一种针对SAR图像的船舶目标检测算法
2024-05-09赵良军郑莉萍席裕斌何中良
宁 峰, 赵良军, 郑莉萍, 梁 刚, 席裕斌, 何中良
(四川轻化工大学,a.自动化与信息工程学院; b.计算机科学与工程学院,四川 宜宾 643000)
0 引言
伴随合成孔径雷达(SAR)技术的不断发展,SAR技术在各个领域都有越来越多的应用,目前已经成为对海洋船舶观测的重要手段之一。相较于传统的光学图像船舶目标检测,可见光图像仅仅能对白天区域内的船舶进行检测,而SAR图像可进行全天候、全天时、不受天气影响的检测,其效果不受昼夜交换和天气变化的影响,具有显著的优势[1]。
由于仅对海洋船舶图像这一类别进行检测,因此本文研究会更多地关心细粒度与网络结构的设计。目前主流的SAR图像目标检测方法均为深度学习方法。其中,以SSD[2]、YOLO系列[3-4]为代表的一阶段模型以及以Faster R-CNN[5]、Cacade R-CNN[6]算法为代表的深度学习目标检测模型凭借其高精度、高效率、高鲁棒性等优点,已在SAR图像目标检测中得到广泛应用。
然而,现有的目标检测算法对海洋、岛礁等的区分还比较受限,存在以下3个主要缺陷:1) SAR图像不易区分海洋、岛礁、沿岸港口等,识别难度大;2) 由环境和地理位置的干扰而引起船舶尺寸和形状变化较大,使得模型准确率较低;3) 数据集中的大船舶模型过少,模型对小目标更灵敏,大船舶检测不佳。
为克服这些缺点本文提出了Vessel-YOLO模型,该模型是一种改进型的YOLOv8n网络结构。具体地,首先使用本文提出CASPP(Context-Aware Spatial Pyramid Pooling)模块,结合了空洞卷积[7],可在不丢失分辨率的情况下扩大卷积核的感受野,提高模型对不同比例船舶的适应程度。此外,本文模型使用了基于动态非单调聚焦机制的边界框损失Wise-IoU[8],相比于CIoU,Wise-IoU提供了更加明智的梯度增益分配策略。实验结果表明,Vessel-YOLO船舶检测模型在很大程度上优于现有的算法。
在目标检测的任务中,不同尺度的目标对于深度学习模型来说一直是一大困扰,模型的特征提取很容易因为目标尺度的数据量差距过大而导致模型向着某一尺度收敛。王凯等[9]提出改进特征提取网络,删除深层次特征层,减少语义丢失现象,来解决这一问题。
1 方法
图1所示为本文提出的Vessel-YOLO模型总体设计结构。
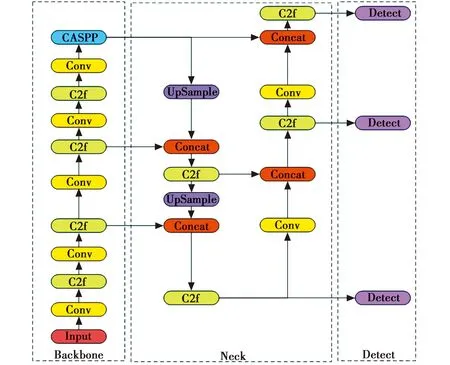
图1 Vessel-YOLO模型结构Fig.1 Vessel-YOLO model structure
图1中,Vessel-YOLO模型以YOLOv8n为基础模型,主要由3个部分组成:1) 以Darknet-53为基础,改进了特征金字塔的主干网络(Backbone);2) 颈部网络(Neck);3) 检测部分(Detect)。
在Backbone部分,Vessel-YOLO由Conv模块、C2f模块和CASPP上下文空间金字塔池化模块组成。其中,Conv模块和C2f采用YOLOv8n相同的结构。 Conv为卷积模块,封装了3个功能,包括二维卷积操作(Conv2d)、BN层以及SiLU激活函数;C2f模块参考了C3模块以及ELAN的思想进行的设计,在结构上增加了更多的跳层连接与额外的Split操作,让YOLOv8n可以在保证轻量化的同时获得更加丰富的梯度流信息。此外,在YOLOv8n的基础上,Vessel-YOLO模型通过本文提出的 CASPP上下文空间金字塔池化模块替换YOLOv8n的SPPF模块,提高了模型的语义感知能力,使模型的精度得到一定的提高。
