面向图像文本的多模态处理方法综述
2024-06-01姜丽梅李秉龙
姜丽梅 李秉龙
摘 要:在深度学习领域,解决实际应用问题往往需要结合多种模态信息进行推理和决策,其中视觉和语言信息是交互过程中重要的两种模态。在诸多应用场景中,处理多模态任务往往面临着模型架构组织方式庞杂、训练方法效率低下等问题。综合以上问题,梳理了在图像文本多模态领域近五年的代表性成果。首先,从主流的多模态任务出发,介绍了相关文本和图像多模态数据集以及预训练目标。其次,考虑以Transformer为基础结构的视觉语言模型,结合特征提取方法,从多模态组织架构、跨模态融合方法等角度进行分析,总结比较不同处理策略的共性和差异性。然后从数据输入、结构组件等多角度介绍模型的轻量化方法。最后,对基于图像文本的多模态方法未来的研究方向进行了展望。
关键词:多模态; 架构; 融合; 轻量化
中图分类号:TP18 文献标志码:A 文章编号:1001-3695(2024)05-001-1281-10
doi:10.19734/j.issn.1001-3695.2023.08.0398
Comprehensive review of multimodal processing methods for image-text
Abstract:In the field of deep learning, solving problems often requires combining multiple modal information for reasoning and decision-making, among which visual and language information are two important modalities in the interaction process. In many application scenarios, processing multi-modal tasks often faces problems such as complex model architecture organization and inefficient training methods. Based on the above problems, this paper reviewed the representative achievements in the field of multimodal image text in the past five years. This paper first started from the mainstream multi-modal tasks and introduced related text and image multi-modal datasets and pre-training targets. Secondly, considering the visual language model based on Transformer and the feature extraction method, this paper analyzed from the perspectives of multi-modal organization architecture and cross-modal fusion methods, and summarized and compared the commonalities and differences of different processing strategies. Then it introduced the lightweight method of the model from data input, structural components and other aspects. Finally, it prospected the future research direction of multimodal methods based on image text.
Key words:multimodal; architecture; fusion; lightweight
0 引言
随着互联网规模的逐步扩大,待挖掘的数据信息呈爆炸式增长,传统的机器学习算法无法对大规模复杂数据集进行拟合和运算。另外,随着高性能和计算设备(GPU、TPU等)的换代发展,为深度学习挖掘大规模数据的能力提供了充分的硬件支撑。在多模态分支领域中,模型需要综合处理不同模态的数据,提升深度学习模型接收多模态信息和理解多模态信息的能力,从而进行决策和推理。研究人员提出了一系列的多模态相关任务,如视觉问答(visual question answering)[1]、基于图像的文本描述生成(image captioning)[2]等。针对各项任务,传统的方式多由相关领域的专家手动构建标准数据集再进行训练和评估。目前,深度学习模型大多是按照预训练(pre-training)-微调(fine-tuning)的架构实现。通过在大规模数据集上完成预训练目标来得到一组具有优异迁移能力的权重参数,然后在下游任务中对预训练模型参数进行微调。预训练-微调的架構提供了模型初始化方案,使模型无须对每个新的子任务都重新进行训练,节省了训练资源。因此,这种成熟优秀的模型训练范式也可以很好地应用到多模态任务中。
2017年,Vaswani等人[3]提出了具有编码器-解码器(encoder-decoder)结构的Transformer模型,不仅很好地解决了机器翻译问题,还为自然语言处理和图像处理等领域提供了新的思路和方法。目前,预训练微调方法大多采用Transformer模型为基础模块,其中,GPT[4]以Transformer的解码器为基础模型,通过无监督的学习方法,在没有标签的文本上训练一个比较大的语言模型,在9个下游任务中得到最好的性能表现(state of art,SOTA);ViLT[5]同时将文本和图像的embedding嵌入作为输入,由Transformer的编码器进行模态之间的交互,以Transformer为基础的预训练模型和自监督学习方式的结合,摆脱了模型对于大量标注数据的依赖和下游任务应用的局限性。当前,多模态任务面临着模型架构组织方式庞杂、训练方法效率低下等问题。本文面向图像和文本两种模态,系统地介绍了相关处理技术。首先介绍主流的多模态任务和多模态图像文本数据集,分析重要的预训练目标和方法;其次阐述视觉和文本信息特征各提取方法的优略;接着重点比较多模态架构中对于不同处理模块的设计策略,从单流架构、双流架构以及混合架构来分类阐述,并从融合时期的角度对模态融合方法进一步分析说明;然后从不同角度来分析轻量化构建大模型的思路;最后对多模态模型的研究方向以及发展趋势进行了探讨。
1 多模态任务及相关工作
1.1 视觉问答
视觉问答(visual question answering,VQA)以图像和关于图像开放式的自然语言问题作为输入,以生成一个答案作为输出,简单来说,VQA任务就是对给定的图片作出问答。该任务在实践中有着广泛的应用,如幼儿教育、商品搜索等。Gao等人[6]提出了一种将多模态特征在模态内和模态之间动态融合的框架(dynamic fusion with intra- and inter-modality attention flow,DFAF)。DFAF由Inter-MAF和Intra-MAF组成,该工作采用了Faster R-CNN[7]提取目标图像的视觉特征,门控循环单元(GRU)[8]来提取图像对应问题的文本特征。相较于Transformer,基于卷积的区域特征以及基于LSTM的文本解码器并不能从全局角度对输入信息进行关注,无法捕捉全局的依赖关系,从而无法充分进行跨模态学习。在第4章中将详细介绍不同特征提取方式的优劣。
1.2 图像-文本检索
