号:2020103)资助的课题。
作者简介:郑剑锋(1997-),硕士研究生,从事计算机视觉、文档分析的研究。
通讯作者:刘英莉(1978-),副教授,从事机器学习、自然语言处理的研究,lyl@kust.edu.cn。
引用本文:郑剑锋,张广涛,刘英莉.基于自适应注意力机制的表格结构识别模型[J].化工自动化及仪表,2024,51
(3):449-455.
DOI:10.20030/j.cnki.1000?3932.202403012
摘 要 针对图像中表格结构识别问题,提出了基于自适应注意力机制的编码-解码架构,预测图像中表格的HTML标签。采用轻量化LCNet和CSP?PAN作为特征编码网络,获得全局图像特征;为解码器设计自适应注意力机制,在解码器的每个时间步骤添加语义特征,使模型自主选择关注图像信息或语义特征。另外,为提升研究效率,对训练图片数量与模型准确率之间的关系进行研究,结果表明合适的图像数量在70k~100k之间,实验从公开数据集PubTabNet中随机选择100k图片进行训练,模型的TEDS?Struct分数达到了95.1%。
关键词 表格结构识别 注意力机制 文档智能 深度学习 模式识别 图像描述
中图分类号 TP18 文献标志码 A 文章编号 1000?3932(2024)03?0449?07
文档中的表格通常承载着特定主题的重要信息,将文档图像中的表格解析为机器可读的HTML标签是文档智能分析中的一项具有挑战性的特色任务[1]。表格结构识别的方法多样,许多研究者选择通过编码-解码结构的模型,利用编码器抽取图像特征、解码器生成标签。而表格的HTML标签同时具有视觉性和非视觉性,已有方法只考虑了图像信息,缺乏视觉信息和语义信息的动态融合。
为解决这一问题,笔者在图像的空间注意力基础上,添加自适应注意力模块,为不同标签分配语义注意力权重。另一方面,由于公开数据集数量庞大,为了提高算法研究效率,笔者研究了图片数量与模型准确率之间的关系,以找出最合适的训练集样本数量。
1 相关工作
目前国内外学者提出了很多基于深度学习的表格结构识别方法,大致可分为3类:将表格视作图像使用图神经网络进行处理的方法;将结构识别视作图像领域的定位或分割任务;使用图像描述方法直接从表格图像中预测出代表结构的标签序列。LI Y等将表格的每个文本单元视作图节点,使用K临近算法建图,通过图卷积算法处理每个节点的邻接关系,最终计算出正确的表格结构[2],这类方法的局限在于建图的难度较大且不适合处理复杂表格。将表格的文本单元视为待识别对象进行图像目标的检测也是常见手段,如CascadeTabNet表格检测网络[3],在定位表区域后进一步检测表单元格,进而解析出表格结构;ZHANG T等提出了LRCAANet,在特征提取阶段结合通道注意力机制,成功缩减了模型结构[4]。使用定位、分割方法进行表格结构识别的优点在于对表单元格位置的识别较为准确,使用同一种模型即可完成表格定位和结构识别任务,但这类方法通常需要人为设定后处理规则,用于构建表格单元之间的邻接关系。
笔者采用图像描述的方式进行表格结构识别,结合计算机视觉和自然语言处理技术,直接根据表格图片生成表结构的标签序列,避免冗余的后处理过程,使表结构的抽取过程更加简洁,因此得到了大量关注。XU K等首次将基于注意力机制的编码-解码结构应用于图像描述[5]。DENG Y T等通过在编码阶段添加递归层来捕获水平空间依赖关系,从而将图像中的数学公式转成LATEX格式[6],同样的模型也被用于Table2Latex数据集中,从表格图像中生成LATEX格式的表格。为了促进基于图像和深度学习的表格识别任务的研究,ZHONG X等公开了自动生成的PubTabNet数据集,使用双解码器结构同时进行结构解码和单元内容解码,并提出了新的表格识别任务评价指标——树编辑距离相似度(Tree Edit Distance Based Similarity,TEDS)[7]。PubTabNet与TEDS也分别成为ICDAR2021科研文献分析竞赛[8]的数据集和评价指标。YE J等发布的TableMaster模型是ICDAR2021的解决方案之一,结合了ResNet的残差模块和多头注意力模块构成图像编码部分[9],使用基于Transformer[10]的解码架構组成两个分支分别预测结构和单元格坐标。与之类似的还有LI C等提出的SLANet[11],结合LCNet[12]和CSP?PAN[13]作为编码网络,解码器由单层GRU构成,在循环网络的每个输出节点使用回归网络和结构识别网络分别预测表格结构和单元格坐标,虽然精度与TableMaster相比略微下降,但模型尺寸远小于前者。