在模型的Neck部分和Detect部分,Vessel-YOLO与YOLOv8n结构相同。
1.1 CASPP 上下文空间金字塔池化
在主干网络架构设计之后,本文设计了以ASPP[10]为基础的CASPP上下文空间金字塔池化模块,如图2所示。
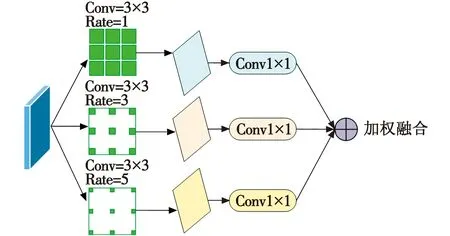
图2 CASPP结构Fig.2 CASPP structure
相较于普通卷积,膨胀卷积引入了一个新的超参数扩张率(Dilation Rate),该参数定义了卷积核处理数据时各值的间距。图2中,当卷积核为3×3时,不同扩张率的感受野各不相同,当扩张率为1时,与普通卷积结果相同,卷积后的感受野为3;当扩张率为3时,感受野为7;当扩张率为5时,感受野为11。因此,膨胀卷积可以使模型提取到更大的感受野。
CASPP 模块首先通过不同扩张率的膨胀卷积获得不同感受野的上下文信息,3个通道一一对应于3个输入,再进行加权融合,通过计算加权和将上下文信息聚合到输出,即在空间和通道的维度上直接添加特征图。将不同尺度或不同模态的特征进行加权求和,以获得更全面和鲁棒性的特征显示。
对于图像语义信息而言,随着模型层数增多,由于小目标尺度小,语义信息在上层即提取完毕。之后随着层数继续增加,小目标的语义信息也会快速被环境信息所稀释;而大目标尺度大,可能要在更高层才能提取到足够的语义信息,但此时小目标的语义信息已经大量丢失。CASPP模块通过以不同的膨胀卷积率进行膨胀卷积来获得不同的感受野的上下文信息,提高了模型对不同尺度特征的提取能力,使其对大小目标都能提取到足够的语义信息,提高了模型的泛化能力。
1.2 损失函数的计算
由于使用了无锚框思想,YOLOv8n的损失函数与YOLOv5系列相比有了很大的变化,其主要由分类和回归两部分损失组成:分类损失仍然使用二进制交叉熵损失(Binary Cross Entropy Loss,BCL),回归部分使用分布焦点损失 (Distribution Focal Loss,DFL)和边界框回归损失(Bounding Box Regression Loss,BBRL)。由于SAR船舶图像种类仅1种,因此二进制交叉熵损失即类别损失为0。最终总的损失为两部分损失通过一定的权重比例之和,总的损失函数可以表示为
fLoss=λ1fDFL+λ2fBBRL
(1)
式中:λ1、λ2代表权重系数,本文中λ1、λ2均取1;fDFL代表分布焦点损失;fBBRL代表回归损失。
DFL是对焦点损失函数的优化,通过积分将分类的离散结果推广为连续结果。表达式为
fDFL(Si,Si+1)=-((yi+1-y)ln(Si)+(y-yi)ln(Si+1))
(2)
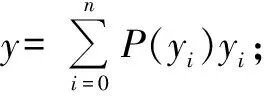
边界框损失函数作为目标检测损失函数的重要组成部分,其良好的定义将为目标检测模型带来显著的性能提升。近年来的研究大多假设训练数据中的示例有较高的质量,致力于强化边界框损失的拟合能力。但是训练数据中难免包含低质量图像,如距离、纵横比之类的几何度量都会加剧低质量图像的误差,从而使模型的泛化能力下降。好的损失函数应该在锚框与目标框较好地重合时减少几何维度的惩罚,不过多地干预训练结果,使模型具有更好的泛化能力。