图像-文本检索(image-text retrieval)就是搜寻配对的图像文本对,图像文本检索任务可以分为图像查询文本和文本查询图像两种。不同模态之间的检索主要是通过对图像-文本数据进行相似度计算来实现,即同时利用单一模态和跨模态之间的联系来挖掘语义关系。现有的大多数图像文本检索方法可以分为两种:a)将整个图像和文本嵌入到共享空间中挖掘语义关系;b)对图像和文本进行单独处理之后进行跨模态融合。目前,多采用第二种方式。ALIGN[9]在超过10亿的有噪声数据集上使用了双编码器结构,将视觉和语言的模态特征在共享嵌入空间中进行对齐,通过对比学习获得了具有迁移能力的模型。区别于对比学习,Ma等人[10]充分利用了图像和文本信息不同层级的匹配关系,使模型可以学习图像与单詞、短语以及句子三个层级的文本信息之间的模态匹配关系。但双编码器的特征处理结构耗时更长,因此ViLT[5]将视觉特征和文本特征拼接,即将完整的图像文本对嵌入到共享空间中,采用注意力机制进行跨模态处理,极大地简化了网络结构。
1.3 图像字幕
图像字幕(image captioning)任务是对目标图像生成相关内容的文本描述,该任务的一个重要下游应用是以图像生成字幕获得低噪声的图像文本数据集。受机器翻译任务的启发,编码器-解码器的架构也可以用来解决图像字幕任务。Vinyals等人[11]通过CNN提取图像特征后,使用LSTM结构将其解码为字幕,但LSTM无法并行处理数据的特点导致其不能很好地用于大数据背景下的预训练学习。Huang等人[12]提出了attention on attention(AoA)模块,该模块扩展了传统的注意力机制,在并行计算与全局注意力机制的基础上进一步挖掘了注意力计算结果与查询之间的关系。Pan等人[13]引入了双线池化来改进传统一阶交互的注意力机制,即X-linear attention,从而实现了高阶特征交互。BLIP[14]综合以上工作提出一种多模态编码器-解码器混合模型,该结构可以有效地应用于多任务预训练,其文本解码器作为字幕生成器,使用语言模型预测目标(language modeling)来进行预训练;文本编码器用于去除图像-文本数据集中噪声(不匹配图像文本对),实验结果在COCO以及Nocaps的表现均达到了SOTA。
1.4 视觉-语言导航
Anderson等人[15]首次提出了视觉-语言导航(vision-and-language navigation,VLN)任务,并公开了基于真实环境的room-to-room数据集。视觉-语言导航任务要求智能体根据给定的自然语言指令在3D模拟环境中导航到目标位置,其大多被定义为一个文本到图像的顺序问题:位于预定义连接图上的特定节点处,智能体通过选择图像表示和指令之间具有最大对应关系的相邻节点来遍历环境。因此,图像文本匹配被认为是解决导航任务的关键。VLN-BERT方法[16]通过预测指令和视觉轨迹的兼容性来进行预训练;Air-BERT方法[17]在室内图像-文本对数据集上训练路径和指令的匹配任务,提出了从指令或者视觉观察中挖掘时间信息对于预测智能体的动作很重要;HOP[18]提出了历史感知代理任务和指令感知代理任务来帮助智能体理解历史内容和时间顺序以作出行为预测。大多数的VLN工作都集中在离散或者连续的环境当中,连续的空间导航更接近于真实世界,但是训练的成本要远超离散空间中的训练成本,然而离散空间的训练也很难转换到连续的导航任务中。Hong等人[19]为了弥补连续环境到离散环境的差距,提出了在导航过程中使用候选路径点将智能体转移到连续环境中进行训练的思想,实验结果表明该工作极大地降低了离散到连续的差距,在R2R-CE和RxR-CE数据集上达到了SOTA。
其余相关多模态任务如表1所示。
2 多模态数据集
多模态视觉语言任务是一个具有极大潜力的发展方向。VLP大模型常常具有数据饥饿(data-thirst)的特性,即当模型具有大量的可学习参数和网络架构层数,往往模型的性能和喂入的数据量成正相关趋势,因此相关研究人员和学术组织为特定任务收集生成了大量的训练数据。主要的图像文本多模态任务的数据集如表2所示[1,25~36]。
伊利诺伊大学厄巴纳香槟分校计算机系研究团队认识到,来自于Web的图像文本对数据,其中文本的描述可能与图像并不匹配,甚至完全区别于人类所能从图像中得到的信息,这种具有严重噪声的图像-文本数据会影响模型正确的学习能力和下游的泛化能力[25]。该团队通过使用AmazonsMechanical Turk(MTurk) 来进行标注,而对MTurk标注任务前的资格测试可保证数据集的质量。参与标注的MTurk大多为非专业人员,也保持了相应字幕内容的丰富性。
Open Images V4[33]用于图像分类、对象检测、视觉关系等任务,该数据集拥有9 178 275张图像,每张图像具有包含多个对象的复杂场景。Open Images V7[36]提出了一种可以扩展到数千个类的语义分割注释策略:从给定的图像级别标签开始,注释者只回答由计算机模型自动生成的对每像素点的二值问题,从而更加高效地将分割注释扩展到了更多的类。
VQA v1.0 [1]收集了MS COCO數据集中包含多个对象和丰富上下文信息的图像,为了扩充VQA数据集对于高级推理的需求,创建了一个包含50 000种场景的抽象场景数据集,并且为每个场景都收集了5个标题。VQA中的视觉问题有选择地针对图像的不同区域,包括背景细节和潜在背景,通过提供准确的自然语言答案来反映真实世界的场景。Goyal等人[31]提出数据集的固有结构和语言中的偏见会导致模型忽略视觉信息,因此在VQA v2.0中通过收集互补图像来平衡VQA数据集,从而使新数据集中的每个问题不仅与单个图像相关,还与一对相似的图像相关,使得问题拥有两个不同答案。
Conceptual 12M(CC12M)[35]是一个具有1 200万图像文本对的数据集,专门用于视觉语言预训练,CC12是由CC3M[37]进一步扩大而来。CC3M的构建使用基于图像、基于文本和基于文本图像三种基本的过滤类型,CC12M保留图像文本过滤器,通过调整图像过滤器和文本过滤器来达到CC12M的数据规模。
3 多模态预训练目标
预训练目标的选择对整个训练过程的成本以及最终模型的性能有着决定性的作用,以下将对匹配式预训练目标(3.2节)和生成式预训练目标(3.3~3.5节)两类预训练目标进行阐述。
3.1 图像文本对比学习
在预训练阶段,图像-文本对比学习(image-text contrastive learning,ITC)[38]用于学习图像和文本在特征空间中更好的表示方式。对比学习将匹配的图像文本看作正样本对,不匹配的图像文本看作负样本对,使用余弦相似度来计算图像特征和文本特征之间的相似度,即不断优化正样本之间的相似度,减小负样本对之间的相似度,从而使得模型可以理解不同模态之间的共性和差异性,在特征空间中可以很好地匹配文字和图像特征。图像-文本对比学习的方式可以应用于多模态检索类型的下游任务。本文将从一个批量的图像文本对来介绍对比学习的具体实现方式。
利用式(1)(2)计算图像文本正样本对之间的softmax归一化相似度,得到式(3)(4)。
其中:σ为温度参数;pi2ti表示图像到文本的第i个正样本的相似度;pt2ii表示文本到图像的第i个正样本对的相似度。
通过训练交叉熵损失H来最大化正样本对之间的相似度以训练模型,得到最终的期望结果如式(5)所示。
其中:D为预训练数据集;yi2t、yt2i分别表示文本图像ground-truth的独热相似度向量,相似度最高的图像文本对概率为1,其余为0。
3.2 图像文本匹配
图像文本匹配(image-text matching,ITM)[39]可以看作是二分类问题,其主要目标是为了预测图像和文本是否匹配。ITM可以让模型学习视觉和语言模态之间的细粒度对齐。通常将图像特征与文本经过模态融合处理后得到的跨模态Token [CLS]通过一个全连接层和softmax层来得到二分类的结果,其输出结果用pi2m(I,T)表示,通过训练交叉熵函数H得到损失公式为
Litm=E(I,T)~D[H(yi2m,pi2m(I,T))](6)
其中:yi2m为ground-truth标签的独热向量;D为预训练数据集。
