基于云计算技术的虚拟数字人算法研究
2024-05-25钟政黄琳舒曾炎麟黎雪黄驰
钟政,黄琳舒,曾炎麟,黎雪,黄驰
广州城市理工学院计算机工程学院,广东广州,510850
0 引言
在数字媒体时代,虚拟数字人在广播、娱乐和教育等领域已崭露头角。它们不仅在网络上娱乐观众,为学生提供个性化教育,还能作为智能助手为日常生活带来便利。但制作和部署这些虚拟数字人仍面临诸多挑战。
1 虚拟数字人技术
1.1 背景与意义
目前,虚拟数字人的制作和部署方式众多,且驱动系统各异,导致移植和部署过程中出现许多问题。为应对这一挑战,本文研究了一种云端的轻量、高效且灵活的虚拟数字人部署架构。
1.2 研究问题
本文着重关注了两项核心技术:算法的容器化和无服务器计算。容器化技术提供了一种高度灵活和可移植的虚拟数字人算法部署方式。无论虚拟数字人的制作者使用何种云计算平台,算法都可以在容器中稳定运行,实现快速部署和高度的可移植性。
对普通用户和大多数创作者而言,虚拟数字人既熟悉又陌生。熟悉的是其形象和声音,而陌生的是背后的技术实现,因为虚拟数字人技术的学习和使用成本相对较高。但在本项目的架构中,算法函数在容器中运行,使得用户无需关心服务器相关技术,可以专注于内容创作。高级用户还可以用自己的算法替换原有算法。因此,云计算架构和容器技术使虚拟数字人技术更为便捷和灵活。
与此同时,计算模型(云函数)提供了一种创新的虚拟数字人部署范式。这种模型使得虚拟数字人视频的制作具有灵活性和便利性。通过结合容器化技术和云计算,构建了一种前沿的虚拟数字人轻量且高效的云上架构,这一架构将推动虚拟数字人技术的普及,更好地服务于观众、学生和用户。虚拟数字人不再仅限于特定平台或场景,而是能在云端高效运行,为各行业创造更多机会。
1.3 研究目标
本文将聚焦于使用现有的目标检测算法、二维坐标与三维坐标转换算法,以及语音生成算法,基于云函数计算和容器化计算,在云端部署一套易复现、高扩展性的虚拟数字人视频生成系统。
2 虚拟数字人技术
2.1 虚拟数字人建模
虚拟数字人形象建模有许多不同的方法。其中五种常见的方法包括:扫描技术、手动建模、基于图像的建模、基于物理仿真的建模和混合方法[1]。本文利用blender 3D建模软件对虚拟数字人形象进行手动建模,这种建模方式可以使得虚拟数字人模型更富有可塑性,在细节方面更具有精准度,在对模型的调整方面更加灵活,也使得模型更加具有设计者的独特风格[2]。本文成功打造了具有青春活力的大学生形象的虚拟数字人模型,并让虚拟数字人形象顺利完成一些新闻播报视频的制作。虚拟形象如图1所示。

图1 虚拟数字人建模
2.2 人物关节点检测
人物关节点检测是虚拟数字人技术的核心环节。其目的是从图像或视频中精确定位和识别人体的关键部位,例如:头部、手部和脚部。在这方面,YOLO系列技术备受瞩目。特别是YOLO3,它采纳了实时目标检测和识别的方法,以其高效和迅速的特性脱颖而出。本研究参考了YOLO3的方法,能够从视频中准确地检测出人体的17个关键节点的二维坐标,如图2所示,为虚拟数字人的姿态估计提供了坚实的数据基础。

图2 人体关节点识别标注
2.3 3D骨骼动画生成
VideoTo3dPoseAndBvh算法融合了YOLO3模型,能够将YOLO3逐帧识别的关节点二维坐标转化为三维坐标。由于人体骨骼、经络和肌肉之间存在紧密的联系,基于二维视频关节点坐标,可以推导出指定坐标系下的三维坐标。获取三维坐标后,进行坐标转换,将关节点坐标移至坐标系中心,然后将每帧的三维坐标写入指定格式的Bvh骨骼动画文件。最终,在Blender等3D建模软件中将骨骼动画与人物模型结合,通过相机记录动作,生成动作文件,达到驱动虚拟数字人的效果,如图3所示。
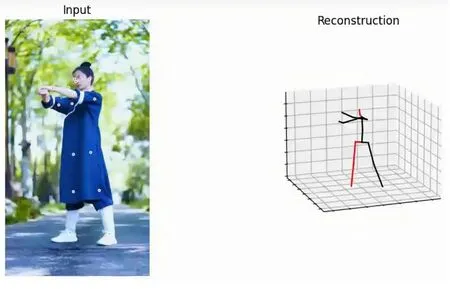
图3 人物姿态动画骨架
2.4 语音合成