由于SAR图像存在由环境和地理位置的干扰而引起船舶尺寸和形状变化较大以及图像质量较低的问题,因此,本文引入了基于 Focal Loss 的Wise-IoU损失函数的计算方法,通过引入框之间的区域和权重系数wi,使得Wise-IoU可以更准确地评估目标检测结果,避免了传统IoU的偏差问题,其表达式为
(3)
式中:n为物体框的数量;bi为第i个物体框的坐标;gi为第i个物体框的真实标注框的坐标;IIoU(bi,gi)为第i个物体框与真实标注框之间的IoU值。
2 实验与分析
2.1 数据集分析
本文使用SAR-Ship-Dataset[11]和SSDD[12]数据集训练和测试船舶检测模型。训练过程中使用的SAR-Ship-Dataset数据集共43 819幅SAR船舶图像,本文按7∶3的比例划分出了训练集、测试集;SSDD数据集则作为模型定量分析的实验数据集。为满足SSDD与SAR-Ship-Dataset数据集格式相同,本文统一将图像标签设置为txt的数据格式。
通过对SAR-Ship-Dataset数据集的图像进行分析,得到了图像的如下特点:1) 如图3(a)所示,只存在1只船舶的图像数量最多,其余图像中平均存在2~3只船舶,也存在少数图像包含大量船舶元素,可以看出,船舶空间分布不均衡在检测含有大量船舶目标的图像时会出现漏检现象;2) 如图3(b)所示,数据集中大多数船舶均为小尺寸目标,也存在有少量的大尺寸船舶目标,即船舶尺寸分布不均衡,检测大尺寸的船舶目标模型会出现欠拟合现象;3) 如图3(c)所示,图像的尺寸以像素为单位,小尺寸船舶占比较多,大型船舶大部分为扁长形;4) 如图3(d)所示,船舶目标框多为小方型和扁长型且真实框的宽高比率集中在1~2之间。

图3 数据集分析Fig.3 Dataset analysis
2.2 评价指标与实验详细信息
为基于验证数据集评估Vessel-YOLO算法在SAR图像船舶检测方面的性能,目标检测通常采用准确率(P)、召回率(R)、平均精度均值(mAP)以及平均召回率(AR)作为评估指标。构成目标检测评价指标的基本参数是真阳性(TP)、假阳性(FP)和假阴性(FN)。TP表示预测阳性目标和实际是阳性目标的数量,即当且仅当Vessel-YOLO准确地检测并定位船舶目标时,结果才被视为真阳性;FP表示预测阳性目标但实际是阴性目标的数量;FN表示预测的阴性目标但实际是阳性目标的数量。
实验采用YOLOv8n作为基础组件,首先使用txt格式数据集训练初始化网络,其次使用batch size为16的SGD优化器对模型进行了300轮的训练。其中,主干网络的初始学习率设为0.02,动量为0.9。本文实验均在NVIDIA GeForce RTX 3060Ti GPU上进行。
2.3 与最新技术的比较
表1所示为Vessel-YOLO与各类SAR图像船舶目标检测算法的定量比较,本文中,表中加粗数据均表示最优结果。表1中采用mAP、帧率(FPS)、参数量(Params)和浮点运算量(FLOPs)作为评价指标。
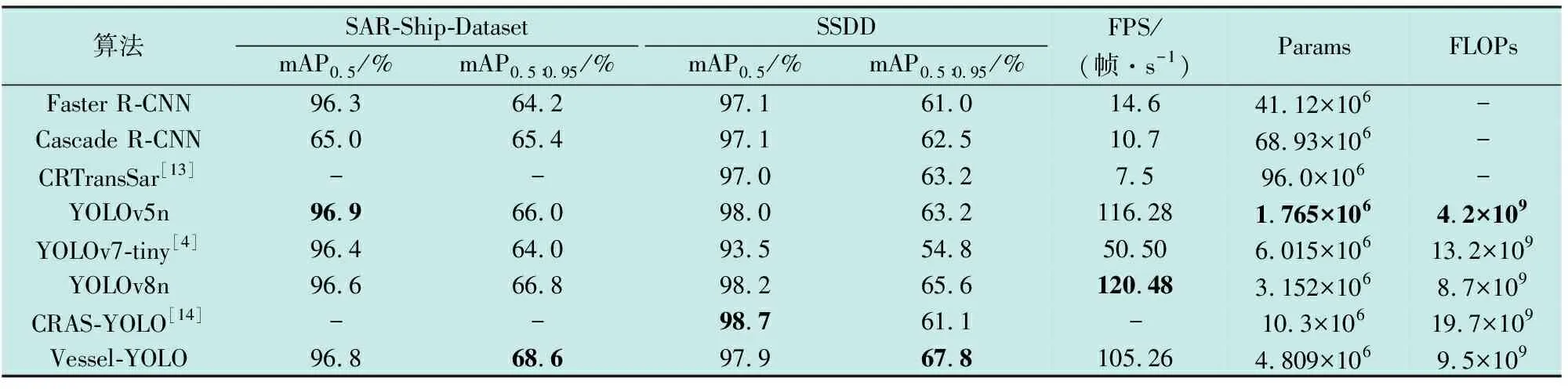
表1 各类SAR图像船舶检测在数据集上的表现
具体来说,本文通过分别选取两阶段、一阶段的目标检测模型和SAR图像船舶目标检测算法与本算法在开源公共数据集SAR-Ship-Dataset和SSDD上进行对比分析。