在实际的训练过程当中,部分负样本同样具有相近的语义信息,只在细粒度上的细节有所不同,也可以理解成最接近正样本的负样本,称为难负样本(hard negatives)。ALBEF[40]进行ITM训练时,通过计算图像文本之间的相似度来寻找每个批次中的难负样本,这样就能提升模型理解不同模态信息的能力。
3.3 遮罩语言模型预测
其中:ymsk为词分布的独热向量,代表ground-truth的Token概率为1,其余Token的概率为0;D为预训练数据。MLM在大规模的语料库中可以高效地从上下文来提取文本中的语义信息,使用MLM预训练的文本特征提取器可以很好地进行不同子任务的迁移,MLM无须任何标签和额外的标注信息,是一种自监督的学习方式,降低了数据采集和标注的成本。因此,MLM在很多工作中[42~44]都起到了很好的预训练效果。
3.4 语言模型预测
与VLP中广泛使用的MLM损失相比,LM预训练目标使模型泛化能力得到了进一步的增强。LM在stable diffusion[45]中也得到了应用,BLIP[14]中文本解码器的训练同样采用LM预训练目标,Laion COCO 600 million数据集的团队也采用了该bootstrapping方法构建数据集。
3.5 遮罩数据模型预测
遮罩数据模型预测(masked data modeling,MDM)将文本和图像都看作是统一模态的数据,同时对单模态图像和文本,以及多模态图像文本对进行遮蔽操作,即在预训练期间随机地遮蔽掉文本Tokens和图像patches,通过预测遮蔽部分来训练模型。MDM的训练方式不仅可以学习到单模态的特征表达和映射,加入masked image还能使模型在预训练阶段额外学习到不同模态之间的对齐和联合语义。BEiT v3[46]改进BEiT[47],将图像、文本、图像文本对不同模态进行统一的遮蔽与预测恢复,从而利用自监督的学习方式来恢复遮蔽Tokens。在VL-BEiT[48]中,分别采取遮罩语言模型预测、遮罩图像模型预测以及遮罩视觉语言模型预测三种预训练目标,统一了不同模态之间的预训练方式,也证明了生成式预训练目标的良好效果。
4 特征提取方法
4.1 图像特征提取
4.1.1 基于目标检测器的区域特征
图文检索、视觉问答、视觉蕴涵等任务与图像的区域性特征有很高的相关性,大多数的VLP模型将图像区域性特征的提取设置为视觉嵌入系统(visual embedding schema)的基本工作[49],采用目标检测系统得到具有语义和离散化的特征表现形式。VL-BERT[50]、UNITER[51]等相关工作在进行图像体征提取时,基于目标检测得到离散、序列化的具有bounding box的区域特征。例如:YOLO[52]使用检测头和非极大值抑制算法,从图像中提取出目标物体的位置和类别信息;Faster R-CNN[7]使用区域候选网络(region proposal network,RPN)来生成候选目标区域。在实验过程中,为了提升训练效率,区域特征通常在训练时预先缓存,尽管使用目标检测器可用于检测精度要求较高的场景,但由于提前缓存的局限性,无法实现子任务的灵活泛化。
4.1.2 基于卷积的网格特征
目标检测器模块给VLP任务造成了高昂的计算成本,提取基于卷积的网格特征能够减少计算量。网格卷积网络(grid convolutional neural network,Grid-CNN)[53]的核心思想是将图像划分为多个网格,然后对每个网格进行特征提取,从而得到整张图像的特征表示。Grid-CNN通常采用多层网格卷积和池化操作,逐层提取细粒度的局部特征,然后通过全局特征的融合实现对整张图像的分类。Pixel-BERT[54]选择直接将图像像素与文本对齐,其关注点不再局限于目标检测器得到的区域特征,而更注重于更为全面的图形形状和空间关系信息,充分利用了原始图像的视觉信息。注意力机制和图像卷积操作的结合也是较为热门的研究方向:residual attention network[55]将注意力机制和残差网络进行结合,提高了网络对于图像中目标物体的关注;NLNet[56]结合了卷积神经网络和自注意力机制,通过学习不同特征图的权重,从而自适应地选择最相关的特征图。
使用卷积网络来提取特征,虽然在一定程度上减轻了使用检测器提取区域特征带来的负担,但卷积网络的计算复杂度同样不能作为轻量强大的视觉编码器去使用。
4.1.3 基于Vi-Transformer的图像patch特征提取
2020年,Dosovitskiy等人[57]基于BERT提出了Vi-Transformer,直接将原大小为224×224的三通道图片处理为规格为16×16×3的patch块,经过线性映射(linear projection)层便得到了图像Token序列,添加位置编码等辅助Token就可以得到图像patch特征。
Vi-Transformer简化了视觉特征的提取过程。VLP模型受Vi-Transformer工作启发,也采用了类似的方法将图像扁平化成patch序列,仅仅采用嵌入层的映射处理,从而减少了卷积操作和特征提取器的操作开销,大大提升了模型在图像处理的运行时间。Vi-Transformer利用自注意力机制进行全局的建模,可以更好地捕捉目标图像中不同像素的长程依赖关系。但是传统Vi-Transformer的设计与实现都是基于固定大小的图像块进行的,Swing Transformer[58]采取了移动窗口实现了层级式的Transformer处理,从而可以处理不同尺度的图像。相比于Vi-Transformer窗口内的信息交互,由于引入了窗口之间的patch交互,增加了每个图像patch的感受野,一定程度上避免了信息的丢失。DeiT[59]、LeVi-Transformer[60]都基于Vi-Transformer进行了改进,提升了模型在数据集上的表现。
4.2 文本特征提取
4.2.1 基于CNN的文本特征提取
卷积神经网络除了在图像处理工作中被广泛使用,在自然语言处理领域也有着出色表现。Kim等人训练了一个精简的CNN,由无监督神经语言模型得到词向量矩阵后,使用卷积核对该矩阵进行卷积操作,从而得到文本特征图[59]。基于卷积的文本特征提取方法可以很好地处理文本中的局部信息,也可以使用多个卷积核得到不同尺度的特征,并且卷积模型的结构相对简单,容易进行训练。但是卷积操作无法处理文本中的序列信息,可能会造成文本的语义丢失,并且全局最大池化操作也存在长文本信息丢失的问题。
4.2.2 基于RNN的文本特征提取
循环神经网络(recurrent neural network,RNN)常用于处理序列文本数据,即结合历史信息对当前的输入进行处理,但传统的RNN具有梯度消失和梯度爆炸的问题[61],因此模型处理较长序列的文本数据会有很大限制。为了解决以上问题,提出了很多变体RNN。长短期记忆网络有效解决了RNN在反向传播的过程中梯度消失和爆炸的问题,能更加高效地处理长序列文本数据。Bi-LSTM[62]是长短期记忆网络的进一步变体,其从两个方向来处理文本数据,可以更好地理解上下文的信息。
SSAE工作将注意力机制和Bi-LSTM结合,将文本输入经过Bi-LSTM进行双向运算,在每个词的两个方向均进行注意力得分运算,从而得到特征表示[63]。文献[64~66]均将注意力机制引入文本特征提取过程中。
4.2.3 基于BERT的文本embedding向量
BERT是基于Transformer的双向编码器预训练模型,BERT将特殊的Token [CLS]和[SEP]分别作为输入文本对(也可以将单个句子作为输入)的特征表示和分割结束符。BERT通过对输入文本进行词嵌入操作、分句编码和位置编码,以此来得到词序列[41]。预训练过程中,通过遮罩语言模型预测、next sentence prediction(NSP)兩种预训练目标进行无监督训练。MLM随机遮盖或替换一句话里面的任意字或词,然后让模型通过上下文预测被遮盖或替换的部分;NSP任务判断这两个句子是否是连续的,并且在判断时需要考虑上下文信息。这两个任务的联合训练可以充分地提取文本特征,从而提升下游任务的性能。RoBERTa[67]通过改进BERT模型的细节,如数据清洗、学习率调度等因素来提升模型的性能。基于BERT预训练模型设计多模态任务中文本编码器可以减少训练时间和数据需求,有效捕捉上下文之间的依赖关系,进一步提升模态内和模态之间的理解能力。