受SLANet启发,笔者构建的表格结构模型使用基于长短时记忆网络(Long Short?term Memory,LSTM)[14]的解码器结构,结合自适应注意力机制,使得在每个时间步骤,模型能够选择从图像或语义信息中预测表格结构标签和单元格坐标,最终提高表格结构识别的准确率。
2 表格结构识别
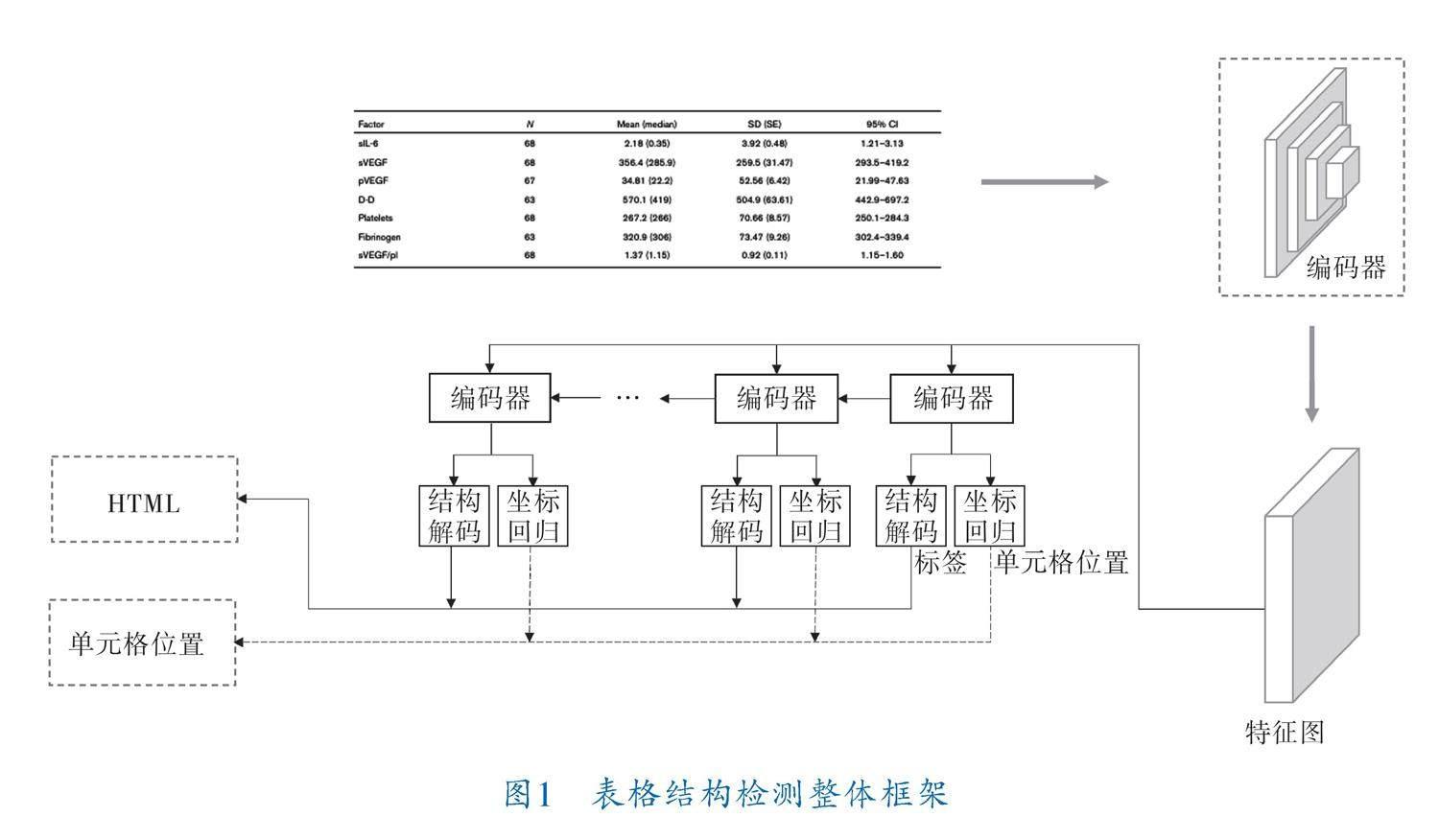
本节详细描述了所提方法的整体结构,模型为编码-解码结构,其中编码器采用基于卷积的深度神经网络,主要用于提取图片特征;解码器主要用于解析表格结构和单元格坐标。整体框架如图1所示。表格图像输入编码器中获得特征图,特征图将送入解码结构进行解码。每个步骤中解码器的输出都将送入结构解码器(Structure Decoder,SD)和单元格坐标回归器(Cell Regression,CR),分别生成结构标签序列和单元格坐标,同一步骤生成的标签和坐标一一对应,拼接所有步骤下生成的标签即为该表格HTML表示。
2.1 编码器结构
编码器主要由骨干网络和颈网络组成,笔者使用轻量级的LCNet作为骨干网络进行特征提取。为了能够融合骨干网络提取的特征,解决尺度变化带来的性能下降,在骨干网络后添加CSP?PAN作为颈网络,在充分融合各层次特征的同时,降低了计算代价。编码器结构如图2所示,其中,LCNet采用DepthSepConv[12]作为基础模块,生成4层不同级别的特征图。CSP?PAN网络则结合了路径聚合网络(Path Aggregation Network,PAN)与局部跨阶(Cross Stage Partial,CSP)模块[13],用于融合不同层次的特征图。
2.2 解码器结构
解码器由基于注意力机制的循环神经网络(Recurrent Neural Networks,RNN)构成,具体包括LSTM、注意力模块和最后的结构解码模块、坐标解码模块(图3)。特征图的长宽维度作为时间序列输入,由递归网络提取序列特性,结构解码器只生成预先定义的表格结构HTML标记,位置编码器负责生成表格单元位置。
图3中,c为注意力1模块产生的上下文向量;[c][^]为注意力2模块最终生成的上下文向量;S为保留了前文语义信息的语义向量;y、l分别为结构解码器和坐标解码器生成的HTML标签类别与单元格坐标;h为该时刻LSTM的隐藏层状态;V为经过编码器处理后的特征图;x为当前步骤下LSTM的输入。
由卷积编码结构生成的特征图V∈Rd×k和LSTM前一时刻的隐藏层状态h可经空间注意模块(图3中注意力1模块)生成当前步骤下特征图k个网格的空间注意力分数α∈Rk,具体公式为:
z=Wtanh(WV+(Wh))(1)
α=softmax(z)(2)
其中,W、W∈Rk×d与Wh∈Rk均为可学习参数。
基于图片的空间注意力分数可以得到仅包含图像特征的图片上下文特征向量c:
c=αv(3)
其中,v表示特征图V的第i个网格的特征值,v∈Rd。
参照LSTM内部机制,可由下式计算得到语义特征向量S:
S=σ(Wx+Wh)☉tanh(m)(4)
其中,W为可学习参数;m为LSTM内部的记忆单元状态。
基于前文所得到的语义向量S和图片上下文特征向量c,通过应用自适应注意力机制(图3中注意力2模块)生成最终的上下文特征向量[c][^],计算式为:
[c][^]=βt St(1-β)c(5)
其中,β为语义注意力分数,其值越高,表示当前时刻模型更加关注语义信息而非图像信息。β由下式计算的[α][^]得到:
