基于改进MobileNetV3模型的服装流行色研究
2024-05-09刘凤华刘兆琪刘卫光赵红升
刘凤华, 刘兆琪, 刘卫光, 赵红升
(中原工学院 计算机学院, 河南 郑州 450007)
颜色是服装的重要属性,是用户购买服装时的主要关注点的之一;准确预测服装颜色流行趋势,对整个服装行业的生产销售具有重大的指导意义[1]。目前,服装流行色的研究方法可主要分为两大类:一类是基于经验的主观分析方法;另一类是基于统计数据的建模分析方法。柴志君等以中国纺织信息中心发布的2012-2019春夏秋冬流行色方案为数据集,考虑流行色变化与季节要素的关联性,结合统计分析与灰色关联分析方法,通过建立曲线拟合模型分析了服装的流行颜色[2];江莎莉以中国纺织信息中心发布的2000-2019春夏秋冬流行色方案为数据集,采用线性趋势分析法、滑动平均法和Mann-Kendall法,对流行色分布规律进行了研究[3];张婕针对服装流行色传统预测方法存在的预测精度低、结果不可靠问题,采用模糊C均值聚类算法对数据进行聚类处理,并在构成训练样本集后用支持向量机技术训练样本,完成模型学习,建立了预测模型[4];黄伟在比较市场调研法、函数模型法、主管判断法3种服装流行色预测方法优劣的基础上,提出了利用云计算技术设计预测模型的思路[5]。分析文献发现,目前的服装流行色研究主要存在3个方面的问题:其一是数据可用性问题,即无论是官方公布数据还是市场调研数据,都会受到所采用数据时间段的限制,且实时性不高;其二是模型实用性问题,即所建立模型大都只是用于泛泛讨论服装的流行色,而缺乏进一步针对款式、品牌等的细致研究;其三是流行色讨论的单一性,即大都局限于对服装单一流行色系的讨论,而未涉及服装的流行色组合。本文提出一种基于实时挖掘的互联网数据进行服装流行色分析的方法,从互联网平台获取实时颜色数据并得到准确的流行色数据集,利用深度学习算法建立模型,在获取不同服装类别的颜色和销量信息后,分析服装颜色的流行趋势,进一步建立不同关键字下的服装颜色预测模型。
1 相关理论和算法
1.1 Selenium数据获取算法
本文采用Selenium框架的Webdriver工具,以测试方式运行浏览器,按设定步骤对电商平台进行操作:首先,搜索服装并按评论数量从多到少进行排序,获取页面内所有关于服装的信息,建立服装唯一性的特征表;然后,设置时间间隔,并定时更新,以保障数据获取的实时性和可靠性;最后,将提取的数据存入本地文件中。由于网页展示数据使用的是Ajax异步加载方式,在页面生成时只能展示数据总量的一半,因此必须通过浏览器操作,下拉滚动条,才能加载所有的数据。
基于Python软件的request库,通过构造url和请求条信息,向目标服务器发送数据请求;返回服务器接口提供的json数据,得到商品详情页的评论数据、图片数据、时间数据等,并存入本地文件中。对于图片数据则需在图片预处理后进行保存。根据电商平台的先购物再评论规则,可以把评论的数量视作商品的销量。因此,通过汇总评论数量可得到相应的销量信息。
在数据抓取时,采用Chromedriver工具抓取服装中的评论数据和图片数据,共计抓取了10 000张图片,并将它们分成了33类,包括男士上衣、男士下装,女士上衣和女士下装等。将评论数据和图片数据组成键值对,并根据评论数量(评论数量>1 000条时)决定要抓取的图片,对图片进行数据清洗后将有效数据存储到本地[6]。
1.2 MobileNetV3图像分类算法
本文构建一种基于MobileNetV3[7]的轻量级网络模型。该模型采用Depthwise(缩写为DW)卷积和Pointwise(缩写为PW)卷积,比传统模型的参数量大为减少,因此可将其直接部署在移动端的设备上。MobileNetV3轻量级网络模型的block结构如图1所示。
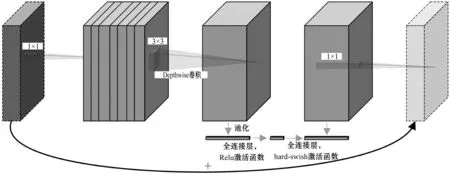
图1 MobileNetV3轻量级网络模型的block结构