5 多模态架构比重策略
将图像文本多模态架构抽象为三个组成部分,即文本嵌入模块(textual embed,TE)、视觉嵌入模块(visual embed,VE)、模态融合模块(modality interaction,MI)。其中TE处理文本模态信息,VE处理图像模态信息,MI负责不同模态间的交互。如图1所示,不同模块在整体架构的不同比重体现了该模块在整体架构中的模型参数量和训练成本,下文以及图1中的“>”表示模块具有更高的参数量和更加复杂的结构。因此,根据不同的比重分布来介绍以下四种多模态融合策略。
5.1 VE>TE>MI
如图1(a)所示,在VSE++[68]模型中,VE使用预训练好的CNN模型,TE直接使用预训练的词嵌入模型将文本序列转换为文本特征,在VSE++使用了难负样本的训练技巧来增强视觉语义嵌入模型(VSE)的鲁棒性,MI模块使用余弦相似度计算损失函数,即简单的直接点积计算来实现。类似的多模态结构策略工作还有Unicoder-VL[69]、stacked cross attention for image-text matching(SCAN) [70]等,都使用较为鲁棒的视觉嵌入模块来组织多模态架构。
在多模态任务中,突出视觉嵌入模块可以更好地利用视觉信息,但由于视觉模块自身的复杂性,使得多模态任务计算需要较长的训练时间和更加高昂的计算成本。此外,由于忽略了视觉信息以及模态之间的交互,导致在场景文本理解类的下游任务中表现不佳。
5.2 VE=TE>MI
如图1(b)所示,CLIP[71]模型采用了相同比重的TE和VE模块。模型的输入是一组配对的文本对,分别通过TE和VE得到图像特征和文本特征,MI模块采用较为简单的对比学习的方式,最大化正样本对的相似度以及最小化负样本对的相似度。相较于模态MI计算相似性来进行跨模态对齐,TE和VE都采用了较鲁棒的特征提取器。CLIP模型将图像特征和文本特征映射到统一特征空间来计算相似性得分,使得该模型在图文检索任务上有着很好的表现,但是模型的泛化能力相对较差,同时直接迁移到新任务也存在着性能表现较差的问题。
类似地,ALIGN[9]采用了视觉语言双编码器架构,使用超过10亿张图像替代文本对的噪声数据集,其中将BERT-Large[41]和EfficientNet-L2[72]分别作为文本和图像编码器,图像和文本编码器通过对比损失函数进行权重的更新,使得特征嵌入空间中正样本对具有相似的嵌入表征。图1(a)的架构策略中,图像和文本编码器有着较为复杂的参数和结构,这需要大量的计算资源,并且简单的模态交互无法充分地学习到不同模态之间的共性和差异性。在有限的训练资源限制下,“头重脚轻”的结构,即单一高性能单模态嵌入器与简单的模态融合并不足以学习复杂的视觉和语言任务,往往无法很好地达到预期性能。
5.3 VE>MI>TE
MI对模态信息交互和理解有着举足轻重的作用,是下游任务性能和模型泛化能力提升的重要因素之一。区别于图1(a)(b)两种浅交互的模型架构,ALBEF采用了BERT前六层Transformer结构作为TE,后六层作为MI,在适当降低TE的比重的同时VE采用Vi-Transformer[57],综合权衡模型的复杂度,提升多模态的任务性能,并在各种下游任务上证明了ALBEF的有效性,包含图像文本检索、视觉问答、视觉推理、视觉蕴涵等任务[40]。VL-BERT[50]从预训练的对象检测网络中提取边界框及其视觉特征来生成图像区域特征,文本表征采用BERT方法,通过扩展BERT来联合表示图像和文本进行跨模态的交互。LXMERT[73]对图像区域特征和文本嵌入进行自注意力编码,其MI使用双向交互模块来融合文本和图像的信息,在双向交互过程中,文本注意力机制将图像特征投影到文本空间中,用于计算文本-图像的相似度,而视觉注意力机制则将文本特征投影到图像空间中,用于计算图像-文本的相似度,从而更好地捕捉多模态输入之间的关联信息。
由上述分析可知,在多模态任务中,MI模块是提升下游任务性能的重要因素,无论是生成式的任务还是理解式的任务,都需要以模态特征之间的对齐和充分融合为前提。
5.4 MI>VE=TE
正如以上工作中,大多数多模态框架对于文本的处理多是通过一个嵌入层直接映射到特征空间,图像的处理往往会先使用一个Backbone网络进行特征提取。注意力机制在NLP和CV领域的突破,BERT和Vi-Transformer使得文本和视觉模态信息的处理有了较为统一的方式,在ViLT模型中,对文本和视觉模态的信息均使用线性嵌入层将模态信息映射到特征空间中的方法,直接将图文特征进行拼接送入注意力层进行模态的交互和理解。MI>VE=TE的架构设计简化了模型的结构,提升了文本嵌入的性能,并且相对鲁棒的MI模块也保证了对于模态信息的理解,该模型也首次在多模态的学习中采用了数据增强的方式[5]。ViLT是一个相当轻量级的VLP模型,该模型舍弃了庞大复杂的视觉和文本编码器,将多模态任务的工作重心更多地关注于MI模块,在COCO、Flickr 30K以及Visual Genome等数据集上均取得了SOTA,也证明了简化特征提取工作的有效性,使用精简的网络结构实现高效的模态融合处理是可行的研究思路。
6 多模态交互架构
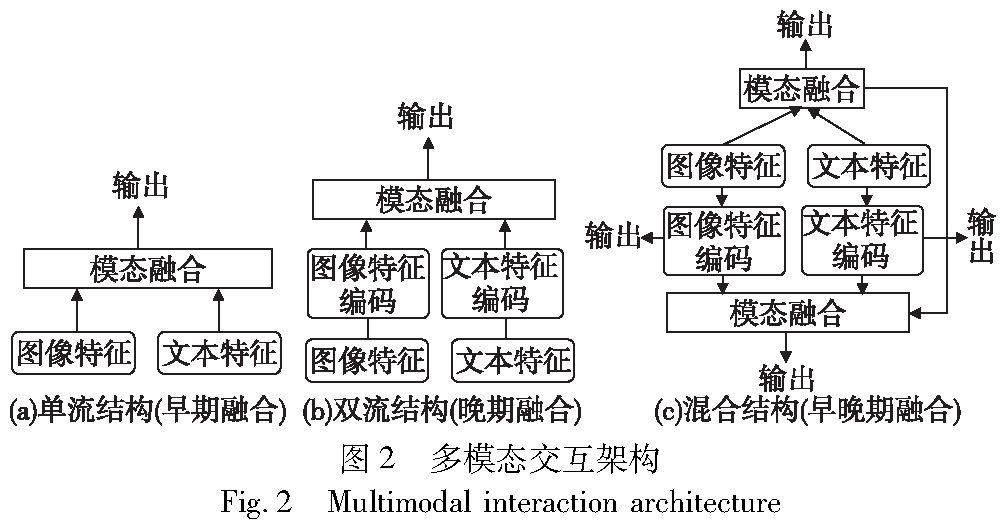
6.1 单流结构
单流模型是指将多个模态的输入通过一个共享的网络模型进行编码,能够同时处理多种形式的输入,并且学习不同模态之间的交互信息,如图2(a)所示。单流结构对于模态之間的潜在关系进行了较为简单的假设。MMBT模型 [74]将图像和文本的特征直接输入到共享模型参数的bidirectional Transformer网络中,并没有在模态融合之前进行单模态的模态内处理。Unicoder-VL[69]将文本嵌入层和视觉嵌入层输出的图像embedding和文本embedding进行拼接,由基于Transformer的交互模块进行跨模态处理。单流结构虽然可以充分地将多模态信息融合进行推理分类,但缺失了模态对齐的操作,因而不适合进行检索任务[5]。
单流模型还可结合早期融合的角度来分析,不同的模态通常是在全局的层级进行融合,此融合方式可以充分考虑模态之间的关联性,但也忽略了模态内部的细节信息。在一些多模态的应用场景中,一些下游任务需要更好地从模态内部理解直接出发,例如图文检索、视觉推理等。因此,尽管早期融合的方法可以高效地进行特征的联合学习,但是模态内部预处理的不足可能导致后续跨模态学习时出现信息丢失。OSCAR[75]对VLP任务中的图像文本对表示为[输入信息Token,对象标签,区域特征],经过嵌入操作后由multi-layers Transformers模块进行模态交互。该工作改进了传统的单流结构的输入,添加了物体标签,丰富了公共嵌入空间的语义信息,提高了模型的迁移性,在一定程度上解决了模型早期融合时对模态内部理解不充分的问题。
6.2 双流结构
双流模型通常具有两个独立的数据处理模块,在不同模态进行融合交互之前进行模态内学习,如图2(b)所示。例如CLIP模型中,文本编码器采用了GPT-2[76]中的12层的Transformer块,视觉编码器采用5个ResNet块和3层的Vi-Transformer块;ALBEF模型同样采用了两个独立的图文编码器进行特征的提取,特征在送入交叉注意力层之前进行了基于MoCo[38]的对比学习,将图像和文本特征进行对齐,目的是提高特征空间中匹配的正样本对的相关度,降低负样本的相关性。相较于单流结构,双流结构中每个模态都有相应的组件进行特征提取,能够充分地捕捉模态内部的特征和细节,并且针对不同模态的数据类型可以有不同的处理方式,可以关注到不同模态之间的差异性,因此雙流结构的模型可以很好地完成检索型任务。然而,引入单模态处理过程也会消耗更多计算资源,训练时间也会变长,并且对不同结构处理后的模态特征进行对齐和融合也是具有挑战性的任务。Miyawaki等人[77]提出了一种改进双流结构的思路,在图像特征编码器中引入了光学字符识别(OCR)系统,将Faster R-CNN从图像中提取的特征与OCR系统提取的图像场景文本进行联合解释。实验表明,联合场景文本和语义表示提高了双编码器的检索性能。因此在双编码器的结构基础上,可以通过添加对应的辅助信息来帮助模型编码输入信息,从而更好地理解模态之间的联合语义信息。