[α][^]=softmax([z;W tanh(WS+Wh)])(6)
其中,W为可学习参数;[α][^]∈Rk+1,β=[α][^][k+1]。
两个解码器均由单层全连接神经网络构成,最后的输出y、l可由下式计算得出:
y=W[c][^](7)
l=W[c][^](8)
其中,W为可学习参数。
以上公式单独将LSTM的语义向量分离出来,并赋予注意力机制,使得模型在生成下一个标签类别时,自发地选择关注图像特征或语义特征。
3 实验结果与分析
3.1 实验背景
為了验证笔者所提算法的有效性,在PubTabNet数据集上进行实验。PubTabNet数据集是IBM澳大利亚研究院公开的基于图像的表格识别数据集,包含了568k表格图像以及相应的HTML结构化表示。在PubTabNet中,用“” “
常以准确率作为性能指标来评价表格结构识别算法的好坏。正确的预测结果意味着一张表格内所有结构标签均与真实值相同。在PubTabNet中使用TEDS作为识别结果的度量方法,TEDS能够同时识别结构错误和单元内容错误。笔者着重研究结构识别算法,且单元内容可由不同OCR算法进行识别,考虑到OCR的识别误差可能影响比较结果,因此参照文献[11,15]中的工作,除了准确率外,文中将忽略单元内容,使用TEDS?Struct作为评价方法。
文中使用在ImageNet上预训练的LCNet网络参数进行初始化以加快训练速度。训练过程中,采用Adam优化器,初始学习率设为0.001,并在50次迭代后调整为0.000 1,共进行70次迭代。训练使用一块NVIDIA 3090 GPU,训练批大小设为48。
3.2 训练集样本数量对模型的影响
PubTabNet包含了大量数据集,从经验来看,数据集数量越多,所训练的神经网络性能越好。为了有效使用计算资源,对训练集样本数量与准确率之间的关系进行评估。对原数据集的训练样本进行随机采样,产生6组数量不同的训练集,其样本数量分别为9k、18k、36k、72k、108k、200k,在使用同样卷积的情况下,分别使用了文献[11]与文献[16]的方法进行测试,结果见表1。
神经网络模型性能通常与训练集样本数量呈对数关系,参照文献[17]所使用的建模方法,笔者通过最小二乘估计预测模型的性能,使用ln函数对其进行拟合,拟合曲线如图4虚线所示,拟合函数为y=0.0889ln x+0.8039,其中x为归一化后的训练样本数量,y为模型准确率。根据拟合曲线,当x=0.14时,曲线斜率为0.6,对应训练样本数
量为72k,此时训练集样本数量的增加对模型性能的提升开始变得有限;x从0.2(108k)到0.4(200k)时,准确率的提升约为0.05,在x超过0.4(200k)后,模型性能的提升没有实质性改善。因此,后续的对比实验将在训练集样本数量为108k条件下进行。
3.3 自适应注意力的有效性
笔者对不同注意力机制对解码效果的影响进行了实验,结果见表2,虽然使用LSTM的准确率
较GRU有所下降,但整体而言,结合笔者提出的自适应注意力机制能够提升表结构识别的准确率。
表3展示了笔者所提方法与PubTabNet数据集上一些先进方法的对比,如EDD、LGPMA[18]和SLANet。可以看出,笔者所提方法对SLANet的改进基本保持了模型尺寸大小,但提升了准确率。
3.4 注意力机制可视化分析
为更好地分析解码器中自适应注意力机制的工作原理,笔者对语义注意力分数和图像中的空间注意力分数进行了可视化。
图5展示了各个标签的语义注意力分数,可以发现,所有的“”标签均得到了很高的语义注意力分数。除此之外,由于HTML标签的标记规则,所有表格的“”和“
”之后必定跟随““
“
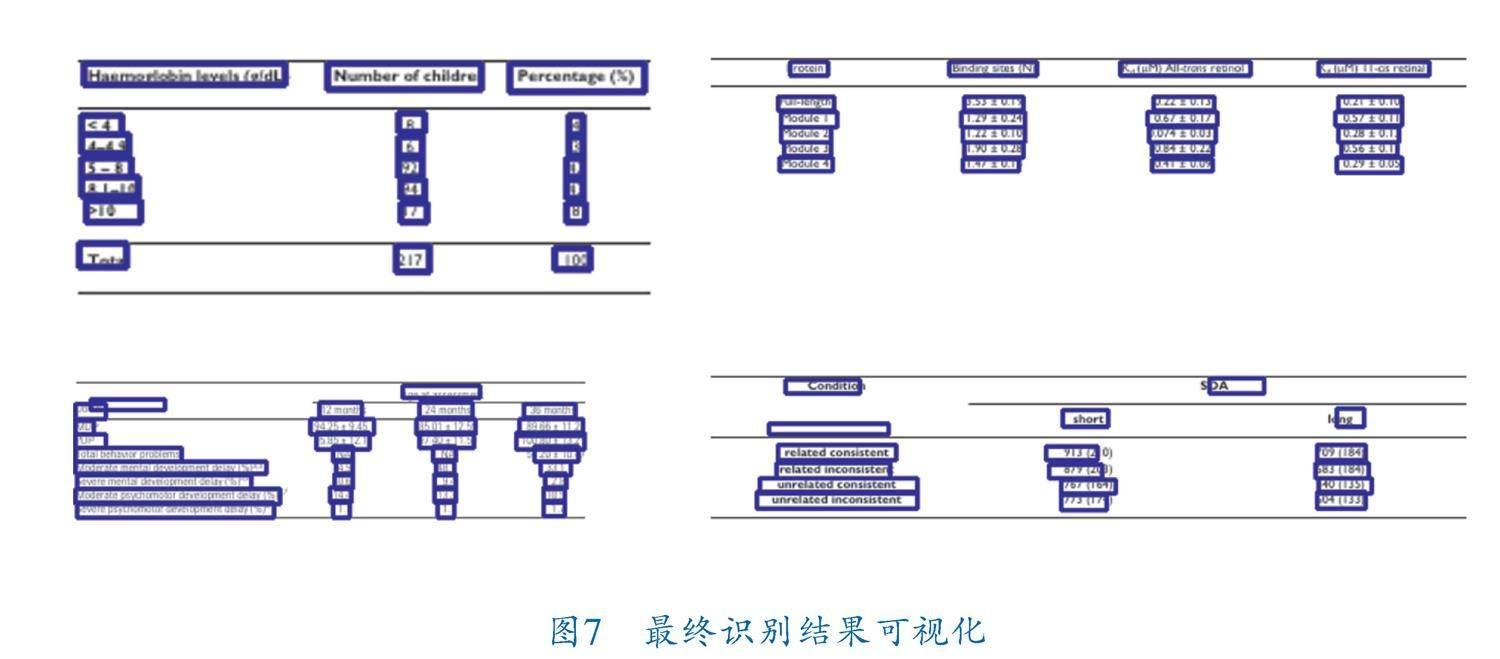
