特征增强的Sparse Transformer目标跟踪算法
2024-05-09张丽君李建民
张丽君, 李建民, 侯 文, 王 洁
(中北大学信息与通信工程学院,太原 030000)
0 引言
视觉目标跟踪技术是计算机视觉领域的一个重要研究方向,它广泛应用于如人机互动、视频监控和自动驾驶[1]。然而,由于存在诸如目标变形、相似物干扰、目标遮挡等外界因素,以及尺度变化和旋转等因素,实现高精度、强鲁棒性和强实时性的目标跟踪仍然是一项具有挑战性的任务[2]。
近年来,基于孪生网络的方法在目标跟踪领域比较流行[3-8]。SiamFC[3]是一项开创性的工作,它将特征相似性学习与连体框架相结合,显著提高了基于深度学习方法的跟踪器的跟踪速度。SiamRPN[6]将孪生网络与RPN[7]结合起来,利用深度相关进行特征融合,获得了更精确的跟踪结果。之后,相关深度学习跟踪器也大多基于此方法进行改进和优化,如增加额外的分支[5]、使用更深的架构[6]和利用无锚的架构[8]等。大多数追踪器,包括一些流行的在线追踪器(如ATOM[9]和DiMP[10])都依赖于相关操作。然而,交叉相关操作执行的是局部线性匹配过程,容易陷入局部最优[11]。其次,交叉相关捕获了关系,但破坏了输入特征的语义信息,这对准确感知目标边界是不利的。
Transformer由VASWANI等[12]首次提出并应用于机器翻译。由于视觉领域的技术发展趋势[13],以及受到Transformer在自然语言处理(NLP)领域取得巨大成就的启发[14],文献[15]将注意力机制与卷积模型相结合,以增强模型的感受野和全局依赖性。之后,RAMACHANDRAN等[16]考虑了注意力是否可以完全取代卷积,提出了一个Stand-Alone自注意力网络(SANet),与原始基线相比,该网络在视觉任务上取得了优异的性能。最近,TransT[11]和DTT[17]提出用Transformer取代交叉相关,从而产生融合的特征,而不是响应得分。由于融合的特征包含丰富的语义信息,这些方法取得了较以往的连体追踪器更准确的跟踪性能。但使用Transformer构建跟踪器会导致新的问题:Transformer中自注意力机制的全局视角缺少对局部特征的捕捉,导致对搜索区域中最相关信息的关注不足,很容易被背景分心,使得前景和背景之间的边界模糊不清,从而降低跟踪性能。
针对上述问题,本文提出特征增强的Sparse Transformer算法,分别在OTB100、VOT2018和LaSOT等5个数据集上进行了测试。试验结果表明,所提算法能较好地缓解自注意力机制容易被背景干扰的问题,有利于准确感知目标的边界,使跟踪器获得良好的跟踪性能。
1 本文算法
本文所提特征增强的Sparse Transformer目标跟踪算法由特征提取网络、特征增强模块、Sparse Transformer和分类回归头组成,算法整体框架如图1所示。
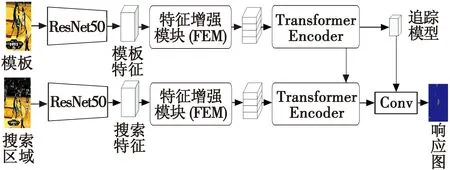
图1 算法整体框架Fig.1 Overall framework of the algorithm
本文将详细介绍特征增强模块与Sparse Transformer模块,本文算法采用的分类回归头与PrDiMP[18]的结构相同,此处不再做具体介绍。