构建MobileNetV3轻量级网络模型的方法为:首先,用倒残差结构进行升维操作,将原先低纬度密集的信息抽象到高维度空间,并在高维度空间采用不同的激活函数来滤除无关信息;然后,采用通道域注意力机制(Squeeze-and-Excitation,SE)模块,增强通道间的特征表达能力;最后,用1×1的卷积核进行降维。SENet[8]是通过对每个通道的加权,使原特征图分别点乘权值,达到对不同特征通道进行资源分配的。但是,它忽略了空间维度上的注意力机制。为此,本文在原有网络模型的基础上,将倒残差结构中的SE模块替换为融合空间域和通道域的注意力机制(Convolutional Block Attention Module,CBAM)模块[9]。CBAM模块的结构如图2所示。CBAM模块包括两部分:第一部分用于对输入特征图进行通道域注意力机制的操作,并将其与输入特征图相乘,以得到空间域注意力机制模块需要的输入特征;第二部分用于对新的输入特征进行空间域注意力机制的操作,并将其与新的输入特征图相乘,以得到最终的生成特征。
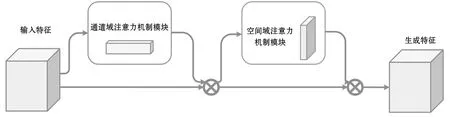
图2 CBAM模块的结构
1.3 GrabCut图像分割算法
将图像分类后,需要判断图像中人物的服装颜色。由于每张图像都含有大量的干扰信息,因此需要将无关区域分割出来,以便有针对性地分析服装颜色。
GrabCut算法可用于人工选取矩形的感兴趣区域。其矩形框外为背景,框内为前景。首先通过GrabCut算法获取人物区域,再通过形态学计算前景区域的像素点数量,以得到人物区域占整张图像的比例,即服装区域所占的比例。
GrabCut算法采用的是s-t网络。采用s-t网络,能针对前景区域与背景区域建立高斯混合模型(Gaussian Mixed Model,GMM),而GMM能通过参数的迭代更新来有效地提高算法的精度。
1.4 K-means颜色聚类算法
K-means颜色聚类算法是一种基于数据划分的无监督聚类算法。它能在不知道样本集所属标签或类别的情况下,借助样本间的相似性完成自主聚类[10],将具有某些相似性的数据点归为一个群集。
该算法的主要步骤为:①随机选取k个像素点,作为初始聚类质心(c1,c2,…,ck);②更新聚类质心,包括分配聚类(即计算数据集中每个像素点xj与各个聚类质心的欧式距离,并将像素点归于与聚类质心最近的聚类)与移动质心(即计算每个聚类中所有像素点的欧氏距离之和,并将聚类质心重定位到平均位置);③迭代步骤②,直到每个聚类中所有像素点的欧氏距离之和达到最小为止。
2 MobileNetV3模型的主要模块
2.1 实时数据获取模块
实时数据获取模块用于实时获取大型电商平台的服装评论和图像数据,并在预处理所获取数据后进行数据的持久化存储。对图像的预处理包括统一图像格式和统一图像文件名格式,将所有图像通过处理函数统一成.jpg格式,在文件名中加上时间戳后通过算法去除雷同的图像,建立服装基础信息表,并保存服装的评论和所获取的其他属性数据。
2.2 服装图像分类模块
服装图像分类模块用于:针对服装图像采用深度学习算法进行分类,为每个图像类别建立数据表,保存图像的分类结果,并建立分类表与服装基本信息表的关联。
服装图像分类过程包括3个阶段:第一个阶段是数据的预处理,即采用Mosaic数据增强、MixUp混类增强(包括图像的水平翻转、随机裁剪、色域扭曲),将图像尺寸固定在224像素×224像素×3通道;第二个阶段是构建合适的特征提取网络并进行图像的特征提取(由于MobileNetV3模型的参数量小、可进行实时性检测、易于部署在移动端等,因此可基于MobileNetV3模型,构建一个融合多策略的分类模型);第三个阶段是模型的训练,包括训练阶段和测试阶段。训练阶段,将训练集输入搭建好的网络模型中,并将训练好的参数模型保存起来;测试阶段,把图像输入训练好的网络模型中,并在输出图像的类别后进行分类。服装图像分类模块的算法流程如图3所示。