图6展现了在预测不同标签时,图像特征中空间注意力机制对图像各区域的关注程度。仅在预测“”时,空间注意力机制正确分辨出了表头区域。当预测单元格标签“ 模式,没有传达明确的行信息,导致注意力模块始终关注图像特征的局部信息,这也是后续工作中所要解决的问题。 如图7所示,笔者从PubTabNet测试集中抽取了4张表格图片进行了最终的可视化展示。可以看出笔者所提模型能够准确预测表格结构和单元格坐标,虽然第2行图像中,空单元格的坐标偏差较大,但不影响实际应用。 4 结束语 笔者探究了在表格结构识别问题中训练集样本数量对基于RNN预测模型的影响,实验结果表明,模型样本准确率与训练集样本数量呈对数关系,最有性价比的訓练样本数量在70k~100k之间。同时,笔者提出了一种基于LSTM的表格结构识别方法,在应用图像空间注意力机制的同时,拓展LSTM生成语义特征,并添加适应性注意力机制,为结构标签的预测提供语义特征上的选择,使模型能够自主选择需要关注的特征类别,通过实验和可视化结果进一步验证了自适应注意力机制的有效性,与仅使用图像特征的空间注意力相比,自适应注意力机制提升了表格结构预测的准确性。 参 考 文 献 [1] CUI L,XU Y,LYU T,et al.Document AI:Benchmarks,Models and Applications[J].Journal of Chinese Information Processing,2022,36(6):1-19. [2] LI Y,HUANG Z,YAN J,et al.GFTE:Graph?Based Financial Table Extraction[C]//Pattern Recognition ICPR International Workshops and Challenges.Berlin:Springer,2021:644-658. [3] PRASAD D, GADPAL A, KAPADNI K,et al.Cascade? TabNet:An approach for end to end table detection and structure recognition from image?based documents[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE,2020:2439-2447. [4] ZHANG T,SUI Y,WU S Y,et al.Table Structure Recognition Method Based on Lightweight Network and Channel Attention[J].Electronics,2023,12(3):673. [5] XU K,BA J L,KIROS R,et al.Show,Attend and Tell:Neural Image Caption Generation with Visual Attention[C]//Proceedings of the 32nd International Conference on Machine Learning.Stroudsburg PA,USA:Curran Associates Inc.,2015:2048-2057. [6] DENG Y T,KANERVISTO A,LING J,et al.Image?to?Markup Generation with Coarse?to?Fine Attention[C]//Proceedings of the 34th International Conference on Machine Learning.Sydney,NSW,Australia:JMLR.org,2017:980-989. [7] ZHONG X,SHAFIEIBAVANI E,JIMENO YEPES A. Image?Based Table Recognition: Data, Model, and Evaluation[C]//Computer Vision?ECCV 2020.Glasgow,UK:Spring,2020:564-580. [8] YEPES A J, ZHONG P,BURDICK D.ICDAR 