晚期融合的思路与双流结构基本一致,对两个模态特征进行全局的融合计算之前会分别对图像特征和文本特征进行学习,更加关注于从单模态内部得到更加丰富的原始信息和模态特征。晚期融合结构可以在视觉和文本模态融合之前进行充分的特征提取和理解。HERO[78]使用了cross-modal Transformer结构对文本嵌入和视觉序列进行特征处理,然后由共享的temporal Transformer进行模态交互,实现了视觉特征和文本特征的有效对齐和交互。实验结果证明了可以在牺牲部分训练资源和时间的基础上,学习模态内部的信息再进行模态融合能够很好地完成视觉问答、字幕生成、图文检索等任务。
6.3 单双流混合结构
从上文的分析中可以得出,双流结构适合用来完成检索类任务,单流结构在推理任务中表现出色。为了提升模型的普适性和泛化性,单双流混合结构的思想在VLMo[79]得到了实现。VLMo模型是基于一种混合专家网络(MOME)实现的。该模型改进了Transformer块中的前向神经网络,该网络被替换为了视觉专家、语言专家和视觉语言专家三个模态专家网络,模型根据不同的输入选择对应的专家网络。当处理检索任务时,则采用模型中的双流架构,分别得到图像和视觉的嵌入结果,计算两者的相似性得分来完成检索任务;当处理推理等分类任务时,则使用视觉专家和语言专家来编码各自的模态向量,然后由融合编码器进行模态交互。总的来说,模态混合专家(MOME)基于一个特定模态的专家池和共享的self-attention层,灵活地对不同的输入作出不同的处理,可以很好地完成检索任务和推理任务。
同样地,也可以用早晚期融合的角度来分析单双流融合结构,根据下游任务和输入模态的特殊性,融合方案能灵活地选择模态内处理和模态间融合的前向路径和网络模块,如图2(c)所示。综合早期和晚期的优点的同时,也不可避免地带来了模型结构太过复杂、预训练模型难以训练的问题。因此,可以根据具体的任务进行结构选择。
7 轻量化参数微调方法
随着基于Transformer的大语言模型以及视觉处理模型等研究的不断发展,为解决多模态任务提供了诸多具有强大性能且开箱即用的预训练模型,如Visual ChatGPT[80]将ChatGPT(InstructGPT[81])与不同的视觉模型进行结合,使得用户与ChatGPT之间不单使用语言来进行交流,进而可以提供复杂的视觉问题或视觉编辑指令。但随着模型越来越大,在常规的硬件设备上实现对大模型的微调变得极为昂贵和耗时。在大模型盛行的趋势下,如何利用这些庞大参数量的模块泛化到一般的实验或应用场景当中是一个值得研究的问题。参数效率微调(parameter-efficient fine-tuning,PEFT)旨在减少需要微调的模型参数的同时避免灾难性遗忘问题的出现。本章将从Adapters组件、提示符学习(prompting learning)以及专家集合模型(Prismer)三种方法来展开讨论。
7.1 Adapter组件
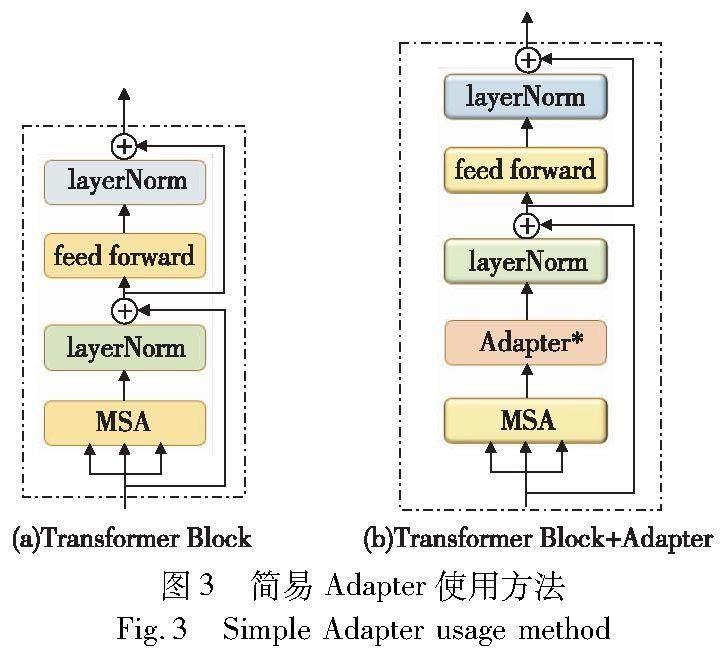
使用大规模预训练模型初始化模型参数是一种比较高效的迁移方法,但在迁移过程中对模型进行微调往往需要更新模型的所有参数,这需要相当庞大的计算资源和时间成本。因此,提出了冻结大部分模型,只更新少量模型参数的方法。因为不同下游任务往往关注于相同模型的不同部分,设计具有泛化性的局部参数微调方法很难实现,并且更新预训练模型的部分参数也可能导致精度的消失以及灾难性遗忘的问题。所以,Houlsby等人[82]提出了Adapter结构,将其作为训练模块插入到Transformer中。图3为一种简易的组件微调方法,冻结Transformer的网络参数,在多头注意力层之后添加可训练的Adapter组件,这样既保留了原始模型的参数内容,又能够以极小的训练代价将大模型的能力泛化到子任务当中。
Adapter有着清晰简单的结构,其输入首先会通过前向下采样映射进行输入特征维度的下采样操作,再通过非线性层和前向上采样映射将特征恢复到输入维度,最终通过跳跃连接将Adapter的原始输入与输出相加作为最终的输出结构。AIM[83]通过冻结预训练好的图像模型,在模型中添加轻量级的Adapter使得模型可以通过更少的可调参数来获得更好的性能,其简单高效的改进能够普遍适用不同的图像预训练模型,以进一步应用到多模态的图像特征处理阶段。
7.2 提示符学习
除了添加可训练的轻量化组件,也可以从信息的输入端来驱动优化模型。例如以提示符学习的方式来提升模型的性能,CLIP[70]在文本编码器处理文本信息之前会添加文字提示(prompt)。即当图像标签的文本为“dog”,则会被处理为“a photo of {dog (object)}”,再对应图像特征进行对齐操作。但每张图片可能有多种描述,如“a photo of a {object}”“a type of {object}”等,以上在预训练过程中被固定好的提示符被称为hard-prompt。但在研究CoOP[84]中,作者发现不同的提示符对最终的实验效果有着不可忽视的影响,因而提出了将文本提示符设置为可学习可优化的一组参数,将其成为软提示符学习方式(soft-prompt)。
如图4所示,提出了两种提示符学习思路:一是统一上下文学习,二是特定于预测类的上下文学习。统一上下文学习为所有的类共享相同的learnable context,也就是对某个子任务数据集只训练一个固定的提示符;特定于预测类的上下文学习对数据集中每一个类都会训练一个不同的learnable context。最终实验结果表明,CoOP的性能都超过了作为基线模型的CLIP,并且作者还实验了{object}在输入中的位置,发现在句中或句尾都具有较为平衡的性能,不同的语句结构顺序并不会对实验结果造成太大的影响。
这种在输入端的处理技巧很好地提供了优化学习参数的思路,仅通过设置很轻量的可训练模块便强有力地将大模型作为基础模型来应用,既保持了其原有性能,又可以通过轻量化可训练模块进一步提升性能,同时可以防止灾难性遗忘问题的出现。
7.3 专家集合模型
Adapter组件在较为简单的工作场景中可以起到很好的优化效果,但其简单的结构属性并不能实现集合复杂的预训练模型。在此基础上,为了实现在更复杂场景下对大模型的有力串联和组合使用,需要提出更高层级的网络组件。Liu等人[85]引入Prismer网络来集成预训练领域的专家模型,即通过单独的子网络来学习技能和领域知识,并且每个专家都可以针对特定的任务进行独立优化。相较于大多单双流模型使用多个预训练目标进行训练,Prismer 只需要一个单一的自回归预测文本作为训练目标,仅专注于微调性能和参数效率。这种方法可以充分利用预训练专家网络,将可训练参数的数量保持在最低限度,在保持专家模块完整性的同时防止微调过程中出现灾难性遗忘问题。
Prismer主要由两个可训练组件构成,专家重采样器在视觉编码器中用于将可变长度的多模态信号映射到具有固定长度的多模态特征序列;轻量级适配器增强了模型的视觉语言推理表达能力。适配器被插入到模型的视觉和语言部分的每个Transformer层中,使预先训练的专家模块适应新的任务和模式。区别于VLMo以及ALBEF混合专家(MoME)结构,在Prismer中,“专家”是独立预训练的模型。这种通过设计一个轻量模块来串联强大预训练模型的思路为实验资源有限的研究提供了强有力的方向指导。ClipCap[86]引入一个映射网络,将CLIP的视觉编码器提取的图像特征通过映射网络得到了與GPT-2的解码器相同的嵌入Token序列,无须额外对编码器和解码器作训练,很好地利用了在上亿文本对训练的预训练模型,该方法仅使用GTX1080训练72 h就能超过基线模型(VLP[87])在V100训练1 200 h的表现效果。