1.1 特征增强模块
近期有学者在工作中提及Transformer的缺点:全局的、长程的注意力机制能够捕获patch之间的长距离依赖关系,但很容易忽略图像的局部特征。为弥补此不足,考虑从增强局部特征方面解决。
本文引入特征增强模块(Feature Enhancement Module,FEM)来实现图像的多尺度特征信息的提取,通过多个不同空洞率的空洞卷积聚合图像中不同尺寸的上下文信息,为后续的Sparse Transformer结构提供包含丰富局部信息的特征,从而增强跟踪算法对目标局部特征的表达能力,如图2所示。
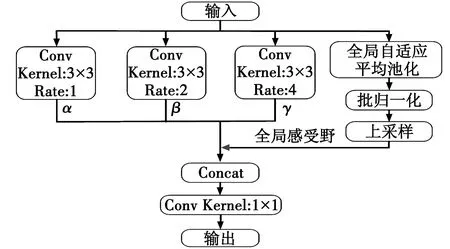
图2 特征增强模块结构Fig.2 Structure of feature enhancement module
如图2所示,特征增强模块结构由3个不同空洞率的空洞卷积(α,β,γ)分支和1个含有全局平均池化(Global Average Pooling,GAP)的分支构成。其中,输入为经过ResNet50网络提取到的目标模板图像的特征与搜索图像的特征。
针对空洞卷积局部相关性不足的问题,本文参考HDC(Hybrid Dilated Convolution)和DUC(Dense Upsampling Convolution)设计原则,将一定数量的卷积层形成一个特征增强模块,该模块使用连续增加的空洞率,可以在更广阔的像素范围内获取信息,从而避免了棋盘问题。同时,通过研究空洞率对算法性能的影响,设置空洞卷积α空洞率(Rate)为1、β空洞率为2、γ空洞率为4,3个空洞卷积的卷积核(Kernel)尺寸都为3×3标准卷积核大小,padding值与空洞率选取值相同。采用多个空洞率较小的空洞卷积,可以避免引入过多冗余信息,通过不同的填充以及膨胀因子,可以提取到多尺度信息。
为防止空洞率增大时出现卷积退化的问题,通过全局平均池化(GAP)获取图像的全局特征信息,批归一化(BN)并上采样到原来的尺寸,最后将多个特征图进行Concat拼接,利用1×1卷积对拼接后的特征进行整合并降维,得到特征增强模块的输出。
1.2 Sparse Transformer模块
Transformer已经成功应用于计算机视觉跟踪任务,但Transformer中自注意力的全局视角会导致主要信息(如搜索区域的目标)聚焦不足,次要信息(如搜索区域的背景)聚焦过度,使得前景和背景之间的边缘区域模糊不清,从而降低跟踪性能。
本文通过引入Sparse Transformer模块,实现对搜索区域最相关信息的关注,抑制干扰性背景信息,使目标更具有辨别力,即使在部分遮挡、比例变化等情况下,目标的边界框也能更精确,从而提高跟踪算法对目标跟踪定位的精度。
1.2.1 位置编码
由于自注意力机制的排列不变性,Transformer需要位置编码来标识当前处理token的位置。SwinTrack[19]在目标跟踪领域取得的成绩令人瞩目,本文参考SwinTrack中采用的无约束位置编码(Untied Positional Encoding)[20]对Sparse Transformer模块进行位置编码。
1.2.2 编码器
图3所示为编码器结构。