在虚拟数字人技术中,赋予其说话能力的关键是语音合成。虽然存在众多相关算法,但此处选择了MockingBird算法,其核心基于Transformer架构。在语音合成的过程中,Mockingbird的工作机制如下。
①文本到语音的转换:在预训练阶段,Mockingbird利用大量语音数据学习文本到语音的转换规则。它尝试预测输入文本的下一个音频帧,通过这种填空方式来掌握文本与语音的关联。
②模型的重新训练:在此阶段,需要为模型加入更多的中文训练数据,使得模型对中文语音的合成有更好的鲁棒性,MockingBird通过大量的音频学习,掌握了如何从中文文本映射至相应的中文语音。
③模型的微调:在此阶段,Mockingbird使用标注的文本数据,例如句子及其对应的语音,来微调预训练的模型参数,确保输出的语音与输入文本高度匹配。
④WaveNet声码器的输出:为了产生高品质的语音输出,Mockingbird结合了WaveNet声码器。WaveNet是一种能够产生自然语音波形的先进声码器。
⑤文本语音的合成:通过结合Transformer与WaveNet,Mockingbird能够生成文本合成的语音波形,为虚拟数字人提供了逼真的语音输出,并确保口型与语音同步。
系统的核心目标是生成高品质的动画和语音,使得虚拟数字人能够逼真地展现其动作和语音。通过整合VideoTo3dPoseAndBvh算法与Mockingbird算法,构建了一个强大的系统,适用于虚拟演员、虚拟主播、游戏角色等多种应用场景。这一基于容器技术和云函数集群的无服务器架构,优雅地应对了多模型应用场景的挑战,允许虚拟数字人的驱动流程与语音合成流程并行运行,为虚拟数字人技术的应用和部署开辟了新的路径。
2.5 视频处理算法
在视频处理过程中,采用了VideoTo3dPose AndBvh算法,其核心步骤如下。
①人物关节点识别:利用YOLO3对视频中的人物关节点进行识别,从而提取出二维关节点坐标。这些二维坐标为后续推导出三维关节点坐标提供了基础。
②2D坐标标准化:为了确保数据的一致性和方便后续计算,对提取的2D坐标进行标准化处理,使其均匀分布在-1到1的范围内。这一步骤确保了来自不同视频源的数据具有一致性。
③3D坐标生成:基于标准化的2D坐标,VideoTo3dPoseAndBvh算法将其映射到三维空间,生成对应的3D关节点坐标。这些三维坐标包括x、y和z轴的位置信息,为接下来的骨骼动画文件生成提供了关键数据。
④坐标轴转化:在合成和渲染视频的过程中调用了blender SDK的相关接口,由于blender等不同3D渲染软件可能存在参考系差异,因此,在视频合成脚本中加入了可选的坐标轴转化。
⑤模型骨骼绑定:在驱动虚拟数字人模型时,需要将模型与骨骼进行绑定,而模型尺寸与骨骼尺寸很可能不匹配,因此在绑定前需要根据模型尺寸比例对骨骼尺寸进行调整,使得模型尺寸与骨骼尺寸相吻合,如图4所示。

图4 调整前后示例
⑥视频合成:在模型骨骼绑定以后,视频合成脚本将会把预制视频环境载入,随后调用3D渲染软件的视频制作接口,导出动画视频,最后将音频与视频进行结合,导出视频片段文件至指定区域,在最后部分视频片段完成以后,调用流处理脚本,将多个小的视频片段文件整合成完整视频存储。
3 云上架构
遵循云原生理念,构建了如图5所示架构,并通过容器技术将算法部署在云函数中。
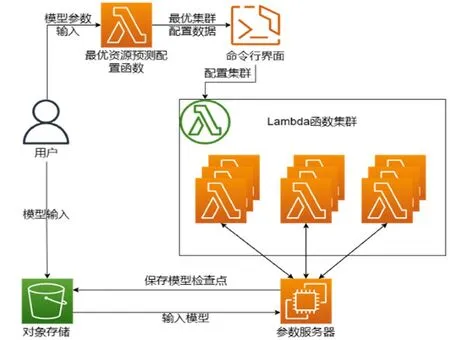
图5 云上架构(以亚马逊云为例)
3.1 云函数计算
无服务器计算是一种新兴的云计算范例,它旨在简化应用程序的部署和管理。云函数允许开发者将代码片段上传到云平台,而无需担心底层服务器的配置和维护。这种计算方式具有自动化、事件触发、高度可伸缩性等特点,非常适合响应性事件驱动的需求。在系统中,云函数集群构建在无服务器架构上,这使得系统具有高度的灵活性,能够根据工作负载的需要自动扩展或缩减,以响应不同的流量需求[3]。