8 多模态领域发展趋势
在VLP领域,根据下游任务构建模型结构、设置预训练目标、构建子任务数据集进行微调等步骤都是研究人员需要思考的重要问题。综上所述,模型的结构与下游任务有着强关联性,单双流的结构决定了模型主要用于进行检索或推理任务,解码器或编码器的选择取决于解决理解式或生成式任务;除了模型结构的设计,公开数据集与任务适配度低、构建下游专用任务数据集困难都是在处理多模态任务时难以解决的问题;在训练过程中,往往设定多个预训练目标进行联合使用,这在大参数的架构中会消耗难以估量的计算成本。因此,多模态任务还面临着很多亟待解决的问题[88]。
综上,在明确解决子任务和搭建模型结构的研究过程中,多模态领域的工作呈现了趋向统一的发展态势,包含且不局限于多模态。对于单模态的自然语言处理、计算机视觉领域等模型都可以从三个方面进行分析:一是以Transformers为基本模块的网络的构建方式;二是生成式的预训练目标在预训练-微调的范式中成为至关重要的参数更新方法;三是大模型大数据释放了模型的能力的同时,高效的组件方法降低了实验成本。
a)模型架构的统一是大一统的重要基础,双流结构适用于检索类的任务;单流结构在完成分类推理等任务具有优势;基于编码器-解码器结构的模型可以用于生成任务。在之前的工作中,大多数模型必须根据特定的任务特性手动调整不同模型结构,并且也无法做到高效地共享模型参数。BLIP[14]对于不同的任务共享部分参数,采用多路Transformer作为骨干网络,类似于VLMo中的共享多头自注意力层。CoCa[89]融合了单双流的encoder-decoder模型结构,既能生成图像模态和文本模态的表示,又能进行更深层次的图像、文本信息融合以及文本生成,适用于更加广泛的任务。编码器-解码器架构的融合以及灵活的单双流架构前向选择过程使得模型从backbone的层面实现了大一统。
b)遮罩數据建模(masked data modeling)预训练目标在多种模态都取得了的成功应用。如第2章中所介绍,目前的VLP的预训练目标通常包含ITC、ITM等,过多的训练目标导致数据在模型的训练过程中需要很多次前向计算,增加了运算成本。BEiT v3[44]也将图像视作一种语言,以相同的方式来处理文本和图像,从而没有了基本的建模差异,将图像文本视为“平行语句对”,以此来学习模态之间的对齐,这种处理方法在视觉和视觉语言任务上都达到了先进的性能,并证明了生成式预训练的优越性。综上,构建双流模型时,往往使用对比学习进行模态的对齐,以此来解决检索式的理解任务;在解码器单流结构的训练中使用生成式自监督目标。清晰简单的训练目标可以提高训练效率,同时保证模型在下游任务上的优秀性能。
c)大模型、大数据集的概念已经成为了提升模型性能的关键。BEiT[44]系列的工作由40层的多路Transformer组成,整个模型包含近19亿个参数,如此庞大的参数量在训练过程中使用的训练数据均来自于公开数据集,打破了以往模型对高成本构建的专业数据集的依赖,仅仅使用了公共数据资源便在多个子任务中达到了SOTA。这一工作在架构、建模、泛化能力上实现了真正意义上的统一,对之后的多模态工作起到了一个规范化的影响。同时,在海量数据以及大模型堆叠的深度学习趋势下,寻找模型的优化方法也是颇具意义的思路之一。在训练资源有限的情况下,可以从模型输入端、组件优化以及网络串联来利用预训练模型的优点,以较小的代价实现大模型优势的同时保证整体结构的轻量化。
多模态领域中通用基础模型的研究有着广阔的前景和空间去发展和完善,设计子任务泛化性好以及训练高效的多模态范式是多模态领域发展的趋势。并且,在以数据为主要驱动的深度学习背景下,引入知识图谱等辅助驱动也是值得思考的研究方向之一[90]。
参考文献:
[1]Antol S, Agrawal A, Lu Jiasen, et al. VQA: visual question answe-ring[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2015: 2425-2433.
[2]Vinyals O, Toshev A, Bengio S, et al. Show and tell: lessons lear-ned from the 2015 MSCOCO image captioning challenge[J]. IEEE Trans on Pattern Analysis and Machine Intelligence, 2017,39(4): 652-663.
[3]Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems. Red Hook,NY:Curran Associates Inc., 2017:6000-6010.
[4]Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training[EB/OL]. (2018). https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[5]Kim W,Son B,Kim I. ViLT:vision-and-language Transformer without convolution or region supervision[C]//Proc of the 38th International Conference on Machine Learning.[S.l.]: PMLR, 2021: 5583-5594.
[6]Gao Peng, Jiang Zhengkai, You Haoxuan, et al. Dynamic fusion with intra-and inter-modality attention flow for visual question answering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2019: 6632-6641.
[7]Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//Proc of the 28th International Conference on Neural Information Processing Systems. Cambridge,MA: MIT Press, 2015:91-99.
[8]Cho K, Van Merriёnboer B, Gulcehre C, et al. Learning phrase re-presentations using RNN encoder-decoder for statistical machine translation[EB/OL]. (2014). https://arxiv.org/abs/1406.1078.
[9]Jia Chao, Yang Yinfei, Xia Ye, et al. Scaling up visual and vision-language representation learning with noisy text supervision[C]//Proc of International Conference on Machine Learning.[S.l.]:PMLR, 2021: 4904-4916.
[10]Ma Lin, Lu Zhengdong, Shang Lifeng, et al. Multimodal convolutional neural networks for matching image and sentence[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press, 2015:2623-2631.