图3 服装图像分类模块的算法流程
2.3 服装图像主颜色提取模块
服装图像主颜色提取模块用于分析图像像素点的颜色分量,确定服装的颜色大类,建立服装图像的主颜色表,并存储服装的主颜色。服装颜色大类分为单色服装、混色服装(包括双色、三色服装)。
服装主颜色的提取主要采用GrabCut方法和K-means方法。
GrabCut方法的作用是提取前景区域[11],并将前景区域的颜色设置成白色,背景区域的颜色设置成黑色,以组成前景值为1、背景值为0且与原始图像大小一致的掩模图像。将掩模图像与原始图像做“与”计算,得到的图像是包含前景图像和黑色背景的图像,且黑色区域所占比例为背景所占整张图像的比例。将原背景区域所占的像素点去除,剩下的部分即前景区域所有颜色的像素点。原始图像经过与掩膜图像的“与”计算,可得到提取前景后的图像,而且此时背景全部为黑色。图像提取前景区域的效果如图4 所示。

(a) 原始图像 (b) 提取前景后的图像
K-means方法的作用是找出图像中能代表整张图像的n种颜色,并针对这n种颜色统计图像中的像素点数量。分别将前景区域每种颜色的像素点数量与前景区域总像素点数量相除,就能得到前景区域每种颜色的占比。某图像中5种颜色的占比如表1所示。

表1 某图像中5种颜色的占比
由表1可知,灰紫色可以作为服装的主颜色。
在服装图像主颜色提取时,首先将要识别的图像输入程序中,创建一个和原始图像尺寸一致的掩模图像;然后利用GrabCut算法分割前景与背景,得到包括前景轮廓信息的掩膜图像,并将掩模图像中背景区域标记为黑色,前景区域标记为白色;再将原始图像与掩模图像做“与”运算,得到去除背景的图像;最后进行K-means聚类运算,得到图像每种颜色像素点的占比。占比最大的颜色即为图像的主颜色。主颜色提取算法的伪代码为:
Begin
cv2.grabCut(原始图像,掩模图像,ROI区域,临时背景,临时前景,迭代次数,cv2.GC_INIT_WITH_RECT)
mask = np.where((掩模图像== 2)|(掩模图像== 0), 0, 1).astype(‘uint8’)
ratio_brown = cv2.countNonZero(mask)/(原始图像尺寸/ 3)
bPercentage = 1 - np.round(ratio_brown, 2)
cutimg *= mask [:, :, np.newaxis]
kmeans = KMeans(n_clusters = CLUSTERS, random_state=0)
hex_colors = [RGB值换算Hex值(center) for center in kmeans.cluster_centers_]
for c in kmeans.cluster_centers_:
h, name = RGB值换算名称(c)
颜色名称数组[h] = name
cluster_map = pd.DataFrame()
mydf=cluster_map.分组查询([‘color’,颜色名称]).agg({‘position’:‘像素点数量’}).reset_index().rename(columns={“position”:“count”})
plt.pie(颜色像素点数量, labels=颜色名称, colors=颜色Hex值, autopct=‘%1.1f%%’, startangle=90)
plt.show()
for index, row in mydf.iterrows():
if check_color(color.to_rgb(row[‘color’])):
mydf.loc[index, “count”] = abs(颜色的像素点数量之和-当前颜色像素点数量)
mydf.loc[index, “Percentage”] =当前颜色像素点数量/图像中像素点总数*100
End。
3 改进的MobileNetV3图像分类模型
改进的MobileNetV3图像分类模型如图5所示。