在两阶段检测模型中,多数研究使用Faster R-CNN和 Cascade R-CNN为基准模型进行改进,如CRTransSar以Swin Transfromer为基本框架提出了一种基于上下文联合表示学习的主干网络,但模型体积和参数量过于庞大。
在一阶段检测模型中,多数学者受YOLO系列算法的启发开始自主实现相关的检测模型,CRAS-YOLO基于一阶段模型思想下构建的网络模型在小目标检测任务上都有着出色的表现,但整体精度AP0.5∶0.95上并无明显增长。
根据表1中的数据可得出以下结论:Vessel-YOLO船舶检测模型在开源数据集SAR-Ship-Dataset和SSDD中均表现出色。具体而言,相较于YOLOv8n模型,在SAR-Ship-Dataset数据集中,Vessel-YOLO在mAP0.5指标上提升了0.2个百分点,并在mAP0.5∶0.95指标上提升了1.8个百分点,达到了68.6%;在SSDD数据集上,两个模型在mAP0.5方面表现相当,而Vessel-YOLO在mAP0.5∶0.95指标上提升了2.2个百分点,提升到了67.8%。
Vessel-YOLO模型作为一阶段的实时检测模型,在速度上远高于Cascade R-CNN、CRTransSar等两阶段的模型。在一阶段模型中,Vessel-YOLO模型在Params和FLOPs两个方面的数据都处于中等水平。在FPS上,稍弱于目前的较为流行的YOLOv8n模型与YOLOv5n模型,但强于YOLOv7-tiny模型。因此,改进模型在速度上是可满足实时检测的。
这些发现强调了Vessel-YOLO模型在船舶检测任务上的优秀性能。对于SAR-Ship-Dataset数据集,Vessel-YOLO相比于YOLOv8n模型取得了显著的改进,表明其在处理SAR图像方面的能力更为出色。而在SSDD数据集上,虽然两个模型在mAP0.5方面表现相似,但在更具挑战性的mAP0.5∶0.95指标上Vessel-YOLO取得了明显的提升,这表明其在处理多尺度和大目标检测方面具有较好的效果。此外,改进方法对模型的参数、计算量和实时检测能力的影响较小,改进模型仍然保持了实时检测的能力。
2.4 对比实验
为证明Vessel-YOLO船舶检测模型的有效性与合理性,本文进行了大量的实验。消融实验使用的基础数据集是SAR-Ship-Dataset数据集。
2.4.1 CASPP 上下文空间金字塔池化
为验证CASPP模块在SAR船舶图像检测中的贡献度,本文将其与现在主流的空间金字塔池化模块SPP、SPPF、SimSPPF[3]、ASPP等进行了对比实验。表2为不同特征金字塔对精度的影响,展示了不同特征金字塔在SAR-Ship-Dataset数据集下的表现。
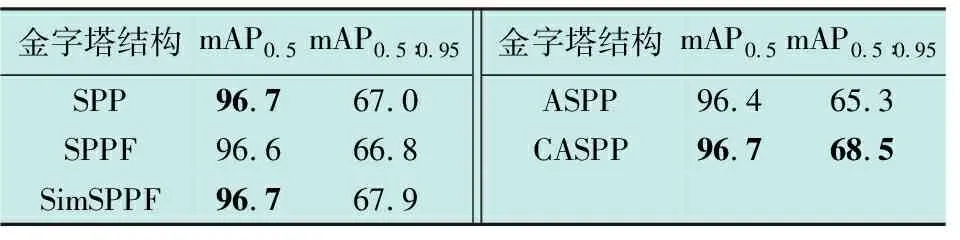
表2 不同特征金字塔池化对精度的影响
空间金字塔池化(Spatial Pyramid Pooling, SPP) 作为特征提取器,通过在不同层级上构建不同大小的空间子区域金字塔,实现对不同尺度或大小的图像进行池化,从而产生固定维数的输出。由表2可知,在SAR-Ship-Dataset数据集下,本文设计的CASPP上下文空间金字塔池化模块在SAR图像船舶检测任务中具有较好的优势。在mAP0.5指标上,CASPP与SimSPPF相当,高于基准模块SPPF;且在mAP0.5∶0.95指标上,CASPP相比于基准模块SPPF提升了1.7个百分点,具有显著优势。