2021 Competition on Scientific Literature Parsing[C]//International Conference on Document Analysis and Recognition.Lausanne, Switzerland:IAPR,2021:605-617. [9] YE J,QI X,HE Y,et al.PingAn?VCGroups Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B:Table Recognition to HTML[J/OL].arXiv,2021.https://doi.org/10.48550/arXiv.2105.01848. [10] VASWANI A,SHAZEER N,PARMAR N,et al.Atten? tion is all you need[C]//Proceedings of the 31st International Conference on Neural Information Proc? essing Systems.New York:Curran Associates Inc.,2017: 6000-6010. [11] LI C,GUO R,ZHOU J,et al.PP?StructureV2:A Stron? ger Document Analysis System[J/OL].arXiv,2022.https://doi.org/10.48550/arXiv.2210.05391. [12] CUI C,GAO T,WEI S,et al.PP?LCNet:A Lightweight CPU Convolutional Neural Network[J/OL].arXiv,2021.https://doi.org/10.48550/arXiv.2109.15099. [13] YU G H,CHANG Q Y,LV W Y,et al.PP?PicoDet:A Better Real?Time Object Detector on Mobile Devices [J/OL]. arXiv, 2021. https://doi. org/10.48550/arXiv.2111.00902. [14] GERS F,SCHMIDHUBER J,CUMMINS F.Learning to Forget:Continual Prediction with LSTM[C]//1999 Ninth International Conference on Artificial Neural Networks.Edinburgh,UK:IET,2000:850-855. [15] ZHENG X,BURDICK D,POPA L,et al.Global Table Extractor(GTE):A Framework for Joint Table Identi? fication and Cell Structure Recognition Using Visual Context[C]//2021 IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE,2021:697-706. [16] LU J,XIONG C,PARIKH D,et al.Knowing When to Look:Adaptive Attention via a Visual Sentinel for Image Captioning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2017:3242-3250. [17] SHAHINFAR S,MEEK P,FALZON G.