[11]Vinyals O, Toshev A, Bengio S, et al. Show and tell: a neural image caption generator[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2015:3156-3164.
[12]Huang Lun, Wang Wenmin, Chen Jie, et al. Attention on attention for image captioning[C]//Proc of IEEE/CVF International Confe-rence on Computer Vision. 2019: 4634-4643.
[13]Pan Yingwei, Yao Ting, Li Yehao, et al. X-linear attention networks for image captioning[C]//Proc of IEEE/CVF Conference on Compu-ter Vision and Pattern Recognition. 2020: 10971-10980.
[14]Li Junnan, Li Dongxu, Xiong Caiming, et al. BLIP: bootstrapping language-image pre-training for unified vision-language understanding and generation[C]//Proc of International Conference on Machine Learning. 2022: 12888-12900.
[15]Anderson P, Wu Qi, Teney D, et al. Vision-and-language navigation:interpreting visually-grounded navigation instructions in real environments[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 3674-3683.
[16]Hong Yicong, Wu Qi, Qi Yuankai, et al. VLN BERT: a recurrent vision-and-language BERT for navigation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 1643-1653.
[17]Guhur P L, Tapaswi M, Chen Shizhe, et al. AirBERT: in-domain pretraining for vision-and-language navigation[C]//Proc of IEEE/CVF International Conference on Computer Vision. 2021: 1634-1643.
[18]Qiao Yanyuan, Qi Yuankai, Hong Yicong, et al. HOP: history-and-order aware pre-training for vision-and-language navigation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 15418-15427.
[19]Hong Yicong, Wang Zun, Wu Qi, et al. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 15439-15449.
[20]Das A, Kottur S, Gupta K, et al. Visual dialog[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2017: 326-335.
[21]Xie Ning , Lai F , Doran D ,et al.Visual entailment task for visually-grounded language learning[EB/OL].(2018). https://arxiv.org/abs/1811.10582.
[22]Suhr A, Lewis M, Yeh J, et al. A corpus of natural language for visual reasoning[C]//Proc of the 55th Annual Meeting of Association for Computational Linguistics. 2017: 217-223.
[23]Zellers R, Bisk Y, Farhadi A, et al. From recognition to cognition: visual commonsense reasoning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6720-6731.
[24]王麗安, 缪佩翰, 苏伟, 等. 图像-文本多模态指代表达理解研究综述[J]. 中国图象图形学报, 2023,28(5): 1308-1325. (Wang Lian, Liao Peihan, Su Wei, et al. Multimodal referring expression comprehension based on image and text: a review[J] Journal of Image and Graphics, 2023,28(5):1308-1325.)
[25]Rashtchian C, Young P, Hodosh M, et al. Collecting image annotations using Amazons mechanical Turk[C]//Proc of NAACL HLT Workshop on Creating Speech and Language Data with Amazons Mechanical Turk. 2010: 139-147.
[26]Welinder C, Branson S, Welinder P,et al.The Caltech-UCSD birds-200-2011 dataset[DB/OL]. (2011).https://gwern.net/doc/ai/dataset/2011-wah.pdf.
[27]Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: common objects in context[C]//Proc of the 13th European Conference on Computer.Berlin: Springer, 2014: 740-755.
[28]Krishna R, Zhu Yuke, Groth O, et al. Visual genome: connecting language and vision using crowdsourced dense image annotations[J]. International Journal of Computer Vision, 2017, 123: 32-73.
[29]Zhu Yuke, Groth O, Bernstein M, et al. Visual 7W: grounded question answering in images[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2016: 4995-5004.
[30]Plummer B A, Wang Liwei, Cervantes C M, et al. Flickr30k entities: collecting region-to-phrase correspondences for richer image-to-sentence models[C]//Proc of IEEE International Conference on Computer Vision. Piscataway,NJ:IEEE Press, 2015: 2641-2649.
[31]Goyal Y, Khot T, Summers-Stay D, et al. Making the v in VQA matter: elevating the role of image understanding in visual question answering[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2017: 6904-6913.
[32]Hudson D A, Manning C D. GQA: a new dataset for real-world visual reasoning and compositional question answering[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 6700-6709.
[33]Kuznetsova A, Rom H, Alldrin N, et al. The open images dataset v4:unified image classification, object detection, and visual relationship detection at scale[J]. International Journal of Computer Vision, 2020, 128(7): 1956-1981.
[34]Wu Hui, Gao Yupeng, Guo Xiaoxiao, et al. Fashion IQ: a new dataset towards retrieving images by natural language feedback[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 11307-11317.
[35]Changpinyo S, Sharma P, Ding N, et al. Conceptual 12M: pushing Web-scale image-text pre-training to recognize long-tail visual concepts[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 3558-3568.
[36]Benenson R, Ferrari V. From colouring-in to pointillism: revisiting semantic segmentation supervision[EB/OL]. (2022). https://arxiv.org/abs/2210.14142.
[37]Sharma P,Ding N,Goodman S, et al. Conceptual captions: a cleaned, hypernymed, image alt-text dataset for automatic image captioning[C]//Proc of the 56th Annual Meeting of the Association for Computational Linguistics. 2018: 2556-2565.
[38]He Kaiming, Fan Haoqi, Wu Yuxin, et al. Momentum contrast for unsupervised visual representation learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 9729-9738.
[39]Lu Jiasen, Batra D, Parikh D, et al. VilBERT: pretraining task-agnostic visiolinguistic representations for vision-and-language tasks[C]//Advances in Neural Information Processing Systems. 2019.
[40]Li Junnan, Selvaraju R, Gotmare A, et al. Align before fuse: vision and language representation learning with momentum distillation[C]//Advances in Neural Information Processing Systems. 2021: 9694-9705.
[41]Kenton J D M W C, Toutanova L K. BERT: pre-training of deep bidirectional Transformers for language understanding[C]//Proc of NAACL-HLT. 2019: 4171-4186.
[42]Lan Zhenzhong, Chen M, Goodman S, et al. ALBERT: ALite BERT for self-supervised learning of language representations[EB/OL]. (2019). https://arxiv.org/abs/1909.11942.
[43]Yang Zhilin, Dai Zihang, Yang Yiming, et al. XLNet: generalized autoregressive pretraining for language understanding[C]//Advances in Neural Information Processing Systems. 2019.
[44]Joshi M, Chen Danqi, Liu Yihan, et al. SpanBERT: improving pre-training by representing and predicting spans[J]. Trans of the Association for Computational Linguistics, 2020,8: 64-77.
[45]Rombach R, Blattmann A, Lorenz D, et al. High-resolution image synthesis with latent diffusion models[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 10684-10695.
[46]Wang Wenhui, Bao Hangbo, Dong Li, et al. Image as a foreign language: BEiT pretraining for all vision and vision-language tasks[EB/OL]. (2022). https://arxiv.org/abs/2208.10442.
[47]Bao Hangbo, Dong Li, Piao Songhao, et al. BEiT: BERT pre-training of image transformers[C]//Proc of International Conference on Lear-ning Representations. 2021.
[48]Bao Hangbo, Wang Wenhui, Dong Li, et al. VL-BEiT: generative vision-language pretraining[EB/OL]. (2022). https://arxiv.org/abs/2206.01127.
[49]陳天鹏,胡建文.面向深度学习的遥感图像旋转目标检测研究综述[J].计算机应用研究, 2024,41(2):329-340. (Chen Tianpeng, Hu Jianwen. Overview of deep learning for oriented rotating object detection in remote sensing images[J].Application Research of Computers, 2024,41(2):329-340.)
[50]Su Weijie, Zhu Xizhou, Cao Yue, et al. VL-BERT: pre-training of generic visual-linguistic representations[C]//Proc of International Conference on Learning Representations. 2019.