CASPP模块通过不同扩张率的膨胀卷积操作获得不同感受野的上下文信息,并使用加权融合操作将这些信息聚合到输出中,从而在空间和通道维度上添加特征图。这样可以对不同尺度、模态的特征进行加权求和,得到更全面和鲁棒性更强的特征表示。因此,相比于其他金字塔池化模块,CASPP模块能够更好地提取语义特征,增强改进模型Vessel-YOLO在SAR图像船舶检测任务中的性能。
2.4.2 Wise-IoU 基于动态非单调聚焦机制的边界框损失
为验证Wise-IoU模块在SAR船舶图像检测中的贡献度,本文将Wise-IoU模块与目前主流的GIoU[15]、 DIoU[16]、CIoU[16]等进行了对比实验。表3为不同IoU在SAR-Ship-Dataset数据集中的表现。

表3 不同IoU对实验结果的影响
由表3可知,通过测试不同的IoU对初始模型在SAR-Ship-Dataset数据集下的表现可知,Wise-IoU表现最优,在mAP0.5∶0.95指标上相比于基准模型CIoU提升了1.2个百分点。
由于SAR图像受环境和地理位置的干扰,船舶尺寸和形状变化较大,训练数据中难以避免地包含低质量图像。传统的边界框损失函数假设训练数据具有较高的质量,强调对边界框的拟合能力,但这种假设会导致模型在低质量图像上的泛化能力下降。Wise-IoU损失函数在锚框与目标框较好地重合时减少几何维度的惩罚,降低对低质量图像的干预,从而提升模型的泛化能力。因此,本文模型引入Wise-IoU损失函数是合理的。
2.5 模型效果对比
图4所示为模型效果对比。

图4 模型效果对比Fig.4 Model performance comparison
由图4(a)~4(c)可知,Vessel-YOLO模型在密集、靠岸、复杂的场景中的表现均强于基准模型YOLOv5n和YOLOv8n,这体现了模型对不同场景的适应程度。由图4(d)~4(f)可知,在小型目标情况下,基准模型与本文模型均表现良好,但在中型与大型目标的情况下,改进模型Vessel-YOLO的效果远高于基准模型。这是由于CASPP上下文金字塔池化模块通过以不同的膨胀卷积率进行膨胀卷积来获得不同的感受野的上下文信息,提高了模型对不同尺度的特征的提取能力,使其具有对大、小型目标都能提取到足够的语义信息,提升模型的泛化能力。
此外,为了展示模型在语义感知能力方面的优势,本文比较了不同尺度下图像热力图的结果,具体表现在图4(g)~4(i)中。热力图可以显示出模型在输入数据的不同区域或特征上的活跃程度,从而反映模型对于不同语义类别的感知能力。总的来说,通过热力图可知,改进模型对于物体边界、纹理特征的提取更加细致。分别来说,对于小型和中型目标,基准模型和Vessel-YOLO模型的差异较小,两者都能够准确地关注到船舶本身。然而,对比大型目标的热力图,可以观察到Vessel-YOLO模型更好地拟合了船舶的形态,进一步验证了改进模型在大型船舶检测方面的显著优势。
3 结束语
本文提出了一种新的细化检测粒度并增强深浅特征融合的SAR图像船舶检测模型Vessel-YOLO,该模型的设计用于不同SAR拍摄场景下船舶的检测与定位,不受船舶尺度变化和较强噪声干扰的影响,具有较高的有效性,广泛的实验也验证了本文模型强大的性能。