图3 编码器结构Fig.3 Encoder structure
图3中,编码器由N个编码器层组成,每个编码器层将其前一个编码器层的输出作为输入,并将空间位置编码输入到编码器中。因此,第1个编码器层把带有空间位置编码的目标模板特征作为输入。具体计算表示为
(1)
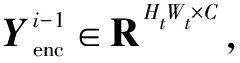
1.2.3 解码器
图4所示为解码器结构。解码器由M个解码器层组成,图4(a)中,每个解码器层不仅输入带有空间位置编码的搜索区域特征或其前一个解码器层的输出,还输入由编码器输出的目标模板的编码特征。具体计算表示为
(2)
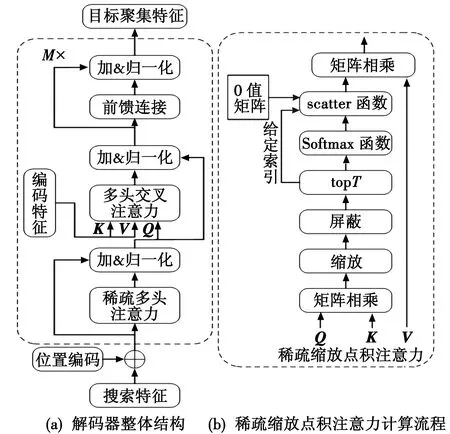
图4 解码器结构Fig.4 Decoder structure
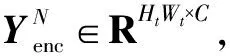
特别地,本文采用的稀疏注意力机制在每个解码器层先使用稀疏多头自我注意力机制(SMSA)计算的自我注意力,再使用多头交叉注意力机制(MCA)计算Z和X之间的互注意力。SMSA具有局部紧密相关和远程稀疏相关的特性,注意力特征的每个像素值只由与之最相似的T个像素值决定,这可以很好地缓解MSA易受噪声和背景干扰的影响。
具体来说,如图4(b)所示,给定Q∈RHW×C、K∈RC×H′W′、V∈RH′W′×C,首先计算Q和K之间所有像素对的相似度,屏蔽掉相似度矩阵中不必要的标记。SMSA只用Softmax函数对相似度矩阵每一行中最大的T个元素(topT)进行归一化处理。scatter函数将给定值填充到给定索引处的 0 值矩阵中。最后,将相似度矩阵和V进行矩阵乘法,得到最终结果。
稀疏注意力机制的每个解码器层可以表示为
(3)
式中:SMSA(·)表示使用稀疏多头注意力计算搜索区域特征X上的注意力;MCA(·)表示使用经典的交叉多头注意力计算X和目标模板特征Z之间的互注意力;FFN(·)表示前馈连接网络层;Norm(·)表示利用归一化层对数据维度进行批标准化操作。
2 实验与结果分析
2.1 实验细节
在Ubuntu16.04系统上使用PyTorch1.4.0深度学习框架和CUDA10.1深度学习架构,实验硬件环境为Intel®CoreTMi7-10700 CPU 2.90 GHz处理器、内存64 GiB的计算机,并使用GPU(NVIDIA TITAN Xp)进行加速。
整体网络利用LaSOT、TrackingNet、GOT-10k和COCO的训练分项进行离线训练,将epoch设为50,每个epoch进行1500次迭代,每批有36个图像对。采用ADAM优化器进行优化,初始学习率为0.01,每15个epoch进行衰减,衰减系数为0.2。
2.2 定性分析
为定性说明本文算法的有效性,从OTB100数据集与LaSOT数据集分别选择2个包含多场景的视频序列,比较4个性能优秀的跟踪器(SAOT、SiamR-CNN、Siam-RPN++、TransT(N2))和本文算法的跟踪结果。图5所示为各算法在4个视频序列中定性评估的跟踪结果。

图5 多种跟踪算法定性分析结果对比Fig.5 Comparison of qualitative analysis results of different tracking algorithms