“How many images do I need?” Understanding how sample size per class affects deep learning model performance metrics for balanced designs in autonomous wildlife monitoring[J]. Ecological Informatics, 2020, 57:101085. [18] QIAO L,LI Z,CHENG Z,et al.LGPMA:Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment[C]//Document Analysis and Recognition. Switzerland:ICDAR,2021:99-114. (收稿日期:2023-05-12,修回日期:2024-03-04) Table Structure Recognition Model Based on Adaptive Attention Mechanism ZHENG Jian?feng1,2, ZHANG Guang?tao1,2, LIU Ying?li1,2 (1. Faculty of Information Engineering and Automation, Kunming University of Science and Technology; 2. Yunnan Key Laboratory of Computer Technologies Applications) Abstract Aiming at recognizing table structure in images, an encoder?decoder architecture based on adaptive attention mechanism was proposed to predict tables HTML tags in images. Lightweight LCNet and CSP?PAN were adopted as feature coding networks to obtain global image features. In addition, an adaptive attention mechanism was designed for the decoder, and semantic features were added at each time step of the decoder so that the model can self?select to focus on the image information or semantic features. For purpose of improving research efficiency, the relationship between the number of training images and the accuracy of the model was studied to show that, the appropriate number of images stays between 70k and 100k. Training 100k images randomly selected from the public dataset PubTabNet shows that, the marks of TEDS?Struct of the model can reach 95.1%. Key words table structure recognition, attention mechanism, document AI, deep learning, pattern recognition, image description”时,空间注意力仅能正确关注列区域,但无法分辨表格中各行的差异,注意力机制始终在第1行的空间范围内选择关注区域,笔者认为原因在于表格的HTML标签在不断重复“ … 猜你喜欢
杂志排行