3.2 云函数集群架构
由于视频数据可以进行帧级别并发,为了尽可能满足不同视频多任务并发和视频内帧级别并发的需求,系统的部署使用容器映像来创建云函数,这种方式可以保证不同任务间和同一任务内部的计算资源隔离,以及云函数的快速启动,实现快速拉起算力,完成多层次的并发处理。
在部署阶段,用户首先使用云资源监测服务来进行负载测试。通过在单个云函数中对模型进行单帧或小时间片段的负载测试,用户可以根据实时性需求计算出单个模型所需要的并发云函数需求量。这个过程的目的是通过云监控服务获取单个云函数对算法的处理能力,根据客户期望的处理速度,计算出相应时间内需要拉取的云函数数量,并最终配置云函数仓库中的云函数参数。根据测试数据来获取合适的云函数并发量,系统可以对云函数触发数量进行配置,从而满足用户对任务处理速度的需求。在使用阶段,用户只需要将数据流上传至云端,并通过云厂商提供的流处理服务触发云函数[4]。云函数会对数据流进行处理,并将处理结果返回给参数服务器,最终将整合完成后的数据流保存到对象存储服务中。这一过程实现了数据流的处理和存储的自动化,大大提高了数据处理的效率和灵活性[5]。
云函数计算在处理大规模数据流时具有很大的优势。通过合理配置云函数并发量,可以灵活地处理不同规模和实时性需求的任务。将各种算法分别编排为云函数集群,根据云函数数据吞吐率定义集群中单次任务响应云函数数量,如图6所示。云函数计算的使用还能减少资源的浪费,因为,用户可以根据实际需求动态调整云函数的数量和并发量,避免了资源浪费。
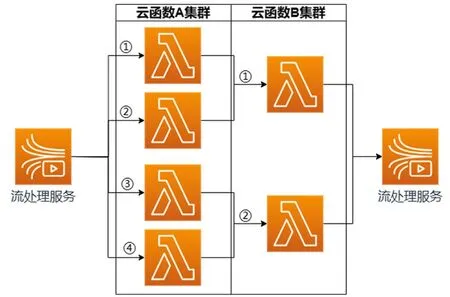
图6 云函数并发处理结构
4 总结
云上架构的成功应用:本文成功构建了一个基于云端的架构,通过容器技术部署了Video To3dPoseAndBvh和Mockingbird两大算法和视频合成脚本三部分云函数集群。这一架构为虚拟数字人的动作和语音合成提供了高效且灵活的解决路径。
YOLO3的表现:YOLO3在人物关节点检测上有着出色的表现,能够准确地检测出17个关键节点。但在某些遮挡情况下,该算法可能会遇到错检、漏检或关节点扭曲的问题。为了进一步提高算法的稳定性,未来的研究方向可以集中在增强算法的鲁棒性。
VideoTo3dPoseAndBvh算法的效果:该算法成功地将2D关节点坐标映射到3D空间,并生成了高品质的骨骼动画。但在处理低帧率视频时,可能会出现动画不流畅的现象,这提示我们在未来的优化中考虑动态调整帧率。
Mockingbird算法的应用:Mockingbird为虚拟数字人提供了高度逼真的语音合成效果,极大地增强了虚拟数字人的真实感和吸引力。但在部分语音合成任务中,合成的语音存在着部分噪声,在优化语音合成效果方面,需要进一步提高训练数据的质量,在进行模型训练前需要对训练数据进行降噪处理,降低噪声干扰。
视频合成脚本:视频合成脚本可完成虚拟数字人模型和骨骼动画的绑定,并调用3D动画制作接口渲染出虚拟数字人视频,最后完成视频和音轨合并等一系列任务。但脚本中的模型骨骼绑定算法需要提前输入模型尺寸数据,这部分往往需要手动测量,在虚拟数字人模型更换时较为复杂。在系统改进方案中,可进一步调用YOLO3算法,对虚拟数字人标准T型姿势下各部分躯体数据进行监测,在虚拟数字人模型更换时自动完成模型尺寸数据的更新。
5 结论
经过本次项目的深入探讨与实证分析,在虚拟数字人领域的云计算技术应用上取得了显著的研究成果。基于云端的架构在实现虚拟数字人驱动时表现卓越,实现了视频到3D姿态及动画的高效转换,并利用Mockingbird算法为数字人带来了高度真实的语音效果。但当前模型尺寸的手动输入过程繁琐,未来计划集成更智能的算法,如利用YOLO3自动检测并更新模型尺寸数据,从而优化用户体验。