由图5可知,本文算法通过特征增强的Sparse Transformer,使跟踪器有较强的稳健性和可靠性。
2.3 定量分析
为评估本文算法的有效性,分别在OTB100、VOT 2018、LaSOT、GOT-10k和TrackingNet等5个测试集上进行测试评估,下面对测评结果进行分析。
2.3.1 TrackingNet数据集实验结果
各流行算法与本文算法在TrackingNet成功率(AUC)、精确度(P)、归一化精确度(PN), GOT-10k数据集上的平均重合度(AO)和成功率(SRT)的结果(概率值)见表1。
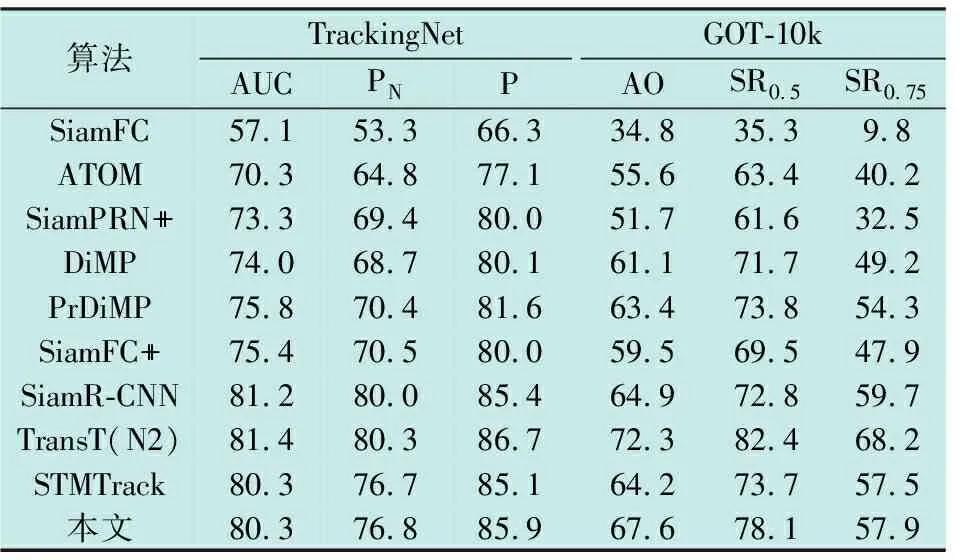
表1 在TrackingNet和GOT-10k数据集上的结果
TrackingNet是一个涵盖了不同物体类别和场景的大规模跟踪数据集,它的测试集包含了511个公开可用的地面实况序列。本文算法的AUC、PN和P分别为80.3%、76.8%和85.9%,整体性能表现良好。
2.3.2 GOT-10k数据集实验结果
GOT-10k数据集包含10k(10000)个序列用于训练,180个序列用于测试。由表1结果显示,本文算法取得了良好的性能,在主要的AO指标方面,本文算法比SiamR-CNN算法高2.7个百分点。
2.3.3 OTB100数据集实验结果
OTB100数据集是视觉目标跟踪领域常见的测试数据集,有100个带有标注的视频,涉及到如光照变化、尺度变化、遮挡、形变、运动模糊等11个属性。将各流行算法与本文算法在OTB100数据集上进行对比,实验结果如图6所示。
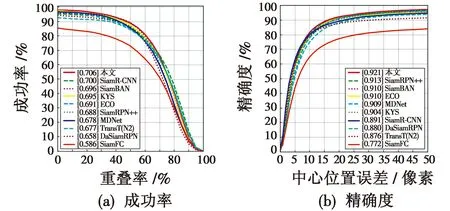
图6 OTB100数据集上各算法的性能评估结果Fig.6 Performance evaluation results of each algorithm on OTB100
由图6可知,相比于SiamR-CNN算法,本文算法在OTB100数据集上的成功率提升了0.6个百分点,精确度提升了3个百分点。
2.3.4 VOT2018数据集实验结果
VOT2018数据集由60个具有不同挑战因素的视频序列组成,评价指标包括准确性(A)、鲁棒性(R)、丢失数(Lost Numbers)和期望平均重叠率(EAO)。遵循VOT2018数据集的评估标准,本文算法与其他流行算法进行对比,结果如图7所示。

图7 VOT2018数据集上各算法的EAO排名Fig.7 EAO ranking of each algorithm on VOT2018
由图7可知,与DiMP50算法相比,本文算法的EAO值提高了1.8个百分点,与近几年的主流跟踪算法相比,本文算法表现出较高的EAO值,在VOT2018数据集上的整体性能表现良好。
2.3.5 LaSOT数据集实验结果
LaSOT是一个具有高质量注释的大规模数据集,它包含1400个具有挑战性的视频。各流行算法与本文算法在LaSOT数据集上的成功率(AUC)和精确度(P)和归一化精确度(PN)如图8所示。
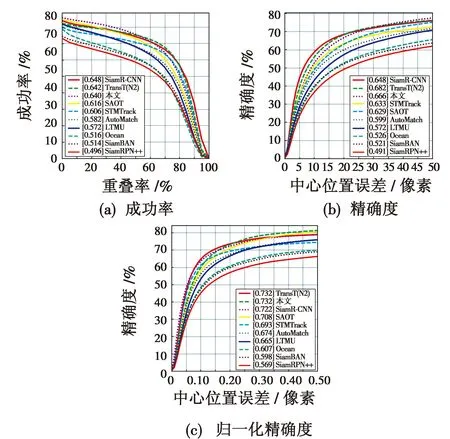