[51]Chen Yenchun, Li Linjie, Yu Licheng, et al. Uniter: universal image text representation learning[C]//Proc of European Conference on Computer Vision. Cham: Springer, 2020: 104-120.
[52]Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2016: 779-788.
[53]Lu Qishou, Liu Chonghua, Jiang Zhuqing, et al. G-CNN: object detection via grid convolutional neural network[J]. IEEE Access, 2017, 5: 24023-24031.
[54]Huang Zhicheng, Zeng Zhaoyang, Liu Bei, et al. Pixel-BERT: aligning image pixels with text by deep multi-modal Transformers[EB/OL]. (2020). https://arxiv.org/abs/2004.00849.
[55]Wang Fei, Jiang Mengqing, Qian Chen, et al. Residual attention network for image classification[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2017: 3156-3164.
[56]Wang Xiaolong, Girshick R, Gupta A, et al. Non-local neural networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition. Piscataway,NJ:IEEE Press, 2018: 7794-7803.
[57]Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2020).https://arxiv.org/abs/2010.11929.
[58]Liu Ze, Lin Yutong, Cao Yue, et al. Swin transformer: hierarchical vision transformer using shifted windows[C]//Proc of IEEE/CVF International Conference on Computer Vision. 2021: 10012-10022.
[59]Touvron H, Cord M, Douze M, et al. Training data-efficient image Transformers & distillation through attention[C]//Proc of International Conference on Machine Learning. 2021: 10347-10357.
[60]Graham B, El-Nouby A, Touvron H, et al. LeVIT: a vision Transformer in convnets clothing for faster inference[C]//Proc of IEEE/CVF International Conference on Computer Vision. 2021: 12259-12269.
[61]Mikolov T, Karafiát M, Burget L, et al. Recurrent neural network based language model[C]//Proc of InterSpeech. 2010: 1045-1048.
[62]Huang Zhiheng, Xu Wei, Yu Kai. Bidirectional LSTM-CRF models for sequence tagging[EB/OL]. (2015). https://arxiv.org/abs/1508.01991.
[63]Lin Zhouhan, Feng Minwei, Dos Santos C, et al. A structured self-attentive sentence embedding[C]//Proc of International Conference on Learning Representations. 2017.
[64]Hu Yongli, Chen Puman, Liu Tengfei, et al. Hierarchical attention Transformer networks for long document classification[C]//Proc of International Joint Conference on Neural Networks. Piscataway,NJ:IEEE Press, 2021: 1-7.
[65]Wang Wei, Yan Ming, Wu Chen. Multi-granularity hierarchical attention fusion networks for reading comprehension and question answering[C]//Proc of the 56th Annual Meeting of Association for Computational Linguistics. 2018: 1705-1714.
[66]Ma Dehong, Li Sujian, Zhang Xiaodong, et al. Interactive attention networks for aspect-level sentiment classification[C]//Proc of the 26th International Joint Conference on Artificial Intelligence. 2017: 4068-4074.
[67]Liu Yinhan, Ott M, Goyal N, et al. RoBERTa: a robustly optimized BERT pretraining approach[EB/OL]. (2019). https://arxiv.org/abs/1907.11692.
[68]Faghri F, Fleet D J, Kiros J R, et al. Improving visual-semantic embeddings with hard negatives[EB/OL]. (2017). https://arxiv.org/abs/1707.05612.
[69]Li Gen, Duan Nan, Fang Yuejian, et al. Unicoder-VL: a universal encoder for vision and language by cross-modal pre-training[C]//Proc of AAAI Conference on Artificial Intelligence. 2020: 11336-11344.
[70]Lee K H, Chen Xi, Hua Gang, et al. Stacked cross attention for image text matching[C]//Proc of European Conference on Computer Vision. 2018: 201-216.
[71]Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//Proc of the 38th International Conference on Machine Learning.[S.l.]:PMLR, 2021: 8748-8763.
[72]Tan Mingxing, Le Q. EfficientNet: rethinking model scaling for con-volutional neural networks[C]//Proc of the 36th International Confe-rence on Machine Learning.[S.l.]:RMLR, 2019: 6105-6114.
[73]Tan Hao, Bansal M. LXMERT: learning cross-modality encoder representations from Transformers[C]//Proc of Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing. 2019: 5100-5111.
[74]Kiela D,Bhooshan S,Firooz H,et al. Supervised multimodal bitransformers for classifying images and text[EB/OL]. (2019). https://arxiv.org/abs/1909.02950.
[75]Li Xiujun, Yin Xi, Li Chunyuan, et al. Oscar: object-semantics aligned pre-training for vision-language tasks[C]//Proc of the 16th European Conference Computer Vision.Berlin:Springer,2020:121-137.
[76]Radford A, Wu J, Child R, et al. Language models are unsupervised multitask learners[J]. OpenAI Blog, 2019,1(8): 9.
[77]Miyawaki S, Hasegawa T, Nishida K, et al. Scene-text aware image and text retrieval with dual-encoder[C]//Proc of the 60th Annual Meeting of Association for Computational Linguistics: Student Research Workshop. 2022: 422-433.
[78]Li Linjie, Chen Yenchun, Cheng Yucheng, et al. HERO: hierarchical encoder for video+ language omni-representation pre-training[C]//Proc of Conference on Empirical Methods in Natural Language Processing. 2020: 2046-2065.
[79]Bao Hangbo, Wang Wenhui, Dong Li, et al. VLMo: unified vision-language pre-training with mixture-of-modality-experts[C]//Advances in Neural Information Processing Systems.2021.
[80]Wu Chenfei, Yin Shengming, Qi Weizhen, et al. Visual ChatGPT: talking, drawing and editing with visual foundation models[EB/OL]. (2023). https://arxiv.org/abs/2303.04671.
[81]Ouyang Long, Wu J, Jiang Xu, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022,35: 27730-27744.
[82]Houlsby N, Giurgiu A, Jastrzebski S, et al. Parameter-efficient transfer learning for NLP[C]//Proc of International Conference on Machine Learning. 2019: 2790-2799.
[83]Yang Taojiannan, Zhu Yi, Xie Yusheng, et al. AIM: adapting image models for efficient video action recognition[C]//Proc of the 11th International Conference on Learning Representations.2023.
[84]Zhou Kaiyang, Yang Jingkang, Loy C C, et al. Learning to prompt for vision-language models[J]. International Journal of Computer Vision, 2022,130(9): 2337-2348.
[85]Liu Shikun, Fan Linxi, Johns E, et al. Prismer: a vision-language model with an ensemble of experts[EB/OL]. (2023). https://arxiv.org/abs/2303.02506.
[86]Yu Jiahui, Wang Zirui, Vasudevan V, et al. CoCa: contrastive captioners are image-text foundation models[EB/OL]. (2022-05-04). https://arxiv.org/abs/2205.01917.
[87]Mokady R, Hertz A, Bermano A H. Clipcap: clip prefix for image captioning[EB/OL]. (2021). https://arxiv.org/abs/2111.09734.
[88]Zhou Luowei, Hamid P, Zhang Lei, et al.Unified vision-language pretraining for image captioning and VQA[C]//Proc of AAAI Confe-rence on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2020:13041-13049.
[89]张浩宇,王天保,李孟择,等. 视觉语言多模态预训练综述[J].中国图象图形学报, 2022,27(9):2652-2682. (Zhang Haoyu, Wang Tianbao, Li Mengze, et al. Comprehensive review of visual-language-oriented multimodal pre-training methods[J].Journal of Image and Graphics, 2022,27(9):2652-2682.)
[90]李源,馬新宇,杨国利,等. 面向知识图谱和大语言模型的因果关系推断综述[J].计算机科学与探索, 2023,17(10):2358-2376. (Li Yuan, Ma Xinyu, Yang Guoli, et al. Survey of causal inference for knowledge graphs and large language models[J].Journal of Frontiers of Computer Science and Technology, 2023,17(10):2358-2376.)