图5 改进的MobileNetV3图像分类模型
在图5中,Bneck为MobileNetV3图像分类模型中的倒残差结构。利用该模型操作时,先将13个倒残差结构堆叠成特征提取网络;然后在提取的特征图上连接线性层,进行特征组合;最后经过Softmax层分类输出图像所属类别的最大概率,实现对图像的分类。
采用迁移学习训练模型时,首先将图像大小设定为224像素×224像素,并输入网络模型中进行训练;其次用预训练权重固定网络特征提取时确定的参数值,并在训练迭代100 epoch后基于验证集测试准确率;然后将训练好的MobileNetV3-CBAM模型(即改进后网络模型)的权重在本地进行保存,并冻结主干提取部分;最后将后续图像批量输入模型中,得出分类结果,并依据分类结果对图像进行分类,以满足对不同类别服装进行分析的需要。采用不同网络模型进行图像分类的结果对比如表2 所示。

表2 采用不同网络模型进行图像分类的结果对比
由表2可知:MobileNetV3-CBAM网络模型比MobileNetV3-SE网络模型(即原网络模型)的准确率提升了1.5个百分点;MobileNetV3-CBAM网络模型比ResNet101-CBAM网络模型的参数量下降了一个数量级。可以认为,本文对图像分类网络模型的改进,无论在网络模型轻量化方面还是在提升图像分类准确率方面都是可行的。
4 基于MobileNetV3-CBAM网络模型的服装流行色分析实验
为了进行服装流行色分析实验,本文给出了图6所示的服装流行色分析模型。该模型主要包括4个模块,即实时数据获取模块、服装图像分类模块、服装图像主颜色提取模块和服装流行色分析模块。

图6 服装流行色的分析模型
可根据得到的数据对服装进行时序规律分析[12]、品类流行分析、地域流行分析等[13]。本文在基于MobileNetV3-CBAM网络模型的服装流行色分析实验中,进行了时序规律分析和品类流行分析。
4.1 时序规律分析
时序规律包括年规律、季规律[14]、月规律、周规律、特定节日规律等。根据文献[15],对整个数据集的某个时间段进行流行色分析时,可汇总该时间段全部服装的主颜色,绘制图形,进行流行色分析。图7所示为2020年1月到2022年5月的黑色、红色、米色服装销量曲线。
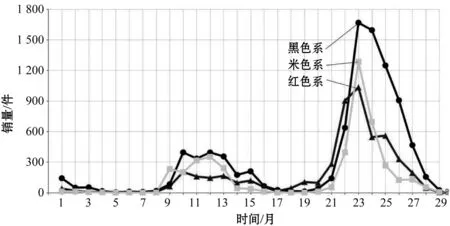
图7 2020年1月到2022年5月的黑色、红色和米色服装销量曲线
4.2 品类流行分析
品类流行分析在于分析不同服装类别、不同服装款式的流行色变化规律,分类汇总数据并进行可视化展示。图8所示为某品牌羽绒服约两年半时间所有色系的销量折线。

图8 某品牌羽绒服约两年半时间所有色系的销量折线
从图8可看出,在2020年1月到2022年5月期间,某品牌羽绒服的销售旺季是每年的10月到次年1月,销量排名前三的流行色分别为黑色系、紫色系和红色系。
5 结语
本文提出了一种基于互联网大数据的服装流行色研究方法。其重点在于数据获取和数据分析。采用深度学习方法对服装图像进行分类识别,可分析不同类别不同款式服装的流行色,解决服装流行色分析数据来源受限、数据集容量不足的问题。下一步将重点研究在复杂背景下准确预测服装流行色的方法,以便从不同维度如不同性别、不同地域进行服装流行色的分析。