图8 LaSOT数据集上各算法的性能评估结果Fig.8 Performance evaluation results of each algorithm on LaSOT
结果显示,除SiamR-CNN和TransT(N2)算法外,本文算法获得了最好的性能,成功率64.0%。
2.4 各算法在不同属性上的成功率比较
图9展示了各算法在OTB100数据集的11种不同属性上的成功率。
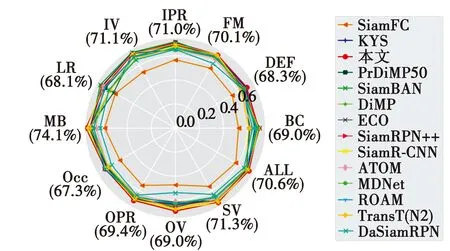
图9 OTB100数据集上不同属性的成功率比较Fig.9 Comparison of success rates of different attributes on OTB100
本文算法在背景干扰(BC)属性上相比基线算法PrDiMP50的成功率提升7.2个百分点,在运动模糊(MB)属性上提升4.1个百分点,这证明特征增强的Sparse Transformer可以有效抓取局部信息,减小杂乱背景带来的影响,提高算法的鲁棒性和跟踪定位的精度。此外,本文算法在出视野(OV)、变形(DEF)、平面外旋转(OPR)等属性上的表现均高于其他算法。
2.5 消融实验
1) 为分析特征增强模块中不同空洞率的设置对算法性能的影响,在GOT-10k数据集上进行实验,参考HDC和DUC设计原则的基础上,设置了5组空洞率并进行实验研究,具体实验结果(概率值)如表2所示。
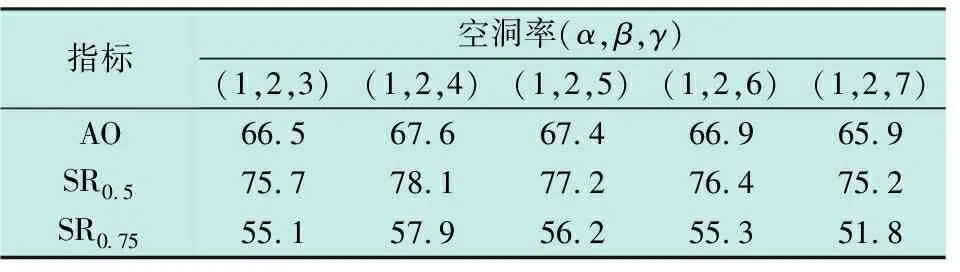
表2 不同空洞率设置的实验结果
实验结果表明,在空洞卷积的卷积核尺寸都为3×3标准卷积核大小的情况下,设置空洞卷积α的空洞率为1、β的空洞率为2、γ的空洞率为4时,取得更好的跟踪性能。
2) 为测试算法中特征增强的Sparse Transformer 模块对跟踪性能产生的影响,在 LaSOT 数据集上进行了消融对比实验,实验从参数量和计算量(FLOPs)以及成功率和帧率(FPS)4个方面进行对比,具体见表3。
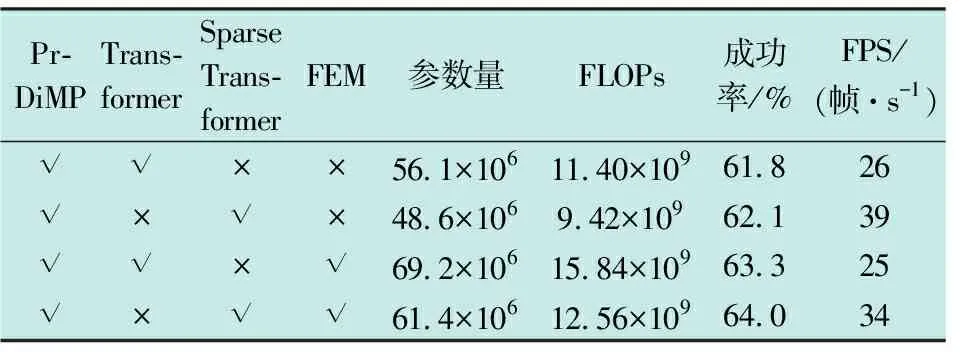
表3 消融实验结果
由于硬件设施等运行环境不同,以及优化过程的随机性等原因,本地复现结果与原作者提供的结果有差异。本地复现的实验结果表明,特征增强的Sparse Transformer聚焦网络模块能够有效提高跟踪器的成功率,同时由于Sparse Transformer减少了关联性的计算,可以节省显存,加快计算速度,这也优化了跟踪器的实时性能。
3 结束语
针对目前基于Transformer的视觉目标跟踪算法计算量大、对局部特征注意力不足等问题,提出一种特征增强的Sparse Transformer视觉目标跟踪算法。利用Sparse Transformer聚焦搜索区域内最相关的信息,降低了跟踪网络的计算复杂度,提高了Transformer的注意力集中度,特征增强模块为Sparse Transformer结构提供包含丰富局部信息的特征,进一步提高目标跟踪的精确度。大量数据集上的实验结果证明了本文算法的有效性,同时也发现其不足之处,例如当发生光照变化或图像分辨率过低时,跟踪器对目标进行跟踪的准确性有所降低,该问题将是下一步继续研究的重点。
